摘要
1. 快速排序其實也是分而治之的思想
2. 快速排序是遞回的
3. 首先找一個基準點,把比基準點小的數字都放到它的左邊,比它大的數字都放在它的右邊,一趟下來基準點的位置找到了,且它左邊的數字小于(等于)它,右邊的數字大于(等于)它, 再遞回地對它左邊的數字和右邊的數字做同樣的操作,直到遞回結束則整個陣列有序, 一般的實作需要兩個指標,low初始指向需要排序的資料的頭部,high指向需要排序的資料的尾部,low向尾走,找尋比基準點大的數字;high向頭走,找尋比基準點小的數字,然后交換數字位置,相遇了則一次遞回呼叫結束,不同的實作細節上會略有差異,但思想大概都是這樣,
4. 快速排序的時間復雜度是O(N*logN), 最壞時間復雜度是O(N^2)
5. 基準點的選擇,可以選擇每段的第一個元素為基準點,但這樣在極端的情況下時間復雜度可能會退化為O(N^2), 可以采用每次隨機選擇元素作為基準點,
詳解
排序的步驟為:
1. 首先選擇基準點,以資料段的第一個元素作為基準點即可,即使是采用隨機的基準點的方法,也是隨機選擇元素的下標,將選擇的元素和第一個元素互換,將基準點的數字保存在變數num中,
2. 設定i,j 兩個下標(第一趟排序時i=0(陣列開頭), j=length-1(陣列結尾),后面遞回時,i每次都指向本次要排序的資料段(原陣列的一部分)的開頭元素,而j每次都指向結尾元素)
3. 每次都先移動j,往左一直找到<num的元素停下,然后移動i, 一直找>num的元素或者與j相遇,將i和j所指的元素交換,直到i和j相等,他們的位置就是基準點的位置,把這個位置的元素跟基準點原來的位置,也就是最左邊的位置互換,至此第一趟排序結束,基準點的位置(下標i)就是整體排序完成后它應該在的位置,它左邊的數字都小于等于它,右邊的數字都大于等于它,這時陣列就被基準點分為了兩半,左半段下標為[0~i-1], 右半段的下標為[i+1,length-1].
4. 遞回對左半段和右半段進行上面第3步的操作,每一段的開頭下標為s(start),結尾下標為e(end). 程式結束的條件是s>=e(本段沒有數字或者只有一個數字)
先上代碼:
1 public static void quickSort_NG(int[] testArr,int s, int e) { 2 if(s >= e) {return;} 3 int p = testArr[s];//p為上文中的num 4 int l = s, r=e; //l為上文中的i,r為j 5 while(l<r) { 6 while(testArr[r] >= p && l<r) {r--;} 7 while(testArr[l] <= p && l<r) {l++;} 8 int temp = testArr[l]; 9 testArr[l] = testArr[r]; 10 testArr[r] = temp; 11 12 } 13 testArr[s] = testArr[l]; 14 testArr[l] = p; 15 quickSort_NG(testArr,s,l-1); 16 quickSort_NG(testArr,l+1,e); 17 18 } 19 public static void main(String[] args) { 20 int[] testArr = {4,3,8,1,-1,2,5,4}; 21 quickSort_NG(testArr,0,testArr.length-1); 22 }
步驟推演和圖解:
如果上面的說明和代碼仍然比較抽象的話,看下面每一步的推演和圖示一定可以明白:
仍然是用代碼中的例子, 用一個有8個元素的陣列[4,3,8,1,-1,2,5,4] ,包含一個重復數字4.
下面的表格是每一步的操作程序:
其中每一次排序的資料用相同顏色的底紋,
|
下標 0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
4 |
3 |
8 |
1 |
-1 |
2 |
5 |
4 |
|
i |
|
|
|
|
|
|
j |
|
Num=4,先移動j,向左一直到找到<num的數字,來到2的位置,然后移動i,向右一直找到>num的數字,來到8的位置,如下: |
|||||||
|
|
|
i |
|
|
j |
|
|
|
交換i j 位置的元素 |
|||||||
|
4 |
3 |
2 |
1 |
-1 |
8 |
5 |
4 |
|
重復上面i,j 移動的邏輯,j來到-1的位置,i向右移動,沒有找到>num的數字,與j在-1處相遇 |
|||||||
|
|
|
|
|
i j |
|
|
|
|
i j 相遇的位置為num在排序完后應該在的位置,把它的位置的數字與num原來的位置(也就是本段開頭的位置)的數字互換,這里就是4和-1互換位置 |
|||||||
|
-1 |
3 |
3 |
1 |
4 |
8 |
5 |
4 |
|
至此第一趟排序結束,樞軸的下標位置為4,左半段下標為[0~3],右半段下標為[5~7],下面進入遞回進入其左半段的排序 |
|||||||
|
-1 |
3 |
3 |
1 |
|
|
|
|
|
i |
|
|
j |
|
|
|
|
|
Num = -1, j先向左移動,一直沒有找到<-1的數字,直到與i相遇,此趟排序沒有變化,樞軸的位置為下標0,左半段[0~-1], 右半段[1~3], 此時還是進入左半部分的遞回,但左半部分的左邊界0>右邊界-1,直接退出,進入右半部分 |
|||||||
|
|
3 |
3 |
1 |
|
|
|
|
|
|
i |
|
j |
|
|
|
|
|
Num=3, j先移動,它目前所在位置的1<num,所以不動,移動i,沒有找到>num的數字,在1處于j相遇 |
|||||||
|
|
|
|
i j |
|
|
|
|
|
i j 相遇的位置就是排序完成后num應該在的位置,把它的位置的數字與num原來的位置(也就是本段開頭的位置)的數字互換,這里就是3和1互換位置 |
|||||||
|
|
1 |
3 |
3 |
|
|
|
|
|
本趟排序結束,樞軸的位置為下標3,左半段為[1~2],右半段為[4~3],遞回進入左半段的排序 |
|||||||
|
|
1 |
3 |
|
|
|
|
|
|
|
i |
j |
|
|
|
|
|
|
Num=1, 先移動j,直接與i在1的位置相遇,本次排序結束,進入右半段的排序,但是右半段[4~3],左邊界>右邊界,表明了沒有數字,直接退出,至此整體的左半段排序完成,方法呼叫來到整體的右半段 |
|||||||
|
-1 |
1 |
3 |
3 |
4 |
8 |
5 |
4 |
|
|
|
|
|
|
i |
|
j |
|
Num=8,先移動j,它當前所在的4<num,先不動,移動i,沒有找到>num的數字,在4的位置與j相遇,交換8和4的位置 |
|||||||
|
|
|
|
|
|
|
|
i j |
|
|
|
|
|
|
4 |
5 |
8 |
|
此趟排序完成,樞軸的位置為下標7, 左半段為[5~6],右半段為[8~7],遞回進入其左半段的排序 |
|||||||
|
|
|
|
|
|
4 |
5 |
|
|
|
|
|
|
|
i |
j |
|
|
Num=4, 先移動j,在4處與i相遇,4與自己交換,本次排序結束,右半段的左邊界8>右邊界7,證明沒有數字,直接退出 |
|||||||
|
|
|
|
|
|
ij |
|
|
|
至此排序結束 |
|||||||
|
-1 |
1 |
3 |
3 |
4 |
4 |
5 |
8 |
下面再用圖概括一下整體的程序:
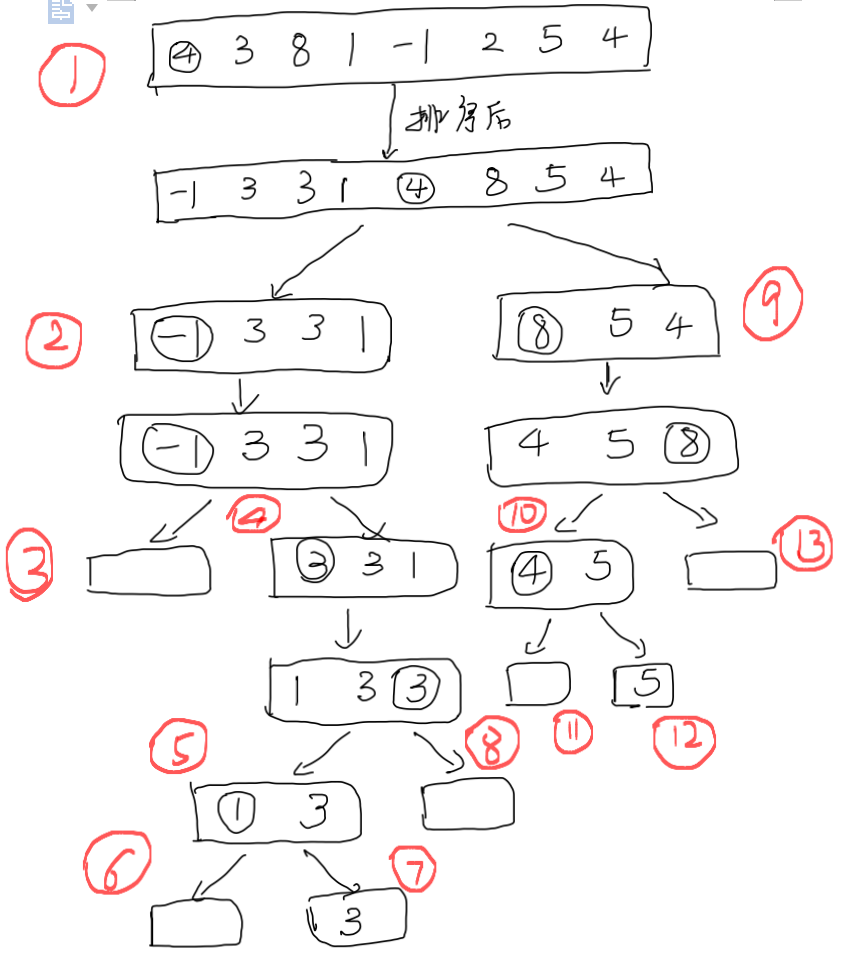
圖中紅色的數字為每一次進入quickSort_NG方法的順序,我們可以發現,這個順序其實就是二叉樹的深度優先遍歷,
關于時間復雜度
眾所周知,快速排序的時間復雜度是O(N*logN), 其實上面的演算法在最壞的情況,時間復雜度可以退化到O(N^2),
我們先看一下時間復雜度是如何計算的,
其實很自然的我們就可以想到,這個演算法所花費的時間就是:方法呼叫所花費的時間*方法遞回呼叫的次數,
那么我們先看一次方法呼叫所花費的時間,我們在一次方法中所進行的操作(除了遞回呼叫自己之外)是:
1. 左右指標i, j 對陣列進行了一次遍歷,操作次數為此段陣列的長度n
2.遍歷的時候會與基準點的數字進行比較,n個數字比較n次
3.最后交換一下基準點的位置,操作次數為1
所以操作次數為2n+1, 我們知道算時間復雜度的時候會忽略掉常數, 而且是只去最高冪次項,所以每一次呼叫的時間復雜度為O(N), N為每次呼叫的陣列長度,我們可以簡單的認為每次方法呼叫所耗費的時間是N個單位時間,其中N是本次呼叫的陣列長度,
那么我們會遞回呼叫多少次呢,為了看得更清晰,我們舉一個最好情況的例子,假設我們有8個數字,而每次我們選擇的基準點的位置都能把陣列分為大概相等的兩部分,如下圖:
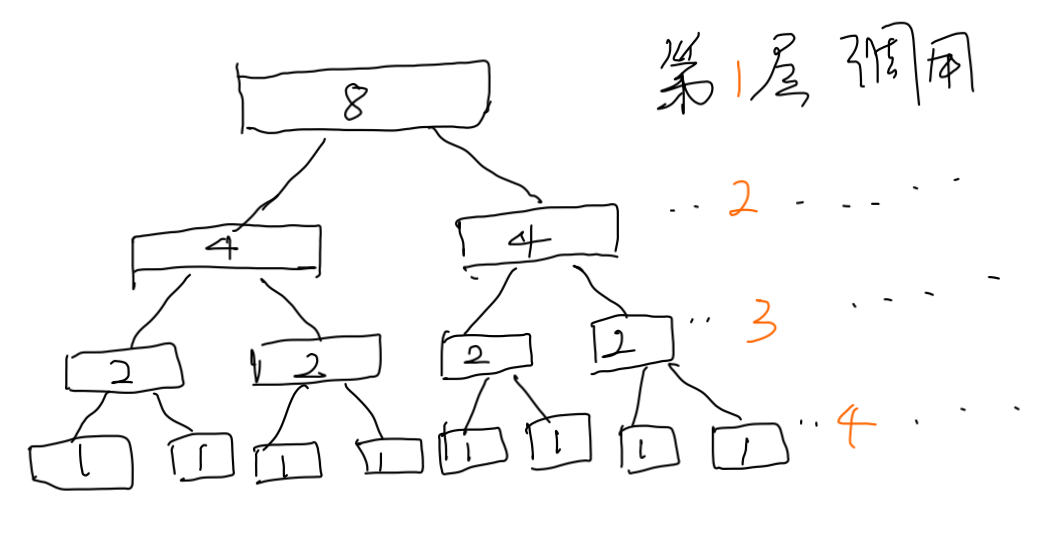
第一層初始呼叫時有8個元素,第一趟排序后分成比較均勻的兩段,然后遞回地呼叫,其實此處不是很準確, 每次排序完基準點的位置就確定了,不用參與到后面的排序,所以理論上第一次排序參與下次排序的是7個元素,均勻的情況也不是分成4,4的兩段, 可能是4,3或者3,4,為了直觀才這樣畫,便于理解,
我們可以看到有4層的方法呼叫,其實就是(log8+1), 第一層方法呼叫一次,元素個數是8, 第二層方法呼叫兩次,每次元素個數是4.以此類推, 我們上面又推匯出每次方法呼叫的時間是跟該次呼叫的元素個數線性相關的,那么本次排序所花費的總時間是(每一層的方法呼叫時間加起來):
8+4*2+2*4+1*8 個單位時間,發現每層呼叫的時間相同,都是8,我們把8替換成N,可以發現是N+N+N+N,也就是4個N,4這個數字其實是log8+1, 同樣把8替換成變數N,我們可以得到時間是(logN+1)*N. 由于時間復雜度只保留最高冪次項,結果為O(logN*N)
改進空間
現在我們考慮下面這組數字:
1,2,3,4,5,6,7,8,9
仍然用上面的方法,發現每次只能搞定一個數字,每趟排序完都是只有右半段有資料,左半段是空,呼叫層數增加,這時候的時間復雜度退化成了O(N^2).
改進的思路有兩個(這部分為整理左神的視頻課):
1. 每次都從待排序的資料段中隨機選擇一個數字作為基準點,把它跟第一個或最后一個數字交換,隨機選擇基準點的方式選擇到每個數字的概率相等,將每種的概率乘以該種情況下的時間復雜度,做累加,然后求長期期望,可以得到時間復雜度為O(N*logN).
2. 上面的排序方法還有一個小問題,我們發現原始陣列[4,3,8,1,-1,2,5,4] 中有兩個4,在我們第一趟排序選擇4為基準點排序后,兩個4沒有在一起,其實此處可以應用荷蘭國旗問題的思路,每趟排序后達成比基準點小的數字在左邊,等于基準點的數字在中間,大于基準點的數字在右邊,這樣如果有重復的數字作為基準點的話,一次就能確定多個數字的位置,比每次只確定一個數字的位置理論上會快一些,
每趟排序的思路與上面類似,略有不同,具體如下:
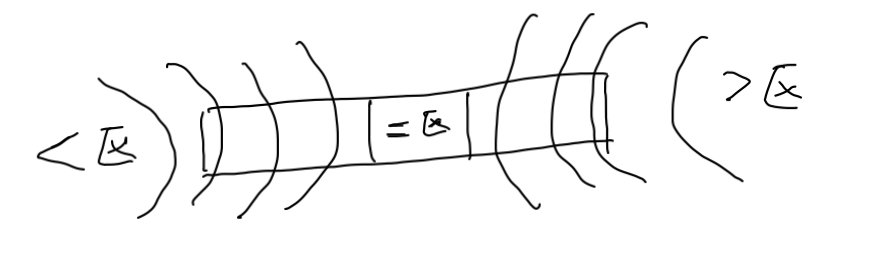
1. 首先選取每段陣列的基準點,陣列的左邊為<區,設定low為<區的右邊界,初始為[陣列的第一個下標-1],也就是初始<區沒有數字;陣列的右邊為>區,設定hign為>區的左邊界,初始為陣列的長度n,也就是初始的時候>區也沒有數字,
2.設定指標i,初始指向本段陣列的第一個數字
3.指標i后移,假設陣列名字為arr, 基準點為num:
1)如果arr[i]<num,則將arr[i]與<區的下一個數字做交換,且<區向右擴展一位,i右移一位
2)如果arr[i]==num, 則i右移一位,無其他操作
3)如果arr[i]>num,則將arr[i]與>區的前一個數字做交換,且>區向左擴展一位,i原地不動,
4. 當指標i和>的左邊界high相遇時,本趟排序結束
5. 每趟排序結束時,陣列的開頭到low指標的位置是下次待排序的左半段, hign指標到陣列結尾的位置為下次待排序的右半段, low 和high之間的為基準點數字,可能不止一個,
6. 遞回地對左半段和右半段進行排序
結合上面兩個改進思路的代碼如下:
1 public static void quickSort(int[] testArr, int s, int e) { 2 if(s >= e) {return;} 3 int low = s-1, high = e+1,i = s; 4 //隨機選擇一個數字作為基準點,這種寫法好像不用把它換到頭部或者尾部 5 int num = testArr[s+(int)(Math.random() * (e-s+1))]; 6 while(i<high) { 7 if(testArr[i] < num) { 8 swap(testArr,i++,++low); 9 } else if(testArr[i] == num){ 10 i++; 11 } else{ 12 swap(testArr,i,--high); 13 } 14 } 15 quickSort(testArr, s, low); 16 quickSort(testArr, high, e); 17 }
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/509610.html
標籤:其他