Overview [1]
kubernetes集群中的調度程式 kube-scheduler 會 watch 未分配節點的新創建的Pod,并未該Pod找到可運行的最佳(特定)節點,那么這些動作或者說這些原理是怎么實作的呢,讓我們往下剖析下,
對于新創建的 pod 或其他未調度的 pod來講,kube-scheduler 選擇一個最佳節點供它們運行,但是,Pod 中的每個容器對資源的要求都不同,每個 Pod 也有不同的要求,因此,需要根據具體的調度要求對現有節點進行過濾,
在Kubernetes集群中,滿足 Pod 調度要求的節點稱為可行節點 ( feasible nodes FN) ,如果沒有合適的節點,則 pod 將保持未調度狀態,直到調度程式能夠放置它,也就是說,當我們創建Pod時,如果長期處于 Pending 狀態,這個時候應該看你的集群調度器是否因為某些問題沒有合適的節點了
調度器為 Pod 找到 FN 后,然后運行一組函式對 FN 進行評分,并在 FN 中找到得分最高的節點來運行 Pod,
調度策略在決策時需要考慮的因素包括個人和集體資源需求、硬體/軟體/策略約束 (constraints)、親和性 (affinity) 和反親和性( anti-affinity )規范、資料區域性、作業負載間干擾等,
如何為pod選擇節點?
kube-scheduler 為pod選擇節點會分位兩部:
- 過濾 (
Filtering) - 打分 (
Scoring)
過濾也被稱為預選 (Predicates),該步驟會找到可調度的節點集,然后通過是否滿足特定資源的請求,例如通過 PodFitsResources 過濾器檢查候選節點是否有足夠的資源來滿足 Pod 資源的請求,這個步驟完成后會得到一個包含合適的節點的串列(通常為多個),如果串列為空,則Pod不可調度,
打分也被稱為優選(Priorities),在該步驟中,會對上一個步驟的輸出進行打分,Scheduer 通過打分的規則為每個通過 Filtering 步驟的節點計算出一個分數,
完成上述兩個步驟之后,kube-scheduler 會將Pod分配給分數最高的 Node,如果存在多個相同分數的節點,會隨機選擇一個,
kubernetes的調度策略
Kubernetes 1.21之前版本可以在代碼 kubernetes\pkg\scheduler\algorithmprovider\registry.go 中看到對應的注冊模式,在1.22 scheduler 更換了其路徑,對于registry檔案更換到了kubernetes\pkg\scheduler\framework\plugins\registry.go ;對于kubernetes官方說法為,調度策略是用于“預選” (Predicates )或 過濾(filtering ) 和 用于 優選(Priorities)或 評分 (scoring)的
注:kubernetes官方沒有找到預選和優選的概念,而Predicates和filtering 是處于預選階段的動詞,而Priorities和scoring是優選階段的動詞,后面用PF和PS代替這個兩個詞,
為Pod預選節點 [2]
上面也提到了,filtering 的目的是為了排除(過濾)掉不滿足 Pod 要求的節點,例如,某個節點上的閑置資源小于 Pod 所需資源,則該節點不會被考慮在內,即被過濾掉,在 “Predicates” 階段實作的 filtering 策略,包括:
NoDiskConflict:評估是否有合適Pod請求的卷NoVolumeZoneConflict:在給定zone限制情況下,評估Pod請求所需的卷在Node上是否可用PodFitsResources:檢查空閑資源(CPU、記憶體)是否滿足Pod請求PodFitsHostPorts:檢查Pod所需埠在Node上是否被占用HostName: 過濾除去,PodSpec中NodeName欄位中指定的Node之外的所有Node,MatchNodeSelector:檢查Node的 label 是否與 Pod 配置中nodeSelector欄位中指定的 label 匹配,并且從 Kubernetes v1.2 開始, 如果存在nodeAffinity也會匹配,CheckNodeMemoryPressure:檢查是否可以在已出現記憶體壓力情況節點上調度 Pod,CheckNodeDiskPressure:檢查是否可以在報告磁盤壓力情況的節點上調度 Pod
具體對應得策略可以在 kubernetes\pkg\scheduler\framework\plugins\registry.go 看到
對預選節點打分 [2]
通過上面步驟過濾過得串列則是適合托管的Pod,這個結果通常來說是一個串列,如何選擇最優Node進行調度,則是接下來打分的步驟步驟,
例如:Kubernetes對剩余節點進行優先級排序,優先級由一組函式計算;優先級函式將為剩余節點給出從0~10 的分數,10 表示最優,0 表示最差,每個優先級函式由一個正數加權組成,每個Node的得分是通過將所有加權得分相加來計算的,設有兩個優先級函式,priorityFunc1 和 priorityFunc2 加上權重因子 weight1 和weight2,那么這個Node的最終得分為:\(finalScore = (w1 \times priorityFunc1) + (w2 \times priorityFunc2)\),計算完分數后,選擇最高分數的Node做為Pod的宿主機,存在多個相同分數Node情況下會隨機選擇一個Node,
目前kubernetes提供了一些在打分 Scoring 階段演算法:
LeastRequestedPriority:Node的優先級基于Node的空閑部分\(\frac{capacity\ -\ Node上所有存在的Pod\ -\ 正在調度的Pod請求}{capacity}\),通過計算具有最高分數的Node是FNBalancedResourceAllocation:該演算法會將 Pod 放在一個Node上,使得在Pod 部署后 CPU 和記憶體的使用率為平衡的SelectorSpreadPriority:通過最小化資源方式,將屬于同一種服務、控制器或同一Node上的Replica的 Pod的數量來分布Pod,如果節點上存在Zone,則會調整優先級,以便 pod可以分布在Zone之上,CalculateAntiAffinityPriority:根據label來分布,按照相同service上相同label值的pod進行分配ImageLocalityPriority:根據Node上鏡像進行打分,Node上存在Pod請求所需的鏡像優先級較高,
在代碼中查看上述的代碼
以 PodFitsHostPorts 演算法為例,因為是Node類演算法,在kubernetes\pkg\scheduler\framework\plugins\nodeports
調度框架 [3]
調度框架 (scheduling framework SF ) 是kubernetes為 scheduler設計的一個pluggable的架構,SF 將scheduler設計為 Plugin 式的 API,API將上一章中提到的一些列調度策略實作為 Plugin,
在 SF 中,定義了一些擴展點 (extension points EP ),而被實作為Plugin的調度程式將被注冊在一個或多個 EP 中,換句話來說,在這些 EP 的執行程序中如果注冊在多個 EP 中,將會在多個 EP 被呼叫,
每次調度都分為兩個階段,調度周期(Scheduling Cycel)與系結周期(Binding Cycle),
- SC 表示為,為Pod選擇一個節點;SC 是串行運行的,
- BC 表示為,將 SC 決策結果應用于集群中;BC 可以同時運行,
調度周期與系結周期結合一起,被稱為調度背景關系 (Scheduling Context),下圖則是調度背景關系的作業流
注:如果決策結果為Pod的調度結果無可用節點,或存在內部錯誤,則中止 SC 或 BC,Pod將重入佇列重試
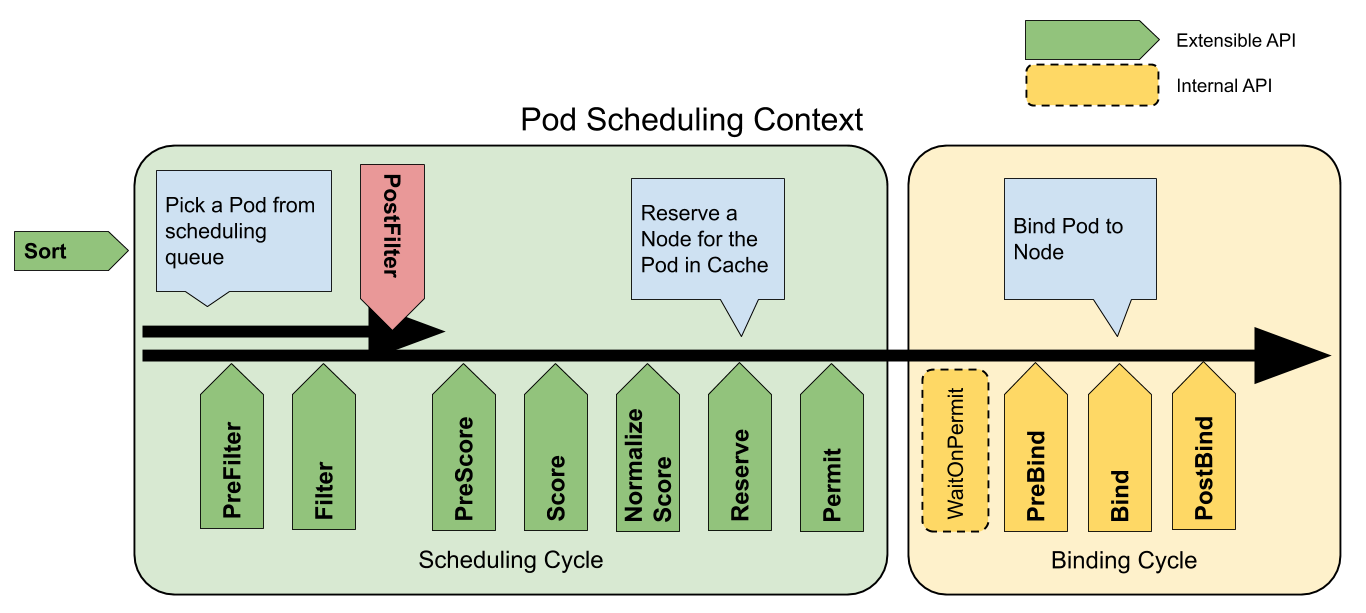
擴展點 [4]
擴展點(Extension points)是指在調度背景關系中的每個可擴展API,通過圖提現為[圖1],其中 Filter 相當于 Predicate 而 Scoring 相當于 Priority,
對于調度階段會通過以下擴展點:
-
Sort:該插件提供了排序功能,用于對在調度佇列中待處理 Pod 進行排序,一次只能啟用一個佇列排序, -
preFilter:該插件用于在過濾之前預處理或檢查 Pod 或集群的相關資訊,這里會終止調度 -
filter:該插件相當于調度背景關系中的Predicates,用于排除不能運行 Pod 的節點,Filter 會按配置的順序進行呼叫,如果有一個filter將節點標記位不可用,則將 Pod 標記為不可調度(即不會向下執行), -
postFilter:當沒有為 pod 找到FN時,該插件會按照配置的順序進行呼叫,如果任何postFilter插件將 Pod 標記為schedulable,則不會呼叫其余插件,即filter成功后不會進行這步驟 -
preScore:可用于進行預Score作業(通知性的擴展點), -
score:該插件為每個通過filter階段的Node提供打分服務,然后Scheduler將選擇具有最高加權分數總和的Node, -
reserve:因為系結事件時異步發生的,該插件是為了避免Pod在系結到節點前時,調度到新的Pod,使節點使用資源超過可用資源情況,如果后續階段發生錯誤或失敗,將觸發UnReserve回滾(通知性擴展點),這也是作為調度周期中最后一個狀態,要么成功到postBind,要么失敗觸發UnReserve, -
permit:該插件可以阻止或延遲 Pod 的系結,一般情況下這步驟會做三件事:appove:調度器繼續系結程序Deny:如果任何一個Premit拒絕了Pod與節點的系結,那么將觸發UnReserve,并重入佇列Wait: 如果 Permit 插件回傳Wait,該 Pod 將保留在內部WaitPod 串列中,直到被Appove,如果發生超時,wait變為deny,將Pod放回至調度佇列中,并觸發Unreserve回滾 ,
-
preBind:該插件用于在 bind Pod 之前執行所需的前置作業,如,preBind可能會提供一個網路卷并將其掛載到目標節點上,如果在該步驟中的任意插件回傳錯誤,則Pod 將被deny并放置到調度佇列中, -
bind:在所有的preBind完成后,該插件將用于將Pod系結到Node,并按順序呼叫系結該步驟的插件,如果有一個插件處理了這個事件,那么則忽略其余所有插件, -
postBind:該插件在系結 Pod 后呼叫,可用于清理相關資源(通知性的擴展點), -
multiPoint:這是一個僅配置欄位,允許同時為所有適用的擴展點啟用或禁用插件,
kube-scheduler作業流分析
對于 kube-scheduler 組件的分析,包含 kube-scheduler 啟動流程,以及scheduler調度流程,這里會主要針對啟動流程分析,后面演算法及二次開發部分會切入調度分析,
對于我們部署時使用的 kube-scheduler 位于 cmd/kube-scheduler ,在 Alpha (1.16) 版本提供了調度框架的模式,到 Stable (1.19) ,從代碼結構上是相似的;直到1.22后改變了代碼風格,
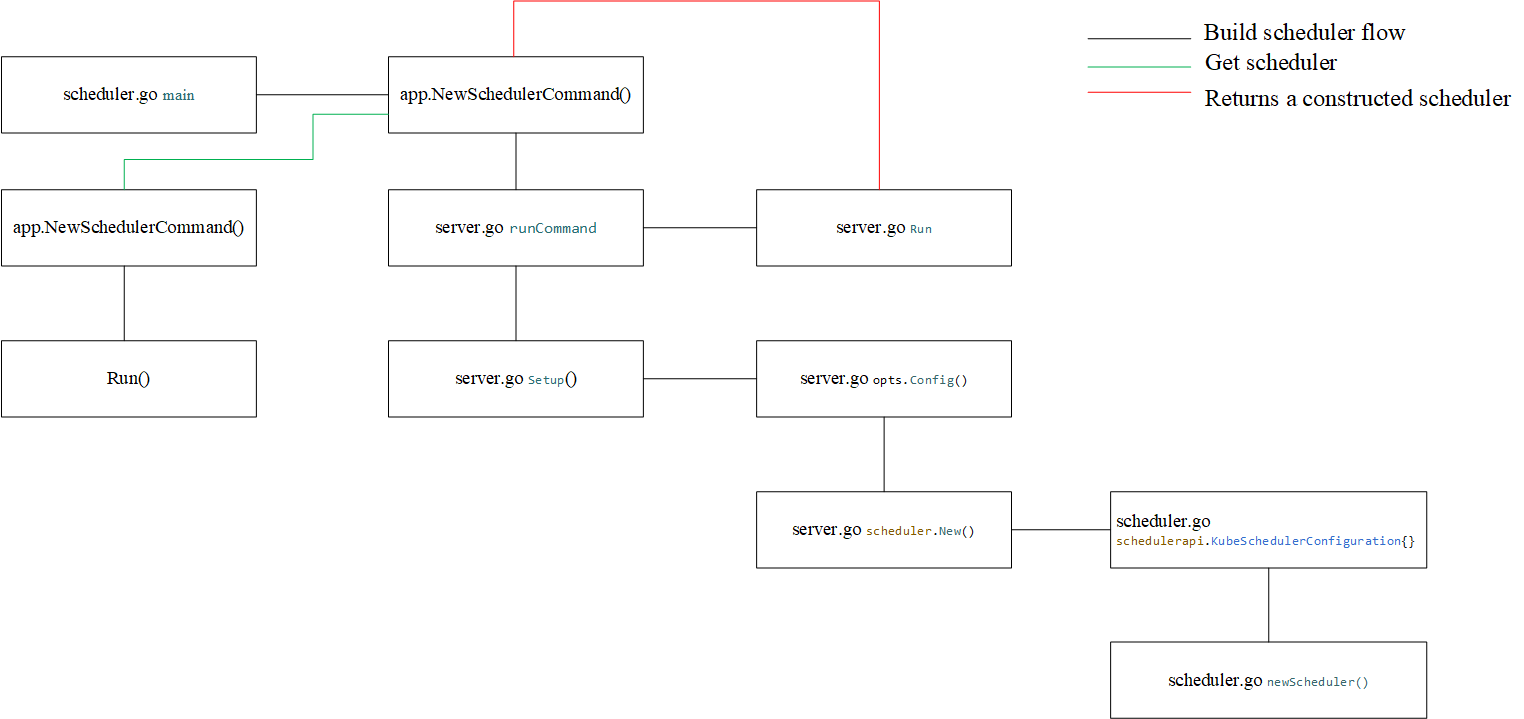
首先看到的是 kube-scheduler 的入口 cmd/kube-scheduler ,這里主要作為兩部分,構建引數與啟動server ,這里嚴格來講 kube-scheduer 是作為一個server,而調度框架等部分是另外的,
func main() {
command := app.NewSchedulerCommand()
code := cli.Run(command)
os.Exit(code)
}
cli.Run 提供了cobra構成的命令列cli,日志將輸出為標準輸出
// 這里是main中執行的Run
func Run(cmd *cobra.Command) int {
if logsInitialized, err := run(cmd); err != nil {
if !logsInitialized {
fmt.Fprintf(os.Stderr, "Error: %v\n", err)
} else {
klog.ErrorS(err, "command failed")
}
return 1
}
return 0
}
// 這個run作為
func run(cmd *cobra.Command) (logsInitialized bool, err error) {
rand.Seed(time.Now().UnixNano())
defer logs.FlushLogs()
cmd.SetGlobalNormalizationFunc(cliflag.WordSepNormalizeFunc)
if !cmd.SilenceUsage {
cmd.SilenceUsage = true
cmd.SetFlagErrorFunc(func(c *cobra.Command, err error) error {
// Re-enable usage printing.
c.SilenceUsage = false
return err
})
}
// In all cases error printing is done below.
cmd.SilenceErrors = true
// This is idempotent.
logs.AddFlags(cmd.PersistentFlags())
// Inject logs.InitLogs after command line parsing into one of the
// PersistentPre* functions.
switch {
case cmd.PersistentPreRun != nil:
pre := cmd.PersistentPreRun
cmd.PersistentPreRun = func(cmd *cobra.Command, args []string) {
logs.InitLogs()
logsInitialized = true
pre(cmd, args)
}
case cmd.PersistentPreRunE != nil:
pre := cmd.PersistentPreRunE
cmd.PersistentPreRunE = func(cmd *cobra.Command, args []string) error {
logs.InitLogs()
logsInitialized = true
return pre(cmd, args)
}
default:
cmd.PersistentPreRun = func(cmd *cobra.Command, args []string) {
logs.InitLogs()
logsInitialized = true
}
}
err = cmd.Execute()
return
}
可以看到最終是呼叫 command.Execute() 執行,這個是執行本身構建的命令,而真正被執行的則是上面的 app.NewSchedulerCommand() ,那么來看看這個是什么
app.NewSchedulerCommand() 構建了一個cobra.Commond物件, runCommand() 被封裝在內,這個是作為啟動scheduler的函式
func NewSchedulerCommand(registryOptions ...Option) *cobra.Command {
opts := options.NewOptions()
cmd := &cobra.Command{
Use: "kube-scheduler",
Long: `The Kubernetes scheduler is a control plane process which assigns
Pods to Nodes. The scheduler determines which Nodes are valid placements for
each Pod in the scheduling queue according to constraints and available
resources. The scheduler then ranks each valid Node and binds the Pod to a
suitable Node. Multiple different schedulers may be used within a cluster;
kube-scheduler is the reference implementation.
See [scheduling](https://kubernetes.io/docs/concepts/scheduling-eviction/)
for more information about scheduling and the kube-scheduler component.`,
RunE: func(cmd *cobra.Command, args []string) error {
return runCommand(cmd, opts, registryOptions...)
},
Args: func(cmd *cobra.Command, args []string) error {
for _, arg := range args {
if len(arg) > 0 {
return fmt.Errorf("%q does not take any arguments, got %q", cmd.CommandPath(), args)
}
}
return nil
},
}
nfs := opts.Flags
verflag.AddFlags(nfs.FlagSet("global"))
globalflag.AddGlobalFlags(nfs.FlagSet("global"), cmd.Name(), logs.SkipLoggingConfigurationFlags())
fs := cmd.Flags()
for _, f := range nfs.FlagSets {
fs.AddFlagSet(f)
}
cols, _, _ := term.TerminalSize(cmd.OutOrStdout())
cliflag.SetUsageAndHelpFunc(cmd, *nfs, cols)
if err := cmd.MarkFlagFilename("config", "yaml", "yml", "json"); err != nil {
klog.ErrorS(err, "Failed to mark flag filename")
}
return cmd
}
下面來看下 runCommand() 在啟動 scheduler 時提供了什么功能,
在新版中已經沒有 algorithmprovider 的概念,所以在 runCommand 中做的也就是僅僅啟動這個 scheduler ,而 scheduler 作為kubernetes組件,也是會watch等操作,自然少不了informer,其次作為和 controller-manager 相同的作業特性,kube-scheduler 也是 基于Leader選舉的,
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
// To help debugging, immediately log version
klog.InfoS("Starting Kubernetes Scheduler", "version", version.Get())
klog.InfoS("Golang settings", "GOGC", os.Getenv("GOGC"), "GOMAXPROCS", os.Getenv("GOMAXPROCS"), "GOTRACEBACK", os.Getenv("GOTRACEBACK"))
// Configz registration.
if cz, err := configz.New("componentconfig"); err == nil {
cz.Set(cc.ComponentConfig)
} else {
return fmt.Errorf("unable to register configz: %s", err)
}
// Start events processing pipeline.
cc.EventBroadcaster.StartRecordingToSink(ctx.Done())
defer cc.EventBroadcaster.Shutdown()
// Setup healthz checks.
var checks []healthz.HealthChecker
if cc.ComponentConfig.LeaderElection.LeaderElect {
checks = append(checks, cc.LeaderElection.WatchDog)
}
waitingForLeader := make(chan struct{})
isLeader := func() bool {
select {
case _, ok := <-waitingForLeader:
// if channel is closed, we are leading
return !ok
default:
// channel is open, we are waiting for a leader
return false
}
}
// Start up the healthz server.
if cc.SecureServing != nil {
handler := buildHandlerChain(newHealthzAndMetricsHandler(&cc.ComponentConfig, cc.InformerFactory, isLeader, checks...), cc.Authentication.Authenticator, cc.Authorization.Authorizer)
// TODO: handle stoppedCh and listenerStoppedCh returned by c.SecureServing.Serve
if _, _, err := cc.SecureServing.Serve(handler, 0, ctx.Done()); err != nil {
// fail early for secure handlers, removing the old error loop from above
return fmt.Errorf("failed to start secure server: %v", err)
}
}
// Start all informers.
cc.InformerFactory.Start(ctx.Done())
// DynInformerFactory can be nil in tests.
if cc.DynInformerFactory != nil {
cc.DynInformerFactory.Start(ctx.Done())
}
// Wait for all caches to sync before scheduling.
cc.InformerFactory.WaitForCacheSync(ctx.Done())
// DynInformerFactory can be nil in tests.
if cc.DynInformerFactory != nil {
cc.DynInformerFactory.WaitForCacheSync(ctx.Done())
}
// If leader election is enabled, runCommand via LeaderElector until done and exit.
if cc.LeaderElection != nil {
cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{
OnStartedLeading: func(ctx context.Context) {
close(waitingForLeader)
sched.Run(ctx)
},
OnStoppedLeading: func() {
select {
case <-ctx.Done():
// We were asked to terminate. Exit 0.
klog.InfoS("Requested to terminate, exiting")
os.Exit(0)
default:
// We lost the lock.
klog.ErrorS(nil, "Leaderelection lost")
klog.FlushAndExit(klog.ExitFlushTimeout, 1)
}
},
}
leaderElector, err := leaderelection.NewLeaderElector(*cc.LeaderElection)
if err != nil {
return fmt.Errorf("couldn't create leader elector: %v", err)
}
leaderElector.Run(ctx)
return fmt.Errorf("lost lease")
}
// Leader election is disabled, so runCommand inline until done.
close(waitingForLeader)
sched.Run(ctx)
return fmt.Errorf("finished without leader elect")
}
上面看到了 runCommend 是作為啟動 scheduler 的作業,那么通過引數構建一個 scheduler 則是在 Setup 中完成的,
// Setup creates a completed config and a scheduler based on the command args and options
func Setup(ctx context.Context, opts *options.Options, outOfTreeRegistryOptions ...Option) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) {
if cfg, err := latest.Default(); err != nil {
return nil, nil, err
} else {
opts.ComponentConfig = cfg
}
// 驗證引數
if errs := opts.Validate(); len(errs) > 0 {
return nil, nil, utilerrors.NewAggregate(errs)
}
// 構建一個config物件
c, err := opts.Config()
if err != nil {
return nil, nil, err
}
// 回傳一個config物件,包含了scheduler所需的配置,如informer,leader selection
cc := c.Complete()
outOfTreeRegistry := make(runtime.Registry)
for _, option := range outOfTreeRegistryOptions {
if err := option(outOfTreeRegistry); err != nil {
return nil, nil, err
}
}
recorderFactory := getRecorderFactory(&cc)
completedProfiles := make([]kubeschedulerconfig.KubeSchedulerProfile, 0)
// 創建出來的scheduler
sched, err := scheduler.New(cc.Client,
cc.InformerFactory,
cc.DynInformerFactory,
recorderFactory,
ctx.Done(),
scheduler.WithComponentConfigVersion(cc.ComponentConfig.TypeMeta.APIVersion),
scheduler.WithKubeConfig(cc.KubeConfig),
scheduler.WithProfiles(cc.ComponentConfig.Profiles...),
scheduler.WithPercentageOfNodesToScore(cc.ComponentConfig.PercentageOfNodesToScore),
scheduler.WithFrameworkOutOfTreeRegistry(outOfTreeRegistry),
scheduler.WithPodMaxBackoffSeconds(cc.ComponentConfig.PodMaxBackoffSeconds),
scheduler.WithPodInitialBackoffSeconds(cc.ComponentConfig.PodInitialBackoffSeconds),
scheduler.WithPodMaxInUnschedulablePodsDuration(cc.PodMaxInUnschedulablePodsDuration),
scheduler.WithExtenders(cc.ComponentConfig.Extenders...),
scheduler.WithParallelism(cc.ComponentConfig.Parallelism),
scheduler.WithBuildFrameworkCapturer(func(profile kubeschedulerconfig.KubeSchedulerProfile) {
// Profiles are processed during Framework instantiation to set default plugins and configurations. Capturing them for logging
completedProfiles = append(completedProfiles, profile)
}),
)
if err != nil {
return nil, nil, err
}
if err := options.LogOrWriteConfig(opts.WriteConfigTo, &cc.ComponentConfig, completedProfiles); err != nil {
return nil, nil, err
}
return &cc, sched, nil
}
上面了解到了 scheduler 是如何被構建出來的,下面就看看 構建時引數是如何傳遞進來的,而物件 option就是對應需要的配置結構,而 ApplyTo 則是將啟動時傳入的引數轉化為構建 scheduler 所需的配置,
對于Deprecated flags可以參考官方對于kube-scheduler啟動引數的說明 [5]
對于如何撰寫一個scheduler config請參考 [6] 與 [7]
func (o *Options) ApplyTo(c *schedulerappconfig.Config) error {
if len(o.ConfigFile) == 0 {
// 在沒有指定 --config時會找到 Deprecated flags:引數
// 通過kube-scheduler --help可以看到這些被棄用的引數
o.ApplyDeprecated()
o.ApplyLeaderElectionTo(o.ComponentConfig)
c.ComponentConfig = *o.ComponentConfig
} else {
// 這里就是指定了--config
cfg, err := loadConfigFromFile(o.ConfigFile)
if err != nil {
return err
}
// 這里會將leader選舉的引數附加到配置中
o.ApplyLeaderElectionTo(cfg)
if err := validation.ValidateKubeSchedulerConfiguration(cfg); err != nil {
return err
}
c.ComponentConfig = *cfg
}
if err := o.SecureServing.ApplyTo(&c.SecureServing, &c.LoopbackClientConfig); err != nil {
return err
}
if o.SecureServing != nil && (o.SecureServing.BindPort != 0 || o.SecureServing.Listener != nil) {
if err := o.Authentication.ApplyTo(&c.Authentication, c.SecureServing, nil); err != nil {
return err
}
if err := o.Authorization.ApplyTo(&c.Authorization); err != nil {
return err
}
}
o.Metrics.Apply()
// Apply value independently instead of using ApplyDeprecated() because it can't be configured via ComponentConfig.
if o.Deprecated != nil {
c.PodMaxInUnschedulablePodsDuration = o.Deprecated.PodMaxInUnschedulablePodsDuration
}
return nil
}
Setup 后會new一個 schedueler , New 則是這個動作,在里面可以看出,會初始化一些informer與 Pod的list等操作,
func New(client clientset.Interface,
informerFactory informers.SharedInformerFactory,
dynInformerFactory dynamicinformer.DynamicSharedInformerFactory,
recorderFactory profile.RecorderFactory,
stopCh <-chan struct{},
opts ...Option) (*Scheduler, error) {
stopEverything := stopCh
if stopEverything == nil {
stopEverything = wait.NeverStop
}
options := defaultSchedulerOptions // 默認調度策略,如percentageOfNodesToScore
for _, opt := range opts {
opt(&options) // opt 是傳入的函式,會回傳一個schedulerOptions即相應的一些配置
}
if options.applyDefaultProfile { // 這個是個bool型別,默認scheduler會到這里
// Profile包含了調度器的名稱與調度器在兩個程序中使用的插件
var versionedCfg v1beta3.KubeSchedulerConfiguration
scheme.Scheme.Default(&versionedCfg)
cfg := schedulerapi.KubeSchedulerConfiguration{} // 初始化一個配置,這個是--config傳入的型別,因為默認的調度策略會初始化
// convert 會將in轉為out即versionedCfg轉換為cfg
if err := scheme.Scheme.Convert(&versionedCfg, &cfg, nil); err != nil {
return nil, err
}
options.profiles = cfg.Profiles
}
registry := frameworkplugins.NewInTreeRegistry() // 調度框架的注冊
if err := registry.Merge(options.frameworkOutOfTreeRegistry); err != nil {
return nil, err
}
metrics.Register() // 指標類
extenders, err := buildExtenders(options.extenders, options.profiles)
if err != nil {
return nil, fmt.Errorf("couldn't build extenders: %w", err)
}
podLister := informerFactory.Core().V1().Pods().Lister()
nodeLister := informerFactory.Core().V1().Nodes().Lister()
// The nominator will be passed all the way to framework instantiation.
nominator := internalqueue.NewPodNominator(podLister)
snapshot := internalcache.NewEmptySnapshot()
clusterEventMap := make(map[framework.ClusterEvent]sets.String)
profiles, err := profile.NewMap(options.profiles, registry, recorderFactory, stopCh,
frameworkruntime.WithComponentConfigVersion(options.componentConfigVersion),
frameworkruntime.WithClientSet(client),
frameworkruntime.WithKubeConfig(options.kubeConfig),
frameworkruntime.WithInformerFactory(informerFactory),
frameworkruntime.WithSnapshotSharedLister(snapshot),
frameworkruntime.WithPodNominator(nominator),
frameworkruntime.WithCaptureProfile(frameworkruntime.CaptureProfile(options.frameworkCapturer)),
frameworkruntime.WithClusterEventMap(clusterEventMap),
frameworkruntime.WithParallelism(int(options.parallelism)),
frameworkruntime.WithExtenders(extenders),
)
if err != nil {
return nil, fmt.Errorf("initializing profiles: %v", err)
}
if len(profiles) == 0 {
return nil, errors.New("at least one profile is required")
}
podQueue := internalqueue.NewSchedulingQueue(
profiles[options.profiles[0].SchedulerName].QueueSortFunc(),
informerFactory,
internalqueue.WithPodInitialBackoffDuration(time.Duration(options.podInitialBackoffSeconds)*time.Second),
internalqueue.WithPodMaxBackoffDuration(time.Duration(options.podMaxBackoffSeconds)*time.Second),
internalqueue.WithPodNominator(nominator),
internalqueue.WithClusterEventMap(clusterEventMap),
internalqueue.WithPodMaxInUnschedulablePodsDuration(options.podMaxInUnschedulablePodsDuration),
)
schedulerCache := internalcache.New(durationToExpireAssumedPod, stopEverything)
// Setup cache debugger.
debugger := cachedebugger.New(nodeLister, podLister, schedulerCache, podQueue)
debugger.ListenForSignal(stopEverything)
sched := newScheduler(
schedulerCache,
extenders,
internalqueue.MakeNextPodFunc(podQueue),
MakeDefaultErrorFunc(client, podLister, podQueue, schedulerCache),
stopEverything,
podQueue,
profiles,
client,
snapshot,
options.percentageOfNodesToScore,
)
// 這個就是controller中onAdd等那三個必須的事件函式
addAllEventHandlers(sched, informerFactory, dynInformerFactory, unionedGVKs(clusterEventMap))
return sched, nil
}
接下來會啟動這個 scheduler, 在上面我們看到 NewSchedulerCommand 構建了一個cobra.Commond物件, runCommand() 最侄訓回傳個 Run,而這個Run就是啟動這個 sche 的,
下面這個 run 是 sche 的運行,他運行并watch資源,直到背景關系完成,
func (sched *Scheduler) Run(ctx context.Context) {
sched.SchedulingQueue.Run()
// We need to start scheduleOne loop in a dedicated goroutine,
// because scheduleOne function hangs on getting the next item
// from the SchedulingQueue.
// If there are no new pods to schedule, it will be hanging there
// and if done in this goroutine it will be blocking closing
// SchedulingQueue, in effect causing a deadlock on shutdown.
go wait.UntilWithContext(ctx, sched.scheduleOne, 0)
<-ctx.Done()
sched.SchedulingQueue.Close()
}
而呼叫這個 Run 的部分則是作為server的 kube-scheduler 中的 run
// Run executes the scheduler based on the given configuration. It only returns on error or when context is done.
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
// To help debugging, immediately log version
klog.InfoS("Starting Kubernetes Scheduler", "version", version.Get())
klog.InfoS("Golang settings", "GOGC", os.Getenv("GOGC"), "GOMAXPROCS", os.Getenv("GOMAXPROCS"), "GOTRACEBACK", os.Getenv("GOTRACEBACK"))
// Configz registration.
if cz, err := configz.New("componentconfig"); err == nil {
cz.Set(cc.ComponentConfig)
} else {
return fmt.Errorf("unable to register configz: %s", err)
}
// Start events processing pipeline.
cc.EventBroadcaster.StartRecordingToSink(ctx.Done())
defer cc.EventBroadcaster.Shutdown()
// Setup healthz checks.
var checks []healthz.HealthChecker
if cc.ComponentConfig.LeaderElection.LeaderElect {
checks = append(checks, cc.LeaderElection.WatchDog)
}
waitingForLeader := make(chan struct{})
isLeader := func() bool {
select {
case _, ok := <-waitingForLeader:
// if channel is closed, we are leading
return !ok
default:
// channel is open, we are waiting for a leader
return false
}
}
// Start up the healthz server.
if cc.SecureServing != nil {
handler := buildHandlerChain(newHealthzAndMetricsHandler(&cc.ComponentConfig, cc.InformerFactory, isLeader, checks...), cc.Authentication.Authenticator, cc.Authorization.Authorizer)
// TODO: handle stoppedCh and listenerStoppedCh returned by c.SecureServing.Serve
if _, _, err := cc.SecureServing.Serve(handler, 0, ctx.Done()); err != nil {
// fail early for secure handlers, removing the old error loop from above
return fmt.Errorf("failed to start secure server: %v", err)
}
}
// Start all informers.
cc.InformerFactory.Start(ctx.Done())
// DynInformerFactory can be nil in tests.
if cc.DynInformerFactory != nil {
cc.DynInformerFactory.Start(ctx.Done())
}
// Wait for all caches to sync before scheduling.
cc.InformerFactory.WaitForCacheSync(ctx.Done())
// DynInformerFactory can be nil in tests.
if cc.DynInformerFactory != nil {
cc.DynInformerFactory.WaitForCacheSync(ctx.Done())
}
// If leader election is enabled, runCommand via LeaderElector until done and exit.
if cc.LeaderElection != nil {
cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{
OnStartedLeading: func(ctx context.Context) {
close(waitingForLeader)
sched.Run(ctx)
},
OnStoppedLeading: func() {
select {
case <-ctx.Done():
// We were asked to terminate. Exit 0.
klog.InfoS("Requested to terminate, exiting")
os.Exit(0)
default:
// We lost the lock.
klog.ErrorS(nil, "Leaderelection lost")
klog.FlushAndExit(klog.ExitFlushTimeout, 1)
}
},
}
leaderElector, err := leaderelection.NewLeaderElector(*cc.LeaderElection)
if err != nil {
return fmt.Errorf("couldn't create leader elector: %v", err)
}
leaderElector.Run(ctx)
return fmt.Errorf("lost lease")
}
// Leader election is disabled, so runCommand inline until done.
close(waitingForLeader)
sched.Run(ctx)
return fmt.Errorf("finished without leader elect")
}
而上面的 server.Run 會被 runCommand 也就是在 NewSchedulerCommand 時被回傳,在 kube-scheduler 的入口檔案中被執行,
cc, sched, err := Setup(ctx, opts, registryOptions...)
if err != nil {
return err
}
return Run(ctx, cc, sched)
至此,整個 kube-scheduler 啟動流就分析完了,這個的流程可以用下圖表示
作者:鋼閘門Reference
[1] kube scheduler
[2] Scheduler Algorithm in Kubernetes
[3] scheduling framework
[4] permit
[5] kube-scheduler parmater
[6] kube-scheduler config.v1beta3/
[7] kube-scheduler config
出處:http://lc161616.cnblogs.com/ 本文著作權歸作者和博客園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連接,否則保留追究法律責任的權利, 阿里云優惠:點擊力享低價 墨墨學英語:幫忙點一下
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/499643.html
標籤:其他
上一篇:Flask send_file函式導致的絕對路徑遍歷
下一篇:5個開源組件管理小技巧