Part2 描述性統計
一、直方圖
直方圖是用面積而不是用高度來表示數,所以其不同于條形圖
左邊的刻度表示該塊每單位所占總面積的百分比,可以稱其為密度尺度,
例如以每50元為一個單位,200-400 就有四個單位,
每一塊所擁有的單位數 \(\times\) 左邊每單位所占百分數 = 該塊所占總百分比
直方圖的總面積 = 總單位數 \(\times\) 每單位對應密度尺度 = 1
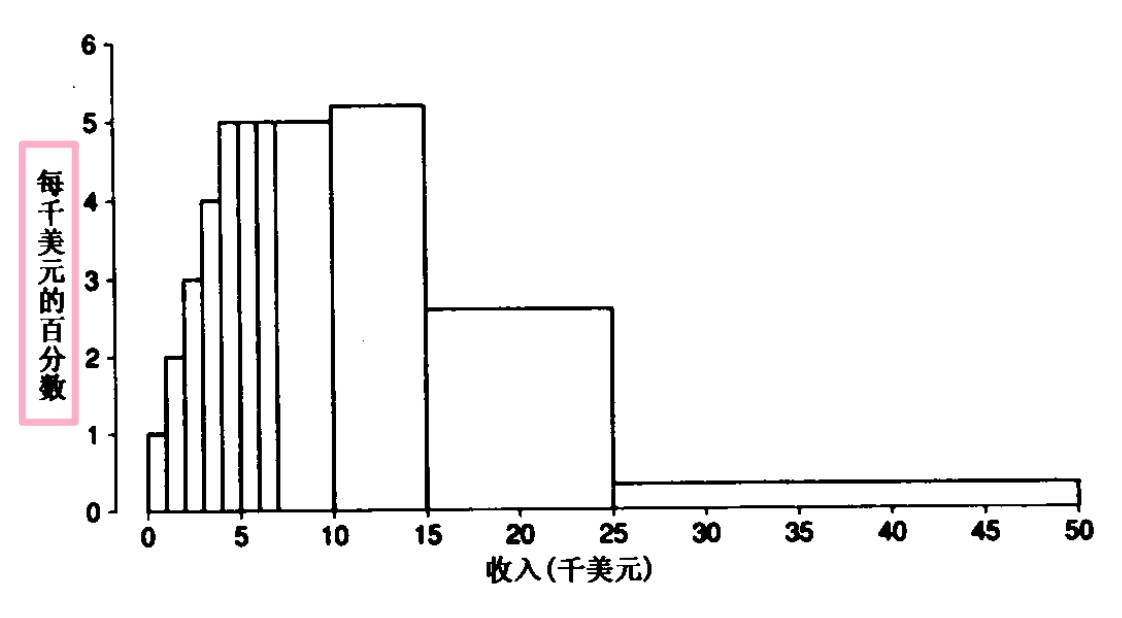
直方圖的繪制是根據百分表來繪制的,即統計的變數的每個子區間內的實體占總實體的百分比數,
在繪制時需要注意邊界處理(終點約定):即位于子區間邊界的值該劃分到哪個子區間中,
直方圖的高度表示什么呢?高度表示擁擠程度(單位區間的密度),也就是堆積在該區間的實體數
小結
-
直方圖以面積表示百分數
-
采用密度尺度,每一個塊形的高度等于相應小組區間中事例的百分數除以該區間的長度
-
采用密度尺度,面積呈現為百分數,總面積是 100%
-
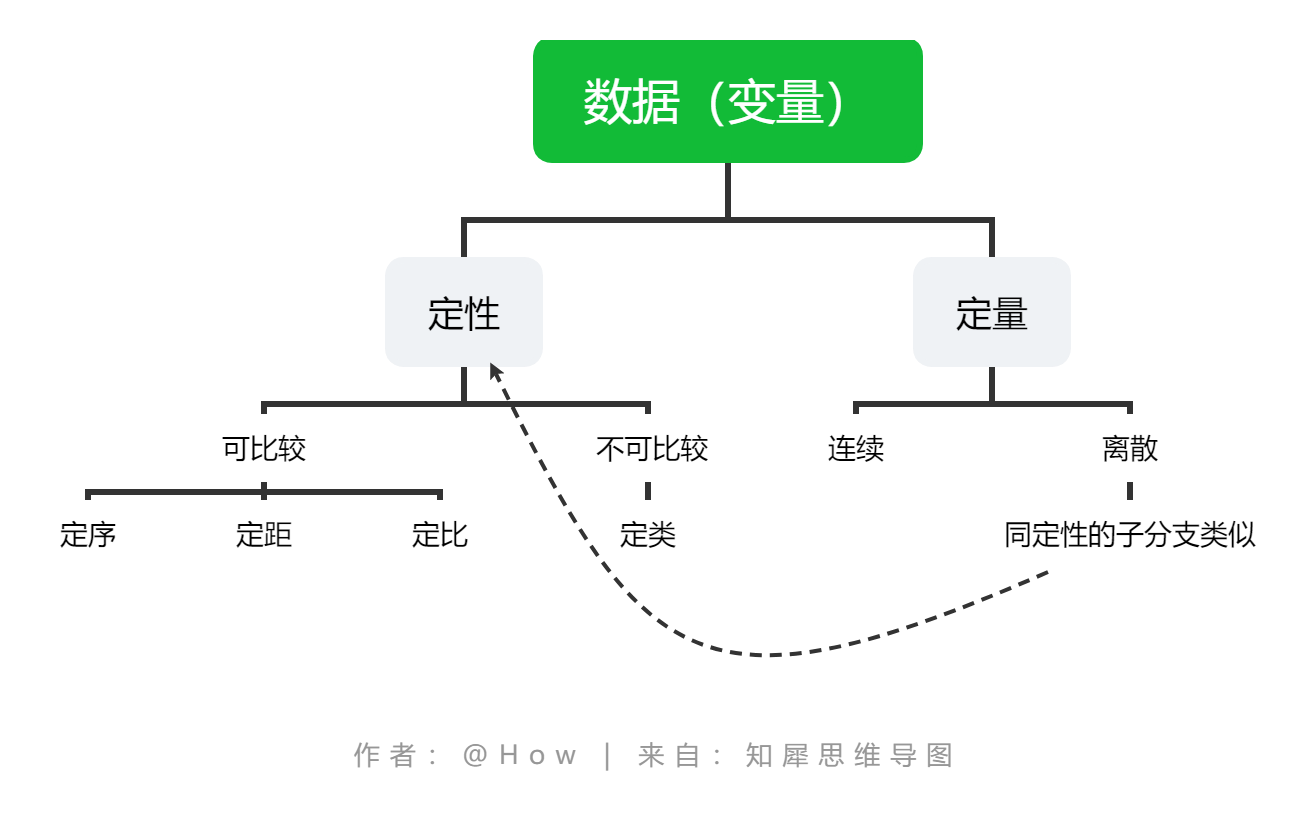
變數是研究中物件的特征,它可以是定性的,也可以是定量的,而如果是定量的,則要么是離散的,要么是連續的
-
混雜因素有時候用交叉串列(可以看成透視表)加以控制
二、中心與散布
1. 中心
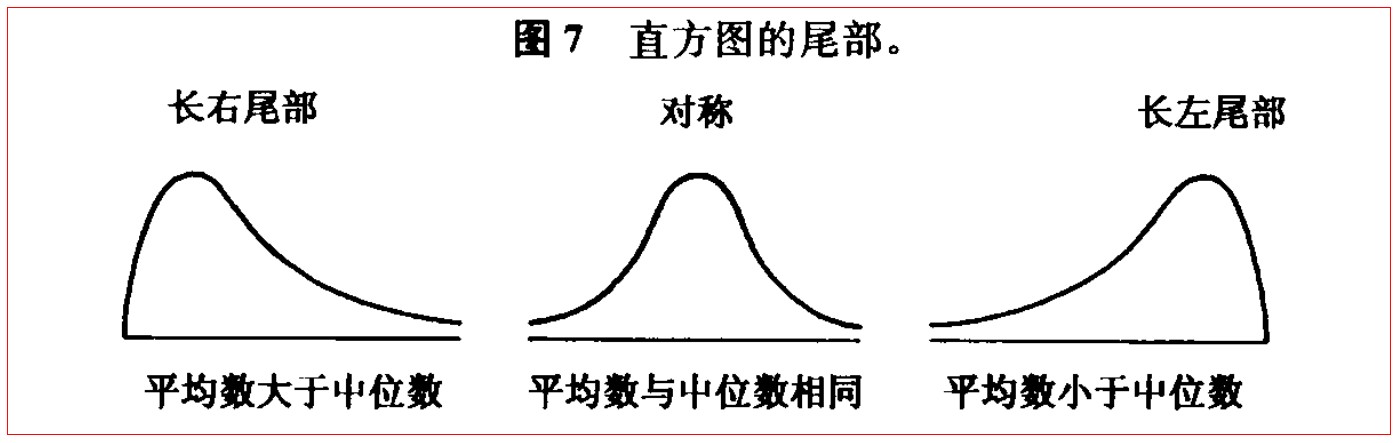
平均數受到離中心越遠的資料的影響越大,可以看成同樣 50% 的體積的資料,越遠的資料給其占比進行了更大的加權,如下圖所示
2. 標準差(SD)
標準差的意義:SD指出了數列中的數離他們的平均數有多遠,數列中大多數項離開平均數大約 1 個 SD 左右,極少數項將離開 2 個或 3 個 SD 以上,
更加具體和數量化的表述:
-
粗略的,數列中 68% (三分之二)的項在離平均數 1 SD 范圍內,其余的 32% 離得較遠,
-
粗略的,95%(20分之19)的項在距平均數 2 個 SD 范圍內,其余 5% 則遠離之,
我想這可能就是顯著值 p = 0.05 的原因之一
對許多數列如此,但不是所有數列都這樣
應該是對正態分布或近似正態分布如此
3. 橫向截面與縱向跟蹤
我們要分清楚不同組的資料是
-
從同一時刻的不同物件橫向截面獲得
-
一直跟蹤同一個物件至多個時刻獲得
這兩種資料能得到的結論是完全不同的
在橫向截面統計得到的資料中,我們是無法得到一個指標隨著時間而變化的結論,因為其統計的只是物件在某一刻的資料,不具有時間上的變化性,
隨時間而變化的變化規律只能是針對同一個物件在時間上的遷移所產生的變化進行統計,
例如:想追蹤是否隨著年齡老化,許多人從左撇子改為右撇子?
可以對這 1000 個人或者更多人進行追蹤調查,然后將這些人在不同年齡段的左右手撇子的分布進行統計,這樣才能得到變化規律,
三、資料的正態近似
正態影像的特征:
-
關于 0 點對稱
-
曲線下面的總面積等于 100%(面積按百分數給出,因為縱軸使用了密度尺度)
即縱軸使用的是每標準單位的百分數
標準單位:標準單位個數是指一個數值在平均數之上或之下多少個 SD
一個標準單位就是一個 SD
所有正態分布都可以通過Z-Score公式轉換成標準正態分布,
正態曲線與直方圖:
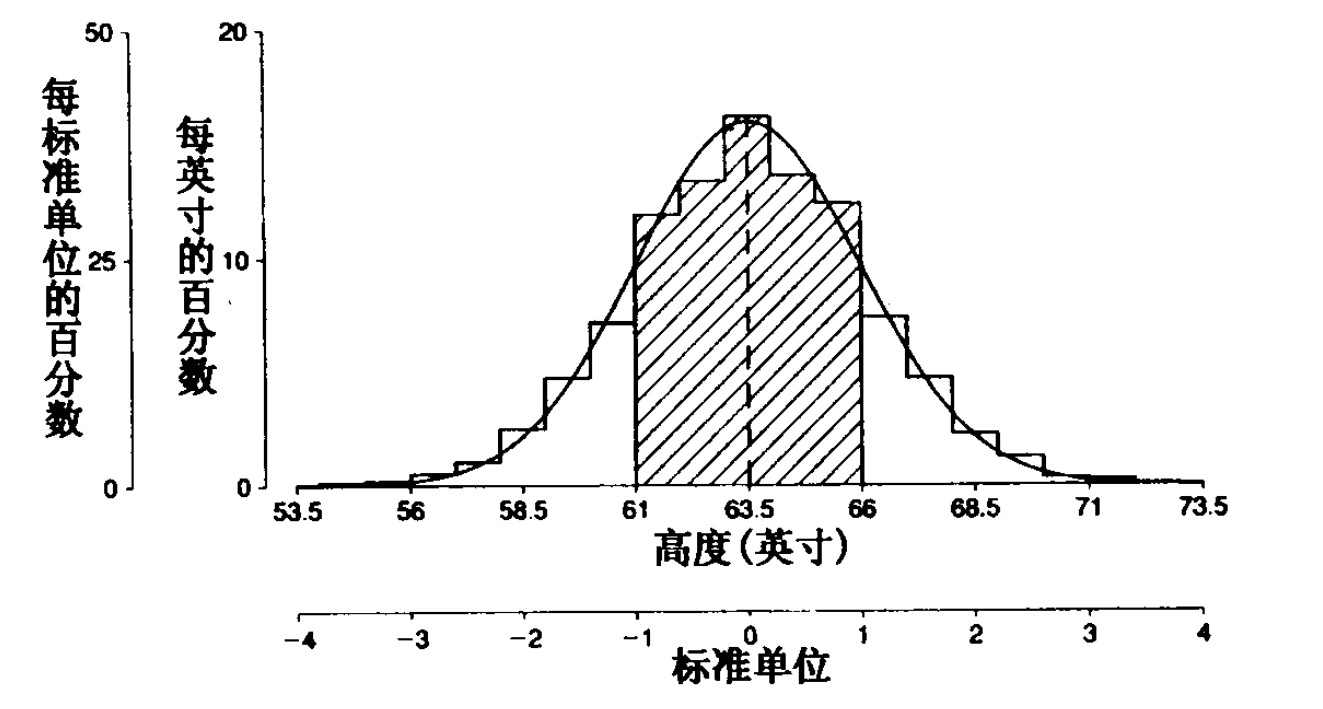
-
直方圖是按照每英寸的百分數繪制
-
正態曲線是按每標準單位的百分數繪制
可以看到,每標準單位 50% 與每英寸 20% 相配,因為對于每個標準單位(即SD)有 2.5 英寸
該處的標準單位對應特定的一組統計資料計算而出
我們查的表(即對應正態分布的表)都是以 SD 為標準單位的取值,
如果要換成原資料單位的話,需要進行換算,例如 SD = 100 cm,那么 1.65 換算成原單位就要變為 1.65 \(\times\) 100 = 165cm
四、百分位數
平均數和 SD 可以用來概括遵循正態曲線的資料,但對于其他型別的資料,它們是不令人滿意滴
存在一套數學理論來解釋什么時候直方圖會遵循正態曲線
對于非正態分布而言,用中心和SD去度量是不準確的,因為其具有偏度,資料在均值兩端的分布是不均衡的,
此時使用百分位數來衡量,即不同階段的人占百分之多少
常用的百分位數有:
25%、50%、75%
其中 75% - 25% 也被稱為四分位數間距
對于非正態分布而言,四分位數間距有時候用作散布的度量
即位于中間 50% 的物件數值分布的范圍有多大
百分位數與正態曲線
正態曲線同樣可以使用百分位數來描述
百分位數是通用的;
均值和 SD 相對來說更加限于描述正態曲線,
當然,并不是說只有符合正態分布的資料才有均值和 SD,而是說均值和 SD 在描述正態曲線上具有更好的意義,
同時,正態表可以用來估計百分位數
正態表就是以 0 為中心,SD 為標準單位進行計算并得到的資料表,
(1 個 SD(標準差) 算一個標準單位)
在對實際資料使用時,需要將中心換為實際資料的均值,SD 的標準單位換算為原資料的單位
總結
-
如果一列數遵循正態曲線,落在一個給定的區間內的項的百分數可以通過將區間換算成標準單位,然后求正態曲線下相應的面積而估計,這個程序叫正態近似;
-
一個遵循正態曲線的直方圖可以根據他的平均數和 SD 相當好的重新構建,這種情況下,平均數和 SD 是好的概括統計量;
-
所有正態分布都可以通過Z-Score公式轉換成標準正態分布,
-
所有直方圖,不管它們是否遵循正態曲線,可以使用百分位數來概括,
五、機會誤差
一系列重復測量的 SD 是單詞測量中機會誤差可能大小的估計
單獨測量值 = 精確值 + 機會誤差
離群點
極端的測量值被稱為離群點 ,
有時一些資料本來應該符合正態分布,但由于其離群點的原因,影響了 SD 的值,使得其在 1 SD 范圍內的資料量不符合 68% 左右,
此時可能需要進行離群點處理
這里有一段值得深思的話,由美國標準局給出:
在統計方法對于測量資料分析的應用中,一個主要困難是獲得合適的資料,問題是比較經常地有意識或者也許無疑是地試圖按照人們鎖了一地那樣構造一個特殊的實施程序,而不是接受真正的事實,給予任意的對實施程序的限制而拒絕資料會嚴重去接對實際變化的估計,這種做法使得原先計劃的目的失效,實際性能引數需要接受全部資料,它們不能由于某種原因而被摒棄,
就例如我們總希望資料符合正態分布,如果不符合總希望通過一些處理手段對資料進行洗掉或者其他的處理將其轉換,在這個程序中,有可能我們就篡改了資料背后的資訊,一定程度上是不嚴謹的,
但是我們通常還是選擇對離群點進行拋棄處理,這是理論戰勝了經驗,
偏性 / 系統誤差
與機會誤差對資料的影響是忽高忽低不同,偏性對資料的影響是將他們推向同一方向的,
如果在測量的程序中沒有偏性,大量重復測量值的平均數將給出待測物體的精確值,所有機會誤差將抵消
單獨測量值 = 精確值 + 偏度 + 機會誤差
總結
-
偏性就是 bias
-
機會誤差就是 variance
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/500412.html
標籤:其他
上一篇:On Java 8讀書筆記