概述
- 哈希表是一種可以滿足快速查找資料結構,時間復雜度接近O(1),
- 哈希函式是無限集到有限集的映射,
- 處理資料量大,查找效率要求高時推薦使用hash容器,
- 問題:
- 什么情況下考慮使用哈希容器?
- 常用的哈希思路有哪些?
- 評判哈希演算法標準有哪些?
- 哈希沖突是如何產生的?如何解決?
- 如何構造一個hash演算法?應注意哪些問題?
評判哈希演算法標準
- 效率高,
- 映射分布均勻,
基礎hash思路
直接尋址法:
取關鍵字key,使用線性函式 Hash(key) = a * key + b,
數字分析法:
在一個班級里,同齡學生很多,在取學生年齡作為key時,應避免以年份作為key組成部分,
平方取中法:
key取平方,截取中間的幾位作為新的key,數學計算的性質乘積中間幾位和乘數每一位都有關,充分混合key每一位對生成的哈希值的影響,使映射分布更均勻,
取余法:
Hash(key) = key % m
相乘取整法:
Hash(key) = floor(frac(key * A), m), 0<A<1
- floor 取整,frac 取小數
- 此法避免像除余法中結果對m過于依賴,
亂數法
Hash(key) = rand(key)
- 據我所知C#的object采用此方法,使用元資料中的幾位存hash值,
折疊法:
將關鍵字按固定長度分成幾段然后相加,
- 如:Hash(1234,m = 2) = 46,
- 關鍵字較長時可以考慮使用此方法,
哈希沖突
產生原因
由于哈希函式是無限集到有限集的映射,換而言之,有限集的元素對應n個無限集的元素,哈希碰撞是不可避免的,
解決辦法
開放地址法
當關鍵字key的哈希地址p=H(key)出現沖突時,遞回呼叫p = Hi(p)直到沒有沖突,
Hi=(H(key)+di)Hi=(H(key)+di) % m ??i=1,2,,3....,ni=1,2,,3....,n
- H(key) 為哈希函式
- m 為表長
- di 為增量序列
根據增量序列di的不同,又分為:
- 線性探測:di = 1,2,3,......
- 二次探測: di = ±1^2, ±2^2,.......
- 隨機探測: di = random(di,seed)
- random 為 無狀態的偽隨機發生函式(所謂無狀態,即無論多少次呼叫,random(a) = b不變)
- seed 一個確定不變的亂數種子
鏈式地址法
結構示意
pos1
pos2 -> val -> val
pos3 -> val
pos4
...
無限集映射到有限集,有限集的每個元素對應一個鏈表,鏈表存盤無限集映射到有限集的n個元素,
再哈希法
Hi=RHi(key)i=1,2,…,k
遞回呼叫哈希函式序列中的函式,直到沒有沖突,
建立公共溢位區法
建立溢位鏈表,如發生哈希碰撞,則使用溢位鏈表,
哈希沖突解決方法優缺點分析
開放散列:鏈式地址法(桶鏈法)
- 優點:
- 添加洗掉方便,避免動態調整開銷
- 桶鏈表記憶體動態分配,減少記憶體浪費
- 當哈希表size很大時,指標的性能消耗可以忽略
- 缺點:
- 動態分配記憶體,記憶體不緊湊,隨機訪問性差,序列化性能差,
- 對于預先知道所有元素,可以實作沒有沖突的完美hash函式,此時效率會遠低于封閉散列,
封閉散列:開放地址法,再哈希法 ...
- 優點:
- 記憶體緊湊,隨機訪問性能好,序列化性能好,
- 預先知道所有元素e,可以實作完美hash函式,此時效率遠高于開放散列,
- 缺點:
- 所有條目數量不能超過陣列的長度,擴容/收緊頻繁,性能消耗大,
- 碰撞探測消耗性能,
- 當陣列長度很大時,有記憶體浪費,
哈希演算法進階實體分析
這是取自lua5.4的
-- lua 5.4
unsigned int luaS_hash (const char *str, size_t l, unsigned int seed,
size_t step) {
unsigned int h = seed ^ cast_uint(l);
for (; l >= step; l -= step)
h ^= ((h<<5) + (h>>2) + cast_byte(str[l - 1]));
return h;
}
#define lmod(s,size) \
(check_exp((size&(size-1))==0, (cast_int((s) & ((size)-1)))))
(h << 5) + (h >> 2)
= (((h << 5) << 2) + ((h >> 2) << 2) >> 2)
= ((h << 7) + h) >> 2
= (129 * h) >> 2
-
和偽亂數生成演算法一樣,要讓生成的數盡量隨機--二進制數的每一個位取0或1的概率都是50%,
-
移位,異或運算充分混合每一位的影響,而加法運算引起多個位的反轉,使hash值的每一個位更加不可預測,以接近不可逆的單向函式,
-
(h << 5) + (h >> 2) = (129 * h) >> 2, 乘法可以被拆分為加法和移位的組合(即(h << 7)+h ),以混合哈希值,不過(h << 7 - h) = 127h 會更好些,127是梅森素數(2^n -1),與線性同余演算法(LCG)生成偽亂數一樣,梅森素數127,只需一次移位運算和一次加法運算,且不會被分解,亂數分布更加均勻,
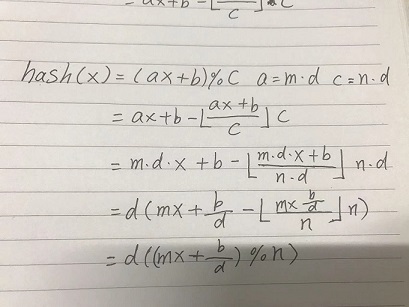
- 非素數會被分解成更小的素數的乘積,參與運算時容易被分解,上例中a和c可以提取公因數d,周期 = n = c/d,
-
a%b = a&(b-1) 當 b = 2^n 時等式成立,lua哈希表的長度保證符合等式成立的條件,lmod使用位運算代替取余運算,效率更高,
-
演算法實際應用詳情請參考我的文章
- 跳轉鏈接: Lua5.4原始碼剖析:二. 詳解String資料結構及操作演算法
進階哈希演算法
下面是一些進階哈希演算法的思路,需要花費一些時間學習,
- 跳轉鏈接:進階哈希演算法
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/499072.html
標籤:其他
上一篇:資料結構——光纖網路設計