摘要:昇騰模型壓縮工具是一個針對昇騰芯片親和的深度學習模型壓縮工具包,提供量化、張量分解等多種模型壓縮特性,致力于幫助用戶高效實作模型的小型化,
本文分享自華為云社區《【CANN檔案速遞11期】帶您了解昇騰模型壓縮工具》,作者: 昇騰CANN ,
什么是AMCT,它能做什么?
昇騰模型壓縮工具(Ascend Model Compression Toolkit,簡稱AMCT)是一個針對昇騰芯片親和的深度學習模型壓縮工具包,提供量化、張量分解等多種模型壓縮特性,致力于幫助用戶高效實作模型的小型化,
它實作了神經網路模型中資料與權重8位元量化、張量分解、模型部署優化(主要為BN融合)的功能,該工具將量化和模型轉換分開,實作對模型中可量化算子的獨立量化,最終輸出量化后的模型,
其中,量化后的仿真模型可以在CPU或者GPU上運行,完成精度仿真;量化后的部署模型可以部署在昇騰AI處理器上運行,達到提升推理性能的目的,
AMCT功能介紹
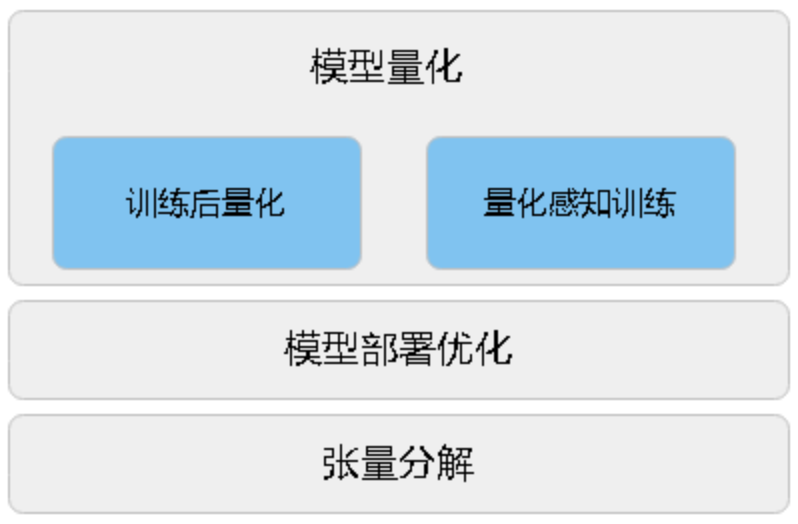
AMCT使用的模型壓縮方法有:量化、張量分解、模型部署優化(主要為BN融合),
量化:指對模型的權重(weight)和資料(activation)進行低位元處理,讓最終生成的網路模型更加輕量化,從而達到節省網路模型存盤空間、降低傳輸時延、提高計算效率,達到性能提升與優化的目標,其原理如下圖所示:
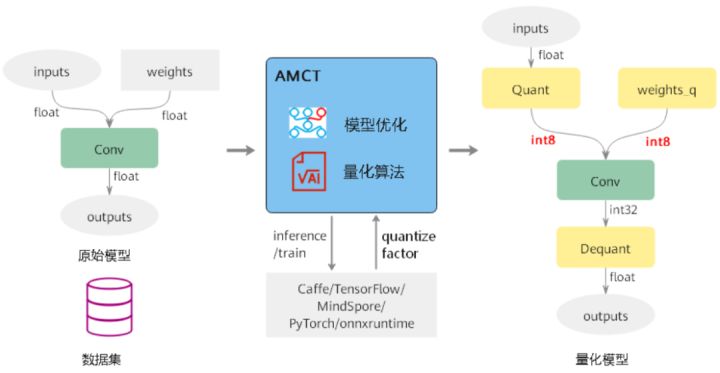
量化根據是否需要重訓練,分為訓練后量化和量化感知訓練,
訓練后量化(Post-Training Quantization,簡稱PTQ)
在模型訓練結束之后進行的量化,再對訓練好的模型進行權重和資料的量化,進而加速模型推理速度,
量化感知訓練(Quantization-Aware Training,簡稱QAT)
在量化程序中,對模型進行訓練的一種量化,QAT會在訓練程序中引入偽量化的操作(從浮點量化到定點,再還原到浮點的操作),用來模擬前向推理時量化帶來的誤差,并借助訓練讓模型權重能更好地適應這種量化的資訊損失,從而提升量化精度,
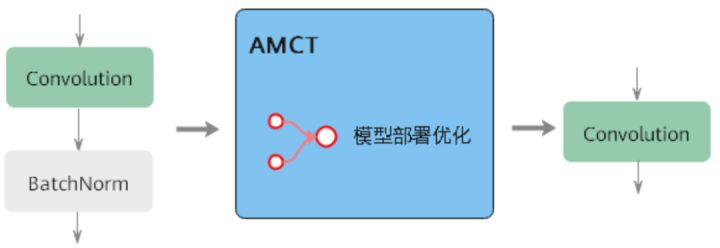
模型部署優化:主要為算子融合功能,指通過數學等價,將模型中的多個算子運算融合為單算子運算,以減少實際前向程序中的運算量,如將卷積層和BN層融合為一個卷積層,該功能在量化程序中實作,當前僅支持BN融合,其原理如下圖所示:
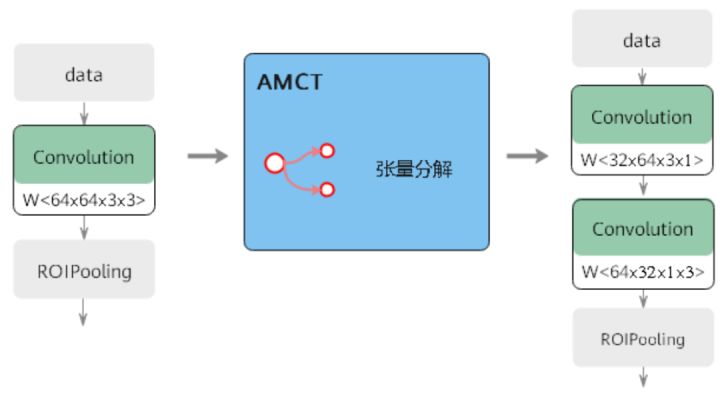
張量分解:通過分解卷積核的張量,可以將一個大卷積核分解為兩個小卷積核的連乘,即將卷積核分解為低秩的張量,從而降低存盤空間和計算量,降低推理開銷,其原理如下圖所示:
AMCT量化方式
AMCT支持兩種方式的量化:命令列方式和Python API介面方式,區別如下:
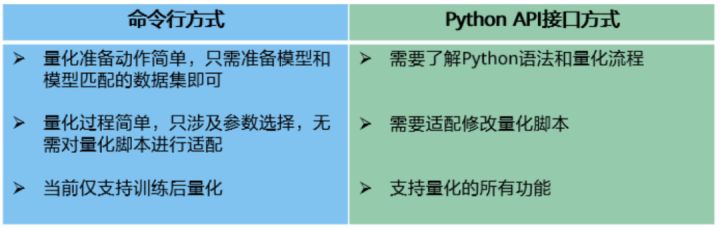
如果用戶想快速體驗AMCT,則可以使用命令列方式進行訓練后量化 ,如果想體驗更多功能,比如量化感知訓練,則必須使用Python API介面方式實作,
如何使用AMCT
下圖展示了使用AMCT進行量化的簡單流程,用于需要先在符合版本要求的Linux服務器部署AMCT,完成模型量化操作,輸出可部署的量化模型;然后借助ATC工具轉成適配昇騰AI處理器的.om離線模型;最后使用.om離線模型,在昇騰AI處理器完成推理業務,
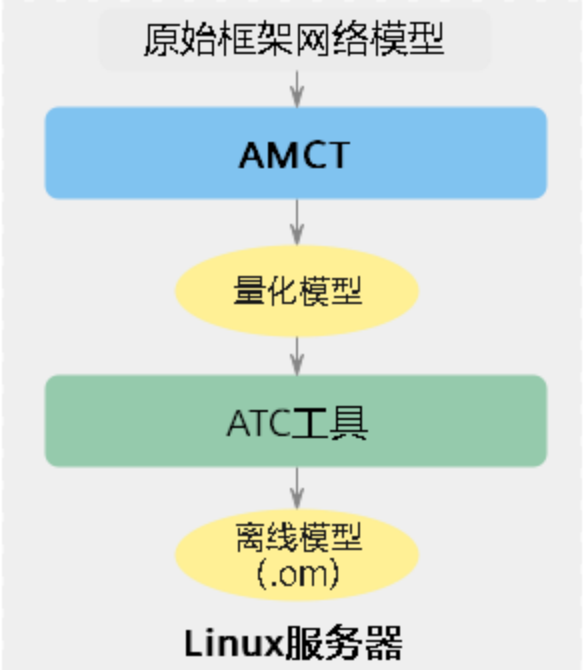
下面以Caffe框架ResNet-50網路模型為例,為您演示如何借助AMCT進行命令列方式的量化,
- 通過昇騰社區獲取AMCT軟體包,并完成安裝,
在任意路徑執行amct_caffe calibration --help命令,若回顯引數資訊,則說明AMCT能正常使用, - 準備要進行量化的模型檔案*.prototxt、權重檔案*.caffemodel、以及與模型匹配的二進制資料集上傳到AMCT所在Linux服務器,
- 執行如下命令進行訓練后量化,

引數解釋如下:
--model:原始網路模型檔案路徑與檔案名,
--weight:原始網路模型權重檔案路徑與檔案名,
--save_path:量化后模型的存放路徑,
--input_shape:指定模型輸入資料的shape,
--data_dir:二進制資料集路徑,
--data_types:輸入資料的型別,
- 量化完成后,在{save_path}引數指定路徑下可以查看量化后的模型,
- (后續處理)用戶使用上述量化后的模型,借助ATC工具轉成適配昇騰AI處理器的.om離線模型,然后在安裝昇騰AI處理器的服務器完成推理業務,
AMCT更多功能
下面介紹Caffe框架下通過Python API介面方式實作的各種功能,
訓練后量化
介面呼叫流程
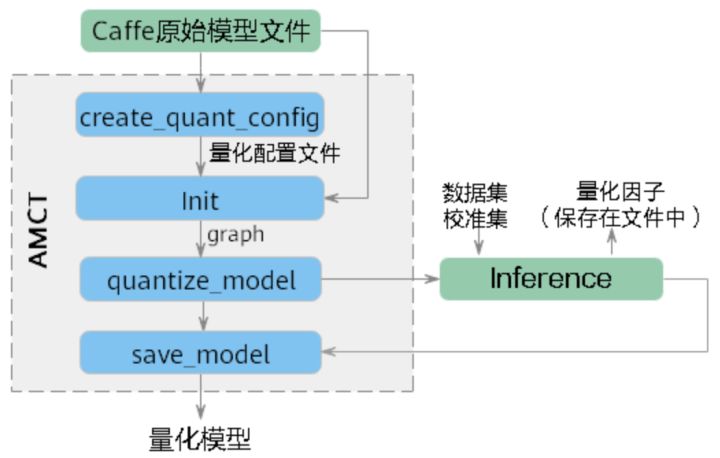
代碼示例
- 匯入AMCT包,

- 呼叫AMCT,量化模型,
- 決議用戶模型,生成量化組態檔,

- 初始化AMCT,讀取用戶量化組態檔、決議用戶模型檔案、生成用戶內部修改模型的Graph IR,

- 執行圖融合、執行權重離線量化以及插入資料量化層得到校準模型,從而在后續校準推理程序中執行資料量化動作,

- 執行校準模型推理,完成資料量化(借助用戶原始Caffe環境) ,

- 執行量化后圖優化動作,并保存得到最終的量化部署模型(deploy)和量化仿真模型(fake_quant),

量化感知訓練
介面呼叫流程
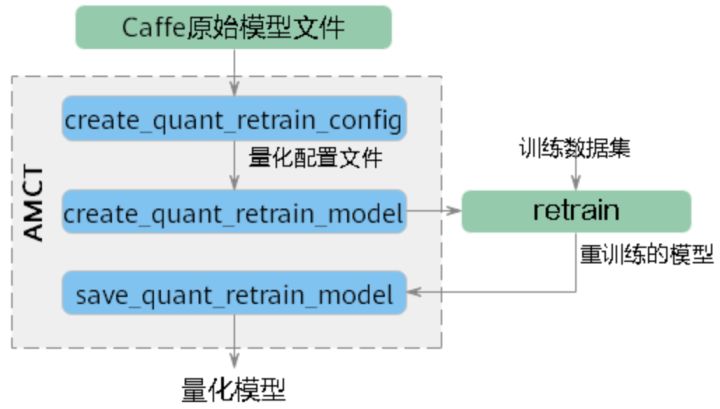
代碼示例
- 匯入AMCT包,

- 呼叫AMCT,量化模型,
- 決議用戶模型,生成量化組態檔,

- 修改模型,插入偽量化層并存為新的模型檔案,

- 使用修改后的模型,創建反向梯度,在訓練集上做訓練,訓練量化因子(借助用戶原始Caffe環境),

- 保存模型,

張量分解
介面呼叫流程
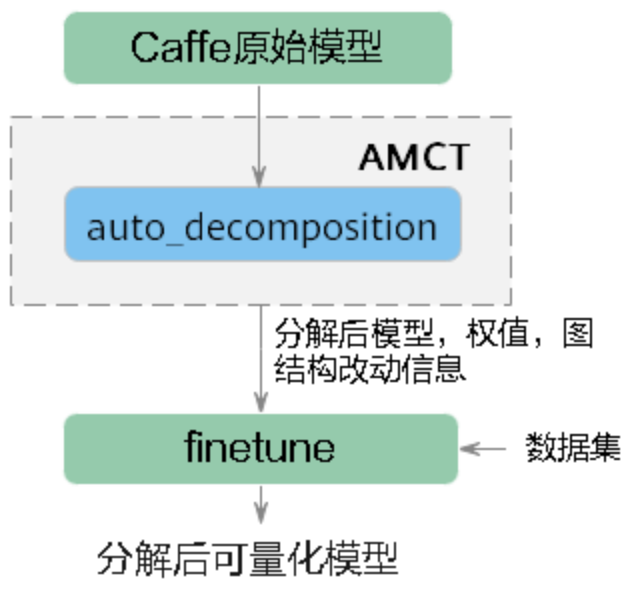
代碼示例
- 匯入AMCT相關模塊,

- 呼叫介面執行張量分解,

- 對分解后的模型進行finetune,輸出最終分解后的模型,
更多介紹
關于文中命令列方式更多引數、Python API方式介面介紹以及TensorFlow、ONNX、PyTorch、MindSpore等框架的AMCT用法介紹,請登錄昇騰社區,閱讀相關檔案:https://www.hiascend.com/document,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/508805.html
標籤:其他