不同的自然語言有不同的語法結構,因此需要對語言資料進行語法決議,才能讓機器更準確地學到相應的模式,兒語言不同于影像,資料標注作業需要有一定的語言學知識,因此資料的整理也相對更困難,下面以英語為例(別的咱也看不懂),對NLP研究中常見的基本語言學概念進行記錄,
詞性(Part Of Speech)
詞性(Part Of Speech, POS)通常在初中就學過:名詞、動詞、形容詞、副詞等,這里不再贅述,由于同一個詞有多種不同詞性的可能,因此資料標注時對陳述句中各個詞的詞性的標注就十分重要,從而消除詞性歧義,如:
There are many chairs in the room.
He chairs the weekly meeting.
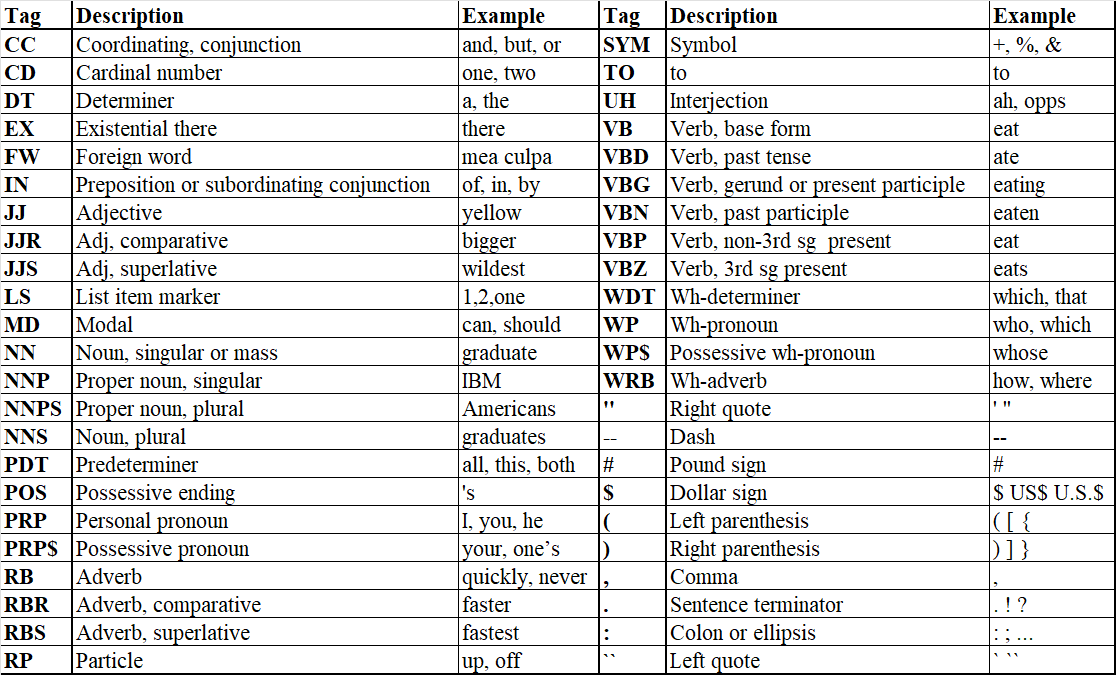
兩個chairs分別是名詞和動詞,以下是賓夕法尼亞大學定義的詞性標簽(Penn Treebank POS Tags),NLP資料集中常見,在此進行記錄以便查詢:
短語結構語法(Phrase Structure Grammar)
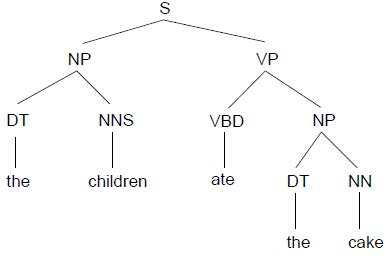
短語結構語法是一種重寫規則,用于描述給定語言的句法,從而消除語法歧義,這是一種基于成分的語法(constituency-based),每次分解對應的詞匯可以有多個(與下面的依賴語法不同),一般來說,每個句子(Sentence, S)都能被分為主語(名詞短語, Noun Phrase, NP)和謂語(動詞短語, Verb Phrase, VP),NP和VP則能被進一步分解更小的NP和VP,或最終分解為不可分解的某種性質的詞匯,例子如下:
The children ate the cake.
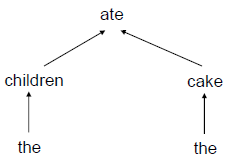
依存語法(Dependency Grammar)
依存語法將句子每個詞匯看做是互相依賴的關系,因此每次分解只對應一個詞匯,具體分解方式先占個坑,以后再記錄,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/509029.html
標籤:其他
下一篇:隱馬爾科夫模型的簡單實作