調度框架 [1]
本文基于 kubernetes 1.24 進行分析
調度框架(Scheduling Framework)是Kubernetes 的調度器 kube-scheduler 設計的的可插拔架構,將插件(調度演算法)嵌入到調度背景關系的每個擴展點中,并編譯為 kube-scheduler
在 kube-scheduler 1.22 之后,在 pkg/scheduler/framework/interface.go 中定義了一個 Plugin 的 interface,這個 interface 作為了所有插件的父級,而每個未調度的 Pod,Kubernetes 調度器會根據一組規則嘗試在集群中尋找一個節點,
type Plugin interface {
Name() string
}
下面會對每個演算法是如何實作的進行分析
在初始化 scheduler 時,會創建一個 profile,profile是關于 scheduler 調度配置相關的定義
func New(client clientset.Interface,
...
profiles, err := profile.NewMap(options.profiles, registry, recorderFactory, stopCh,
frameworkruntime.WithComponentConfigVersion(options.componentConfigVersion),
frameworkruntime.WithClientSet(client),
frameworkruntime.WithKubeConfig(options.kubeConfig),
frameworkruntime.WithInformerFactory(informerFactory),
frameworkruntime.WithSnapshotSharedLister(snapshot),
frameworkruntime.WithPodNominator(nominator),
frameworkruntime.WithCaptureProfile(frameworkruntime.CaptureProfile(options.frameworkCapturer)),
frameworkruntime.WithClusterEventMap(clusterEventMap),
frameworkruntime.WithParallelism(int(options.parallelism)),
frameworkruntime.WithExtenders(extenders),
)
if err != nil {
return nil, fmt.Errorf("initializing profiles: %v", err)
}
if len(profiles) == 0 {
return nil, errors.New("at least one profile is required")
}
....
}
關于 profile 的實作,則為 KubeSchedulerProfile,也是作為 yaml生成時傳入的配置
// KubeSchedulerProfile 是一個 scheduling profile.
type KubeSchedulerProfile struct {
// SchedulerName 是與此組態檔關聯的調度程式的名稱,
// 如果 SchedulerName 與 pod “spec.schedulerName”匹配,則使用此組態檔調度 pod,
SchedulerName string
// Plugins指定應該啟用或禁用的插件集,
// 啟用的插件是除了默認插件之外應該啟用的插件,禁用插件應是禁用的任何默認插件,
// 當沒有為擴展點指定啟用或禁用插件時,將使用該擴展點的默認插件(如果有),
// 如果指定了 QueueSort 插件,
// 則必須為所有組態檔指定相同的 QueueSort Plugin 和 PluginConfig,
// 這個Plugins展現的形式則是調度背景關系中的所有擴展點(這是抽象),實際中會表現為多個擴展點
Plugins *Plugins
// PluginConfig 是每個插件的一組可選的自定義插件引數,
// 如果省略PluginConfig引數等同于使用該插件的默認配置,
PluginConfig []PluginConfig
}
對于 profile.NewMap 就是根據給定的配置來構建這個framework,因為配置可能是存在多個的,而 Registry 則是所有可用插件的集合,內部構造則是 PluginFactory ,通過函式來構建出對應的 plugin
func NewMap(cfgs []config.KubeSchedulerProfile, r frameworkruntime.Registry, recorderFact RecorderFactory,
stopCh <-chan struct{}, opts ...frameworkruntime.Option) (Map, error) {
m := make(Map)
v := cfgValidator{m: m}
for _, cfg := range cfgs {
p, err := newProfile(cfg, r, recorderFact, stopCh, opts...)
if err != nil {
return nil, fmt.Errorf("creating profile for scheduler name %s: %v", cfg.SchedulerName, err)
}
if err := v.validate(cfg, p); err != nil {
return nil, err
}
m[cfg.SchedulerName] = p
}
return m, nil
}
// newProfile 給的配置構建出一個profile
func newProfile(cfg config.KubeSchedulerProfile, r frameworkruntime.Registry, recorderFact RecorderFactory,
stopCh <-chan struct{}, opts ...frameworkruntime.Option) (framework.Framework, error) {
recorder := recorderFact(cfg.SchedulerName)
opts = append(opts, frameworkruntime.WithEventRecorder(recorder))
return frameworkruntime.NewFramework(r, &cfg, stopCh, opts...)
}
可以看到最侄訓傳的是一個 Framework ,那么來看下這個 Framework
Framework 是一個抽象,管理著調度程序中所使用的所有插件,并在調度背景關系中適當的位置去運行對應的插件
type Framework interface {
Handle
// QueueSortFunc 回傳對調度佇列中的 Pod 進行排序的函式
// 也就是less,在Sort打分階段的打分函式
QueueSortFunc() LessFunc
// RunPreFilterPlugins 運行配置的一組PreFilter插件,
// 如果這組插件中,任何一個插件失敗,則回傳 *Status 并設定為non-success,
// 如果回傳狀態為non-success,則調度周期中止,
// 它還回傳一個 PreFilterResult,它可能會影響到要評估下游的節點,
RunPreFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod) (*PreFilterResult, *Status)
// RunPostFilterPlugins 運行配置的一組PostFilter插件,
// PostFilter 插件是通知性插件,在這種情況下應配置為先執行并回傳 Unschedulable 狀態,
// 或者嘗試更改集群狀態以使 pod 在未來的調度周期中可能會被調度,
RunPostFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, filteredNodeStatusMap NodeToStatusMap) (*PostFilterResult, *Status)
// RunPreBindPlugins 運行配置的一組 PreBind 插件,
// 如果任何一個插件回傳錯誤,則回傳 *Status 并且code設定為non-success,
// 如果code為“Unschedulable”,則調度檢查失敗,
// 則認為是內部錯誤,在任何一種情況下,Pod都不會被bound,
RunPreBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
// RunPostBindPlugins 運行配置的一組PostBind插件
RunPostBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
// RunReservePluginsReserve運行配置的一組Reserve插件的Reserve方法,
// 如果在這組呼叫中的任何一個插件回傳錯誤,則不會繼續運行剩余呼叫的插件并回傳錯誤,
// 在這種情況下,pod將不能被調度,
RunReservePluginsReserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
// RunReservePluginsUnreserve運行配置的一組Reserve插件的Unreserve方法,
RunReservePluginsUnreserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
// RunPermitPlugins運行配置的一組Permit插件,
// 如果這些插件中的任何一個回傳“Success”或“Wait”之外的狀態,則它不會繼續運行其余插件并回傳錯誤,
// 否則,如果任何插件回傳 “Wait”,則此函式將創建等待pod并將其添加到當前等待pod的map中,
// 并使用“Wait” code回傳狀態, Pod將在Permit插件回傳的最短持續時間內保持等待pod,
RunPermitPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
// 如果pod是waiting pod,WaitOnPermit 將阻塞,直到等待的pod被允許或拒絕,
WaitOnPermit(ctx context.Context, pod *v1.Pod) *Status
// RunBindPlugins運行配置的一組bind插件, Bind插件可以選擇是否處理Pod,
// 如果 Bind 插件選擇跳過binding,它應該回傳 code=5("skip")狀態,
// 否則,它應該回傳“Error”或“Success”,
// 如果沒有插件處理系結,則RunBindPlugins回傳code=5("skip")的狀態,
RunBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
// 如果至少定義了一個filter插件,則HasFilterPlugins回傳true
HasFilterPlugins() bool
// 如果至少定義了一個PostFilter插件,則HasPostFilterPlugins回傳 true,
HasPostFilterPlugins() bool
// 如果至少定義了一個Score插件,則HasScorePlugins回傳 true,
HasScorePlugins() bool
// ListPlugins將回傳map,key為擴展點名稱,value則是配置的插件串列,
ListPlugins() *config.Plugins
// ProfileName則是與profile name關聯的framework
ProfileName() string
}
而實作這個抽象的則是 frameworkImpl;frameworkImpl 是初始化與運行 scheduler plugins 的組件,并在調度背景關系中會運行這些擴展點
type frameworkImpl struct {
registry Registry
snapshotSharedLister framework.SharedLister
waitingPods *waitingPodsMap
scorePluginWeight map[string]int
queueSortPlugins []framework.QueueSortPlugin
preFilterPlugins []framework.PreFilterPlugin
filterPlugins []framework.FilterPlugin
postFilterPlugins []framework.PostFilterPlugin
preScorePlugins []framework.PreScorePlugin
scorePlugins []framework.ScorePlugin
reservePlugins []framework.ReservePlugin
preBindPlugins []framework.PreBindPlugin
bindPlugins []framework.BindPlugin
postBindPlugins []framework.PostBindPlugin
permitPlugins []framework.PermitPlugin
clientSet clientset.Interface
kubeConfig *restclient.Config
eventRecorder events.EventRecorder
informerFactory informers.SharedInformerFactory
metricsRecorder *metricsRecorder
profileName string
extenders []framework.Extender
framework.PodNominator
parallelizer parallelize.Parallelizer
}
那么來看下 Registry ,Registry 是作為一個可用插件的集合,framework 使用 registry 來啟用和對插件配置的初始化,在初始化框架之前,所有插件都必須在注冊表中,表現形式就是一個 map[];key 是插件的名稱,value是 PluginFactory ,
type Registry map[string]PluginFactory
而在 pkg\scheduler\framework\plugins\registry.go 中會將所有的 in-tree plugin 注冊進來,通過 NewInTreeRegistry ,后續如果還有插件要注冊,可以通過 WithFrameworkOutOfTreeRegistry 來注冊其他的插件,
func NewInTreeRegistry() runtime.Registry {
fts := plfeature.Features{
EnableReadWriteOncePod: feature.DefaultFeatureGate.Enabled(features.ReadWriteOncePod),
EnableVolumeCapacityPriority: feature.DefaultFeatureGate.Enabled(features.VolumeCapacityPriority),
EnableMinDomainsInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.MinDomainsInPodTopologySpread),
EnableNodeInclusionPolicyInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.NodeInclusionPolicyInPodTopologySpread),
}
return runtime.Registry{
selectorspread.Name: selectorspread.New,
imagelocality.Name: imagelocality.New,
tainttoleration.Name: tainttoleration.New,
nodename.Name: nodename.New,
nodeports.Name: nodeports.New,
nodeaffinity.Name: nodeaffinity.New,
podtopologyspread.Name: runtime.FactoryAdapter(fts, podtopologyspread.New),
nodeunschedulable.Name: nodeunschedulable.New,
noderesources.Name: runtime.FactoryAdapter(fts, noderesources.NewFit),
noderesources.BalancedAllocationName: runtime.FactoryAdapter(fts, noderesources.NewBalancedAllocation),
volumebinding.Name: runtime.FactoryAdapter(fts, volumebinding.New),
volumerestrictions.Name: runtime.FactoryAdapter(fts, volumerestrictions.New),
volumezone.Name: volumezone.New,
nodevolumelimits.CSIName: runtime.FactoryAdapter(fts, nodevolumelimits.NewCSI),
nodevolumelimits.EBSName: runtime.FactoryAdapter(fts, nodevolumelimits.NewEBS),
nodevolumelimits.GCEPDName: runtime.FactoryAdapter(fts, nodevolumelimits.NewGCEPD),
nodevolumelimits.AzureDiskName: runtime.FactoryAdapter(fts, nodevolumelimits.NewAzureDisk),
nodevolumelimits.CinderName: runtime.FactoryAdapter(fts, nodevolumelimits.NewCinder),
interpodaffinity.Name: interpodaffinity.New,
queuesort.Name: queuesort.New,
defaultbinder.Name: defaultbinder.New,
defaultpreemption.Name: runtime.FactoryAdapter(fts, defaultpreemption.New),
}
}
這里插入一個題外話,關于 in-tree plugin
在這里沒有找到關于,kube-scheduler ,只是找到有關的概念,大概可以解釋為,in-tree表示為隨kubernetes官方提供的二進制構建的 plugin 則為
in-tree,而獨立于kubernetes代碼庫之外的為out-of-tree[3] ,這種情況下,可以理解為,AA則是out-of-tree而Pod,DeplymentSet等是in-tree,
接下來回到初始化 scheduler ,在初始化一個 scheduler 時,會通過NewInTreeRegistry 來初始化
func New(client clientset.Interface,
....
registry := frameworkplugins.NewInTreeRegistry()
if err := registry.Merge(options.frameworkOutOfTreeRegistry); err != nil {
return nil, err
}
...
profiles, err := profile.NewMap(options.profiles, registry, recorderFactory, stopCh,
frameworkruntime.WithComponentConfigVersion(options.componentConfigVersion),
frameworkruntime.WithClientSet(client),
frameworkruntime.WithKubeConfig(options.kubeConfig),
frameworkruntime.WithInformerFactory(informerFactory),
frameworkruntime.WithSnapshotSharedLister(snapshot),
frameworkruntime.WithPodNominator(nominator),
frameworkruntime.WithCaptureProfile(frameworkruntime.CaptureProfile(options.frameworkCapturer)),
frameworkruntime.WithClusterEventMap(clusterEventMap),
frameworkruntime.WithParallelism(int(options.parallelism)),
frameworkruntime.WithExtenders(extenders),
)
...
}
接下來在調度背景關系 scheduleOne 中 schedulePod 時,會通過 framework 呼叫對應的插件來處理這個擴展點作業,具體的體現在,pkg\scheduler\schedule_one.go 中的預選階段
func (sched *Scheduler) schedulePod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
trace := utiltrace.New("Scheduling", utiltrace.Field{Key: "namespace", Value: pod.Namespace}, utiltrace.Field{Key: "name", Value: pod.Name})
defer trace.LogIfLong(100 * time.Millisecond)
if err := sched.Cache.UpdateSnapshot(sched.nodeInfoSnapshot); err != nil {
return result, err
}
trace.Step("Snapshotting scheduler cache and node infos done")
if sched.nodeInfoSnapshot.NumNodes() == 0 {
return result, ErrNoNodesAvailable
}
feasibleNodes, diagnosis, err := sched.findNodesThatFitPod(ctx, fwk, state, pod)
if err != nil {
return result, err
}
trace.Step("Computing predicates done")
與其他擴展點部分,在調度背景關系 scheduleOne 中可以很好的看出,功能都是 framework 提供的,
func (sched *Scheduler) scheduleOne(ctx context.Context) {
...
scheduleResult, err := sched.SchedulePod(schedulingCycleCtx, fwk, state, pod)
...
// Run the Reserve method of reserve plugins.
if sts := fwk.RunReservePluginsReserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() {
}
...
// Run "permit" plugins.
runPermitStatus := fwk.RunPermitPlugins(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
// One of the plugins returned status different than success or wait.
fwk.RunReservePluginsUnreserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
...
// bind the pod to its host asynchronously (we can do this b/c of the assumption step above).
go func() {
...
waitOnPermitStatus := fwk.WaitOnPermit(bindingCycleCtx, assumedPod)
if !waitOnPermitStatus.IsSuccess() {
...
// trigger un-reserve plugins to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
}
// Run "prebind" plugins.
preBindStatus := fwk.RunPreBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
...
// trigger un-reserve plugins to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
...
...
// trigger un-reserve plugins to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
...
// Run "postbind" plugins.
fwk.RunPostBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
...
}
插件 [4]
插件(Plugins)(也可以算是調度策略)在 kube-scheduler 中的實作為 framework plugin,插件API的實作分為兩個步驟:register 和 configured,然后都實作了其父方法 Plugin,然后可以通過配置(kube-scheduler --config 提供)啟動或禁用插件;除了默認插件外,還可以實作自定義調度插件與默認插件進行系結,
type Plugin interface {
Name() string
}
// sort擴展點
type QueueSortPlugin interface {
Plugin
Less(*v1.pod, *v1.pod) bool
}
// PreFilter擴展點
type PreFilterPlugin interface {
Plugin
PreFilter(context.Context, *framework.CycleState, *v1.pod) error
}
插件的載入程序
在 scheduler 被啟動時,會 scheduler.New(cc.Client.. 這個時候會傳入 profiles,整個的流如下:
NewScheduler:kubernetes/cmd/kube-scheduler/app/server.goprofile.NewMap:kubernetes/pkg/scheduler/scheduler.gonewProfile:kubernetes/pkg/scheduler/scheduler.go
frameworkruntime.NewFramework:kubernetes/pkg/scheduler/framework/runtime/framework.gopluginsNeeded:kubernetes/pkg/scheduler/framework/runtime/framework.go
NewScheduler
我們了解如何 New 一個 scheduler 即為 Setup 中去配置這些引數,
func Setup(ctx context.Context, opts *options.Options, outOfTreeRegistryOptions ...Option) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) {
...
// Create the scheduler.
sched, err := scheduler.New(cc.Client,
cc.InformerFactory,
cc.DynInformerFactory,
recorderFactory,
ctx.Done(),
scheduler.WithComponentConfigVersion(cc.ComponentConfig.TypeMeta.APIVersion),
scheduler.WithKubeConfig(cc.KubeConfig),
scheduler.WithProfiles(cc.ComponentConfig.Profiles...),
scheduler.WithPercentageOfNodesToScore(cc.ComponentConfig.PercentageOfNodesToScore),
scheduler.WithFrameworkOutOfTreeRegistry(outOfTreeRegistry),
scheduler.WithPodMaxBackoffSeconds(cc.ComponentConfig.PodMaxBackoffSeconds),
scheduler.WithPodInitialBackoffSeconds(cc.ComponentConfig.PodInitialBackoffSeconds),
scheduler.WithPodMaxInUnschedulablePodsDuration(cc.PodMaxInUnschedulablePodsDuration),
scheduler.WithExtenders(cc.ComponentConfig.Extenders...),
scheduler.WithParallelism(cc.ComponentConfig.Parallelism),
scheduler.WithBuildFrameworkCapturer(func(profile kubeschedulerconfig.KubeSchedulerProfile) {
// Profiles are processed during Framework instantiation to set default plugins and configurations. Capturing them for logging
completedProfiles = append(completedProfiles, profile)
}),
)
...
}
profile.NewMap
在 scheduler.New 中,會根據配置生成profile,而 profile.NewMap 會完成這一步
func New(client clientset.Interface,
...
clusterEventMap := make(map[framework.ClusterEvent]sets.String)
profiles, err := profile.NewMap(options.profiles, registry, recorderFactory, stopCh,
frameworkruntime.WithComponentConfigVersion(options.componentConfigVersion),
frameworkruntime.WithClientSet(client),
frameworkruntime.WithKubeConfig(options.kubeConfig),
frameworkruntime.WithInformerFactory(informerFactory),
frameworkruntime.WithSnapshotSharedLister(snapshot),
frameworkruntime.WithPodNominator(nominator),
frameworkruntime.WithCaptureProfile(frameworkruntime.CaptureProfile(options.frameworkCapturer)),
frameworkruntime.WithClusterEventMap(clusterEventMap),
frameworkruntime.WithParallelism(int(options.parallelism)),
frameworkruntime.WithExtenders(extenders),
)
...
}
NewFramework
newProfile 回傳的則是一個創建好的 framework
func newProfile(cfg config.KubeSchedulerProfile, r frameworkruntime.Registry, recorderFact RecorderFactory,
stopCh <-chan struct{}, opts ...frameworkruntime.Option) (framework.Framework, error) {
recorder := recorderFact(cfg.SchedulerName)
opts = append(opts, frameworkruntime.WithEventRecorder(recorder))
return frameworkruntime.NewFramework(r, &cfg, stopCh, opts...)
}
最侄訓走到 pluginsNeeded,這里會根據配置中開啟的插件而回傳一個插件集,這個就是最終在每個擴展點中藥執行的插件,
func (f *frameworkImpl) pluginsNeeded(plugins *config.Plugins) sets.String {
pgSet := sets.String{}
if plugins == nil {
return pgSet
}
find := func(pgs *config.PluginSet) {
for _, pg := range pgs.Enabled {
pgSet.Insert(pg.Name)
}
}
// 獲取到所有的擴展點,找到為Enabled的插件加入到pgSet
for _, e := range f.getExtensionPoints(plugins) {
find(e.plugins)
}
// Parse MultiPoint separately since they are not returned by f.getExtensionPoints()
find(&plugins.MultiPoint)
return pgSet
}
插件的執行
在對插件原始碼部分分析,會找幾個典型的插件進行分析,而不會對全部的進行分析,因為總的來說是大同小異,分析的插件有 NodePorts,NodeResourcesFit,podtopologyspread
NodePorts
這里以一個簡單的插件來分析;NodePorts 插件用于檢查Pod請求的埠,在節點上是否為空閑埠,
NodePorts 實作了 FilterPlugin 和 PreFilterPlugin
PreFilter 將會被 framework 中 PreFilter 擴展點被呼叫,
func (pl *NodePorts) PreFilter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod) (*framework.PreFilterResult, *framework.Status) {
s := getContainerPorts(pod) // 或得Pod得埠
// 寫入狀態
cycleState.Write(preFilterStateKey, preFilterState(s))
return nil, nil
}
Filter 將會被 framework 中 Filter 擴展點被呼叫,
// Filter invoked at the filter extension point.
func (pl *NodePorts) Filter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
wantPorts, err := getPreFilterState(cycleState)
if err != nil {
return framework.AsStatus(err)
}
fits := fitsPorts(wantPorts, nodeInfo)
if !fits {
return framework.NewStatus(framework.Unschedulable, ErrReason)
}
return nil
}
func fitsPorts(wantPorts []*v1.ContainerPort, nodeInfo *framework.NodeInfo) bool {
// 對比existingPorts 和 wantPorts是否沖突,沖突則調度失敗
existingPorts := nodeInfo.UsedPorts
for _, cp := range wantPorts {
if existingPorts.CheckConflict(cp.HostIP, string(cp.Protocol), cp.HostPort) {
return false
}
}
return true
}
New ,初始化新插件,在 register 中注冊得
func New(_ runtime.Object, _ framework.Handle) (framework.Plugin, error) {
return &NodePorts{}, nil
}
在呼叫中,如果有任何一個插件回傳錯誤,則跳過該擴展點注冊得其他插件,回傳失敗,
func (f *frameworkImpl) RunFilterPlugins(
ctx context.Context,
state *framework.CycleState,
pod *v1.Pod,
nodeInfo *framework.NodeInfo,
) framework.PluginToStatus {
statuses := make(framework.PluginToStatus)
for _, pl := range f.filterPlugins {
pluginStatus := f.runFilterPlugin(ctx, pl, state, pod, nodeInfo)
if !pluginStatus.IsSuccess() {
if !pluginStatus.IsUnschedulable()
errStatus := framework.AsStatus(fmt.Errorf("running %q filter plugin: %w", pl.Name(), pluginStatus.AsError())).WithFailedPlugin(pl.Name())
return map[string]*framework.Status{pl.Name(): errStatus}
}
pluginStatus.SetFailedPlugin(pl.Name())
statuses[pl.Name()] = pluginStatus
}
}
return statuses
}
回傳得狀態是一個 Status 結構體,該結構體表示了插件運行的結果,由 Code、reasons、(可選)err 和 failedPlugin (失敗的那個插件名)組成,當 code 不是 Success 時,應說明原因,而且,當 code 為 Success 時,其他所有欄位都應為空,nil 狀態也被視為成功,
type Status struct {
code Code
reasons []string
err error
// failedPlugin is an optional field that records the plugin name a Pod failed by.
// It's set by the framework when code is Error, Unschedulable or UnschedulableAndUnresolvable.
failedPlugin string
}
NodeResourcesFit [5]
NodeResourcesFit 擴展檢查節點是否擁有 Pod 請求的所有資源,分數可以使用以下三種策略之一,擴展點為:preFilter, filter,score
LeastAllocated(默認)MostAllocatedRequestedToCapacityRatio
Fit
NodeResourcesFit PreFilter 可以看到呼叫得 computePodResourceRequest
// PreFilter invoked at the prefilter extension point.
func (f *Fit) PreFilter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod) (*framework.PreFilterResult, *framework.Status) {
cycleState.Write(preFilterStateKey, computePodResourceRequest(pod))
return nil, nil
}
computePodResourceRequest 這里有一個注釋,總體解釋起來是這樣得:computePodResourceRequest ,回傳值( framework.Resource)覆寫了每一個維度中資源的最大寬度,因為將按照 init-containers , containers 得順序運行,會通過迭代方式收集每個維度中的最大值,計算時會對常規容器的資源向量求和,因為containers 運行會同時運行多個容器,計算示例為:
Pod:
InitContainers
IC1:
CPU: 2
Memory: 1G
IC2:
CPU: 2
Memory: 3G
Containers
C1:
CPU: 2
Memory: 1G
C2:
CPU: 1
Memory: 1G
在維度1中(InitContainers)所需資源最大值時,CPU=2, Memory=3G;而維度2(Containers)所需資源最大值為:CPU=2, Memory=1G;那么最終結果為 CPU=3, Memory=3G,因為在維度1,最大資源時Memory=3G;而維度2最大資源是CPU=1+2, Memory=1+1,取每個維度中最大資源最大寬度即為 CPU=3, Memory=3G,
下面則看下代碼得實作
func computePodResourceRequest(pod *v1.Pod) *preFilterState {
result := &preFilterState{}
for _, container := range pod.Spec.Containers {
result.Add(container.Resources.Requests)
}
// 取最大得資源
for _, container := range pod.Spec.InitContainers {
result.SetMaxResource(container.Resources.Requests)
}
// 如果Overhead正在使用,需要將其計算到總資源中
if pod.Spec.Overhead != nil {
result.Add(pod.Spec.Overhead)
}
return result
}
// SetMaxResource 是比較ResourceList并為每個資源取最大值,
func (r *Resource) SetMaxResource(rl v1.ResourceList) {
if r == nil {
return
}
for rName, rQuantity := range rl {
switch rName {
case v1.ResourceMemory:
r.Memory = max(r.Memory, rQuantity.Value())
case v1.ResourceCPU:
r.MilliCPU = max(r.MilliCPU, rQuantity.MilliValue())
case v1.ResourceEphemeralStorage:
if utilfeature.DefaultFeatureGate.Enabled(features.LocalStorageCapacityIsolation) {
r.EphemeralStorage = max(r.EphemeralStorage, rQuantity.Value())
}
default:
if schedutil.IsScalarResourceName(rName) {
r.SetScalar(rName, max(r.ScalarResources[rName], rQuantity.Value()))
}
}
}
}
leastAllocate
LeastAllocated 是 NodeResourcesFit 的打分策略 ,LeastAllocated 打分的標準是更偏向于請求資源較少的Node,將會先計算出Node上調度的pod請求的記憶體、CPU與其他資源的百分比,然后并根據請求的比例與容量的平均值的最小值進行優先級排序,
計算公式是這樣的:\(\frac{\frac{cpu((capacity-requested) \times MaxNodeScore \times cpuWeight)}{capacity} + \frac{memory((capacity-requested) \times MaxNodeScore \times memoryWeight}{capacity}) + ...}{weightSum}\)
下面來看下實作
func leastResourceScorer(resToWeightMap resourceToWeightMap) func(resourceToValueMap, resourceToValueMap) int64 {
return func(requested, allocable resourceToValueMap) int64 {
var nodeScore, weightSum int64
for resource := range requested {
weight := resToWeightMap[resource]
// 計算出的資源分數乘weight
resourceScore := leastRequestedScore(requested[resource], allocable[resource])
nodeScore += resourceScore * weight
weightSum += weight
}
if weightSum == 0 {
return 0
}
// 最終除weightSum
return nodeScore / weightSum
}
}
leastRequestedScore 計算標準為未使用容量的計算范圍為 0~MaxNodeScore,0 為最低優先級,MaxNodeScore 為最高優先級,未使用的資源越多,得分越高,
func leastRequestedScore(requested, capacity int64) int64 {
if capacity == 0 {
return 0
}
if requested > capacity {
return 0
}
// 容量 - 請求的 x 預期值(100)/ 容量
return ((capacity - requested) * int64(framework.MaxNodeScore)) / capacity
}
Topology [6]
Concept
在對 podtopologyspread 插件進行分析前,先需要掌握Pod拓撲的概念,
Pod拓撲(Pod Topology)是Kubernetes Pod調度機制,可以將Pod分布在集群中不同 Zone ,以及用戶自定義的各種拓撲域 (topology domains),當有了拓撲域后,用戶可以更高效的利用集群資源,
如何來解釋拓撲域,首先需要提及為什么需要拓撲域,在集群有3個節點,并且當Pod副本數為2時,又不希望兩個Pod在同一個Node上運行,在隨著擴大Pod的規模,副本數擴展到到15個時,這時候最理想的方式是每個Node運行5個Pod,在這種背景下,用戶希望對集群中Zone的安排為相似的副本數量,并且在集群存在部分問題時可以更好的自愈(也是按照相似的副本數量均勻的分布在Node上),在這種情況下Kubernetes 提供了Pod 拓撲約束來解決這個問題,
定義一個Topology
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# Configure a topology spread constraint
topologySpreadConstraints:
- maxSkew: <integer> #
minDomains: <integer> # optional; alpha since v1.24
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
引數的描述:
- maxSkew:Required,Pod分布不均的程度,并且數字必須大于零
- 當
whenUnsatisfiable: DoNotSchedule,則定義目標拓撲中匹配 pod 的數量與 全域最小值(拓撲域中的標簽選擇器匹配的 pod 的最小數量 )maxSkew之間的最大允許差異,例如有 3 個Zone,分別具有 2、4 和 5 個匹配的 pod,則全域最小值為 2 - 當
whenUnsatisfiable: ScheduleAnyway,scheduler 會為減少傾斜的拓撲提供更高的優先級,
- 當
- minDomains:optional,符合條件的域的最小數量,
- 如果不指定該選項
minDomains,則約束的行為minDomains: 1, minDomains必須大于 0,minDomains與whenUnsatisfiable一起時為whenUnsatisfiable: DoNotSchedule,
- 如果不指定該選項
- topologyKey:Node label的key,如果多個Node都使用了這個lable key那么 scheduler 將這些 Node 看作為相同的拓撲域,
- whenUnsatisfiable:當 Pod 不滿足分布的約束時,怎么去處理
DoNotSchedule(默認)不要調度,ScheduleAnyway仍然調度它,同時優先考慮最小化傾斜節點
- labelSelector:查找匹配的 Pod label選擇器的node進行技術,以計算Pod如何分布在拓撲域中
對于拓撲域的理解
對于拓撲域,官方是這么說明的,假設有一個帶有以下lable的 4 節點集群:
NAME STATUS ROLES AGE VERSION LABELS
node1 Ready <none> 4m26s v1.16.0 node=node1,zone=zoneA
node2 Ready <none> 3m58s v1.16.0 node=node2,zone=zoneA
node3 Ready <none> 3m17s v1.16.0 node=node3,zone=zoneB
node4 Ready <none> 2m43s v1.16.0 node=node4,zone=zoneB
那么集群拓撲如圖:

假設一個 4 節點集群,其中 3個label被標記為foo: bar的 Pod 分別位于Node1、Node2 和 Node3:
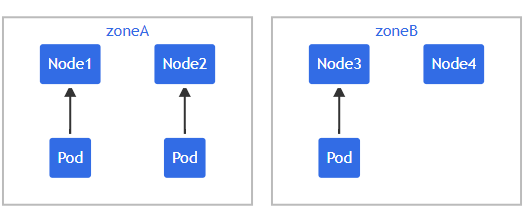
這種情況下,新部署一個Pod,并希望新Pod與現有Pod跨 Zone均勻分布,資源清單檔案如下:
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: k8s.gcr.io/pause:3.1
這個清單對于拓撲域來說,topologyKey: zone 表示對Pod均勻分布僅應用于已標記的節點(如 foo: bar),將會跳過沒有標簽的節點(如zone: <any value>),如果 scheduler 找不到滿足約束的方法,whenUnsatisfiable: DoNotSchedule 設定的策略則是 scheduler 對新部署的Pod保持 Pendding
如果此時 scheduler 將新Pod 調度至 \(Zone_A\),此時Pod分布在拓撲域間為 \([3,1]\) ,而 maxSkew 配置的值是1,此時傾斜值為 \(Zone_A - Zone_B = 3-1=2\),不滿足 maxSkew=1,故這個Pod只能被調度到 \(Zone_B\),
此時Pod調度拓撲圖為圖3或圖4
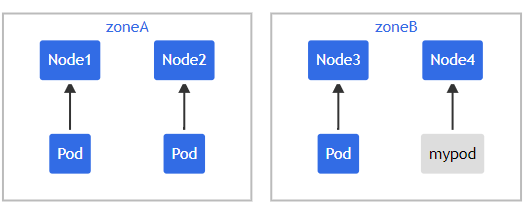
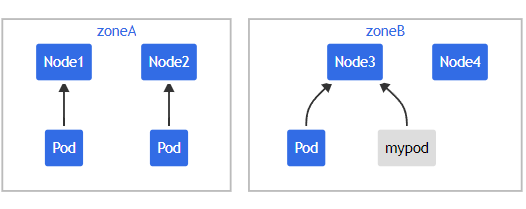
如果需要將Pod調度到 \(Zone_A\) ,可以按照如下方式進行:
- 修改
maxSkew=2 - 修改
topologyKey: node而不是Zone,這種模式下可以將 Pod 均勻分布在Node而不是Zone之間, - 修改
whenUnsatisfiable: DoNotSchedule為whenUnsatisfiable: ScheduleAnyway確保新的Pod始終可被調度
下面再通過一個例子增強對拓撲域了解
多拓撲約束
設擁有一個 4 節點集群,其中 3 個現有 Pod 標記 foo: bar 分別位于 node1、node2 和 node3
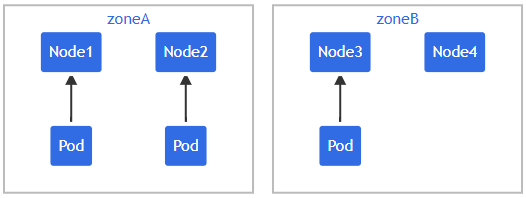
部署的資源清單如下:可以看出拓撲分布約束配置了多個
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
- maxSkew: 1
topologyKey: node
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: k8s.gcr.io/pause:3.1
在這種情況下,為了匹配第一個約束條件,新Pod 只能放置在 \(Zone_B\) ;而就第二個約束條件,新Pod只能調度到 node4,在這種配置多約束條件下, scheduler 只考慮滿足所有約束的值,因此唯一有效的是 node4,
如何為集群設定一個默認拓撲域約束
默認情況下,拓撲域約束也作 scheduler 的為 scheduler configurtion 中的一部分引數,這也意味著,可以通過profile為整個集群級別指定一個默認的拓撲域調度約束,
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
defaultingType: List
默認約束策略
如果在沒有配置集群級別的約束策略時,kube-scheduler 內部 topologyspread 插件提供了一個默認的拓撲約束策略,大致上如下列清單所示
defaultConstraints:
- maxSkew: 3
topologyKey: "kubernetes.io/hostname"
whenUnsatisfiable: ScheduleAnyway
- maxSkew: 5
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: ScheduleAnyway
上述清單中內容可以在 pkg\scheduler\framework\plugins\podtopologyspread\plugin.go
var systemDefaultConstraints = []v1.TopologySpreadConstraint{
{
TopologyKey: v1.LabelHostname,
WhenUnsatisfiable: v1.ScheduleAnyway,
MaxSkew: 3,
},
{
TopologyKey: v1.LabelTopologyZone,
WhenUnsatisfiable: v1.ScheduleAnyway,
MaxSkew: 5,
},
}
可以通過在組態檔中留空,來禁用默認配置
defaultConstraints: []defaultingType: List
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints: []
defaultingType: List
通過原始碼學習Topology
podtopologyspread 實作了4種擴展點方法,包含 filter 和 score
PreFilter
可以看到 PreFilter 的核心為 calPreFilterState
func (pl *PodTopologySpread) PreFilter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod) (*framework.PreFilterResult, *framework.Status) {
s, err := pl.calPreFilterState(ctx, pod)
if err != nil {
return nil, framework.AsStatus(err)
}
cycleState.Write(preFilterStateKey, s)
return nil, nil
}
calPreFilterState 主要功能是用在計算如何在拓撲域中分布Pod,首先看段代碼時,需要掌握下屬幾個概念
- preFilterState
- criticalPaths
- update
func (pl *PodTopologySpread) calPreFilterState(ctx context.Context, pod *v1.Pod) (*preFilterState, error) {
// 獲取Node
allNodes, err := pl.sharedLister.NodeInfos().List()
if err != nil {
return nil, fmt.Errorf("listing NodeInfos: %w", err)
}
var constraints []topologySpreadConstraint
if len(pod.Spec.TopologySpreadConstraints) > 0 {
// 這里會構建出TopologySpreadConstraints,因為約束是不確定的
constraints, err = filterTopologySpreadConstraints(
pod.Spec.TopologySpreadConstraints,
v1.DoNotSchedule,
pl.enableMinDomainsInPodTopologySpread,
pl.enableNodeInclusionPolicyInPodTopologySpread,
)
if err != nil {
return nil, fmt.Errorf("obtaining pod's hard topology spread constraints: %w", err)
}
} else {
// buildDefaultConstraints使用".DefaultConstraints"與pod匹配的
// service、replication controllers、replica sets
// 和stateful sets的選擇器為pod構建一個約束,
constraints, err = pl.buildDefaultConstraints(pod, v1.DoNotSchedule)
if err != nil {
return nil, fmt.Errorf("setting default hard topology spread constraints: %w", err)
}
}
if len(constraints) == 0 { // 如果是空的,則回傳空preFilterState
return &preFilterState{}, nil
}
// 初始化一個 preFilterState 狀態
s := preFilterState{
Constraints: constraints,
TpKeyToCriticalPaths: make(map[string]*criticalPaths, len(constraints)),
TpPairToMatchNum: make(map[topologyPair]int, sizeHeuristic(len(allNodes), constraints)),
}
// 根據node統計拓撲域數量
tpCountsByNode := make([]map[topologyPair]int, len(allNodes))
// 獲取pod親和度配置
requiredNodeAffinity := nodeaffinity.GetRequiredNodeAffinity(pod)
processNode := func(i int) {
nodeInfo := allNodes[i]
node := nodeInfo.Node()
if node == nil {
klog.ErrorS(nil, "Node not found")
return
}
// 通過spreading去過濾node以用作filters,錯誤決議以向后兼容
if !pl.enableNodeInclusionPolicyInPodTopologySpread {
if match, _ := requiredNodeAffinity.Match(node); !match {
return
}
}
// 確保node的lable 包含topologyKeys定義的值
if !nodeLabelsMatchSpreadConstraints(node.Labels, constraints) {
return
}
tpCounts := make(map[topologyPair]int, len(constraints))
for _, c := range constraints { // 對應的約束串列
if pl.enableNodeInclusionPolicyInPodTopologySpread &&
!c.matchNodeInclusionPolicies(pod, node, requiredNodeAffinity) {
continue
}
// 構建出 topologyPair 以key value形式,
// 通常情況下TopologyKey屬于什么型別的拓撲
// node.Labels[c.TopologyKey] 則是屬于這個拓撲中那個子域
pair := topologyPair{key: c.TopologyKey, value: node.Labels[c.TopologyKey]}
// 計算與標簽選擇器相匹配的pod有多少個
count := countPodsMatchSelector(nodeInfo.Pods, c.Selector, pod.Namespace)
tpCounts[pair] = count
}
tpCountsByNode[i] = tpCounts // 最終形成的拓撲結構
}
// 執行上面的定義的processNode,執行的數量就是node的數量
pl.parallelizer.Until(ctx, len(allNodes), processNode)
// 最后構建出 TpPairToMatchNum
// 表示每個拓撲域中的每個子域各分布多少Pod,如圖6所示
for _, tpCounts := range tpCountsByNode {
for tp, count := range tpCounts {
s.TpPairToMatchNum[tp] += count
}
}
if pl.enableMinDomainsInPodTopologySpread {
// 根據狀態進行構建 preFilterState
s.TpKeyToDomainsNum = make(map[string]int, len(constraints))
for tp := range s.TpPairToMatchNum {
s.TpKeyToDomainsNum[tp.key]++
}
}
// 計算最小匹配出的拓撲對
for i := 0; i < len(constraints); i++ {
key := constraints[i].TopologyKey
s.TpKeyToCriticalPaths[key] = newCriticalPaths()
}
for pair, num := range s.TpPairToMatchNum {
s.TpKeyToCriticalPaths[pair.key].update(pair.value, num)
}
return &s, nil // 回傳的值則包含最小的分布
}
preFilterState
// preFilterState 是在PreFilter處計算并在Filter處使用,
// 它結合了 “TpKeyToCriticalPaths” 和 “TpPairToMatchNum” 來表示:
//(1)在每個分布約束上匹配最少pod的criticalPaths,
// (2) 在每個分布約束上匹配的pod的數量,
// “nil preFilterState” 則表示沒有設定(在PreFilter階段);
// empty “preFilterState”物件則表示它是一個合法的狀態,并在PreFilter階段設定,
type preFilterState struct {
Constraints []topologySpreadConstraint
// 這里記錄2條關鍵路徑而不是所有關鍵路徑,
// criticalPaths[0].MatchNum 始終保存最小匹配數,
// criticalPaths[1].MatchNum 總是大于或等于criticalPaths[0].MatchNum,但不能保證是第二個最小匹配數,
TpKeyToCriticalPaths map[string]*criticalPaths
// TpKeyToDomainsNum 以 “topologyKey” 作為key ,并以zone的數量作為值,
TpKeyToDomainsNum map[string]int
// TpPairToMatchNum 以 “topologyPair作為key” ,并以匹配到pod的數量作為value,
TpPairToMatchNum map[topologyPair]int
}
criticalPaths
// [2]criticalPath能夠作業的原因是基于當前搶占演算法的實作,特別是以下兩個事實
// 事實 1:只搶占同一節點上的Pod,而不是多個節點上的 Pod,
// 事實 2:每個節點在其搶占周期期間在“preFilterState”的單獨副本上進行評估,如果我們計劃轉向更復雜的演算法,例如“多個節點上的任意pod”時則需要重新考慮這種結構,
type criticalPaths [2]struct {
// TopologyValue代表映射到拓撲鍵的拓撲值,
TopologyValue string
// MatchNum代表匹配到的pod數量
MatchNum int
}
單元測驗中的測驗案例,具有兩個約束條件的場景,通過表格來決議如下:
Node串列與標簽如下表:
| Node Name | ???Lable-zone | ???Lable-node |
|---|---|---|
| node-a | zone1 | node-a |
| node-b | zone1 | node-b |
| node-x | zone2 | node-x |
| node-y | zone2 | node-y |
Pod串列與標簽如下表:
| Pod Name | Node | ???Label |
|---|---|---|
| p-a1 | node-a | foo: |
| p-a2 | node-a | foo: |
| p-b1 | node-b | foo: |
| p-y1 | node-y | foo: |
| p-y2 | node-y | foo: |
| p-y3 | node-y | foo: |
| p-y4 | node-y | foo: |
對應的拓撲約束
spec:
topologySpreadConstraints:
- MaxSkew: 1
TopologyKey: zone
labelSelector:
matchLabels:
foo: bar
MinDomains: 1
NodeAffinityPolicy: Honor
NodeTaintsPolicy: Ignore
- MaxSkew: 1
TopologyKey: node
labelSelector:
matchLabels:
foo: bar
MinDomains: 1
NodeAffinityPolicy: Honor
NodeTaintsPolicy: Ignore
那么整個分布如下:
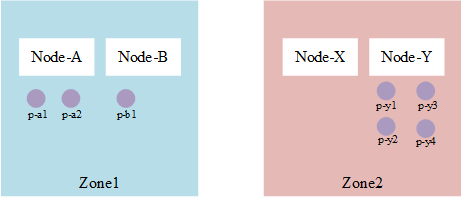
實作的測驗代碼如下
{
name: "normal case with two spreadConstraints",
pod: st.MakePod().Name("p").Label("foo", "").
SpreadConstraint(1, "zone", v1.DoNotSchedule, fooSelector, nil, nil, nil).
SpreadConstraint(1, "node", v1.DoNotSchedule, fooSelector, nil, nil, nil).
Obj(),
nodes: []*v1.Node{
st.MakeNode().Name("node-a").Label("zone", "zone1").Label("node", "node-a").Obj(),
st.MakeNode().Name("node-b").Label("zone", "zone1").Label("node", "node-b").Obj(),
st.MakeNode().Name("node-x").Label("zone", "zone2").Label("node", "node-x").Obj(),
st.MakeNode().Name("node-y").Label("zone", "zone2").Label("node", "node-y").Obj(),
},
existingPods: []*v1.Pod{
st.MakePod().Name("p-a1").Node("node-a").Label("foo", "").Obj(),
st.MakePod().Name("p-a2").Node("node-a").Label("foo", "").Obj(),
st.MakePod().Name("p-b1").Node("node-b").Label("foo", "").Obj(),
st.MakePod().Name("p-y1").Node("node-y").Label("foo", "").Obj(),
st.MakePod().Name("p-y2").Node("node-y").Label("foo", "").Obj(),
st.MakePod().Name("p-y3").Node("node-y").Label("foo", "").Obj(),
st.MakePod().Name("p-y4").Node("node-y").Label("foo", "").Obj(),
},
want: &preFilterState{
Constraints: []topologySpreadConstraint{
{
MaxSkew: 1,
TopologyKey: "zone",
Selector: mustConvertLabelSelectorAsSelector(t, fooSelector),
MinDomains: 1,
NodeAffinityPolicy: v1.NodeInclusionPolicyHonor,
NodeTaintsPolicy: v1.NodeInclusionPolicyIgnore,
},
{
MaxSkew: 1,
TopologyKey: "node",
Selector: mustConvertLabelSelectorAsSelector(t, fooSelector),
MinDomains: 1,
NodeAffinityPolicy: v1.NodeInclusionPolicyHonor,
NodeTaintsPolicy: v1.NodeInclusionPolicyIgnore,
},
},
TpKeyToCriticalPaths: map[string]*criticalPaths{
"zone": {{"zone1", 3}, {"zone2", 4}},
"node": {{"node-x", 0}, {"node-b", 1}},
},
for pair, num := range s.TpPairToMatchNum {
s.TpKeyToCriticalPaths[pair.key].update(pair.value, num)
}
TpPairToMatchNum: map[topologyPair]int{
{key: "zone", value: "zone1"}: 3,
{key: "zone", value: "zone2"}: 4,
{key: "node", value: "node-a"}: 2,
{key: "node", value: "node-b"}: 1,
{key: "node", value: "node-x"}: 0,
{key: "node", value: "node-y"}: 4,
},
},
},
update
update 函式實際上時用于計算 criticalPaths 中的第一位始終保持為是一個最小Pod匹配值
func (p *criticalPaths) update(tpVal string, num int) {
// first verify if `tpVal` exists or not
i := -1
if tpVal == p[0].TopologyValue {
i = 0
} else if tpVal == p[1].TopologyValue {
i = 1
}
if i >= 0 {
// `tpVal` 表示已經存在
p[i].MatchNum = num
if p[0].MatchNum > p[1].MatchNum {
// swap paths[0] and paths[1]
p[0], p[1] = p[1], p[0]
}
} else {
// `tpVal` 表示不存在,如一個新初始化的值
// num對應子域分布的pod
// 說明第一個元素不是最小的,則作為交換
if num < p[0].MatchNum {
// update paths[1] with paths[0]
p[1] = p[0]
// update paths[0]
p[0].TopologyValue, p[0].MatchNum = tpVal, num
} else if num < p[1].MatchNum {
// 如果小于 paths[1],則更新它,永遠保證元素0是最小,1是次小的
p[1].TopologyValue, p[1].MatchNum = tpVal, num
}
}
}
綜合來講 Prefilter 主要做的作業是,回圈所有的節點,先根據 NodeAffinity 或者 NodeSelector 進行過濾,然后根據約束中定義的 topologyKeys (拓撲劃分的依據) 來選擇節點,
接下來會計算出每個拓撲域下的拓撲對(可以理解為子域)匹配的 Pod 數量,存入 TpPairToMatchNum 中,最后就是要把所有約束中匹配的 Pod 數量最小(第二小)匹配出來的路徑(代碼是這么定義的,理解上可以看作是分布圖)放入 TpKeyToCriticalPaths 中保存起來,整個 preFilterState 保存下來傳遞到后續的 filter 插件中使用,
Filter
在 preFilter 中 最后的計算結果會保存在 CycleState 中
cycleState.Write(preFilterStateKey, s)
Filter 主要是從 PreFilter 處理的程序中拿到狀態 preFilterState,然后看下每個拓撲約束中的 MaxSkew 是否合法,具體的計算公式為:\(matchNum + selfMatchNum - minMatchNum\)
matchNum:Prefilter 中計算出的對應的拓撲分布數量,可以在Prefilter中參考對應的內容if tpCount, ok := s.TpPairToMatchNum[pair]; ok {
selfMatchNum:匹配到label的數量,匹配到則是1,否則為0minMatchNum:獲的Prefilter中計算出來的最小匹配的值
func (pl *PodTopologySpread) Filter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
node := nodeInfo.Node()
if node == nil {
return framework.AsStatus(fmt.Errorf("node not found"))
}
// 拿到 prefilter處理的s,即preFilterState
s, err := getPreFilterState(cycleState)
if err != nil {
return framework.AsStatus(err)
}
// 一個 空型別的 preFilterState是合法的,這種情況下將容忍每一個被調度的 Pod
if len(s.Constraints) == 0 {
return nil
}
podLabelSet := labels.Set(pod.Labels) // 設定標簽
for _, c := range s.Constraints { // 因為拓撲約束允許多個所以
tpKey := c.TopologyKey
tpVal, ok := node.Labels[c.TopologyKey]
if !ok {
klog.V(5).InfoS("Node doesn't have required label", "node", klog.KObj(node), "label", tpKey)
return framework.NewStatus(framework.UnschedulableAndUnresolvable, ErrReasonNodeLabelNotMatch)
}
// 判斷標準
// 現有的匹配數量 + 子匹配(1|0) - 全域minimum <= maxSkew
minMatchNum, err := s.minMatchNum(tpKey, c.MinDomains, pl.enableMinDomainsInPodTopologySpread)
if err != nil {
klog.ErrorS(err, "Internal error occurred while retrieving value precalculated in PreFilter", "topologyKey", tpKey, "paths", s.TpKeyToCriticalPaths)
continue
}
selfMatchNum := 0
if c.Selector.Matches(podLabelSet) {
selfMatchNum = 1
}
pair := topologyPair{key: tpKey, value: tpVal}
matchNum := 0
if tpCount, ok := s.TpPairToMatchNum[pair]; ok {
matchNum = tpCount
}
skew := matchNum + selfMatchNum - minMatchNum
if skew > int(c.MaxSkew) {
klog.V(5).InfoS("Node failed spreadConstraint: matchNum + selfMatchNum - minMatchNum > maxSkew", "node", klog.KObj(node), "topologyKey", tpKey, "matchNum", matchNum, "selfMatchNum", selfMatchNum, "minMatchNum", minMatchNum, "maxSkew", c.MaxSkew)
return framework.NewStatus(framework.Unschedulable, ErrReasonConstraintsNotMatch)
}
}
return nil
}
minMatchNum
// minMatchNum用于計算 傾斜的全域最小值,同時考慮 MinDomains,
func (s *preFilterState) minMatchNum(tpKey string, minDomains int32, enableMinDomainsInPodTopologySpread bool) (int, error) {
paths, ok := s.TpKeyToCriticalPaths[tpKey]
if !ok {
return 0, fmt.Errorf("failed to retrieve path by topology key")
}
// 通常來說最小值是第一個
minMatchNum := paths[0].MatchNum
if !enableMinDomainsInPodTopologySpread { // 就是plugin的配置的 enableMinDomainsInPodTopologySpread
return minMatchNum, nil
}
domainsNum, ok := s.TpKeyToDomainsNum[tpKey]
if !ok {
return 0, fmt.Errorf("failed to retrieve the number of domains by topology key")
}
if domainsNum < int(minDomains) {
// 當有匹配拓撲鍵的符合條件的域的數量小于 配置的"minDomains"(每個約束條件的這個配置) 時,
//它將全域“minimum” 設定為0,
// 因為minimum默認就為1,如果他小于1,就讓他為0
minMatchNum = 0
}
return minMatchNum, nil
}
PreScore
與 Filter 類似, PreScore 也是類似 PreFilter 的構成, initPreScoreState 來完成過濾,
有了 PreFilter 基礎后,對于 Score 來說大同小異
func (pl *PodTopologySpread) PreScore(
ctx context.Context,
cycleState *framework.CycleState,
pod *v1.Pod,
filteredNodes []*v1.Node,
) *framework.Status {
allNodes, err := pl.sharedLister.NodeInfos().List()
if err != nil {
return framework.AsStatus(fmt.Errorf("getting all nodes: %w", err))
}
if len(filteredNodes) == 0 || len(allNodes) == 0 {
// No nodes to score.
return nil
}
state := &preScoreState{
IgnoredNodes: sets.NewString(),
TopologyPairToPodCounts: make(map[topologyPair]*int64),
}
// Only require that nodes have all the topology labels if using
// non-system-default spreading rules. This allows nodes that don't have a
// zone label to still have hostname spreading.
// 如果使用非系統默認分布規則,則僅要求節點具有所有拓撲標簽,
// 這將允許沒有zone標簽的節點仍然具有hostname分布,
requireAllTopologies := len(pod.Spec.TopologySpreadConstraints) > 0 || !pl.systemDefaulted
err = pl.initPreScoreState(state, pod, filteredNodes, requireAllTopologies)
if err != nil {
return framework.AsStatus(fmt.Errorf("calculating preScoreState: %w", err))
}
// return if incoming pod doesn't have soft topology spread Constraints.
if len(state.Constraints) == 0 {
cycleState.Write(preScoreStateKey, state)
return nil
}
// Ignore parsing errors for backwards compatibility.
requiredNodeAffinity := nodeaffinity.GetRequiredNodeAffinity(pod)
processAllNode := func(i int) {
nodeInfo := allNodes[i]
node := nodeInfo.Node()
if node == nil {
return
}
if !pl.enableNodeInclusionPolicyInPodTopologySpread {
// `node` should satisfy incoming pod's NodeSelector/NodeAffinity
if match, _ := requiredNodeAffinity.Match(node); !match {
return
}
}
// All topologyKeys need to be present in `node`
if requireAllTopologies && !nodeLabelsMatchSpreadConstraints(node.Labels, state.Constraints) {
return
}
for _, c := range state.Constraints {
if pl.enableNodeInclusionPolicyInPodTopologySpread &&
!c.matchNodeInclusionPolicies(pod, node, requiredNodeAffinity) {
continue
}
pair := topologyPair{key: c.TopologyKey, value: node.Labels[c.TopologyKey]}
// If current topology pair is not associated with any candidate node,
// continue to avoid unnecessary calculation.
// Per-node counts are also skipped, as they are done during Score.
tpCount := state.TopologyPairToPodCounts[pair]
if tpCount == nil {
continue
}
count := countPodsMatchSelector(nodeInfo.Pods, c.Selector, pod.Namespace)
atomic.AddInt64(tpCount, int64(count))
}
}
pl.parallelizer.Until(ctx, len(allNodes), processAllNode)
// 保存狀態給后面sorce呼叫
cycleState.Write(preScoreStateKey, state)
return nil
}
與Filter中Update使用的函式一樣,這里也會到這一步,這里會構建出TopologySpreadConstraints,因為約束是不確定的
func filterTopologySpreadConstraints(constraints []v1.TopologySpreadConstraint, action v1.UnsatisfiableConstraintAction, enableMinDomainsInPodTopologySpread, enableNodeInclusionPolicyInPodTopologySpread bool) ([]topologySpreadConstraint, error) {
var result []topologySpreadConstraint
for _, c := range constraints {
if c.WhenUnsatisfiable == action { // 始終調度時
selector, err := metav1.LabelSelectorAsSelector(c.LabelSelector)
if err != nil {
return nil, err
}
tsc := topologySpreadConstraint{
MaxSkew: c.MaxSkew,
TopologyKey: c.TopologyKey,
Selector: selector,
MinDomains: 1, // If MinDomains is nil, we treat MinDomains as 1.
NodeAffinityPolicy: v1.NodeInclusionPolicyHonor, // If NodeAffinityPolicy is nil, we treat NodeAffinityPolicy as "Honor".
NodeTaintsPolicy: v1.NodeInclusionPolicyIgnore, // If NodeTaintsPolicy is nil, we treat NodeTaintsPolicy as "Ignore".
}
if enableMinDomainsInPodTopologySpread && c.MinDomains != nil {
tsc.MinDomains = *c.MinDomains
}
if enableNodeInclusionPolicyInPodTopologySpread {
if c.NodeAffinityPolicy != nil {
tsc.NodeAffinityPolicy = *c.NodeAffinityPolicy
}
if c.NodeTaintsPolicy != nil {
tsc.NodeTaintsPolicy = *c.NodeTaintsPolicy
}
}
result = append(result, tsc)
}
}
return result, nil
}
Score
// 在分數擴展點呼叫分數,該函式回傳的“score”是 `nodeName` 上匹配的 pod 數量,稍后會進行歸一化,
func (pl *PodTopologySpread) Score(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, nodeName string) (int64, *framework.Status) {
nodeInfo, err := pl.sharedLister.NodeInfos().Get(nodeName)
if err != nil {
return 0, framework.AsStatus(fmt.Errorf("getting node %q from Snapshot: %w", nodeName, err))
}
node := nodeInfo.Node()
s, err := getPreScoreState(cycleState)
if err != nil {
return 0, framework.AsStatus(err)
}
// Return if the node is not qualified.
if s.IgnoredNodes.Has(node.Name) {
return 0, nil
}
// 對于每個當前的 <pair>,當前節點獲得 <matchSum> 的信用分,
// 計算 <matchSum>總和 并將其作為該節點的分數回傳,
var score float64
for i, c := range s.Constraints {
if tpVal, ok := node.Labels[c.TopologyKey]; ok {
var cnt int64
if c.TopologyKey == v1.LabelHostname {
cnt = int64(countPodsMatchSelector(nodeInfo.Pods, c.Selector, pod.Namespace))
} else {
pair := topologyPair{key: c.TopologyKey, value: tpVal}
cnt = *s.TopologyPairToPodCounts[pair]
}
score += scoreForCount(cnt, c.MaxSkew, s.TopologyNormalizingWeight[i])
}
}
return int64(math.Round(score)), nil
}
在 Framework 中會運行 ScoreExtension ,即 NormalizeScore
// Run NormalizeScore method for each ScorePlugin in parallel.
f.Parallelizer().Until(ctx, len(f.scorePlugins), func(index int) {
pl := f.scorePlugins[index]
nodeScoreList := pluginToNodeScores[pl.Name()]
if pl.ScoreExtensions() == nil {
return
}
status := f.runScoreExtension(ctx, pl, state, pod, nodeScoreList)
if !status.IsSuccess() {
err := fmt.Errorf("plugin %q failed with: %w", pl.Name(), status.AsError())
errCh.SendErrorWithCancel(err, cancel)
return
}
})
if err := errCh.ReceiveError(); err != nil {
return nil, framework.AsStatus(fmt.Errorf("running Normalize on Score plugins: %w", err))
}
NormalizeScore 會為所有的node根據之前計算出的權重進行打分
func (pl *PodTopologySpread) NormalizeScore(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, scores framework.NodeScoreList) *framework.Status {
s, err := getPreScoreState(cycleState)
if err != nil {
return framework.AsStatus(err)
}
if s == nil {
return nil
}
// 計算 <minScore> 和 <maxScore>
var minScore int64 = math.MaxInt64
var maxScore int64
for i, score := range scores {
// it's mandatory to check if <score.Name> is present in m.IgnoredNodes
if s.IgnoredNodes.Has(score.Name) {
scores[i].Score = invalidScore
continue
}
if score.Score < minScore {
minScore = score.Score
}
if score.Score > maxScore {
maxScore = score.Score
}
}
for i := range scores {
if scores[i].Score == invalidScore {
scores[i].Score = 0
continue
}
if maxScore == 0 {
scores[i].Score = framework.MaxNodeScore
continue
}
s := scores[i].Score
scores[i].Score = framework.MaxNodeScore * (maxScore + minScore - s) / maxScore
}
return nil
}
到此,對于pod拓撲插件功能大概可以明了了,
- Filter 部分(
PreFilter,Filter)完成拓撲對(Topology Pair)劃分 - Score部分(
PreScore,Score,NormalizeScore)主要是對拓撲對(可以理解為拓撲結構劃分)來選擇一個最適合的pod的節點(即分數最優的節點)
而在 scoring_test.go 給了很多用例,可以更深入的了解這部分演算法
作者:鋼閘門Reference
[1] scheduling code hierarchy
[2] scheduler algorithm
[3] in tree VS out of tree volume plugins
[4] scheduler_framework_plugins
[5] scheduling config
[6] topology spread constraints
出處:http://lc161616.cnblogs.com/ 本文著作權歸作者和博客園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連接,否則保留追究法律責任的權利, 阿里云優惠:點擊力享低價 墨墨學英語:幫忙點一下
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/500435.html
標籤:其他
下一篇:On Java 8讀書筆記