一章我們來聊聊在中文領域都有哪些預訓練模型的改良方案,Bert-WWM,MacBert,ChineseBert主要從3個方向在預訓練中補充中文文本的資訊:詞粒度資訊,中文筆畫資訊,拼音資訊,與其說是推薦帖,可能更多需要客觀看待以下'中文'改良的在實際應用中的效果~
Bert-WWM
- Take Away: Whole Word Masking全詞掩碼
- Paper:Bert-WWM,Pre-Training with Whole Word Masking for Chinese BERT
- Github:https://github.com/ymcui/Chinese-BERT-wwm
全詞掩碼并不是中文的專屬,而是google最早在英文預訓練任務中提出的,在英文中的使用方式是當word piece tokenizer把一個單詞分割成幾個部分時,在MASK階段只要一個部分被掩碼,一個單詞的其他部分也會被MASK,google提供的英文全詞掩碼的處理方式如下,很直觀就是把所有'##'的部分都補充進掩碼
def create_masked_lm_predictions(tokens, masked_lm_prob,
max_predictions_per_seq, vocab_words, rng):
"""Creates the predictions for the masked LM objective."""
cand_indexes = []
for (i, token) in enumerate(tokens):
if token == "[CLS]" or token == "[SEP]":
continue
if (FLAGS.do_whole_word_mask and len(cand_indexes) >= 1 and
token.startswith("##")):
cand_indexes[-1].append(i)
else:
cand_indexes.append([i])
...
而在中文使用中,并不存在字被拆分的情況,因此中文全詞是指對詞粒度進行掩碼,在哈工大開源的Bert/Roberta-WWM系列中,以LTP分詞結果作為掩碼的最小粒度如下

實作方案其實可以借鑒上面的英文代碼,只需要根據分詞結果對字符加上'##'前綴,例如'語言模型',正常tokenize會得到['語','言','模','型'], 基于LTP的分詞結果['語言','模型'], 只需要把tokenizer調整為['語','##言','模,'##型'],就可以和英文用相同的處理方式了~
這里的全詞掩碼只影響MLM預訓練任務,和下游微調以及模型自身結構無關,因此可以遷移到任意的預訓練模型框架和下游任務中,全詞掩碼有兩個優點
- 部分解決了MLM獨立性假設,使得預測token之間擁有了一定的關聯性
- 提高了MLM任務難度,使得模型需要更多依賴遠距離的背景關系來判斷掩碼部分的內容
但是WWM是否在所有中文任務中都比字符粒度的模型更好呢?在使用程序中感覺也不盡然,例如在做一些資訊抽取任務時會發現當抽取資訊的粒度和詞粒度存在一定不一致時,字符BERT的效果是要顯著由于WWM的,猜測是WWM引入了部分詞邊界資訊,和下游任務抽取的邊界存在一定沖突,
簡單說就是中文詞本身的粒度在不同背景關系語境中是存在差異的,這是和英文單詞最大的差異,而這個差異并不能通過LTP單一的分詞器來引入,Ref3的論文也指出在中文字符糾錯任務中對WWM的效果并沒有BERT好,不過論文只給出了字符+WWM的混合掩碼方案,感覺,,,如果預訓練模型都需要因地制宜的話,那只能說我們還沒找到合適的預訓練方案,,,
MacBert
- Take Away: MLM->糾錯任務,解決MASK在預訓練和微調的不一致性
- Paper:MacBert, Pre-Training with Whole Word Masking for Chinese BERT
- Github:https://github.com/ymcui/MacBERT
MacBert可能放在中文這里并不太十分合適,其實是針對MASK在預訓練和微調中的不一致問題進行的改良,在Bert不完全手冊4. 繞開BERT的MASK策略?XLNET & ELECTRA中聊到Electra和XLNET也分別通過生成-判別器,以及亂序語言模型的方案繞開MASK學習雙向背景關系資訊,MacBert給出了另一種方案,
MacBert對原始的MLM任務做了如下調整
- 用相似詞替代[MASK]進行掩碼,這里的相似詞是基于word2vec similarity來召回候選,如果沒有召回就降級為隨機掩碼,于是完形填空任務其實變成了糾錯任務(這里應該也要限制召回的詞和原詞長度相同)
- WWM + N-gram掩碼,10%的4gram,20%3gram,30%2gram,40%1gram,個人理解這里的gram不是字符粒度而是詞粒度,否則會有大量的ngram不再以上word2vec的詞表內無法召回,不過MacBert并沒有開源訓練代碼所以無從考證

在抽取式閱讀理解上,MacBert略有提升,其他任務感覺提升不太明顯,整體改良非常簡單易懂,但是邏輯上其實有一點存疑,就是基于word2vec的相似詞替換作為掩碼,真的不會導致模型在訓練程序中出現資訊泄露的問題么?因為部分相似詞替換例如高興->快樂, 下雨->降雨,其實是提供了近乎一樣的文本資訊的,這種情況下模型其實不需要依賴背景關系,直接通過替換后的文本也能進行預測,這里其實和Electra的生成器部分不能太強是有些相似的問題,N-gram的掩碼可能一定程度上緩解了這個資訊泄露的問題,但感覺這個問題還是存在的~
ChineseBert
- Take Away: 引入拼音和筆畫資訊
- paper: ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information
- Github: https://github.com/ShannonAI/ChineseBert
最后這個模型是有一些起名nb癥在的,雖然整體效果提升只能說比隨機波動要更顯著一些,不過改良的方向,包括拼音和筆畫資訊的引入比較有意思,相似的方案在一些文本糾錯,風控文本變形之類的領域也看到過有類似的應用,所以還是來簡單聊聊
- 拼音資訊
相同漢字在不同的場景下會存在發音不同的情況,例如音樂和快樂中,yue發音對應的是樂曲,le對應的發音是喜悅,因此發音和漢字互動后也會提供一定的共享資訊,不過一字多音的情況相對少,所以感覺拼音層能提供的資訊比較有限,不過類似的方案之前有想在風控領域去做嘗試,因為風控中經常會出現同音字的變形,例如把佳琪改寫成嘉琪,加7等形式去繞過違禁詞封禁,如果使用這里已經與訓練好的拼音embedding去在下游進行遷移可能效果會有提升~
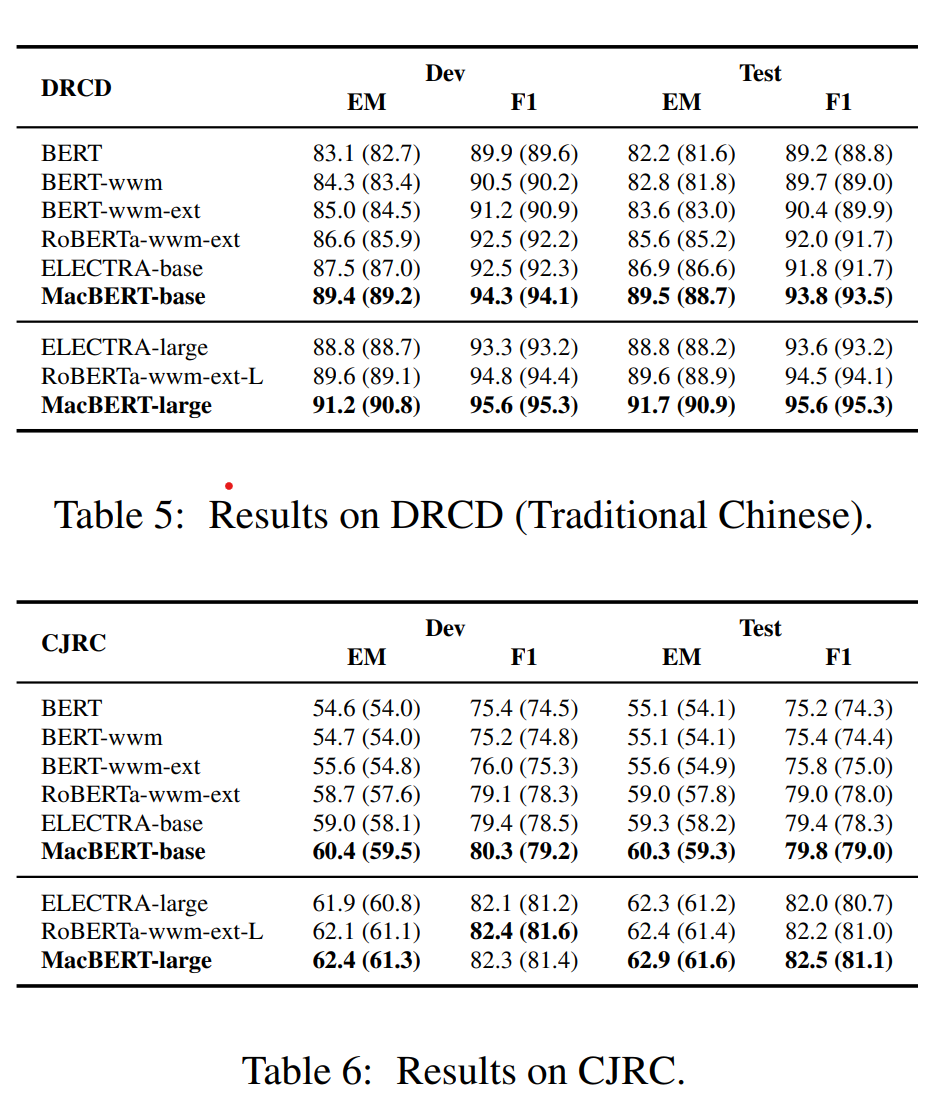
這里用了pypinyin來生成文字對應的拼音和聲調,例如貓->mao1,拼音復用原始的token,4個聲調額外用4個特殊token來表征,拼音部分用特殊字符'-'pad到等長,提取資訊這里用了width=2的CNN+max pooling來生成每個字符最終的拼音embedding
- 筆畫資訊
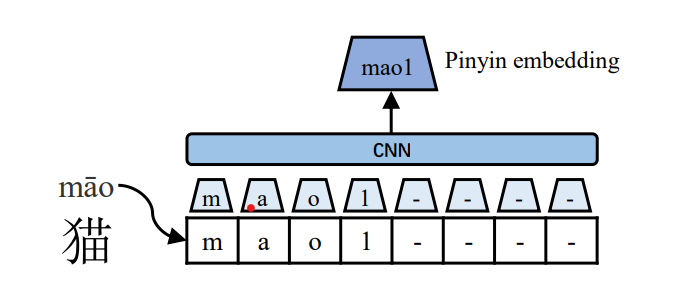
筆畫資訊一定程度給字之間增加了共享資訊,例如'江','河','湖','泊'都三點水的偏旁部首,他們存在的背景關系也會有一定相似性,因此可以有一部分資訊遷移,算是變相增加了背景關系資訊的豐富程度,不過ChineseBert使用的方式并沒有用五筆,而是用了影像資訊,使用了仿宋,隸書,行楷三種字體的圖片向量化(24243),對3種字體的圖片輸入進行拼接,然后過全連接層得到每個字符的筆畫embedding
- 資訊融合
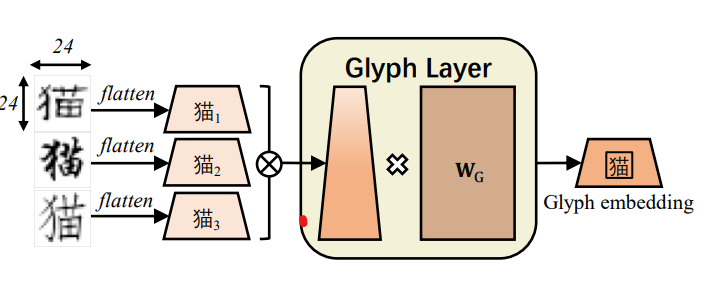
在原始Bert token embedding的基礎上,加入了拼音和筆畫embedding層,特征融合層,簡單使用了3個embedding拼接,過全連接層的方式得到融合后的輸入embedding,之后的模型結構就和BERT一致了,
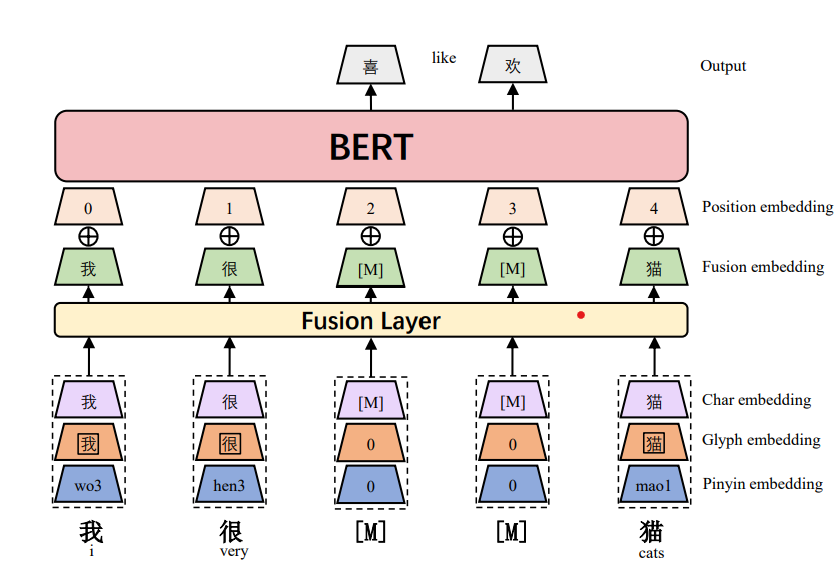
- MASK: 使用了字符+WWM的混合掩碼方式
Reference
- Spelling Error Correction with Soft-Masked BERT
- https://github.com/shibing624/pycorrector
- Is Whole Word Masking Always Better for Chinese BERT?": Probing on Chinese Grammatical Error Correction
- https://blog.csdn.net/Jiana_Feng/article/details/123539083
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/500440.html
標籤:其他