一、目標檢測概述
1.什么是目標檢測
目標檢測定義識別圖片中有哪些物體以及物體的位置(坐標位置)
2.傳統目標演算法到深度學習
2.1目標檢測演算法的變遷
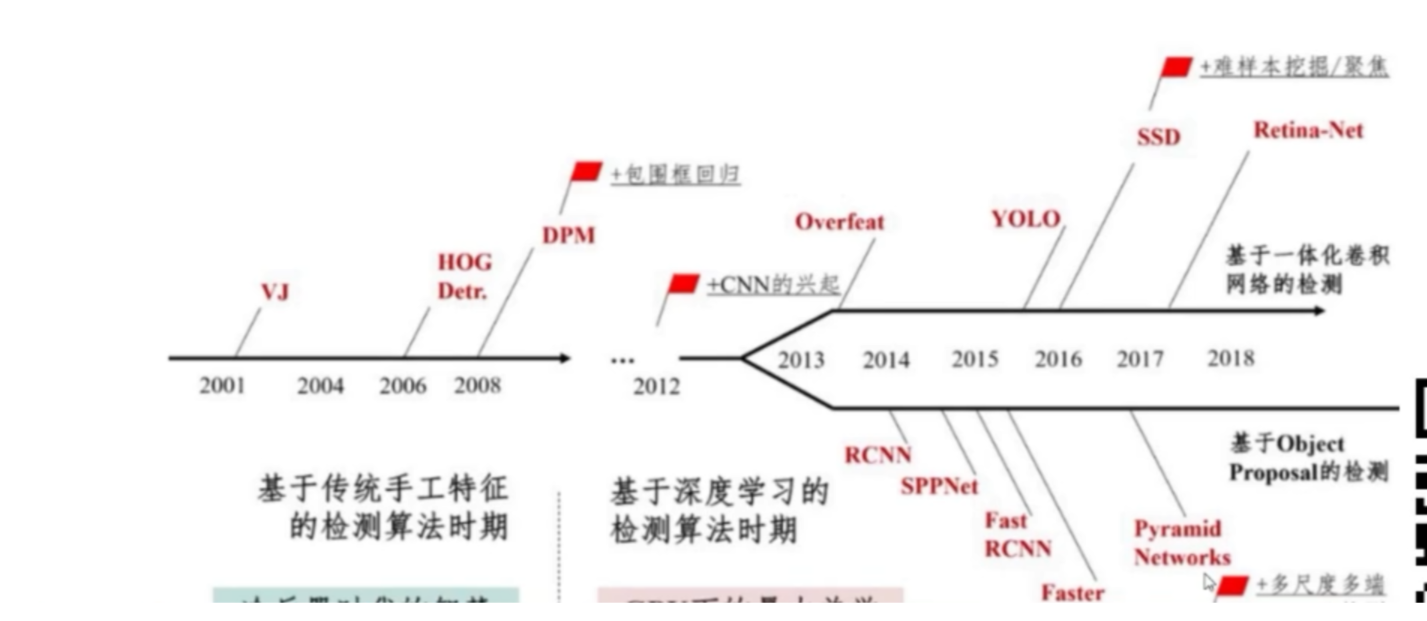
對于傳統的:
將待檢測作為輸入圖片,候選框的提取通常會通過滑動視窗的方法進行,對每一個視窗的區域性特征會采用傳統的計算機視覺和模式識別一些比較表征的方法,分別為基于顏色,紋理,形狀,以及一些中層次或者高層次的方法,有的是要經過學習來得到的方法,比如說湊趣直方圖特征,紋理特征,提取方法之后會通過PCA對特征進行降維度,或者通過LDA對演算法進行空間的投影,
分為三類:
(1)低層次的特征(手工設計的特征)
(2)中層次的特征:特征挖掘LDA之類的(學習的特征)
(3)高層次的特征:將低層次,中層次特征進行特征的挖掘
一般集中在第1,2類,
對于深度學習:
將特征提取的部分變成卷積神經網,候選框則通過一個RPN網路來完成(也就是twostage的目標檢測演算法),onestage的目標檢測演算法則通過直接回歸的方法來獲得可能得目標區域,位置,和目標的類別,
2.2演算法基本流程
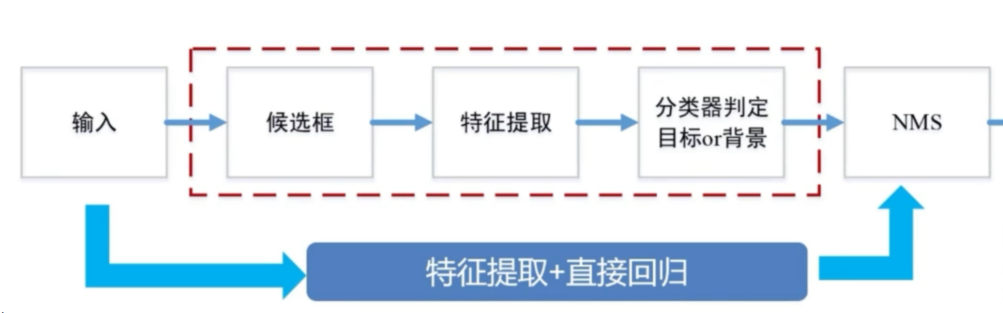
3.目標檢測任務描述
3.1目標檢測演算法分類
(1)傳統目標檢測方法(候選區域+手工特征提取+分類器)
HOG+SVM、DPM(傳統演算法中比較好)
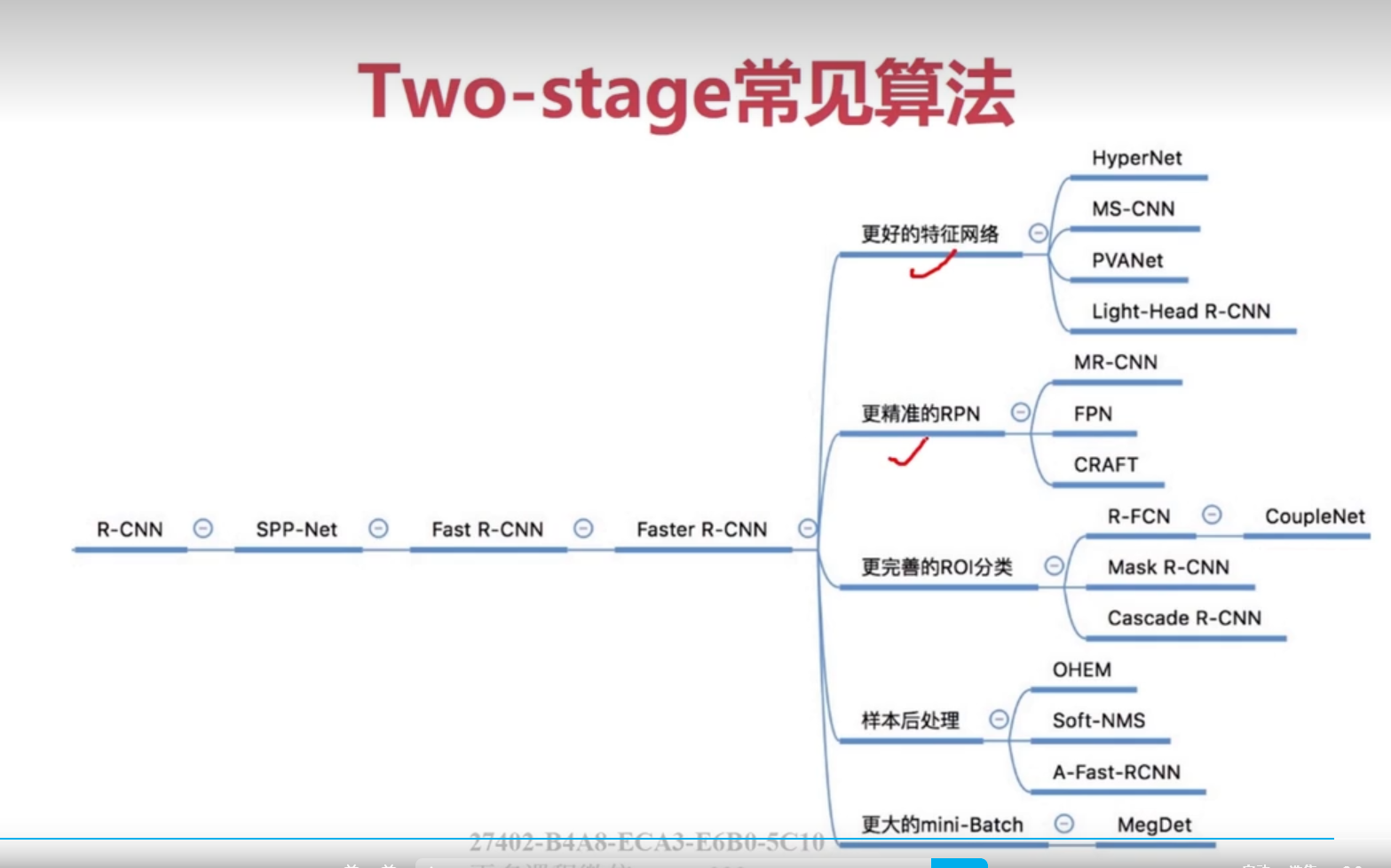
(2)region proposal+CNN提取分類的目標檢測框架
(R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN)
(3)端到端(End-to-End)的目標檢測框架
YOLO、SSD
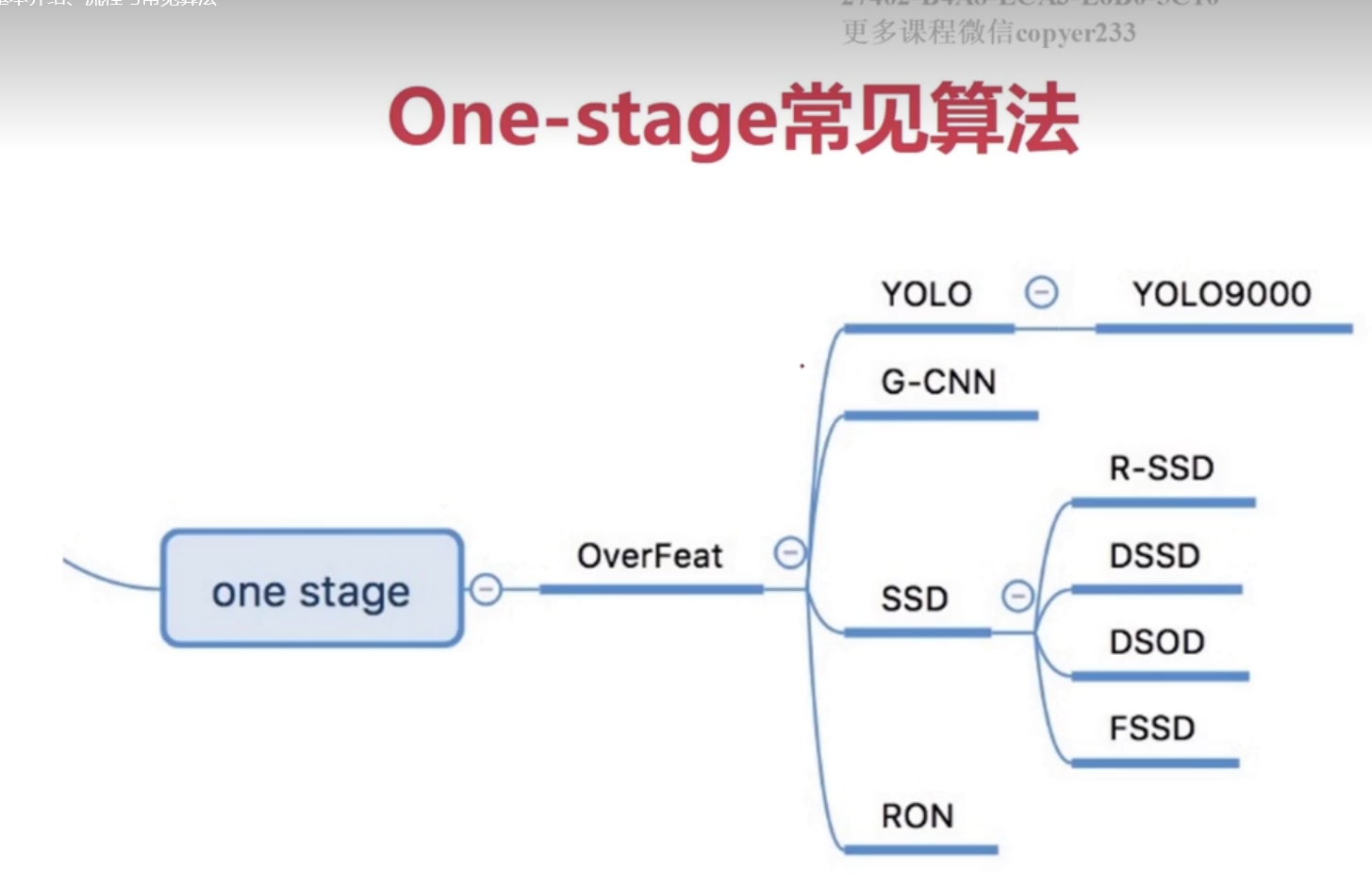
3.2目標檢測的常見指標
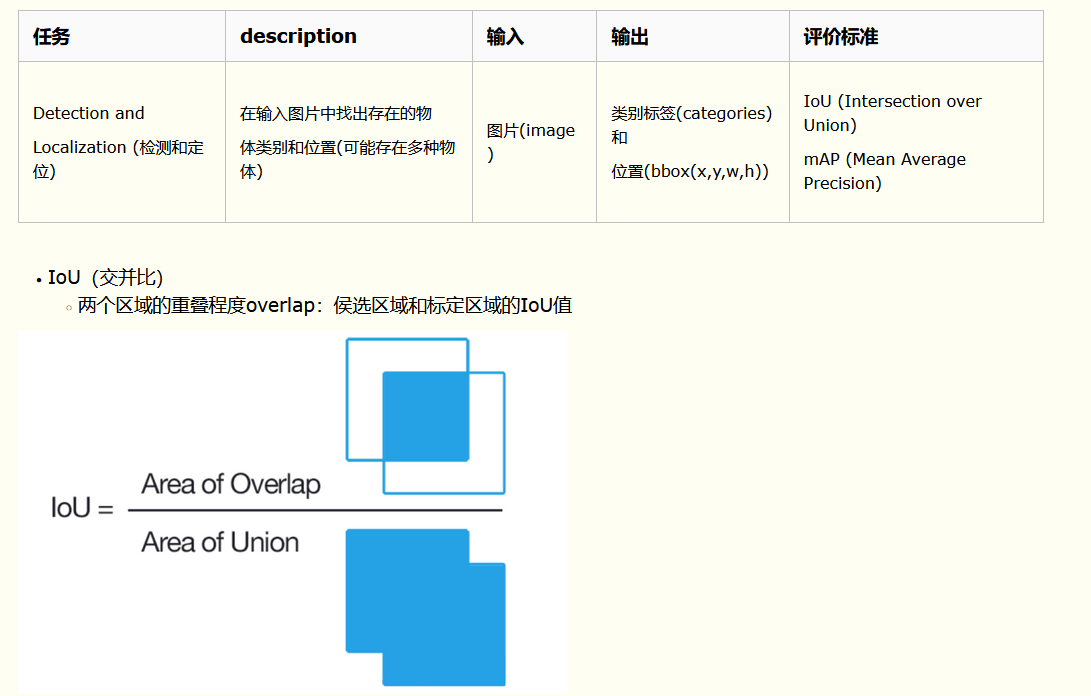
3.3目標定位的簡單實作
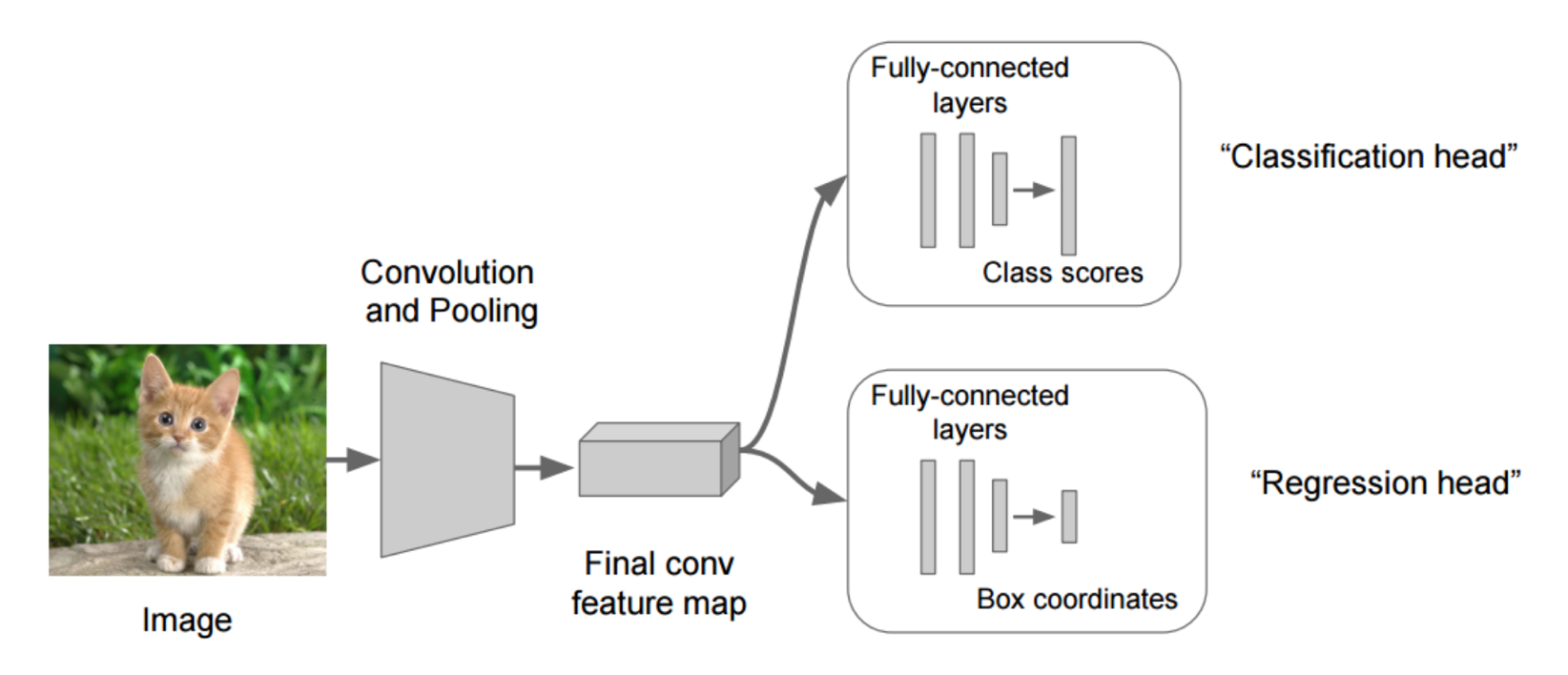
在分類的時候我們直接輸出各個類別的概率,如果再加上定位的話,我們可以考慮在網路的最后輸出加上位置資訊,
例如:增加一個全連接層,即為FC1、FC2FC1:作為類別的輸出,FC2:作為這個物體位置數值的輸出
假設有10個類別,輸出[p1,p2,p3,...,p10],然后輸出這一個物件的四個位置資訊[x,y,w,h]
位置數值的處理(歸一化)
對于輸出的位置資訊是四個比較大的像素大小值,在回歸的時候不適合,目前統一的做法是,每個位置除以圖片本身像素大小,
假設以中心坐標方式,那么x = x/x_image,y/y_image, w/x_image,h/y_image,也就是這幾個點最后都變成了0~1之間的值(歸一化),
參考檔案 :https://www.cnblogs.com/kongweisi/p/10894415.html
參考視頻:https://www.bilibili.com/video/BV1mb4y1H7ZB/?spm_id_from=333.999.0.0&vd_source=84555d77a58e708cf47319e185cf427a
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/509606.html
標籤:其他
上一篇:《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》論文筆記
下一篇:二、目標檢測演算法之R-CNN