分布式id解決方案
一、從mysql本身出發
- 專門用一張表記錄最后一次的id
select last_insert_id()
- 每個mysql的庫中自增的值不一樣
A庫 從0開始每次增加2
B庫 從1開始每次增加2
- 同2相似
A庫 從1開始每次增加1
B庫 從100萬開始每次增加1
二、通過生成的UUID存值
String s = UUID.randomUUID().toString();
數字生成為32位,浪費資源;且生成的值沒有規律,不好儲存取值
三、使用redis
于redis生成全域id策略,因為Redis是單線的天生保證原子性,可以使用原子性操作INCR和INCRBY來實作,注意在Redis集群情況下,
同MySQL一樣需要設定不同的增長步長,同時key一定要設定有效期,可以使用Redis集群來獲取更高的吞吐量
因為redis天生就是單執行緒的,保證了事務的原子性
四、雪花演算法(推薦)

1位: 不用,二進制中最高位為1的都是負數,但是我們生成的id一般都使用整數,所以這個最高位固定是0
41位: 用來記錄時間戳(毫秒),
41位可以表示
2
41
?
1
2^{41}-1
241?1個數字,
如果只用來表示正整數(計算機中正數包含0),可以表示的數值范圍是:0 至
2
41
?
1
2^{41}-1
241?1,減1是因為可表示的數值范圍是從0開始算的,而不是1,
也就是說41位可以表示
2
41
?
1
2^{41}-1
241?1個毫秒的值,轉化成單位年則是
(
2
41
?
1
)
/
(
1000
?
60
?
60
?
24
?
365
)
=
69
(2^{41}-1) / (1000 * 60 * 60 * 24 * 365) = 69
(241?1)/(1000?60?60?24?365)=69年
10位: 用來記錄作業機器id,
可以部署在
2
10
=
1024
2^{10} = 1024
210=1024個節點,包括5位datacenterId和5位workerId
5位(bit)可以表示的最大正整數是
2
5
?
1
=
31
2^{5}-1 = 31
25?1=31,即可以用0、1、2、3、…31這32個數字,來表示不同的datecenterId或workerId
12位,序列號,用來記錄同毫秒內產生的不同id,
12位: (bit)可以表示的最大正整數是
2
12
?
1
=
4095
2^{12}-1 = 4095
212?1=4095,即可以用0、1、2、3、…4094這4095個數字,來表示同一機器同一時間截(毫秒)內產生的4095個ID序號
由于在Java中64bit的整數是long型別,所以在Java中SnowFlake演算法生成的id就是long來存盤的,
SnowFlake可以保證:
所有生成的id按時間趨勢遞增
整個分布式系統內不會產生重復id(因為有datacenterId和workerId來做區分)
·
·
·
代碼實作
演算法來自githup:https://github.com/souyunku/SnowFlake,僅作參考以輔助演算法理解
package snowFlake;
public class SnowFlake {
/**
* 起始的時間戳
*/
private final static long START_STMP = 1480166465631L;
/**
* 每一部分占用的位數
*/
private final static long SEQUENCE_BIT = 12; //序列號占用的位數
private final static long MACHINE_BIT = 5; //機器標識占用的位數
private final static long DATACENTER_BIT = 5;//資料中心占用的位數
/**
* 每一部分的最大值
*/
private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
private long datacenterId; //資料中心
private long machineId; //機器標識
private long sequence = 0L; //序列號
private long lastStmp = -1L;//上一次時間戳
public SnowFlake(long datacenterId, long machineId) {
if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.datacenterId = datacenterId;
this.machineId = machineId;
}
/**
* 產生下一個ID
*
* @return
*/
public synchronized long nextId() {
long currStmp = getNewstmp();
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStmp == lastStmp) {
//相同毫秒內,序列號自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列數已經達到最大
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
//不同毫秒內,序列號置為0
sequence = 0L;
}
lastStmp = currStmp;
return (currStmp - START_STMP) << TIMESTMP_LEFT //時間戳部分
| datacenterId << DATACENTER_LEFT //資料中心部分
| machineId << MACHINE_LEFT //機器標識部分
| sequence; //序列號部分
}
private long getNextMill() {
long mill = getNewstmp();
while (mill <= lastStmp) {
mill = getNewstmp();
}
return mill;
}
private long getNewstmp() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowFlake snowFlake = new SnowFlake(2, 3);
long start = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
System.out.println(snowFlake.nextId());
}
System.out.println(System.currentTimeMillis() - start);
}
}
驗證
package snowFlake;
public class SnowFlakeTest {
public static void main(String[] args) {
SnowFlake snowFlake=new SnowFlake(1,1);
long l0 = snowFlake.nextId();
long l1 = snowFlake.nextId();
long l2 = snowFlake.nextId();
System.out.println(l0);
System.out.println(l1);
System.out.println(l2);
}
}
實作結果
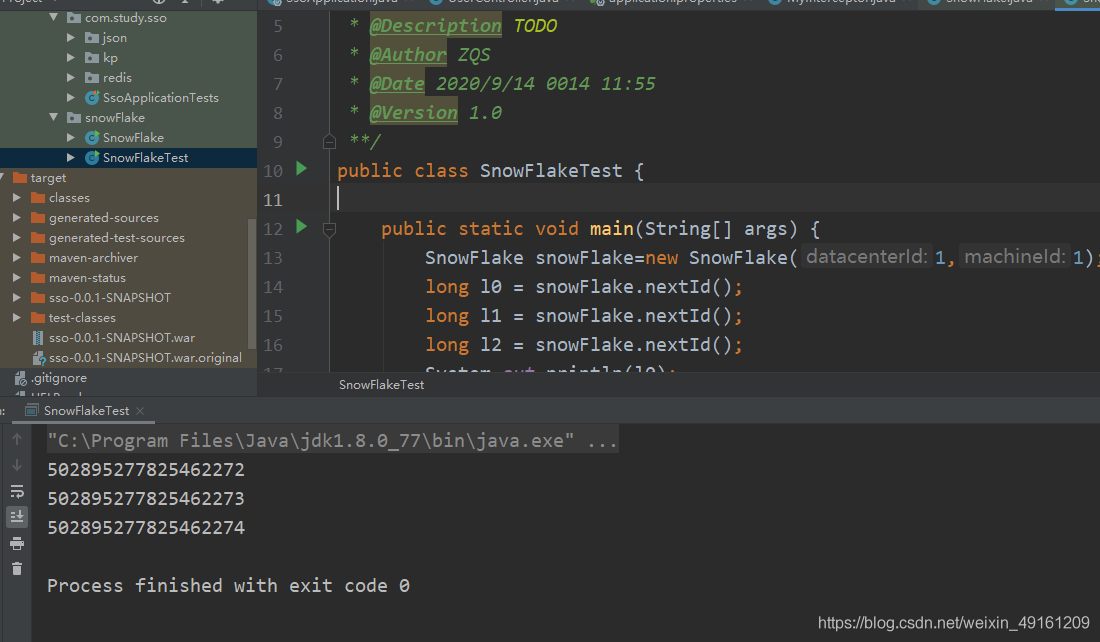
從上面可以看出生成的值是有序切不沖突
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/50071.html
標籤:AI
上一篇:Python自學感想