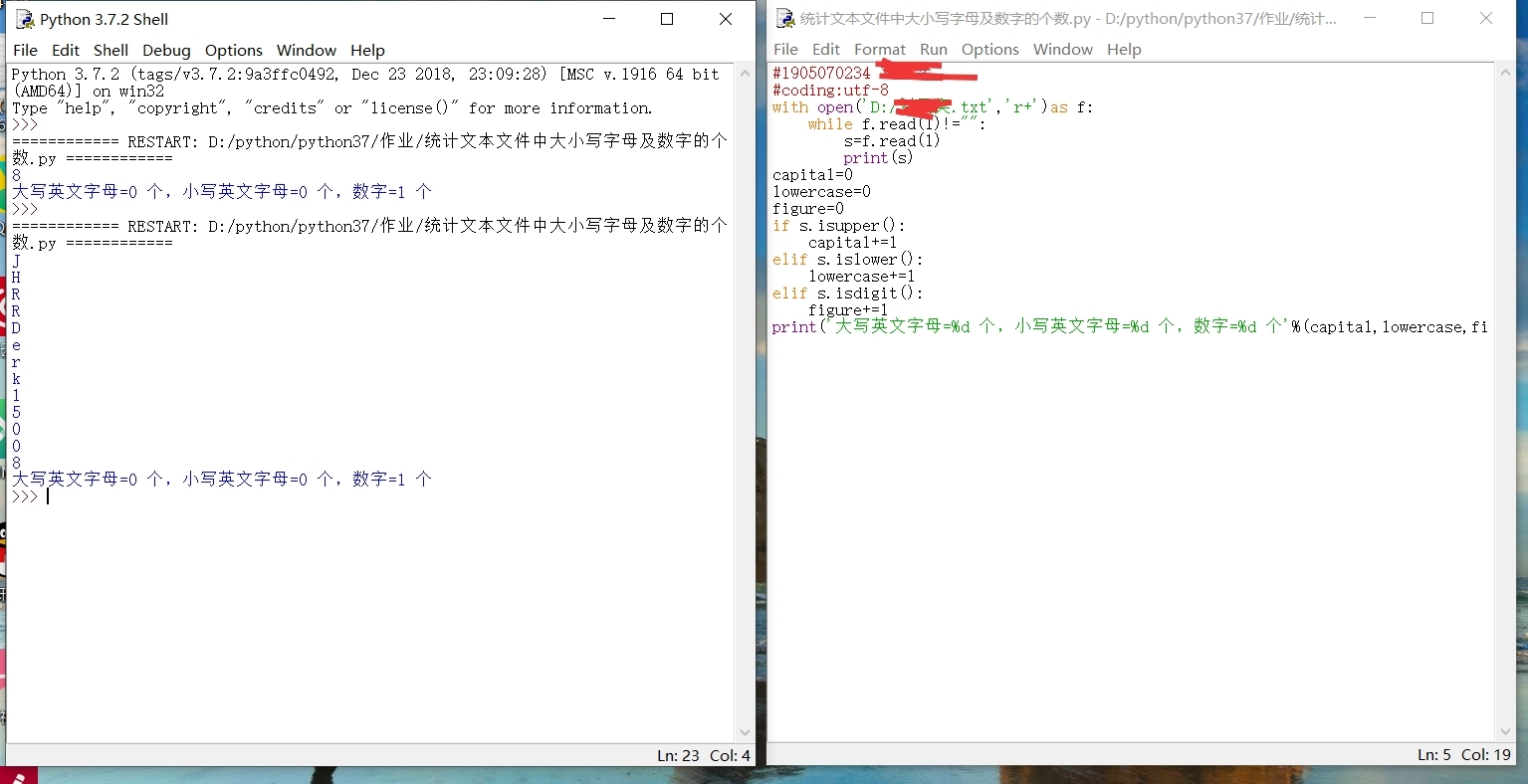
我想知道這個統計文本檔案大小寫字母及數字個數的程式錯誤在哪,實在是找不到邏輯錯在哪,求大佬幫忙指出改正,謝謝
uj5u.com熱心網友回復:
1. 變數的初始化放在程式的開頭2. 字符型別的判斷放在while的回圈體內
3. f.read()讀一次就放進變數s里,不要在一個回圈里讀兩次
uj5u.com熱心網友回復:
你寫的只是判斷了最后一個是什么,要放在回圈體內判斷才對uj5u.com熱心網友回復:
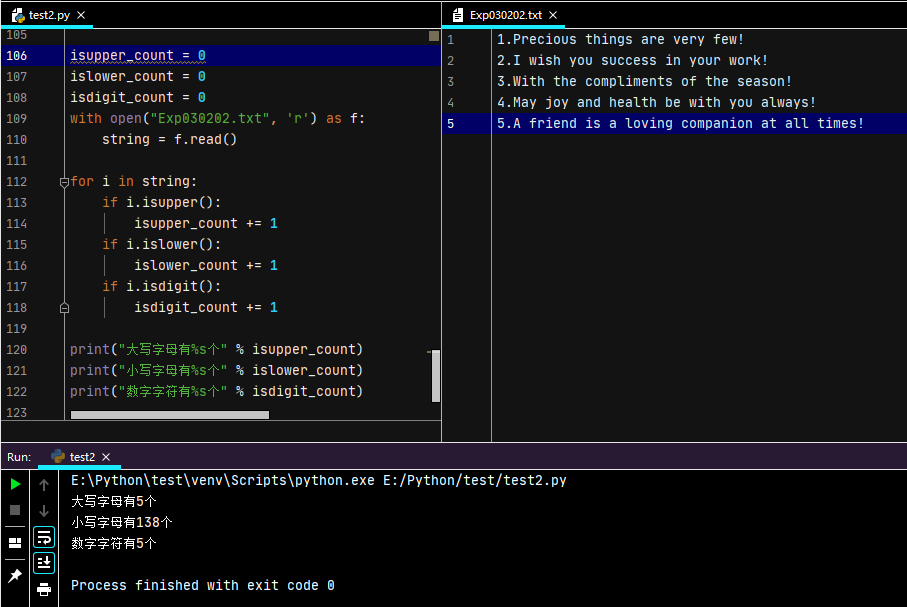
"""適合小打開小檔案"""
isupper_count = 0
islower_count = 0
isdigit_count = 0
with open("Exp030202.txt", 'r') as f:
string = f.read()
for i in string:
if i.isupper():
isupper_count += 1
if i.islower():
islower_count += 1
if i.isdigit():
isdigit_count += 1
print("大寫字母有%s個" % isupper_count)
print("小寫字母有%s個" % islower_count)
print("數字字符有%s個" % isdigit_count)
uj5u.com熱心網友回復:
了解了,謝謝你
uj5u.com熱心網友回復:
謝謝,已改正
uj5u.com熱心網友回復:
謝謝你的代碼,很清晰
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/49891.html