作者:喬雷,Vesoft.Inc 云原生技術專家
NebulaGraph 介紹
NebulaGraph 是由杭州悅數科技有限公司自主研發的一款開源分布式圖資料庫產品,擅長處理千億節點萬億條邊的超大資料集,同時保持毫秒級查詢延時,得益于其 shared-nothing 以及存盤與計算分離的架構設計,NebulaGraph 具備在線水平擴縮容能力;原生分布式架構,使用 Raft 協議保證資料一致性,確保集群高可用;同時兼容 openCypher,能夠無縫對接 Neo4j 用戶,降低學習及遷移成本,
NebulaGraph 經過幾年的發展,目前已經形成由云服務、可視化工具、圖計算、大資料生態支持、工程相關的 Chaos 以及性能壓測等產品構成的生態,接下來會圍繞云服務展開,分享落地程序中的實踐經驗,
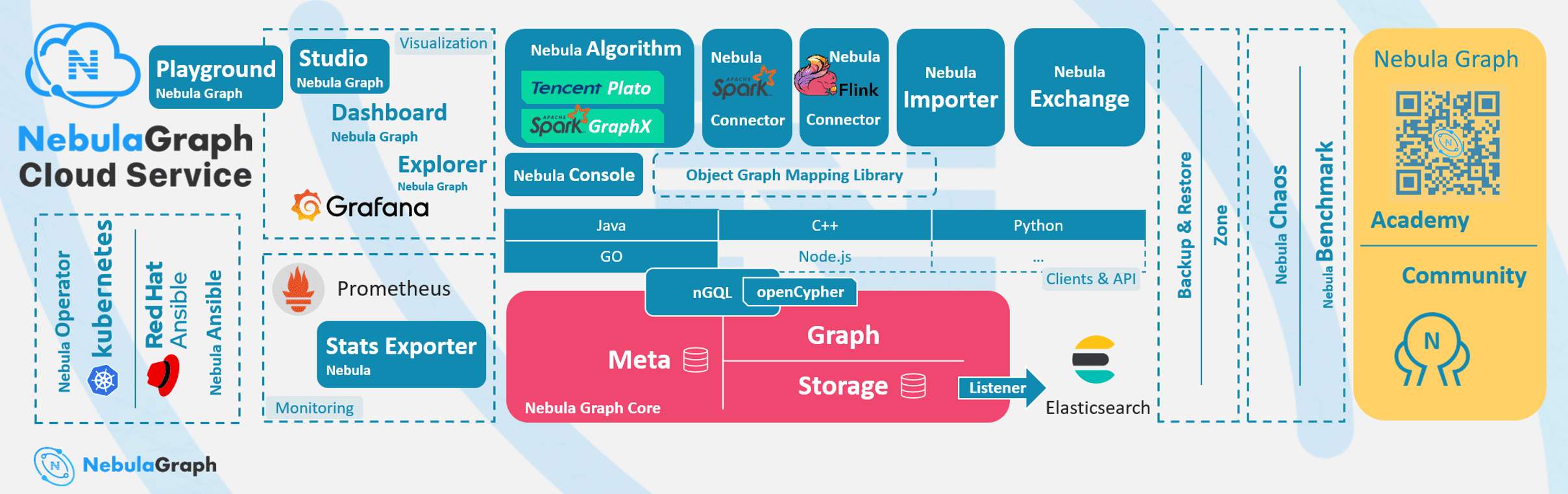
交付模式
NebulaGraph 在云上的交付模式分為自管模式、半托管模式與全托管模式三種,
自管模式
自管模式基于各家云廠商的的資源堆疊編排產品交付,例如 AWS Cloudformation、Azure ResourceManager、Aliyun Resource Orchestration Service、GCP DeploymentManager 等等,自管模式的特點是所有資源部署在客戶的租戶內,用戶自己運維管理,軟體服務商負責將產品上架到 Marketplace,按照最佳實踐給客戶提供服務配置組裝和一鍵部署的能力,相比于傳統模式下以天計的交付周期,現在幾分鐘內就可以在云上部署一個圖資料庫,
半托管模式
半托管模式是在自管模式的基礎上為客戶提供了代運維的能力,阿里云計算巢通過將應用發布為服務的方式,為服務商提供了一個智能簡捷的服務發布和管理平臺,覆寫了服務的整個生命周期,包括服務的交付、部署、運維等,當客戶的集群出現問題時,服務商運維人員的所有操作均被記錄,資源操作通過 ActionTrail 記錄日志,實體操作保留錄屏,還原運維程序,做到運維安全合規可追溯,避免服務糾紛,
NebulaGraph 采用存盤與計算分離的架構,存盤計算分離有諸多優勢,最直接的優勢就是,計算層和存盤層可以根據各自的情況彈性擴容、縮容,存盤計算分離還帶來了另一個優勢:使水平擴展成為可能,通過計算巢提供的彈性伸縮能力,保障自身擴縮容需要,
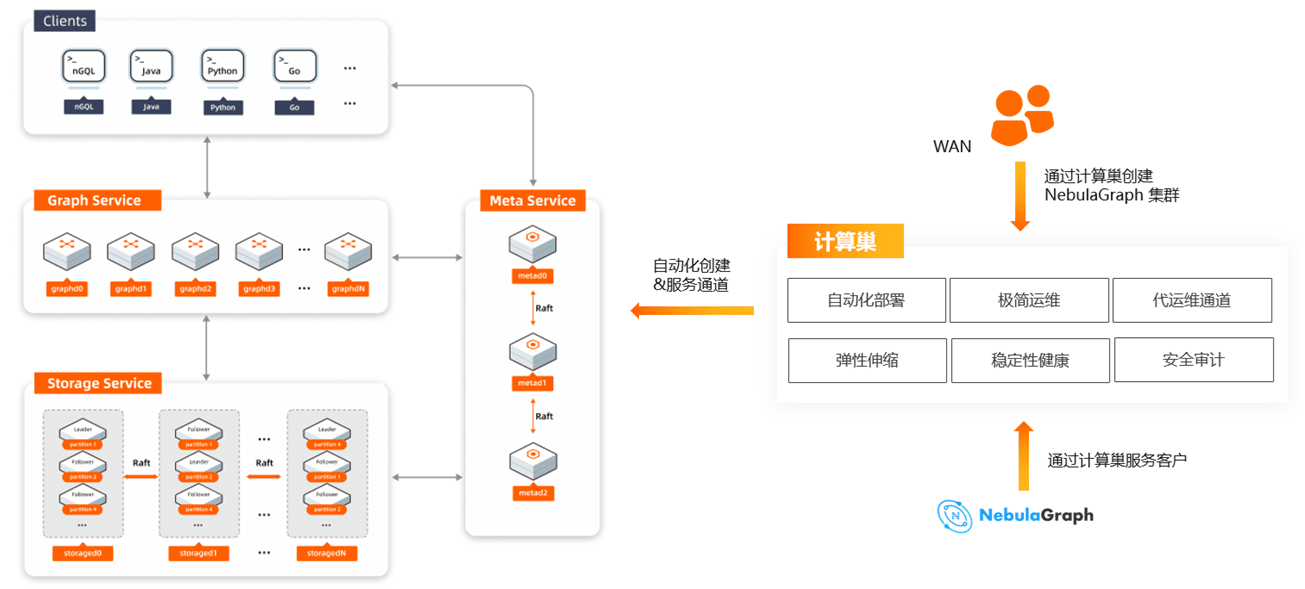
全托管模式
全托管模式交付由服務商托管的圖資料庫產品,客戶按需訂閱付費,只需選擇產品規格與節點,NebulaGraph 全堆疊產品便可在幾分鐘內交付,客戶無需關注底層資源的監控運維,資料庫集群的穩定性保障作業,這些都將由服務商解決,
NebulaGraph DBaaS 依托于 Kubernetes 構建,Kubernetes 的架構設計帶來以下優勢:通過宣告式 API 將整體運維復雜性下沉,交給 IaaS 層實作和持續優化;抽象出 Loadbalance Service、Ingress、NodePool、PVC 等物件,幫助應用層可以更好通過業務語意使用基礎設施,無需關注底層實作差異;通過 CRD(Custom Resource Definition)/ Operator 等方法提供領域相關的擴展實作,最大化 Kubernetes 的應用價值,
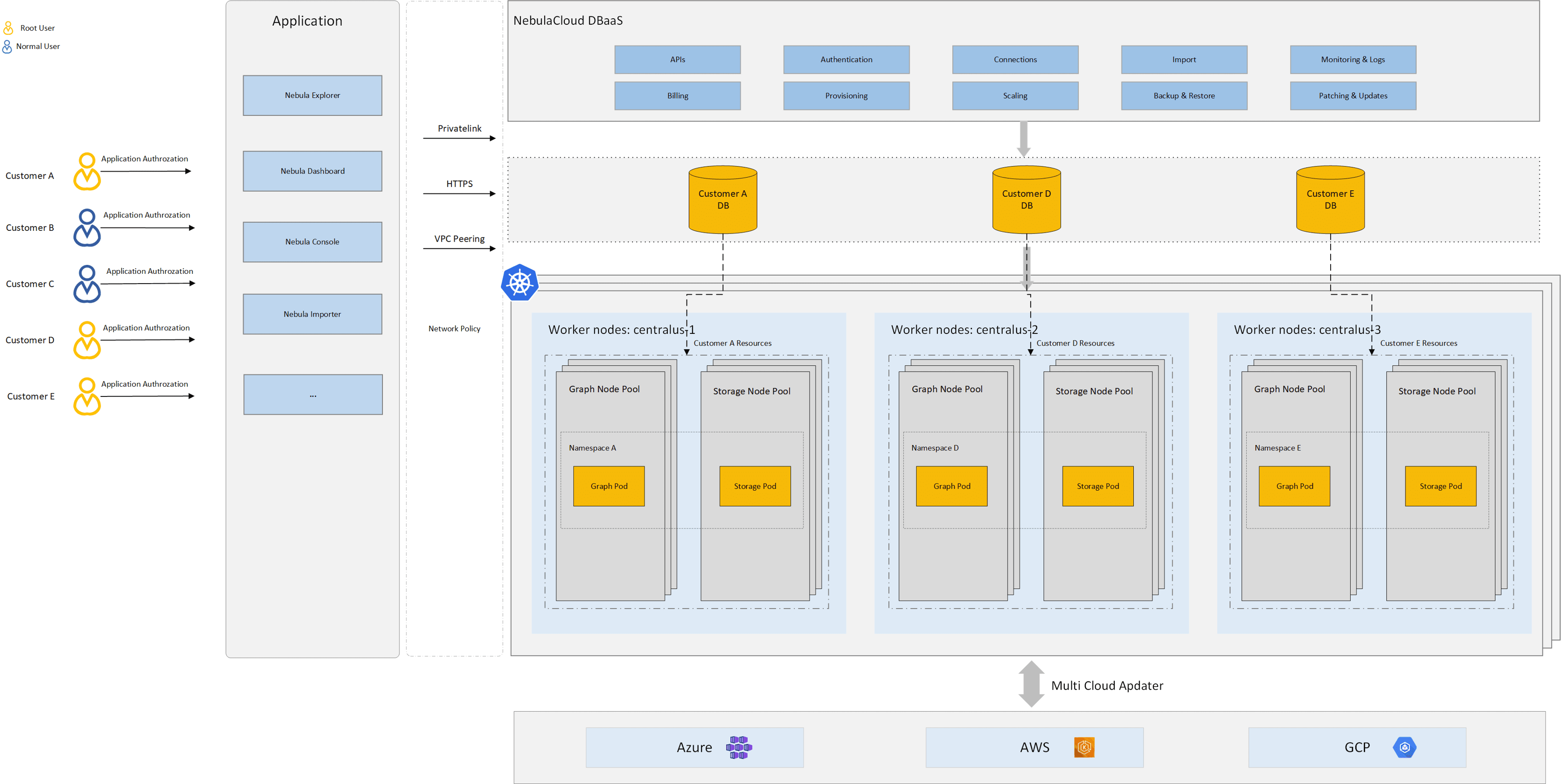
落地實踐
落地實踐主要講述全托管模式產品的架構演進,云原生技術與業務平臺的融合,
IaC
下圖是 Azure 業務側基礎設施的架構,初始配置時對接到管理平臺需要耗時幾個小時,這在有大量用戶申請訂閱實體的情況下是完全不能接受的,
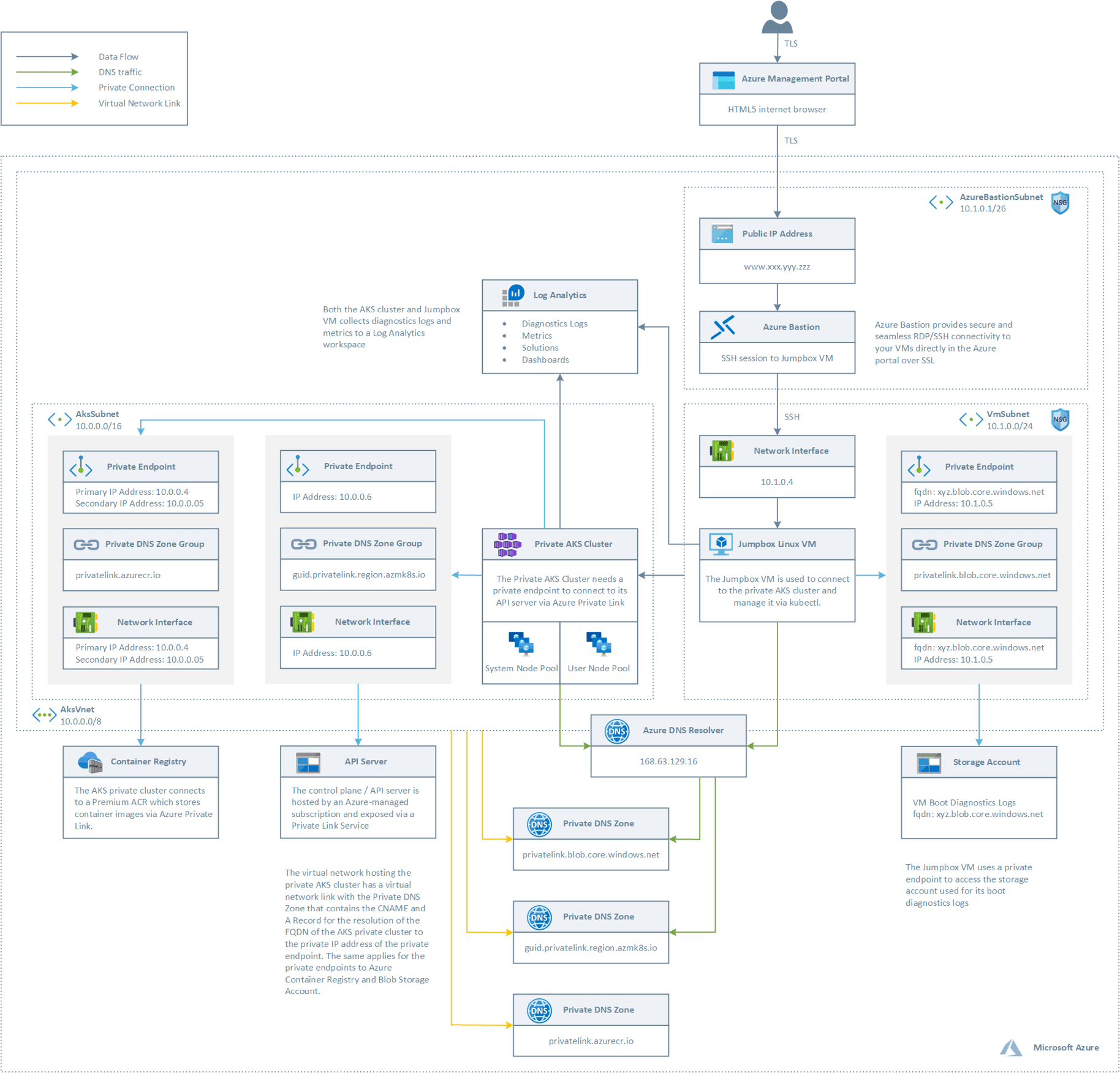
因此,我們想到了將基礎設施模板化,先定義出 dev、test、prod 三種運行環境,再將資源劃分為 VPC & Peering、Private DNS Zone、Kubernetes、Database、Container Registry、Bastion 等幾個類別,使用 terraform 完成自動化配置,但是,僅完成這一步是遠遠不夠的,為了滿足客戶側 Kubernetes 集群及時彈性要求,我們定義了 Cluster CRD,將 Cluster 的所有操作放入 Operator 里執行,terraform 的可執行檔案與模板代碼打包到容器鏡像后由 Job 驅動運行,Operator 向 Job 注入云廠商、地域、子網等環境變數,業務集群的狀態保存到 Cluster Status 里,到此,配置基礎設施實作了手動向自動化的演進,
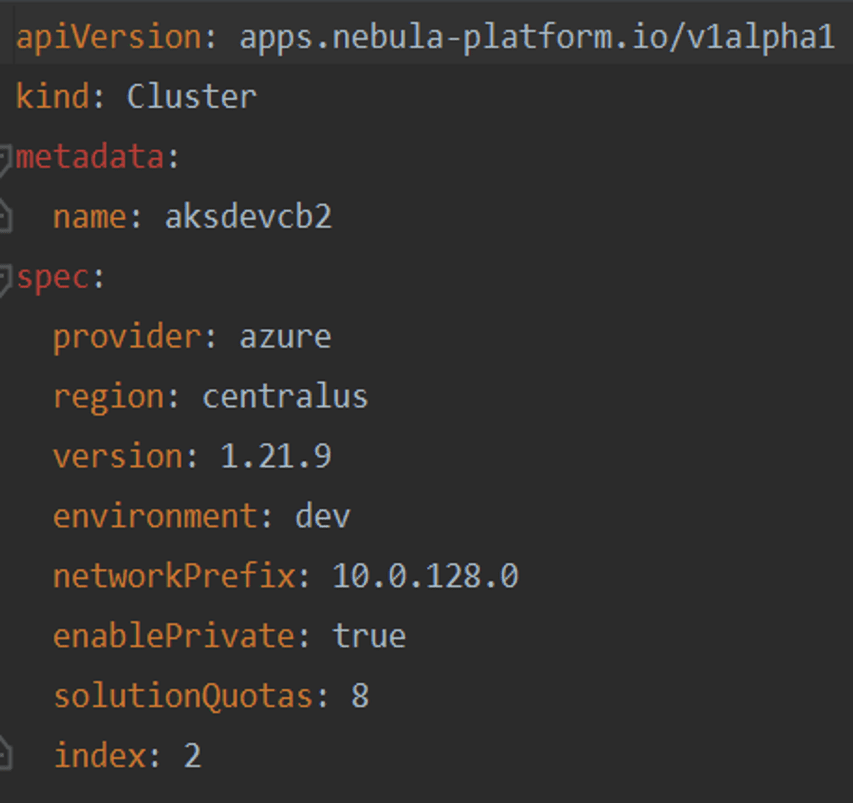
Operators
紅帽出品了一本關于 Kubernetes 設計模式的書籍 《 Kubernetes Patterns 》,關注這個領域的同學想必不會陌生,這本書的出現是針對目前云原生時代的設計模式,之前的設計模式更多的是對單個模塊或是簡單系統的,但是云原生時代的開發方式和理念與之前的主機開發模式還是存在很大差異的,

在 DBaaS 平臺上線初期,創建一個訂閱實體大致由以下流程構成:
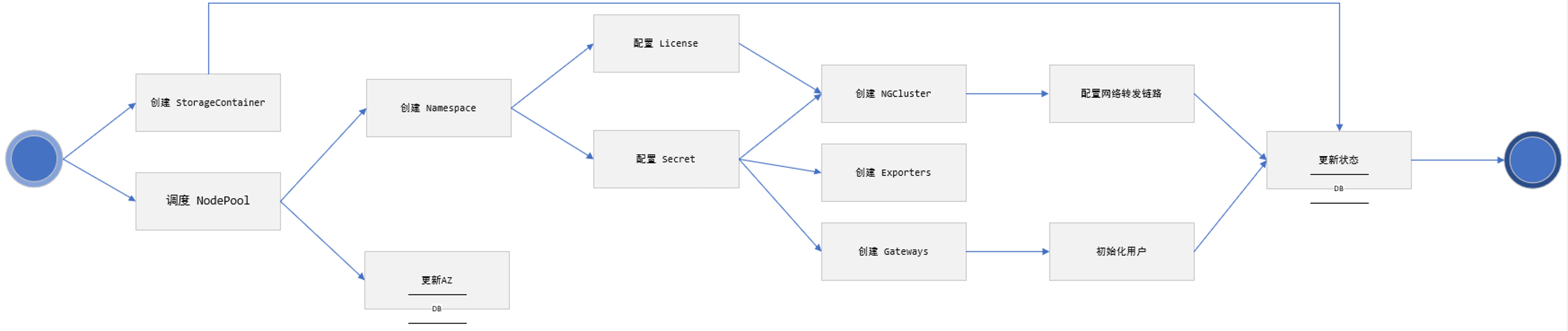
我們在資料庫里定義了 Task 表,包含 succeed、failed、running、pending 四種狀態,每個訂閱實體流程的任務節點狀態會存盤到 Task 表,服務啟動后會拉起一個監控執行緒,它主要負責定時檢查訂閱實體狀態,當訂閱實體狀態例外后會發送告警通知,然后根據預期的狀態執行恢復任務,訂閱實體的生命周期管理是一個長耗時的異步任務,這里涉及基礎設施資源管理,業務資料的更新等步驟,針對例外情況下不同流程的恢復處理導致業務邏輯復雜,后期再維護的成本逐漸增加,因此,我們對服務做了拆分重構,
我們先行調研了作業流編排系統,比如 Uber 的 Cadence,基礎設施編排領域的成熟案例有 Banzai Cloud,Hashicorp,但是也因引入三方系統帶來額外的運維成本,
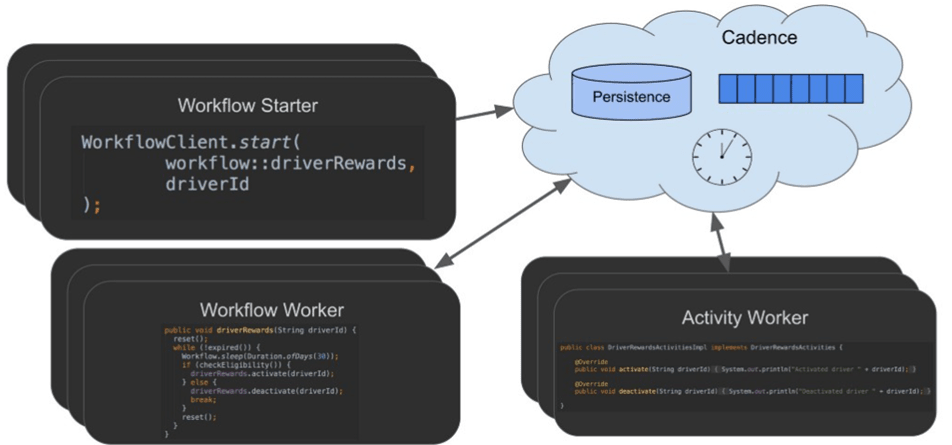
另一套方案基于 Operator 的設計模式實作,核心原理是回圈控制協調,直到運行成功,將每個訂閱實體的管理流程放入協調器里,實體狀態保存到到 Status ,平臺業務層模塊驅動 Operator 并同步各種 Event,最終我們選擇了基于 Operator 的實作方案,將各種長耗時的任務剝離出來抽象為 CRD,統一交由 workflow-operator 來管理,
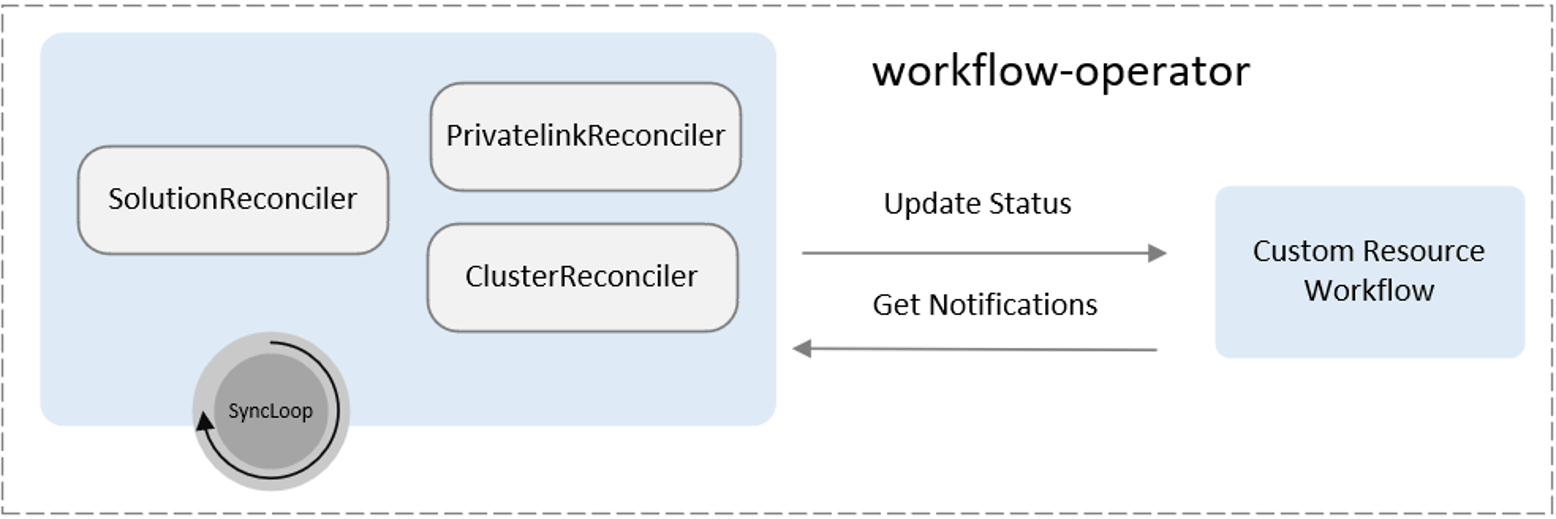
經過重構后,訂閱實體的生命周期管理非常簡潔,復雜度大幅降低,
成本控制
隨著企業將更多核心業務從資料中心遷移到云上,越來越多的企業迫切需要對云上環境進行預算制定、成本核算和成本優化,同樣地,客戶也對云上的費用支出例外敏感,
首先,我們在存盤層服務做了優化,通過 NVMe cache 降低存盤資費,NVMe 是專門為 NAND、閃存等非易失性存盤設計的,NVMe 協議建立在高速 PCIe 通道上,使用NVMe Cache,可以取得相比于同等大小的高性能磁盤不差的性能,而成本至少可以減少50%,

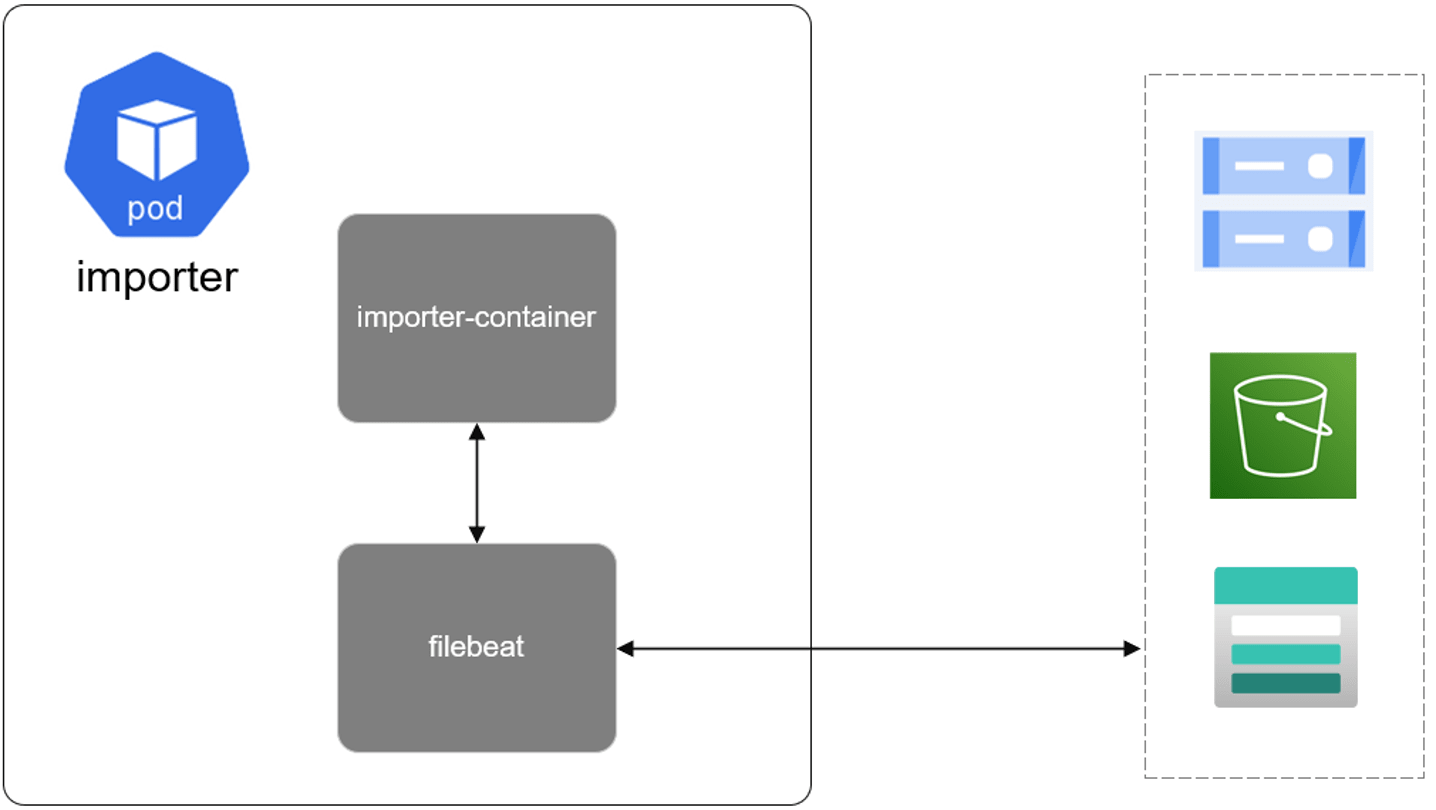
上次分享有介紹過我們的日志存盤基于 ES 系統,大家都知道,ES 系統存盤是非常耗費資源的,因此我們對業務平臺的應用日志存盤做了優化,主要是對 filebeat 做了定制開發,支持多家云廠商的物件存盤服務,改造 Rotater 支持檔案順序索引,可以按照行數切割檔案;基于 fsnotify 庫監聽檔案事件,將切割出來的小檔案上傳到物件存盤;當獲取日志時,可以根據 offset 計算出對應的日志檔案索引從而快速獲取日志,
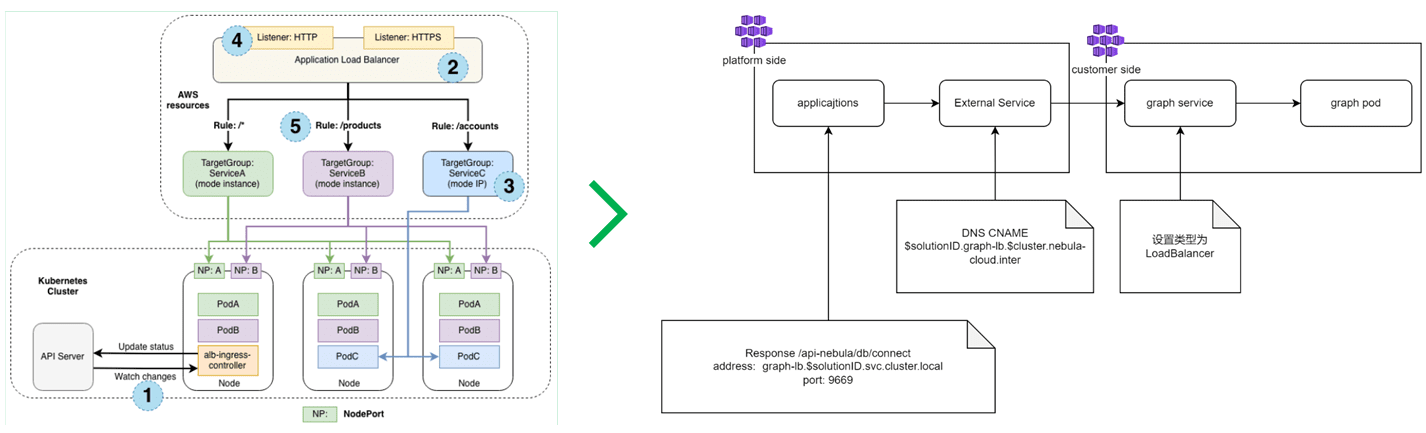
從用戶控制臺到資料庫的請求鏈路也做了相應優化,每個云廠商都會為型別為 LoadBalancer 的 Service 或者 Ingress 提供配套的服務組件,這些組件可以解決負載均衡設備配置流程繁瑣的問題,通過在 Ingress 資源的 Annotation 里添加幾個配置項,就可以輕松拉起一個負載均衡設備,但凡事總有利弊,作為服務商簡化了管理,對應的在用戶端就會增加資費成本,另外,在實踐的程序中發現每家云廠商對基礎設施支持的完成度不盡相同,綜合以上因素考慮,我們基于 nginx-ingress-controller 做了鏈路優化,在管理平臺與業務集群打通網路的條件下,通過 External Service 將流量轉發到對應的訂閱實體,
在開發測驗流程上我們基于 Kubesphere 做了以下嘗試,
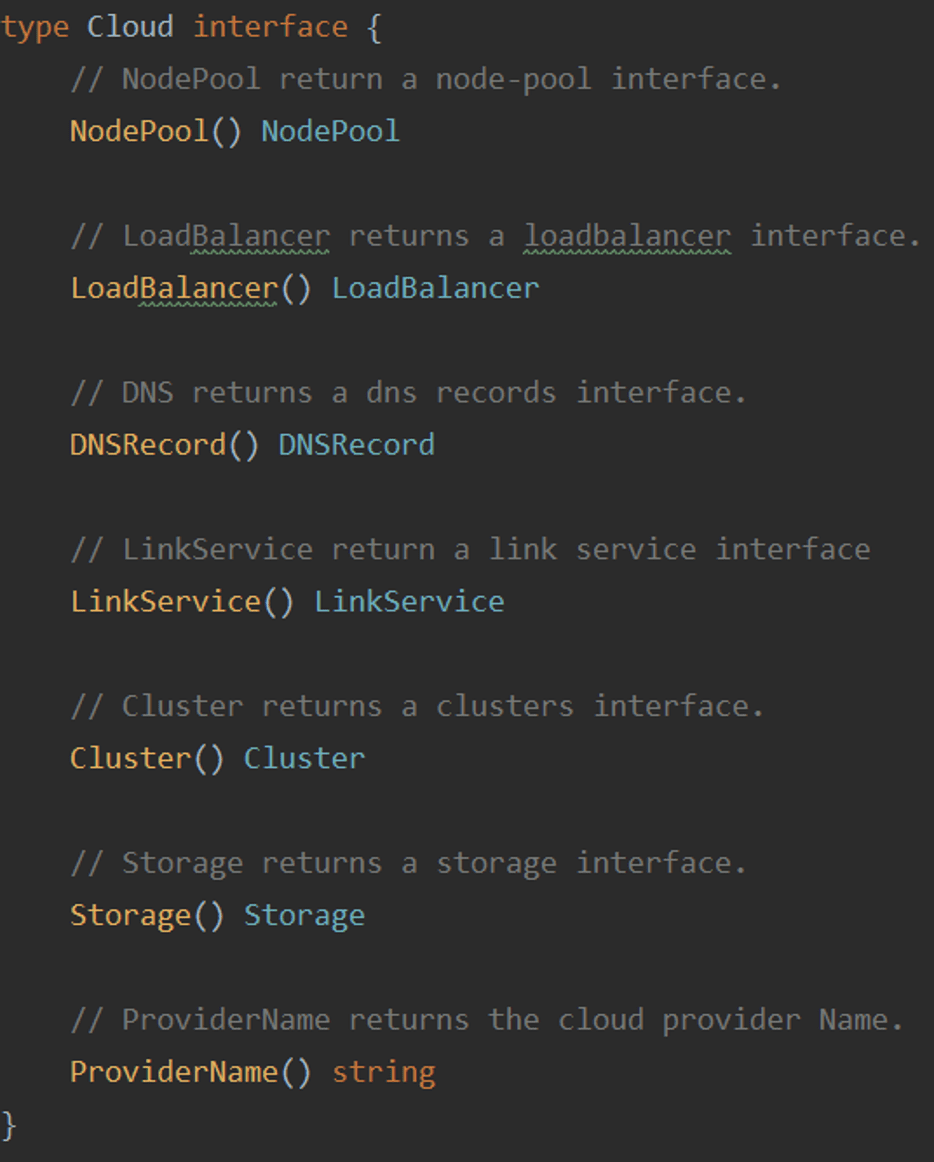
將基礎設施層抽象出 Cloud 介面,里面包含節點池、 負載均衡、DNS 域名等各個子介面,我們針對本地環境提供 Local Provider 的實作,除非像 Privatelink 比較特殊的服務,但是不會影響整體功能測驗,
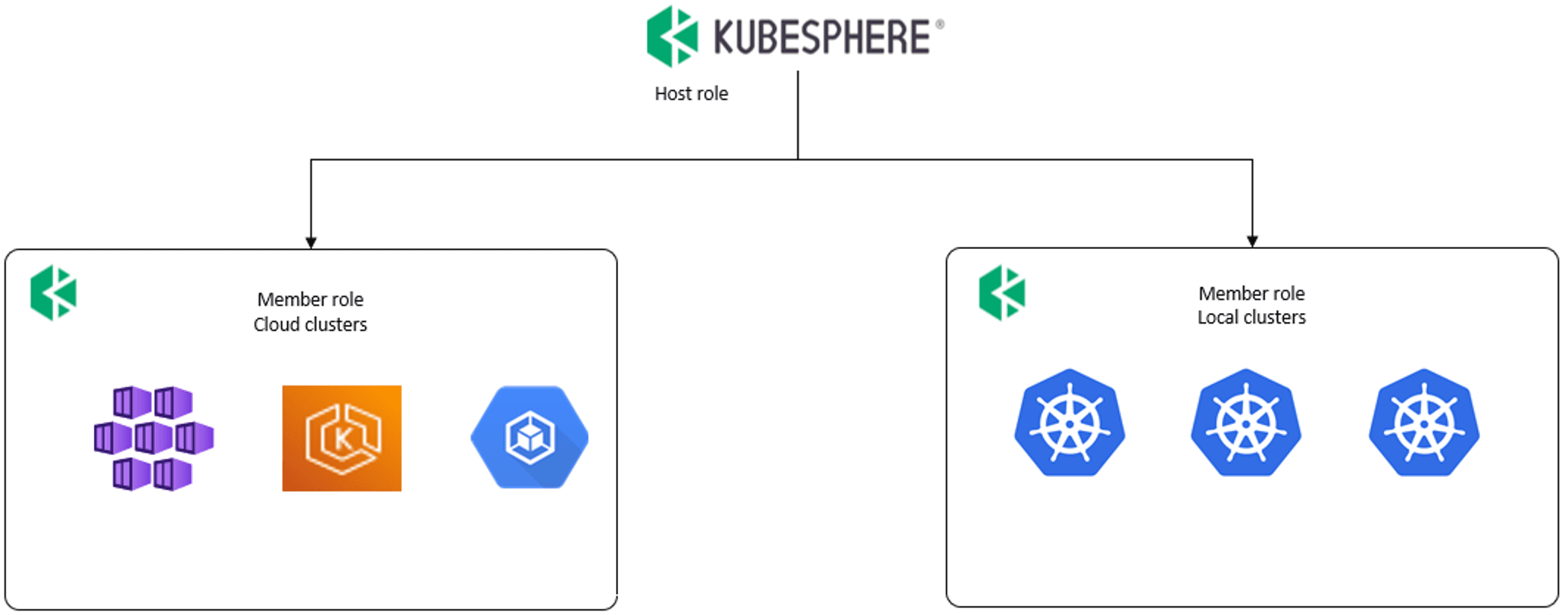
我們將 Kubernetes 集群分為兩種,一類是由云廠商托管的 cloud 集群,另外一類就是自己搭建的本地集群,將他們匯入到 Kubesphere 統一管理,
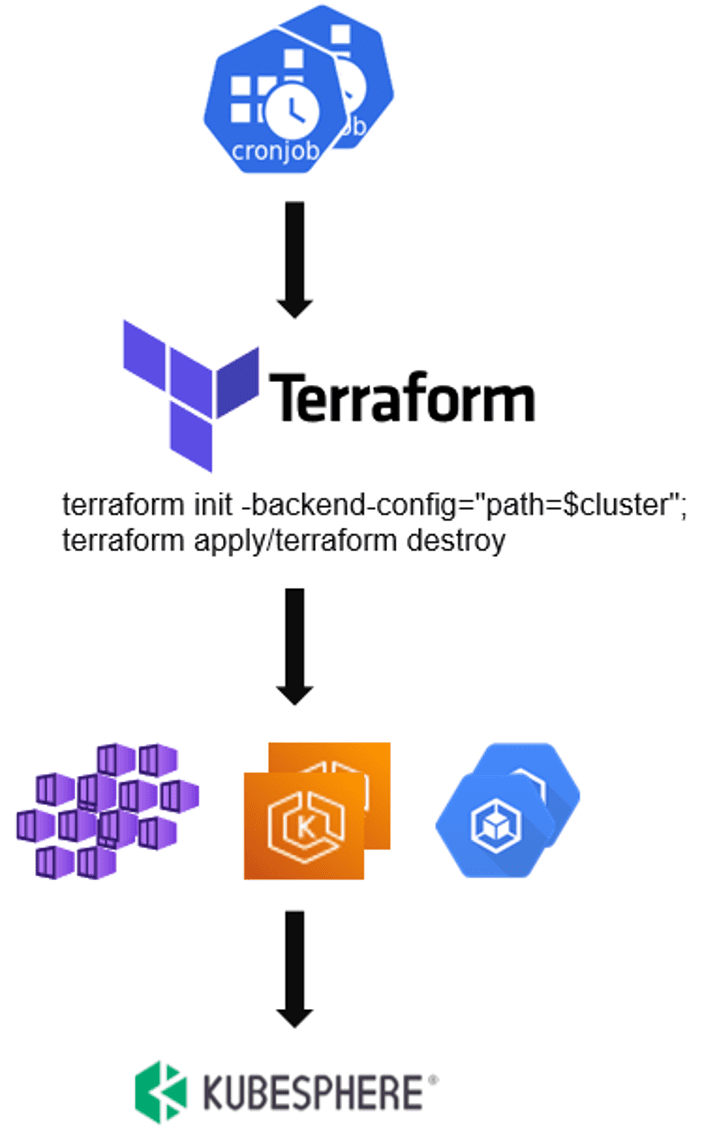
控制成本的核心是資源回收,我們通過 CronJob 定時創建、銷毀 cloud 型別的開發、測驗集群,同時設定 k8s 集群的系統節點池規格滿足最小化運行需求,內測期間無訪問流量的實體自動回收,通過這些策略將成本控制在一個比較理想的狀態,
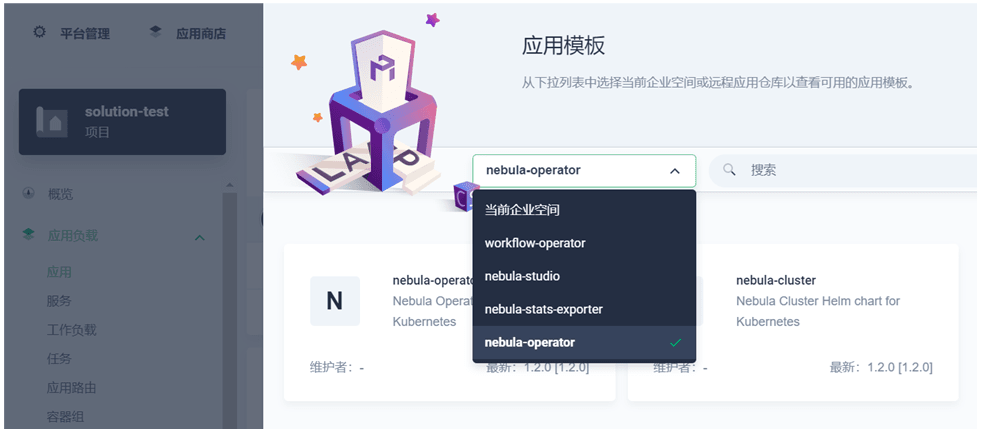
為了給不熟悉 Kubernetes 的同學測驗業務流程,我們為必要的服務組件提供了 helm charts 包,將他們上傳到 Kubesphere 應用倉庫然后提供應用模板來測驗流程,
總結與展望
總結
經過1年多的實踐,我們總結出以下幾點心得:
為了滿足安全合規、成本優化、提升地域覆寫性和避免廠商鎖等需求,以及客戶出于資料主權和安全隱私的考慮,混合云/多云架構已經成為通用解決方案,云原生軟體架構的目標是構建松耦合、具備彈性、韌性的分布式應用軟體架構,可以更好地應對業務需求的變化和發展,保障系統穩定性,IaC 可以進一步延伸到 Evething as Code,覆寫整個云原生軟體的交付、運維流程,釋放生產力,成本優化至關重要,不論是對客戶還是對服務商而言,
展望
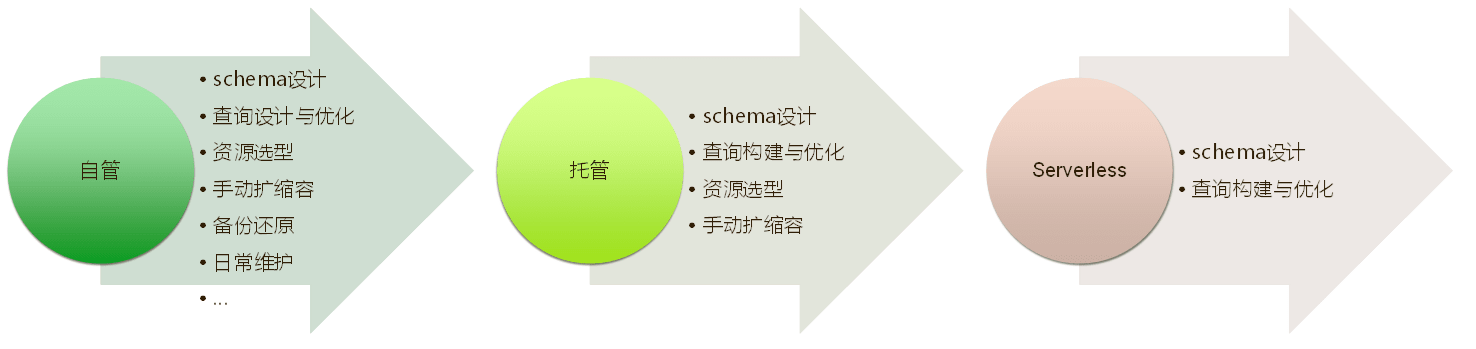
在應用研發的程序中,越來越多的開發者接受了無服務器的理念,Serverless 資料庫可按需求自動縮放配置,根據應用程式的需求自動擴展容量,并內置高可用和容錯能力,采用 Serverless 資料庫開發者將無需考慮選型問題,只需要關注如何設計 schema ,怎樣查詢資料,及如何進行相應的優化即可,對于 NebulaGraph,我們期望未來可以幫助用戶實作端到端的 Serverless 架構,進一步提升用戶體驗,
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/509130.html
標籤:其他