這一篇介紹重頭戲:多智能體強化學習,多智能體要比之前的單智能體復雜很多,但也更有意思,
13. Multi-Agent-Reiforcement-Learning
13.1 多智能體關系設定
- 合作關系 Full Cooperative Setting
- 競爭關系 Full Competitive Setting
- 合作和競爭的混合 Mixed Cooperative & Competitive
- 利己主義 Self-Interested
a. 完全合作關系
- agents 的利益一致,合作去獲取共同的回報;
- 如工業機器人共同裝配;
b. 完全競爭關系
- 一個 agent 的收益是另一個 agent 的損失;
- 如機器人搏斗,零和博弈;
c. 合作競爭混合
- 既有合作,也有競爭;
- 如足球機器人;
d. 利己主義
- 每個 agent 只考慮最大化自身利益,不關心別人的利益;
- 比如股票的自動交易;
13.2 專業術語
下面在多智能體的背景下更新一下先前的概念:
a. state / action / state transition
-
假設系統中有 n 個 agents,S 表示狀態,用 \(A^i\) 表示 第 i 個agent 的動作
-
狀態轉移函式 : \(p(s'|s,a^1,...,a^n)=\mathbb{p}(S'=s'|S'= s',A^1=a^1,...,A^n = a^n)\)
這個函式是隱藏的,即只有環境知道,而人不知道,
-
多智能體問題的難點就是,下一狀態 S' 會受到所有 agents 的 動作的影響,
b. Rewards
- 有 n 個 agents ,每一輪就會有 n 個獎勵,用 \(R^i\) 表示第 i 個 agent 的獎勵;
- 在合作的情境下:每個 agent 的獎勵都相等;
- 在競爭的情境下:一個 agent 的獎勵是另一個 agent 獎勵的損失:\(R^1 \propto -R^2\)
- agent 獲得的獎勵不僅僅取決于本身的動作,還取決于 其他 agent 的動作;
c. Returns
-
用 \(R^i_t\) 來表示第 i 個 agent 在 t 時刻獲得的獎勵;
-
則 第 i 個 agent 在時刻 t 的回報 Return 表示為:
\(U_t^i=R_t^i+R^i_{t+1}+...+...\)
-
折扣回報是加權和:
\(U_t^i = R^i_t+\gamma \cdot R_{t+1}^i +\gamma^2\cdot R_{t+2}^i + ...\)
d. Policy Network 策略網路
- 用神經網路近似策略函式 \(pi\);
- 第 i 個 agent 的策略網路記為: \(\pi(a^i|s;\theta^i)\),所有網路結構可以相同;
- 在一些情況下,不同agent的網路引數可能一樣,因為它們彼此是可以替換的;
- 在更多場景中,策略網路不能互換,不同 agent 的功能不同,
e. 獎勵和回報 隨機性的來源
- 獎勵 \(R_t^i\) 依賴于當前狀態 \(S_t\) 和 所有 agent 當前的動作 \(A_t^1,A_t^2,...,A_t^n\)
- 狀態的隨機性來自于狀態轉移函式 p;
- \(A_t^i\) 的隨機性 來自于 策略函式,具體問題中是策略網路 \(\pi\);
- 回報 \(U_t^i\) 依賴于t 時刻開始所有的 獎勵:
- 未來所有的狀態 \({S_t,S_{t+1},...}\)
- 未來所有的動作 \(A_t^i,A_{t+1}^i,A_{t+2}^i,...\)
f. 狀態價值函式
-
第 i 個 agent 的狀態價值函式 是:\(V^i(s_t;\theta^1,...,\theta^n)=\mathbb{E}[U^i_t | S_t=s_t]\)
-
對 \(U_t\) 求期望后,就消除掉了未來的狀態以及所有 agent 的動作,這樣 \(V^i\) 只依賴于 當前狀態 \(s_t\)
-
動作 \(A^j_t\) 是隨機的,根據策略函式 \(\pi\) 來隨機抽樣選擇:\(A^j_t\sim\pi(\cdot | s_t;\theta^j)\);
-
所以第 j 個策略網路會影響狀態價值函式 \(V^i\)
解釋:
- 道理其實很好理解,但上面那么說可能有點繞;意思是,第 i 個 agent 的狀態價值函式 \(V^i\) 依賴于所有 agent 的 策略函式;
- 因為agent 并不獨立嘛,很好理解,如果一個 agent 的策略發生了變化,那么所有的 agent 的狀態價值函式都會發生變化;
13.3 多智能體策略學習的收斂問題
Convergence , 收斂.
- 收斂的意思是,無法通過改變策略,來獲得更大的價值回報;如果所有的 agent 都找不到更好的策略,說明已經收斂,可以停止訓練;
a. 單智能體的策略學習
-
單智能體的策略網路只有一個:\(\pi(a|s;\theta)\)
-
狀態價值函式:\(V(s;\theta)\);
-
對 V 關于狀態 s 求期望,得到目標函式: \(J(\theta)=E_s[V(s;\theta)]\)
消掉了 狀態 s;因為只依賴于 θ,所以可以用于評價策略好壞, J 越大,則說明策略越好,
-
策略網路的引數學習方式為最大化目標函式 J:$ \max\limits_{\theta} J(\theta)$
具體參見:策略學習
-
策略網路的收斂條件為目標函式不再增加,
b. 多智能體的策略學習
如果有多個 agents,判斷收斂的條件就是 納什均衡,
納什均衡:
當其他 agents 都不改變策略時,一個 agent 改變策略,無法讓自己獲得更高的回報,
解釋:
- 一個 agent 制定策略時,需要考慮其他 agents 的策略,在達到納什均衡的狀態下,每個agent 都在以最優的動作應對其他各方的策略;
- 如果所有的 agents 都是理性的,在達到納什均衡時,沒有理由改變改變自己的策略,因為改變不會再增加自己的收益;
- 這達到了一種平衡,收斂了,
在多智能體問題上直接應用單智能體的 演算法 并不好,可能會不收斂,原因:
c. 在 m-agents 問題上應用 s-agent 方法
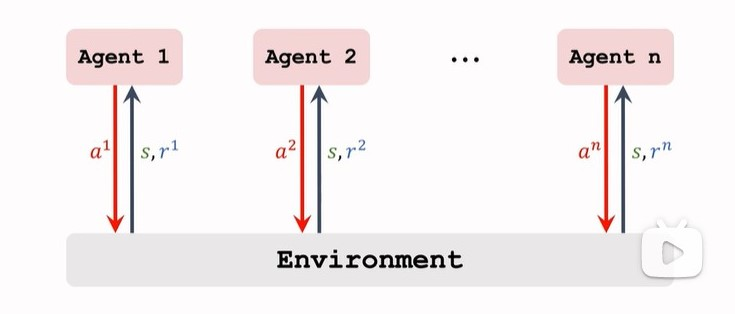
系統中有 n 個 agent,假設獨立和環境互動,即每個 agent 都可以獨立觀測到 環境的狀態 s、接識訓境給的獎勵 ri,進而計算 ai并執行;
接著用策略梯度演算法更新各自的策略網路,就相當于 n 個 agents 的策略學習的疊加,并且彼此之間沒有直接聯系,
下面說明一下這種思路為什么不行:
-
假設第 i 個智能體的策略網路為: \(\pi(a^i|s;\theta^i)\)
-
第 i 個智能體的狀態價值函式為:\(V(s;\theta^1,...,\theta^n)\)
-
目標函式為:\(J(\theta^1,\theta^2,...,\theta^n)=\mathbb{E}[V(s;\theta^1,\theta^2,...,\theta^n)]\)
-
當 \(agent^i\) 要提高自己的回報,即學習第 i 個策略網路的引數,就是最大化目標函式:\(\max\limits_{\theta^i}J^i(\theta^1,..,\theta^n)\)
注意這里的目標函式 \(\max\limits_{\theta^i}J^i(\theta^1,..,\theta^n)\),對于每個 agent 都不相同,
-
當一個智能體通過策略學習更新了策略,會通過環境影響其他智能體的目標函式,這樣整體的策略學習可能永遠無法收斂;
假設 第 i 個智能體找到了最優策略:\(\theta^i_*J^i(\theta^1,\theta^2,...,\theta^n)\)
其余 agent 改變自己的策略時,第 i 個智能體的最優策略就又改變了,
即,每個 agent 都不是獨立的,每個 agent 都影響了下一個狀態,下一個狀態的改變反過來又改變了 agent 的策略,
那么我們應當如何處理多智能體的強化學習呢?
13.4 多智能體學習方法
因為 agents 之間會互相影響,所以最好在 agents 之間做通信來共享資訊,而 agents 之間的通信方式主要分為 中心式 和 去中心式,
a. 去中心化
Fully decentralized. 即 agents 都是獨立的個體,每個 agent 獨立與系統互動,用自己觀測到的狀態和獎勵更新自己的策略;彼此之間不交流,不知道別人的動作,
13.3 中已經介紹了這種方式的不足,
b. 中心化
所有 agent 都把資訊傳給中央控制器,中央控制器收集所有的狀態和獎勵,由中央統一做出決策,agent 自己不做決策,即 定于一尊,
c. 中心化訓練 & 去中心化執行
這種方式 agents 各有各的策略網路;而訓練時有中央控制器,中央統一收集資訊幫助 agents 訓練,訓練結束后就由各自的策略網路作決策,不再需要中央控制器,
下面以比較常用的 Actor-Critic 來介紹多智能體強化學習的實作細節,
13.5 不完全觀測
Partial Observation.在多智能體強化學習中,通常假設智能體是不完全觀測的,即只能觀測到區域狀態,不能觀測到全域的狀態,
- 把 \(agent^i\) 觀測到的狀態記為 \(o^i\),在不完全觀測時, \(o^i\neq s\)
- 完全觀測時,\(o^1=...=o^n=s\)
13.6 完全去中心化
每個 agent 獨立與環境進行互動,獨立訓練自己的策略網路,跟之前的單智能體強化學習基本相同,訓練結束后,每個 agent 用自己的策略網路來作決策,把觀測到的 \(o^i\) 輸入,輸出動作的概率分布,抽樣得到動作并執行 \(a^i\),

本質還是單智能體強化學習,而不是多智能體強化學習;
如何用去中心化實作 Actor-Critic ?
- 每個 agent 上都搭載了計算設備,如 CPU、GPU;
- 在每個 agent 上都部署策略網路 Actor \(\pi(a^i|o^i;\theta^i)\) 和價值網路 Critic \(q(o^i,a^i;w^i)\) ;訓練思路與此前的 Actor-Critic 相同,
- agent 獨立運行,不做通信;
- 但 agents 之間的聯系不能忽略,這樣做效果不好,
13.7 完全中心化
-
n 個 agents 與環境互動,將觀測到的 狀態和獎勵 都上報給 中央控制器,由中央的策略網路來作決策,中央把決策發給每個 agent ,
-
agents上面沒有策略網路,不能自己作決策,只聽中央控制器的,
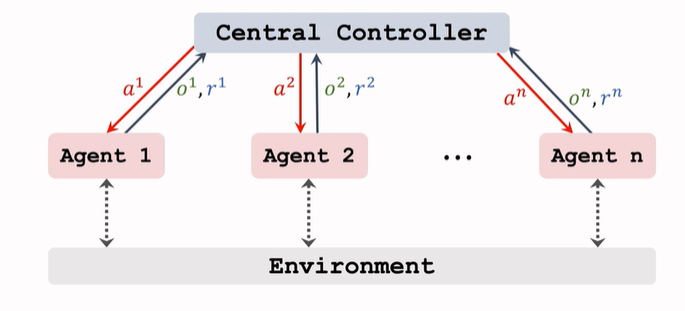
-
訓練也是在中央控制器進行,用所有觀測到的的狀態和獎勵來訓練策略網路,
-
執行時,也需要中央控制器訓練出的 n 個策略網路,網路結構相同,具體引數可能不同,
由于輸入需要時所有的狀態,所以策略網路不能部署到具體的agent,只能放在中央控制器,
如何用中心化實作 Actor-Critic ?
- 中央控制器接收到 所有的動作 \(a\) 和 狀態 \(o\),以及所有的獎勵;
- 中央控制器上有 n 個策略網路和 n 個價值網路,對應 n 個agents;
- 策略網路 \(\pi(a^i|o_{all};\theta^i)\),輸入是所有的觀測值 o,輸出是動作概率值;通過概率抽樣執行動作;
- 價值網路 \(q(o,a;w^i)\),評價對應的策略網路的決策好壞;
- 用策略梯度演算法來訓練策略網路;
- 用 TD演算法 訓練 價值網路;
- 結束訓練后,中央控制器用策略網路來作決策:
- agents 上報 狀態\(o_{all}\),中央輸入 策略網路,抽樣得到動作 \(a^i\)
- 把 \(a^i\) 傳達到 第 i 個 agent,命令其執行;
中心化的好處是收集全域的資訊,可以面向所有 agents 做出好的決策,但缺點主要在于執行速度慢,無法做到實時決策,
13.8 中心化訓練 & 去中心化執行
- 每個 agent 都有策略網路,訓練的時候使用 13.7 中心化訓練的方式,執行時不需要中央控制器,用自己的策略網路,基于區域觀測來做出決策,
- 這個方式目前比較流行,模型也有很多種,下面介紹一種 Actor-Critic 方法:
- 參考文獻:
- Multi-agent actor-critic for mixed cooperative-competitive environments
- Counterfactual multi-agent policy gradients
- 每個agent上都布置自己的策略網路 \(\pi(a^i|o^i;\theta^i)\),輸入是agent自己的區域觀測 狀態 \(o^i\) ,不依賴其他 agents,
- 中央控制器上有 n 個價值網路 \(q(o,a;w^i)\),對對應的策略網路進行評價,幫助訓練策略網路;輸入是所有的動作和狀態;價值網路的結構相同,但是引數不同;
- 訓練時中央控制器收集所有的觀測、動作和獎勵;
- 完成訓練,每個 agent 獨立作決策,
- 參考文獻:

訓練方式:
-
中央控制器上訓練的價值網路,使用TD演算法進行更新,輸入:
- \(a=[a^1,a^2,...,a^n]\)
- \(o=[o^1,o^2,...,o^n]\)
- 注意,只需一個獎勵 \(r^i\)
輸出用TD演算法擬合 TD target,即為 \(q^i\).
-
agent 端訓練的策略網路在中央控制器的價值網路提供的 q 下進行訓練;輸入為:
- \(a^i\)、\(o^i\)、\(q^i\)
- 不需要其他 agents 的資訊,
用策略梯度演算法 更新 \(\theta_i\);
執行程序:

不再需要中央控制器,只基于各自的區域觀測與策略網路來做出決策,
13.9 引數共享
在本文舉例的 Actor-Critic 中,有:
- n個策略網路:\(\pi(a^i|o^i;\theta^i)\)
- n個價值網路:\(q(o,a;w^i)\)
- 訓練的引數是 \(\theta,w\)
- 第 i 和第 j 兩個神經網路,共享引數的意思是,\(\theta^i=\theta^j,w^i=w^j\)
- 是否共享引數取決于情境
- 功能不同的 agents 之間不能共享:如足球機器人
- 功能相同的 agents 之間可以共享:如無人車
13.10 總結
| 學習方式 | 策略網路(actor) | 價值網路(critic) |
|---|---|---|
| 完全去中心化 | \(\pi(a^i,o^i;\theta^i)\) | \(q(o^i,a^i;w^i)\) |
| 完全中心化 | \(\pi(a^i,o;\theta^i)\) | \(q(o,a;w^i)\) |
| 中心化訓練 & 去中心化執行 | \(\pi(a^i,o^i;\theta^i)\) | \(q(o,a;w^i)\) |
看似一樣,不同的是全域與區域,
x. 參考教程
- 視頻課程:深度強化學習(全)_嗶哩嗶哩_bilibili
- 視頻原地址:https://www.youtube.com/user/wsszju
- 課件地址:https://github.com/wangshusen/DeepLearning
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/498750.html
標籤:其他