Scheduler結構
Scheduler 是整個 kube-scheduler 的一個 structure,提供了 kube-scheduler 運行所需的組件,
type Scheduler struct {
// Cache是一個抽象,會快取pod的資訊,作為scheduler進行查找,操作是基于Pod進行增加
Cache internalcache.Cache
// Extenders 算是調度框架中提供的調度插件,會影響kubernetes中的調度策略
Extenders []framework.Extender
// NextPod 作為一個函式提供,會阻塞獲取下一個ke'diao'du
NextPod func() *framework.QueuedPodInfo
// Error is called if there is an error. It is passed the pod in
// question, and the error
Error func(*framework.QueuedPodInfo, error)
// SchedulePod 嘗試將給出的pod調度到Node,
SchedulePod func(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (ScheduleResult, error)
// 關閉scheduler的信號
StopEverything <-chan struct{}
// SchedulingQueue保存要調度的Pod
SchedulingQueue internalqueue.SchedulingQueue
// Profiles中是多個調度框架
Profiles profile.Map
client clientset.Interface
nodeInfoSnapshot *internalcache.Snapshot
percentageOfNodesToScore int32
nextStartNodeIndex int
}
作為實際執行的兩個核心,SchedulingQueue ,與 scheduleOne 將會分析到這兩個
SchedulingQueue
在知道 kube-scheduler 初始化程序后,需要對 kube-scheduler 的整個 structure 和 workflow 進行分析
在 Run 中,運行的是 一個 SchedulingQueue 與 一個 scheduleOne ,從結構上看是屬于 Scheduler
func (sched *Scheduler) Run(ctx context.Context) {
sched.SchedulingQueue.Run()
// We need to start scheduleOne loop in a dedicated goroutine,
// because scheduleOne function hangs on getting the next item
// from the SchedulingQueue.
// If there are no new pods to schedule, it will be hanging there
// and if done in this goroutine it will be blocking closing
// SchedulingQueue, in effect causing a deadlock on shutdown.
go wait.UntilWithContext(ctx, sched.scheduleOne, 0)
<-ctx.Done()
sched.SchedulingQueue.Close()
}
SchedulingQueue 是一個佇列的抽象,用于存盤等待調度的Pod,該介面遵循類似于 cache.FIFO 和 cache.Heap 的模式,
type SchedulingQueue interface {
framework.PodNominator
Add(pod *v1.Pod) error
// Activate moves the given pods to activeQ iff they're in unschedulablePods or backoffQ.
// The passed-in pods are originally compiled from plugins that want to activate Pods,
// by injecting the pods through a reserved CycleState struct (PodsToActivate).
Activate(pods map[string]*v1.Pod)
// 將不可調度的Pod重入到佇列中
AddUnschedulableIfNotPresent(pod *framework.QueuedPodInfo, podSchedulingCycle int64) error
// SchedulingCycle returns the current number of scheduling cycle which is
// cached by scheduling queue. Normally, incrementing this number whenever
// a pod is popped (e.g. called Pop()) is enough.
SchedulingCycle() int64
// Pop會彈出一個pod,并從head優先級佇列中洗掉
Pop() (*framework.QueuedPodInfo, error)
Update(oldPod, newPod *v1.Pod) error
Delete(pod *v1.Pod) error
MoveAllToActiveOrBackoffQueue(event framework.ClusterEvent, preCheck PreEnqueueCheck)
AssignedPodAdded(pod *v1.Pod)
AssignedPodUpdated(pod *v1.Pod)
PendingPods() []*v1.Pod
// Close closes the SchedulingQueue so that the goroutine which is
// waiting to pop items can exit gracefully.
Close()
// Run starts the goroutines managing the queue.
Run()
}
而 PriorityQueue 是 SchedulingQueue 的實作,該部分的核心構成是兩個子佇列與一個資料結構,即 activeQ、backoffQ 和 unschedulablePods
activeQ:是一個 heap 型別的優先級佇列,是 sheduler 從中獲得優先級最高的Pod進行調度backoffQ:也是一個 heap 型別的優先級佇列,存放的是不可調度的PodunschedulablePods:保存確定不可被調度的Pod
type SchedulingQueue interface {
framework.PodNominator
Add(pod *v1.Pod) error
// Activate moves the given pods to activeQ iff they're in unschedulablePods or backoffQ.
// The passed-in pods are originally compiled from plugins that want to activate Pods,
// by injecting the pods through a reserved CycleState struct (PodsToActivate).
Activate(pods map[string]*v1.Pod)
// AddUnschedulableIfNotPresent adds an unschedulable pod back to scheduling queue.
// The podSchedulingCycle represents the current scheduling cycle number which can be
// returned by calling SchedulingCycle().
AddUnschedulableIfNotPresent(pod *framework.QueuedPodInfo, podSchedulingCycle int64) error
// SchedulingCycle returns the current number of scheduling cycle which is
// cached by scheduling queue. Normally, incrementing this number whenever
// a pod is popped (e.g. called Pop()) is enough.
SchedulingCycle() int64
// Pop removes the head of the queue and returns it. It blocks if the
// queue is empty and waits until a new item is added to the queue.
Pop() (*framework.QueuedPodInfo, error)
Update(oldPod, newPod *v1.Pod) error
Delete(pod *v1.Pod) error
MoveAllToActiveOrBackoffQueue(event framework.ClusterEvent, preCheck PreEnqueueCheck)
AssignedPodAdded(pod *v1.Pod)
AssignedPodUpdated(pod *v1.Pod)
PendingPods() []*v1.Pod
// Close closes the SchedulingQueue so that the goroutine which is
// waiting to pop items can exit gracefully.
Close()
// Run starts the goroutines managing the queue.
Run()
}
在New scheduler 時可以看到會初始化這個queue
podQueue := internalqueue.NewSchedulingQueue(
// 實作pod對比的一個函式即less
profiles[options.profiles[0].SchedulerName].QueueSortFunc(),
informerFactory,
internalqueue.WithPodInitialBackoffDuration(time.Duration(options.podInitialBackoffSeconds)*time.Second),
internalqueue.WithPodMaxBackoffDuration(time.Duration(options.podMaxBackoffSeconds)*time.Second),
internalqueue.WithPodNominator(nominator),
internalqueue.WithClusterEventMap(clusterEventMap),
internalqueue.WithPodMaxInUnschedulablePodsDuration(options.podMaxInUnschedulablePodsDuration),
)
而 NewSchedulingQueue 則是初始化這個 PriorityQueue
// NewSchedulingQueue initializes a priority queue as a new scheduling queue.
func NewSchedulingQueue(
lessFn framework.LessFunc,
informerFactory informers.SharedInformerFactory,
opts ...Option) SchedulingQueue {
return NewPriorityQueue(lessFn, informerFactory, opts...)
}
// NewPriorityQueue creates a PriorityQueue object.
func NewPriorityQueue(
lessFn framework.LessFunc,
informerFactory informers.SharedInformerFactory,
opts ...Option,
) *PriorityQueue {
options := defaultPriorityQueueOptions
for _, opt := range opts {
opt(&options)
}
// 這個就是 less函式,作為打分的一部分
comp := func(podInfo1, podInfo2 interface{}) bool {
pInfo1 := podInfo1.(*framework.QueuedPodInfo)
pInfo2 := podInfo2.(*framework.QueuedPodInfo)
return lessFn(pInfo1, pInfo2)
}
if options.podNominator == nil {
options.podNominator = NewPodNominator(informerFactory.Core().V1().Pods().Lister())
}
pq := &PriorityQueue{
PodNominator: options.podNominator,
clock: options.clock,
stop: make(chan struct{}),
podInitialBackoffDuration: options.podInitialBackoffDuration,
podMaxBackoffDuration: options.podMaxBackoffDuration,
podMaxInUnschedulablePodsDuration: options.podMaxInUnschedulablePodsDuration,
activeQ: heap.NewWithRecorder(podInfoKeyFunc, comp, metrics.NewActivePodsRecorder()),
unschedulablePods: newUnschedulablePods(metrics.NewUnschedulablePodsRecorder()),
moveRequestCycle: -1,
clusterEventMap: options.clusterEventMap,
}
pq.cond.L = &pq.lock
pq.podBackoffQ = heap.NewWithRecorder(podInfoKeyFunc, pq.podsCompareBackoffCompleted, metrics.NewBackoffPodsRecorder())
pq.nsLister = informerFactory.Core().V1().Namespaces().Lister()
return pq
}
了解了Queue的結構,就需要知道 入佇列與出佇列是在哪里操作的,在初始化時,需要注冊一個 addEventHandlerFuncs 這個時候,會注入三個動作函式,也就是controller中的概念;而在AddFunc中可以看到會入佇列,
注入是對 Pod 的informer注入的,注入的函式 addPodToSchedulingQueue 就是入堆疊
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: sched.addPodToSchedulingQueue,
UpdateFunc: sched.updatePodInSchedulingQueue,
DeleteFunc: sched.deletePodFromSchedulingQueue,
},
func (sched *Scheduler) addPodToSchedulingQueue(obj interface{}) {
pod := obj.(*v1.Pod)
klog.V(3).InfoS("Add event for unscheduled pod", "pod", klog.KObj(pod))
if err := sched.SchedulingQueue.Add(pod); err != nil {
utilruntime.HandleError(fmt.Errorf("unable to queue %T: %v", obj, err))
}
}
而這個 SchedulingQueue 的實作就是 PriorityQueue ,而Add中則對 activeQ進行的操作
func (p *PriorityQueue) Add(pod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
// 格式化入堆疊資料,包含podinfo,里會包含v1.Pod
// 初始化的時間,創建的時間,以及不能被調度時的記錄其plugin的名稱
pInfo := p.newQueuedPodInfo(pod)
// 入堆疊
if err := p.activeQ.Add(pInfo); err != nil {
klog.ErrorS(err, "Error adding pod to the active queue", "pod", klog.KObj(pod))
return err
}
if p.unschedulablePods.get(pod) != nil {
klog.ErrorS(nil, "Error: pod is already in the unschedulable queue", "pod", klog.KObj(pod))
p.unschedulablePods.delete(pod)
}
// Delete pod from backoffQ if it is backing off
if err := p.podBackoffQ.Delete(pInfo); err == nil {
klog.ErrorS(nil, "Error: pod is already in the podBackoff queue", "pod", klog.KObj(pod))
}
metrics.SchedulerQueueIncomingPods.WithLabelValues("active", PodAdd).Inc()
p.PodNominator.AddNominatedPod(pInfo.PodInfo, nil)
p.cond.Broadcast()
return nil
}
在上面看 scheduler 結構時,可以看到有一個 nextPod的,nextPod就是從佇列中彈出一個pod,這個在scheduler 時會傳入 MakeNextPodFunc 就是這個 nextpod
func MakeNextPodFunc(queue SchedulingQueue) func() *framework.QueuedPodInfo {
return func() *framework.QueuedPodInfo {
podInfo, err := queue.Pop()
if err == nil {
klog.V(4).InfoS("About to try and schedule pod", "pod", klog.KObj(podInfo.Pod))
for plugin := range podInfo.UnschedulablePlugins {
metrics.UnschedulableReason(plugin, podInfo.Pod.Spec.SchedulerName).Dec()
}
return podInfo
}
klog.ErrorS(err, "Error while retrieving next pod from scheduling queue")
return nil
}
}
而這個 queue.Pop() 對應的就是 PriorityQueue 的 Pop() ,在這里會將作為 activeQ 的消費端
func (p *PriorityQueue) Pop() (*framework.QueuedPodInfo, error) {
p.lock.Lock()
defer p.lock.Unlock()
for p.activeQ.Len() == 0 {
// When the queue is empty, invocation of Pop() is blocked until new item is enqueued.
// When Close() is called, the p.closed is set and the condition is broadcast,
// which causes this loop to continue and return from the Pop().
if p.closed {
return nil, fmt.Errorf(queueClosed)
}
p.cond.Wait()
}
obj, err := p.activeQ.Pop()
if err != nil {
return nil, err
}
pInfo := obj.(*framework.QueuedPodInfo)
pInfo.Attempts++
p.schedulingCycle++
return pInfo, nil
}
在上面入口部分也看到了,scheduleOne 和 scheduler,scheduleOne 就是去消費一個Pod,他會呼叫 NextPod,NextPod就是在初始化傳入的 MakeNextPodFunc ,至此回到對應的 Pop來做消費,
schedulerOne是為一個Pod做調度的流程,
func (sched *Scheduler) scheduleOne(ctx context.Context) {
podInfo := sched.NextPod()
// pod could be nil when schedulerQueue is closed
if podInfo == nil || podInfo.Pod == nil {
return
}
pod := podInfo.Pod
fwk, err := sched.frameworkForPod(pod)
if err != nil {
// This shouldn't happen, because we only accept for scheduling the pods
// which specify a scheduler name that matches one of the profiles.
klog.ErrorS(err, "Error occurred")
return
}
if sched.skipPodSchedule(fwk, pod) {
return
}
...
調度背景關系
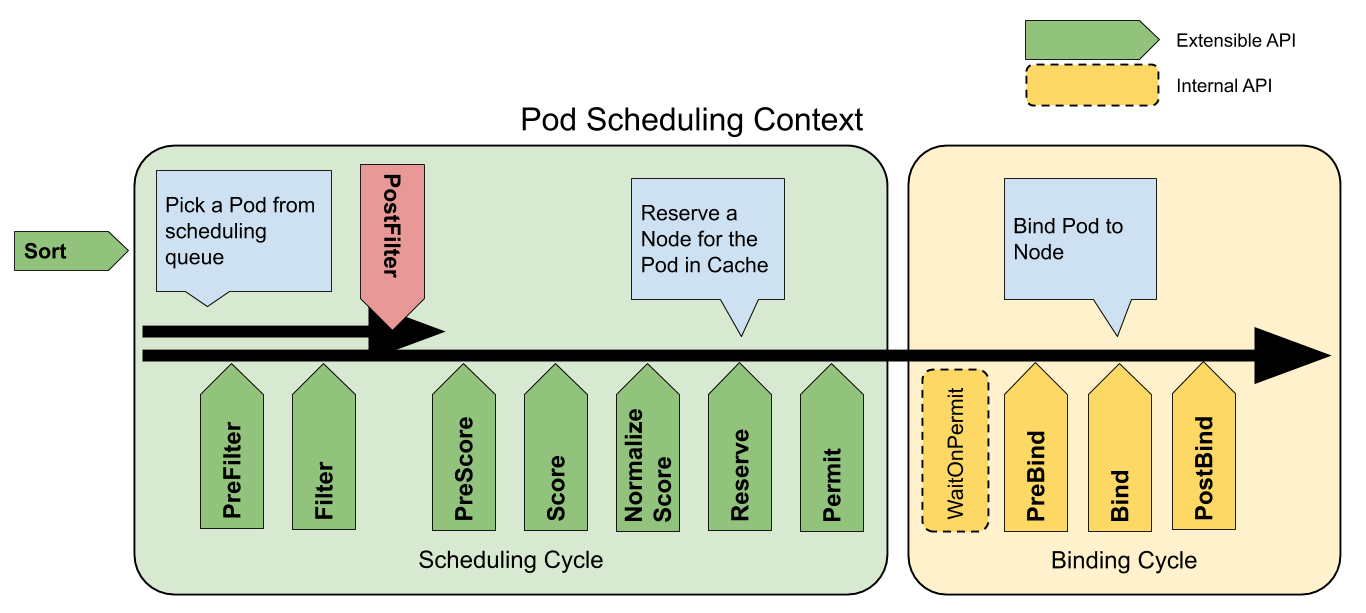
當了解了scheduler結構后,下面分析下調度背景關系的程序,看看擴展點是怎么作業的,這個時候又需要提到官網的調度背景關系的圖,
調度框架 [2]
調度框架 (scheduling framework SF ) 是kubernetes為 scheduler設計的一個pluggable的架構,SF 將scheduler設計為 Plugin 式的 API,API將上一章中提到的一些列調度策略實作為 Plugin,
在 SF 中,定義了一些擴展點 (extension points EP ),而被實作為Plugin的調度程式將被注冊在一個或多個 EP 中,換句話來說,在這些 EP 的執行程序中如果注冊在多個 EP 中,將會在多個 EP 被呼叫,
每次調度都分為兩個階段,調度周期(Scheduling Cycel)與系結周期(Binding Cycle),
- SC 表示為,為Pod選擇一個節點;SC 是串行運行的,
- BC 表示為,將 SC 決策結果應用于集群中;BC 可以同時運行,
調度周期與系結周期結合一起,被稱為調度背景關系 (Scheduling Context),下圖則是調度背景關系的作業流
注:如果決策結果為Pod的調度結果無可用節點,或存在內部錯誤,則中止 SC 或 BC,Pod將重入佇列重試
擴展點 [3]
擴展點(Extension points)是指在調度背景關系中的每個可擴展API,通過圖提現為[圖1],其中 Filter 相當于 Predicate 而 Scoring 相當于 Priority,
對于調度階段會通過以下擴展點:
-
Sort:該插件提供了排序功能,用于對在調度佇列中待處理 Pod 進行排序,一次只能啟用一個佇列排序, -
preFilter:該插件用于在過濾之前預處理或檢查 Pod 或集群的相關資訊,這里會終止調度 -
filter:該插件相當于調度背景關系中的Predicates,用于排除不能運行 Pod 的節點,Filter 會按配置的順序進行呼叫,如果有一個filter將節點標記位不可用,則將 Pod 標記為不可調度(即不會向下執行), -
postFilter:當沒有為 pod 找到FN時,該插件會按照配置的順序進行呼叫,如果任何postFilter插件將 Pod 標記為schedulable,則不會呼叫其余插件,即filter成功后不會進行這步驟 -
preScore:可用于進行預Score作業(通知性的擴展點), -
score:該插件為每個通過filter階段的Node提供打分服務,然后Scheduler將選擇具有最高加權分數總和的Node, -
reserve:因為系結事件時異步發生的,該插件是為了避免Pod在系結到節點前時,調度到新的Pod,使節點使用資源超過可用資源情況,如果后續階段發生錯誤或失敗,將觸發UnReserve回滾(通知性擴展點),這也是作為調度周期中最后一個狀態,要么成功到postBind,要么失敗觸發UnReserve, -
permit:該插件可以阻止或延遲 Pod 的系結,一般情況下這步驟會做三件事:appove:調度器繼續系結程序Deny:如果任何一個Premit拒絕了Pod與節點的系結,那么將觸發UnReserve,并重入佇列Wait: 如果 Permit 插件回傳Wait,該 Pod 將保留在內部WaitPod 串列中,直到被Appove,如果發生超時,wait變為deny,將Pod放回至調度佇列中,并觸發Unreserve回滾 ,
-
preBind:該插件用于在 bind Pod 之前執行所需的前置作業,如,preBind可能會提供一個網路卷并將其掛載到目標節點上,如果在該步驟中的任意插件回傳錯誤,則Pod 將被deny并放置到調度佇列中, -
bind:在所有的preBind完成后,該插件將用于將Pod系結到Node,并按順序呼叫系結該步驟的插件,如果有一個插件處理了這個事件,那么則忽略其余所有插件, -
postBind:該插件在系結 Pod 后呼叫,可用于清理相關資源(通知性的擴展點), -
multiPoint:這是一個僅配置欄位,允許同時為所有適用的擴展點啟用或禁用插件,
而 scheduler 對于調度背景關系在代碼中的實現就是 scheduleOne ,下面就是看這個調度背景關系
Sort
Sort 插件提供了排序功能,用于對在調度佇列中待處理 Pod 進行排序,一次只能啟用一個佇列排序,
在進入 scheduleOne 后,NextPod 從 activeQ 中佇列中得到一個Pod,然后的 frameworkForPod 會做打分的動作就是調度背景關系的第一個擴展點 sort
func (sched *Scheduler) scheduleOne(ctx context.Context) {
podInfo := sched.NextPod()
// pod could be nil when schedulerQueue is closed
if podInfo == nil || podInfo.Pod == nil {
return
}
pod := podInfo.Pod
fwk, err := sched.frameworkForPod(pod)
...
func (sched *Scheduler) frameworkForPod(pod *v1.Pod) (framework.Framework, error) {
// 獲取指定的profile
fwk, ok := sched.Profiles[pod.Spec.SchedulerName]
if !ok {
return nil, fmt.Errorf("profile not found for scheduler name %q", pod.Spec.SchedulerName)
}
return fwk, nil
}
回顧,因為在New scheduler時會初始化這個 sort 函式
podQueue := internalqueue.NewSchedulingQueue(
profiles[options.profiles[0].SchedulerName].QueueSortFunc(),
informerFactory,
internalqueue.WithPodInitialBackoffDuration(time.Duration(options.podInitialBackoffSeconds)*time.Second),
internalqueue.WithPodMaxBackoffDuration(time.Duration(options.podMaxBackoffSeconds)*time.Second),
internalqueue.WithPodNominator(nominator),
internalqueue.WithClusterEventMap(clusterEventMap),
internalqueue.WithPodMaxInUnschedulablePodsDuration(options.podMaxInUnschedulablePodsDuration),
)
preFilter
preFilter作為第一個擴展點,是用于在過濾之前預處理或檢查 Pod 或集群的相關資訊,這里會終止調度
func (sched *Scheduler) scheduleOne(ctx context.Context) {
podInfo := sched.NextPod()
// pod could be nil when schedulerQueue is closed
if podInfo == nil || podInfo.Pod == nil {
return
}
pod := podInfo.Pod
fwk, err := sched.frameworkForPod(pod)
if err != nil {
// This shouldn't happen, because we only accept for scheduling the pods
// which specify a scheduler name that matches one of the profiles.
klog.ErrorS(err, "Error occurred")
return
}
if sched.skipPodSchedule(fwk, pod) {
return
}
klog.V(3).InfoS("Attempting to schedule pod", "pod", klog.KObj(pod))
// Synchronously attempt to find a fit for the pod.
start := time.Now()
state := framework.NewCycleState()
state.SetRecordPluginMetrics(rand.Intn(100) < pluginMetricsSamplePercent)
// Initialize an empty podsToActivate struct, which will be filled up by plugins or stay empty.
podsToActivate := framework.NewPodsToActivate()
state.Write(framework.PodsToActivateKey, podsToActivate)
schedulingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
// 這里將進入prefilter
scheduleResult, err := sched.SchedulePod(schedulingCycleCtx, fwk, state, pod)
schedulePod 嘗試將給定的 pod 調度到節點串列中的節點之一,如果成功,它將回傳節點的名稱,
func (sched *Scheduler) schedulePod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
trace := utiltrace.New("Scheduling", utiltrace.Field{Key: "namespace", Value: pod.Namespace}, utiltrace.Field{Key: "name", Value: pod.Name})
defer trace.LogIfLong(100 * time.Millisecond)
// 用于將cache更新為當前內容
if err := sched.Cache.UpdateSnapshot(sched.nodeInfoSnapshot); err != nil {
return result, err
}
trace.Step("Snapshotting scheduler cache and node infos done")
if sched.nodeInfoSnapshot.NumNodes() == 0 {
return result, ErrNoNodesAvailable
}
// 找到一個合適的pod時,會執行擴展點
feasibleNodes, diagnosis, err := sched.findNodesThatFitPod(ctx, fwk, state, pod)
...
findNodesThatFitPod 會執行對應的過濾插件來找到最適合的Node,包括備注,以及方法名都可以看到,這里運行的插件????,后面會分析演算法內容,只對workflow學習,
func (sched *Scheduler) findNodesThatFitPod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) ([]*v1.Node, framework.Diagnosis, error) {
diagnosis := framework.Diagnosis{
NodeToStatusMap: make(framework.NodeToStatusMap),
UnschedulablePlugins: sets.NewString(),
}
// Run "prefilter" plugins.
preRes, s := fwk.RunPreFilterPlugins(ctx, state, pod)
allNodes, err := sched.nodeInfoSnapshot.NodeInfos().List()
if err != nil {
return nil, diagnosis, err
}
if !s.IsSuccess() {
if !s.IsUnschedulable() {
return nil, diagnosis, s.AsError()
}
// All nodes will have the same status. Some non trivial refactoring is
// needed to avoid this copy.
for _, n := range allNodes {
diagnosis.NodeToStatusMap[n.Node().Name] = s
}
// Status satisfying IsUnschedulable() gets injected into diagnosis.UnschedulablePlugins.
if s.FailedPlugin() != "" {
diagnosis.UnschedulablePlugins.Insert(s.FailedPlugin())
}
return nil, diagnosis, nil
}
// "NominatedNodeName" can potentially be set in a previous scheduling cycle as a result of preemption.
// This node is likely the only candidate that will fit the pod, and hence we try it first before iterating over all nodes.
if len(pod.Status.NominatedNodeName) > 0 {
feasibleNodes, err := sched.evaluateNominatedNode(ctx, pod, fwk, state, diagnosis)
if err != nil {
klog.ErrorS(err, "Evaluation failed on nominated node", "pod", klog.KObj(pod), "node", pod.Status.NominatedNodeName)
}
// Nominated node passes all the filters, scheduler is good to assign this node to the pod.
if len(feasibleNodes) != 0 {
return feasibleNodes, diagnosis, nil
}
}
nodes := allNodes
if !preRes.AllNodes() {
nodes = make([]*framework.NodeInfo, 0, len(preRes.NodeNames))
for n := range preRes.NodeNames {
nInfo, err := sched.nodeInfoSnapshot.NodeInfos().Get(n)
if err != nil {
return nil, diagnosis, err
}
nodes = append(nodes, nInfo)
}
}
feasibleNodes, err := sched.findNodesThatPassFilters(ctx, fwk, state, pod, diagnosis, nodes)
if err != nil {
return nil, diagnosis, err
}
feasibleNodes, err = findNodesThatPassExtenders(sched.Extenders, pod, feasibleNodes, diagnosis.NodeToStatusMap)
if err != nil {
return nil, diagnosis, err
}
return feasibleNodes, diagnosis, nil
}
filter
filter插件相當于調度背景關系中的 Predicates,用于排除不能運行 Pod 的節點,Filter 會按配置的順序進行呼叫,如果有一個filter將節點標記位不可用,則將 Pod 標記為不可調度(即不會向下執行),
對于代碼中來講,filter還是處于 findNodesThatFitPod 函式中,findNodesThatPassFilters 就是獲取到 FN,即可行節點,而這個程序就是 filter 擴展點
func (sched *Scheduler) findNodesThatFitPod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) ([]*v1.Node, framework.Diagnosis, error) {
...
feasibleNodes, err := sched.findNodesThatPassFilters(ctx, fwk, state, pod, diagnosis, nodes)
if err != nil {
return nil, diagnosis, err
}
feasibleNodes, err = findNodesThatPassExtenders(sched.Extenders, pod, feasibleNodes, diagnosis.NodeToStatusMap)
if err != nil {
return nil, diagnosis, err
}
return feasibleNodes, diagnosis, nil
}
Postfilter
當沒有為 pod 找到FN時,該插件會按照配置的順序進行呼叫,如果任何postFilter插件將 Pod 標記為schedulable,則不會呼叫其余插件,即 filter 成功后不會進行這步驟,那我們來驗證下這里把??
還是在 scheduleOne 中,當我們運行的 SchedulePod 完成后(成功或失敗),這時會回傳一個err,而 postfilter 會根據這個 err進行選擇執行或不執行,符合官方給出的說法,
scheduleResult, err := sched.SchedulePod(schedulingCycleCtx, fwk, state, pod)
if err != nil {
// SchedulePod() may have failed because the pod would not fit on any host, so we try to
// preempt, with the expectation that the next time the pod is tried for scheduling it
// will fit due to the preemption. It is also possible that a different pod will schedule
// into the resources that were preempted, but this is harmless.
var nominatingInfo *framework.NominatingInfo
if fitError, ok := err.(*framework.FitError); ok {
if !fwk.HasPostFilterPlugins() {
klog.V(3).InfoS("No PostFilter plugins are registered, so no preemption will be performed")
} else {
// Run PostFilter plugins to try to make the pod schedulable in a future scheduling cycle.
result, status := fwk.RunPostFilterPlugins(ctx, state, pod, fitError.Diagnosis.NodeToStatusMap)
if status.Code() == framework.Error {
klog.ErrorS(nil, "Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", status)
} else {
fitError.Diagnosis.PostFilterMsg = status.Message()
klog.V(5).InfoS("Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", status)
}
if result != nil {
nominatingInfo = result.NominatingInfo
}
}
// Pod did not fit anywhere, so it is counted as a failure. If preemption
// succeeds, the pod should get counted as a success the next time we try to
// schedule it. (hopefully)
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
} else if err == ErrNoNodesAvailable {
nominatingInfo = clearNominatedNode
// No nodes available is counted as unschedulable rather than an error.
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
} else {
nominatingInfo = clearNominatedNode
klog.ErrorS(err, "Error selecting node for pod", "pod", klog.KObj(pod))
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
}
sched.handleSchedulingFailure(ctx, fwk, podInfo, err, v1.PodReasonUnschedulable, nominatingInfo)
return
}
PreScore,Score
可用于進行預Score作業,作為通知性的擴展點,會在在filter完之后直接會關聯 preScore 插件進行繼續作業,而不是回傳,如果配置的這些插件有任何一個回傳失敗,則Pod將被拒絕,
func (sched *Scheduler) schedulePod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
trace := utiltrace.New("Scheduling", utiltrace.Field{Key: "namespace", Value: pod.Namespace}, utiltrace.Field{Key: "name", Value: pod.Name})
defer trace.LogIfLong(100 * time.Millisecond)
if err := sched.Cache.UpdateSnapshot(sched.nodeInfoSnapshot); err != nil {
return result, err
}
trace.Step("Snapshotting scheduler cache and node infos done")
if sched.nodeInfoSnapshot.NumNodes() == 0 {
return result, ErrNoNodesAvailable
}
feasibleNodes, diagnosis, err := sched.findNodesThatFitPod(ctx, fwk, state, pod)
if err != nil {
return result, err
}
trace.Step("Computing predicates done")
if len(feasibleNodes) == 0 {
return result, &framework.FitError{
Pod: pod,
NumAllNodes: sched.nodeInfoSnapshot.NumNodes(),
Diagnosis: diagnosis,
}
}
// When only one node after predicate, just use it.
if len(feasibleNodes) == 1 {
return ScheduleResult{
SuggestedHost: feasibleNodes[0].Name,
EvaluatedNodes: 1 + len(diagnosis.NodeToStatusMap),
FeasibleNodes: 1,
}, nil
}
// 這里會完成prescore,score
priorityList, err := prioritizeNodes(ctx, sched.Extenders, fwk, state, pod, feasibleNodes)
if err != nil {
return result, err
}
host, err := selectHost(priorityList)
trace.Step("Prioritizing done")
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(feasibleNodes) + len(diagnosis.NodeToStatusMap),
FeasibleNodes: len(feasibleNodes),
}, err
}
priorityNodes 會通過配置的插件給Node打分,并回傳每個Node的分數,將每個插件打分結果計算總和獲得Node的分數,最后獲得節點的加權總分數,
func prioritizeNodes(
ctx context.Context,
extenders []framework.Extender,
fwk framework.Framework,
state *framework.CycleState,
pod *v1.Pod,
nodes []*v1.Node,
) (framework.NodeScoreList, error) {
// If no priority configs are provided, then all nodes will have a score of one.
// This is required to generate the priority list in the required format
if len(extenders) == 0 && !fwk.HasScorePlugins() {
result := make(framework.NodeScoreList, 0, len(nodes))
for i := range nodes {
result = append(result, framework.NodeScore{
Name: nodes[i].Name,
Score: 1,
})
}
return result, nil
}
// Run PreScore plugins.
preScoreStatus := fwk.RunPreScorePlugins(ctx, state, pod, nodes)
if !preScoreStatus.IsSuccess() {
return nil, preScoreStatus.AsError()
}
// Run the Score plugins.
scoresMap, scoreStatus := fwk.RunScorePlugins(ctx, state, pod, nodes)
if !scoreStatus.IsSuccess() {
return nil, scoreStatus.AsError()
}
// Additional details logged at level 10 if enabled.
klogV := klog.V(10)
if klogV.Enabled() {
for plugin, nodeScoreList := range scoresMap {
for _, nodeScore := range nodeScoreList {
klogV.InfoS("Plugin scored node for pod", "pod", klog.KObj(pod), "plugin", plugin, "node", nodeScore.Name, "score", nodeScore.Score)
}
}
}
// Summarize all scores.
result := make(framework.NodeScoreList, 0, len(nodes))
for i := range nodes {
result = append(result, framework.NodeScore{Name: nodes[i].Name, Score: 0})
for j := range scoresMap {
result[i].Score += scoresMap[j][i].Score
}
}
if len(extenders) != 0 && nodes != nil {
var mu sync.Mutex
var wg sync.WaitGroup
combinedScores := make(map[string]int64, len(nodes))
for i := range extenders {
if !extenders[i].IsInterested(pod) {
continue
}
wg.Add(1)
go func(extIndex int) {
metrics.SchedulerGoroutines.WithLabelValues(metrics.PrioritizingExtender).Inc()
defer func() {
metrics.SchedulerGoroutines.WithLabelValues(metrics.PrioritizingExtender).Dec()
wg.Done()
}()
prioritizedList, weight, err := extenders[extIndex].Prioritize(pod, nodes)
if err != nil {
// Prioritization errors from extender can be ignored, let k8s/other extenders determine the priorities
klog.V(5).InfoS("Failed to run extender's priority function. No score given by this extender.", "error", err, "pod", klog.KObj(pod), "extender", extenders[extIndex].Name())
return
}
mu.Lock()
for i := range *prioritizedList {
host, score := (*prioritizedList)[i].Host, (*prioritizedList)[i].Score
if klogV.Enabled() {
klogV.InfoS("Extender scored node for pod", "pod", klog.KObj(pod), "extender", extenders[extIndex].Name(), "node", host, "score", score)
}
combinedScores[host] += score * weight
}
mu.Unlock()
}(i)
}
// wait for all go routines to finish
wg.Wait()
for i := range result {
// MaxExtenderPriority may diverge from the max priority used in the scheduler and defined by MaxNodeScore,
// therefore we need to scale the score returned by extenders to the score range used by the scheduler.
result[i].Score += combinedScores[result[i].Name] * (framework.MaxNodeScore / extenderv1.MaxExtenderPriority)
}
}
if klogV.Enabled() {
for i := range result {
klogV.InfoS("Calculated node's final score for pod", "pod", klog.KObj(pod), "node", result[i].Name, "score", result[i].Score)
}
}
return result, nil
}
Reserve
Reserve 因為系結事件時異步發生的,該插件是為了避免Pod在系結到節點前時,調度到新的Pod,使節點使用資源超過可用資源情況,如果后續階段發生錯誤或失敗,將觸發 UnReserve 回滾(通知性擴展點),這也是作為調度周期中最后一個狀態,要么成功到 postBind ,要么失敗觸發 UnReserve,
// Run the Reserve method of reserve plugins.
if sts := fwk.RunReservePluginsReserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() { // 當處理不成功時
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
// 觸發 un-reserve 來清理相關Pod的狀態
fwk.RunReservePluginsUnreserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache.ForgetPod(assumedPod); forgetErr != nil {
klog.ErrorS(forgetErr, "Scheduler cache ForgetPod failed")
}
sched.handleSchedulingFailure(ctx, fwk, assumedPodInfo, sts.AsError(), SchedulerError, clearNominatedNode)
return
}
permit
Permit 插件可以阻止或延遲 Pod 的系結
// Run "permit" plugins.
runPermitStatus := fwk.RunPermitPlugins(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if !runPermitStatus.IsWait() && !runPermitStatus.IsSuccess() {
var reason string
if runPermitStatus.IsUnschedulable() {
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = v1.PodReasonUnschedulable
} else {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = SchedulerError
}
// 只要其中一個插件回傳的狀態不是 success 或者 wait
fwk.RunReservePluginsUnreserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
// 從cache中忘掉pod
if forgetErr := sched.Cache.ForgetPod(assumedPod); forgetErr != nil {
klog.ErrorS(forgetErr, "Scheduler cache ForgetPod failed")
}
sched.handleSchedulingFailure(ctx, fwk, assumedPodInfo, runPermitStatus.AsError(), reason, clearNominatedNode)
return
}
Binding Cycle
在選擇好 FN 后則做一個假設系結,并更新到cache中,接下來回去執行真正的bind操作,也就是 binding cycle
func (sched *Scheduler) scheduleOne(ctx context.Context) {
...
...
// binding cycle 是一個異步的操作,這里表現就是go協程
go func() {
bindingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
metrics.SchedulerGoroutines.WithLabelValues(metrics.Binding).Inc()
defer metrics.SchedulerGoroutines.WithLabelValues(metrics.Binding).Dec()
// 運行WaitOnPermit插件,如果失敗則,unReserve回滾
waitOnPermitStatus := fwk.WaitOnPermit(bindingCycleCtx, assumedPod)
if !waitOnPermitStatus.IsSuccess() {
var reason string
if waitOnPermitStatus.IsUnschedulable() {
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = v1.PodReasonUnschedulable
} else {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = SchedulerError
}
// trigger un-reserve plugins to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache.ForgetPod(assumedPod); forgetErr != nil {
klog.ErrorS(forgetErr, "scheduler cache ForgetPod failed")
} else {
// "Forget"ing an assumed Pod in binding cycle should be treated as a PodDelete event,
// as the assumed Pod had occupied a certain amount of resources in scheduler cache.
// TODO(#103853): de-duplicate the logic.
// Avoid moving the assumed Pod itself as it's always Unschedulable.
// It's intentional to "defer" this operation; otherwise MoveAllToActiveOrBackoffQueue() would
// update `q.moveRequest` and thus move the assumed pod to backoffQ anyways.
defer sched.SchedulingQueue.MoveAllToActiveOrBackoffQueue(internalqueue.AssignedPodDelete, func(pod *v1.Pod) bool {
return assumedPod.UID != pod.UID
})
}
sched.handleSchedulingFailure(ctx, fwk, assumedPodInfo, waitOnPermitStatus.AsError(), reason, clearNominatedNode)
return
}
// 運行Prebind 插件
preBindStatus := fwk.RunPreBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if !preBindStatus.IsSuccess() {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
// trigger un-reserve plugins to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache.ForgetPod(assumedPod); forgetErr != nil {
klog.ErrorS(forgetErr, "scheduler cache ForgetPod failed")
} else {
// "Forget"ing an assumed Pod in binding cycle should be treated as a PodDelete event,
// as the assumed Pod had occupied a certain amount of resources in scheduler cache.
// TODO(#103853): de-duplicate the logic.
sched.SchedulingQueue.MoveAllToActiveOrBackoffQueue(internalqueue.AssignedPodDelete, nil)
}
sched.handleSchedulingFailure(ctx, fwk, assumedPodInfo, preBindStatus.AsError(), SchedulerError, clearNominatedNode)
return
}
// bind是真正的系結操作
err := sched.bind(bindingCycleCtx, fwk, assumedPod, scheduleResult.SuggestedHost, state)
if err != nil {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
// 如果失敗了就觸發 un-reserve plugins
fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if err := sched.Cache.ForgetPod(assumedPod); err != nil {
klog.ErrorS(err, "scheduler cache ForgetPod failed")
} else {
// "Forget"ing an assumed Pod in binding cycle should be treated as a PodDelete event,
// as the assumed Pod had occupied a certain amount of resources in scheduler cache.
// TODO(#103853): de-duplicate the logic.
sched.SchedulingQueue.MoveAllToActiveOrBackoffQueue(internalqueue.AssignedPodDelete, nil)
}
sched.handleSchedulingFailure(ctx, fwk, assumedPodInfo, fmt.Errorf("binding rejected: %w", err), SchedulerError, clearNominatedNode)
return
}
// Calculating nodeResourceString can be heavy. Avoid it if klog verbosity is below 2.
klog.V(2).InfoS("Successfully bound pod to node", "pod", klog.KObj(pod), "node", scheduleResult.SuggestedHost, "evaluatedNodes", scheduleResult.EvaluatedNodes, "feasibleNodes", scheduleResult.FeasibleNodes)
metrics.PodScheduled(fwk.ProfileName(), metrics.SinceInSeconds(start))
metrics.PodSchedulingAttempts.Observe(float64(podInfo.Attempts))
metrics.PodSchedulingDuration.WithLabelValues(getAttemptsLabel(podInfo)).Observe(metrics.SinceInSeconds(podInfo.InitialAttemptTimestamp))
// 運行 "postbind" 插件
// 是通知性的擴展點,該插件在系結 Pod 后呼叫,可用于清理相關資源(),
fwk.RunPostBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
// At the end of a successful binding cycle, move up Pods if needed.
if len(podsToActivate.Map) != 0 {
sched.SchedulingQueue.Activate(podsToActivate.Map)
// Unlike the logic in scheduling cycle, we don't bother deleting the entries
// as `podsToActivate.Map` is no longer consumed.
}
}()
}
調度背景關系中的失敗流程
上面說到的都是正常的請求,下面會對失敗的請求是如何重試的進行分析,而 scheduler 中關于失敗處理方面相關的屬性會涉及到上面 scheduler 結構中的 backoffQ 與 unschedulablePods
backoffQ:也是一個 heap 型別的優先級佇列,存放的是不可調度的PodunschedulablePods:保存確定不可被調度的Pod,一個map型別
backoffQ 與 unschedulablePods 會在初始化 scheduler 時初始化,
func NewPriorityQueue(
lessFn framework.LessFunc,
informerFactory informers.SharedInformerFactory,
opts ...Option,
) *PriorityQueue {
options := defaultPriorityQueueOptions
for _, opt := range opts {
opt(&options)
}
comp := func(podInfo1, podInfo2 interface{}) bool {
pInfo1 := podInfo1.(*framework.QueuedPodInfo)
pInfo2 := podInfo2.(*framework.QueuedPodInfo)
return lessFn(pInfo1, pInfo2)
}
if options.podNominator == nil {
options.podNominator = NewPodNominator(informerFactory.Core().V1().Pods().Lister())
}
pq := &PriorityQueue{
PodNominator: options.podNominator,
clock: options.clock,
stop: make(chan struct{}),
podInitialBackoffDuration: options.podInitialBackoffDuration,
podMaxBackoffDuration: options.podMaxBackoffDuration,
podMaxInUnschedulablePodsDuration: options.podMaxInUnschedulablePodsDuration,
activeQ: heap.NewWithRecorder(podInfoKeyFunc, comp, metrics.NewActivePodsRecorder()),
unschedulablePods: newUnschedulablePods(metrics.NewUnschedulablePodsRecorder()),
moveRequestCycle: -1,
clusterEventMap: options.clusterEventMap,
}
pq.cond.L = &pq.lock
// 初始化backoffQ
// NewWithRecorder作為一個可選的 metricRecorder 的 Heap 物件,
// podInfoKeyFunc是一個函式,回傳錯誤與字串
// pq.podsCompareBackoffCompleted 比較兩個pod的回退時間,如果第一個在第二個之前為true,
// 反之 false
pq.podBackoffQ = heap.NewWithRecorder(podInfoKeyFunc, pq.podsCompareBackoffCompleted, metrics.NewBackoffPodsRecorder())
pq.nsLister = informerFactory.Core().V1().Namespaces().Lister()
return pq
}
對于初始化 backoffQ 會產生的兩個函式,getBackoffTime 與 calculateBackoffDuration
// getBackoffTime returns the time that podInfo completes backoff
func (p *PriorityQueue) getBackoffTime(podInfo *framework.QueuedPodInfo) time.Time {
duration := p.calculateBackoffDuration(podInfo)
backoffTime := podInfo.Timestamp.Add(duration)
return backoffTime
}
// calculateBackoffDuration is a helper function for calculating the backoffDuration
// based on the number of attempts the pod has made.
func (p *PriorityQueue) calculateBackoffDuration(podInfo *framework.QueuedPodInfo) time.Duration {
duration := p.podInitialBackoffDuration
for i := 1; i < podInfo.Attempts; i++ {
// Use subtraction instead of addition or multiplication to avoid overflow.
if duration > p.podMaxBackoffDuration-duration {
return p.podMaxBackoffDuration
}
duration += duration
}
return duration
}
對于整個故障錯誤會按照如下流程進行,在初始化 scheduler 會注冊一個 Error 函式,這個函式用作對不可調度Pod進行處理,實際上被注冊的函式是 MakeDefaultErrorFunc,這個函式將作為 Error 函式被呼叫,
sched := newScheduler(
schedulerCache,
extenders,
internalqueue.MakeNextPodFunc(podQueue),
MakeDefaultErrorFunc(client, podLister, podQueue, schedulerCache),
stopEverything,
podQueue,
profiles,
client,
snapshot,
options.percentageOfNodesToScore,
)
而在 調度周期中,也就是 scheduleOne 可以看到,每個擴展點操作失敗后都會呼叫 handleSchedulingFailure 而該函式,使用了注冊的 Error 函式來處理Pod
func (sched *Scheduler) scheduleOne(ctx context.Context) {
...
defer cancel()
scheduleResult, err := sched.SchedulePod(schedulingCycleCtx, fwk, state, pod)
if err != nil {
var nominatingInfo *framework.NominatingInfo
if fitError, ok := err.(*framework.FitError); ok {
if !fwk.HasPostFilterPlugins() {
klog.V(3).InfoS("No PostFilter plugins are registered, so no preemption will be performed")
} else {
result, status := fwk.RunPostFilterPlugins(ctx, state, pod, fitError.Diagnosis.NodeToStatusMap)
if status.Code() == framework.Error {
klog.ErrorS(nil, "Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", status)
} else {
fitError.Diagnosis.PostFilterMsg = status.Message()
klog.V(5).InfoS("Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", status)
}
if result != nil {
nominatingInfo = result.NominatingInfo
}
}
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
} else if err == ErrNoNodesAvailable {
nominatingInfo = clearNominatedNode
// No nodes available is counted as unschedulable rather than an error.
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
} else {
nominatingInfo = clearNominatedNode
klog.ErrorS(err, "Error selecting node for pod", "pod", klog.KObj(pod))
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
}
// 處理不可調度Pod
sched.handleSchedulingFailure(ctx, fwk, podInfo, err, v1.PodReasonUnschedulable, nominatingInfo)
return
}
來到了注冊的 Error 函式 MakeDefaultErrorFunc
func MakeDefaultErrorFunc(client clientset.Interface, podLister corelisters.PodLister, podQueue internalqueue.SchedulingQueue, schedulerCache internalcache.Cache) func(*framework.QueuedPodInfo, error) {
return func(podInfo *framework.QueuedPodInfo, err error) {
pod := podInfo.Pod
if err == ErrNoNodesAvailable {
klog.V(2).InfoS("Unable to schedule pod; no nodes are registered to the cluster; waiting", "pod", klog.KObj(pod))
} else if fitError, ok := err.(*framework.FitError); ok {
// Inject UnschedulablePlugins to PodInfo, which will be used later for moving Pods between queues efficiently.
podInfo.UnschedulablePlugins = fitError.Diagnosis.UnschedulablePlugins
klog.V(2).InfoS("Unable to schedule pod; no fit; waiting", "pod", klog.KObj(pod), "err", err)
} else if apierrors.IsNotFound(err) {
klog.V(2).InfoS("Unable to schedule pod, possibly due to node not found; waiting", "pod", klog.KObj(pod), "err", err)
if errStatus, ok := err.(apierrors.APIStatus); ok && errStatus.Status().Details.Kind == "node" {
nodeName := errStatus.Status().Details.Name
// when node is not found, We do not remove the node right away. Trying again to get
// the node and if the node is still not found, then remove it from the scheduler cache.
_, err := client.CoreV1().Nodes().Get(context.TODO(), nodeName, metav1.GetOptions{})
if err != nil && apierrors.IsNotFound(err) {
node := v1.Node{ObjectMeta: metav1.ObjectMeta{Name: nodeName}}
if err := schedulerCache.RemoveNode(&node); err != nil {
klog.V(4).InfoS("Node is not found; failed to remove it from the cache", "node", node.Name)
}
}
}
} else {
klog.ErrorS(err, "Error scheduling pod; retrying", "pod", klog.KObj(pod))
}
// Check if the Pod exists in informer cache.
cachedPod, err := podLister.Pods(pod.Namespace).Get(pod.Name)
if err != nil {
klog.InfoS("Pod doesn't exist in informer cache", "pod", klog.KObj(pod), "err", err)
return
}
// In the case of extender, the pod may have been bound successfully, but timed out returning its response to the scheduler.
// It could result in the live version to carry .spec.nodeName, and that's inconsistent with the internal-queued version.
if len(cachedPod.Spec.NodeName) != 0 {
klog.InfoS("Pod has been assigned to node. Abort adding it back to queue.", "pod", klog.KObj(pod), "node", cachedPod.Spec.NodeName)
return
}
// As <cachedPod> is from SharedInformer, we need to do a DeepCopy() here.
podInfo.PodInfo = framework.NewPodInfo(cachedPod.DeepCopy())
// 添加到unschedulable佇列中
if err := podQueue.AddUnschedulableIfNotPresent(podInfo, podQueue.SchedulingCycle()); err != nil {
klog.ErrorS(err, "Error occurred")
}
}
}
下面來到 AddUnschedulableIfNotPresent ,這個也是操作 backoffQ 和 unschedulablePods 的真正的動作
AddUnschedulableIfNotPresent 函式會吧無法調度的 pod 插入佇列,除非它已經在佇列中,通常情況下,PriorityQueue 將不可調度的 Pod 放在 unschedulablePods 中,但如果最近有 move request,則將 pod 放入 podBackoffQ 中,
func (p *PriorityQueue) AddUnschedulableIfNotPresent(pInfo *framework.QueuedPodInfo, podSchedulingCycle int64) error {
p.lock.Lock()
defer p.lock.Unlock()
pod := pInfo.Pod
// 如果已經存在則不添加
if p.unschedulablePods.get(pod) != nil {
return fmt.Errorf("Pod %v is already present in unschedulable queue", klog.KObj(pod))
}
// 檢查是否在activeQ中
if _, exists, _ := p.activeQ.Get(pInfo); exists {
return fmt.Errorf("Pod %v is already present in the active queue", klog.KObj(pod))
}
// 檢查是否在podBackoffQ中
if _, exists, _ := p.podBackoffQ.Get(pInfo); exists {
return fmt.Errorf("Pod %v is already present in the backoff queue", klog.KObj(pod))
}
// 在重新添加時,會重繪 Pod時間為最新操作的時間
pInfo.Timestamp = p.clock.Now()
for plugin := range pInfo.UnschedulablePlugins {
metrics.UnschedulableReason(plugin, pInfo.Pod.Spec.SchedulerName).Inc()
}
// 如果接受到move request那么則放入BackoffQ
if p.moveRequestCycle >= podSchedulingCycle {
if err := p.podBackoffQ.Add(pInfo); err != nil {
return fmt.Errorf("error adding pod %v to the backoff queue: %v", pod.Name, err)
}
metrics.SchedulerQueueIncomingPods.WithLabelValues("backoff", ScheduleAttemptFailure).Inc()
} else {
// 否則將放入到 unschedulablePods
p.unschedulablePods.addOrUpdate(pInfo)
metrics.SchedulerQueueIncomingPods.WithLabelValues("unschedulable", ScheduleAttemptFailure).Inc()
}
p.PodNominator.AddNominatedPod(pInfo.PodInfo, nil)
return nil
}
在啟動 scheduler 時,會將這兩個佇列異步啟用兩個loop來操作佇列,表現在 Run()
func (p *PriorityQueue) Run() {
go wait.Until(p.flushBackoffQCompleted, 1.0*time.Second, p.stop)
go wait.Until(p.flushUnschedulablePodsLeftover, 30*time.Second, p.stop)
}
可以看到 flushBackoffQCompleted 作為 BackoffQ 實作;而 flushUnschedulablePodsLeftover 作為 UnschedulablePods 實作,
flushBackoffQCompleted 是用于將所有已完成回退的 pod 從 backoffQ 移到 activeQ 中
func (p *PriorityQueue) flushBackoffQCompleted() {
p.lock.Lock()
defer p.lock.Unlock()
broadcast := false
for { // 這就是heap實作的方法,窺視下,但不彈出
rawPodInfo := p.podBackoffQ.Peek()
if rawPodInfo == nil {
break
}
pod := rawPodInfo.(*framework.QueuedPodInfo).Pod
boTime := p.getBackoffTime(rawPodInfo.(*framework.QueuedPodInfo))
if boTime.After(p.clock.Now()) {
break
}
_, err := p.podBackoffQ.Pop() // 彈出一個
if err != nil {
klog.ErrorS(err, "Unable to pop pod from backoff queue despite backoff completion", "pod", klog.KObj(pod))
break
}
p.activeQ.Add(rawPodInfo) // 放入到活動佇列中
metrics.SchedulerQueueIncomingPods.WithLabelValues("active", BackoffComplete).Inc()
broadcast = true
}
if broadcast {
p.cond.Broadcast()
}
}
flushUnschedulablePodsLeftover 函式用于將在 unschedulablePods 中的存放時間超過 podMaxInUnschedulablePodsDuration 值的 pod 移動到 backoffQ 或 activeQ 中,
podMaxInUnschedulablePodsDuration 會根據配置傳入,當沒有傳入,也就是使用了 Deprecated 那么會為5分鐘,
func NewOptions() *Options {
o := &Options{
SecureServing: apiserveroptions.NewSecureServingOptions().WithLoopback(),
Authentication: apiserveroptions.NewDelegatingAuthenticationOptions(),
Authorization: apiserveroptions.NewDelegatingAuthorizationOptions(),
Deprecated: &DeprecatedOptions{
PodMaxInUnschedulablePodsDuration: 5 * time.Minute,
},
對于 flushUnschedulablePodsLeftover 就是做一個時間對比,然后添加到對應的佇列中
func (p *PriorityQueue) flushUnschedulablePodsLeftover() {
p.lock.Lock()
defer p.lock.Unlock()
var podsToMove []*framework.QueuedPodInfo
currentTime := p.clock.Now()
for _, pInfo := range p.unschedulablePods.podInfoMap {
lastScheduleTime := pInfo.Timestamp
if currentTime.Sub(lastScheduleTime) > p.podMaxInUnschedulablePodsDuration {
podsToMove = append(podsToMove, pInfo)
}
}
if len(podsToMove) > 0 {
p.movePodsToActiveOrBackoffQueue(podsToMove, UnschedulableTimeout)
}
}
總結調度背景關系流程
- 在構建一個 scheduler 時經歷如下步驟:
- 準備cache,informer,queue,錯誤處理函式等
- 添加事件函式,會監聽資源(如Pod),當有變動則觸發對應事件函式,這是入站
activeQ
- 構建完成后會 run,run時會run一個
SchedulingQueue,這個是作為不可調度佇列BackoffQUnschedulablePods- 不可調度佇列會根據注冊時定期消費佇列中Pod將其添加到
activeQ中
- 啟動一個
scheduleOne的loop,這個是調度背景關系中所有的擴展點的執行,也是activeQ的消費端scheduleOne獲取 pod- 執行各個擴展點,如果出錯則 Error 函式
MakeDefaultErrorFunc將其添加到不可調度佇列中 - 回到不可調度佇列中消費部分
作者:鋼閘門Reference
[1] kubernetes scheduler extender
[2] scheduling framework
[3] Extension points
出處:http://lc161616.cnblogs.com/ 本文著作權歸作者和博客園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連接,否則保留追究法律責任的權利, 阿里云優惠:點擊力享低價 墨墨學英語:幫忙點一下
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/500008.html
標籤:其他