論文題目:《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》
論文作者:Qibin Hou, Zihang Jiang, Li Yuan et al.
論文發表年份:2022.2
模型簡稱:ViP
發表期刊: IEEE Transactions on Pattern Analysis and Machine Intelligence
Abstract
在本文中,我們提出了一種概念簡單、資料高效的類似MLP的視覺識別體系結構——視覺置換器(Vision Permutator),不同于最近的類似MLP的模型大都沿著平坦的空間維度編碼空間資訊,由于認識到二維特征表示所攜帶的位置資訊的重要性,Vision Permutator通過線性投影分別對沿高度和寬度維度的特征表示進行編碼,這使得Vision Permutator可以沿著一個空間方向捕獲遠程依賴關系,同時保持沿著另一個方向的精確位置資訊,由此產生的位置敏感輸出,然后以相互補充的方式聚合,形成感興趣的物件的表達,Vision Permutator由純1 × 1卷積組成,但可以對全域資訊進行編碼,Vision Permutator也消除了對自注意力的依賴,因此效率更高,開源代碼: https://github.com/Andrew-Qibin/VisionPermutator
Method
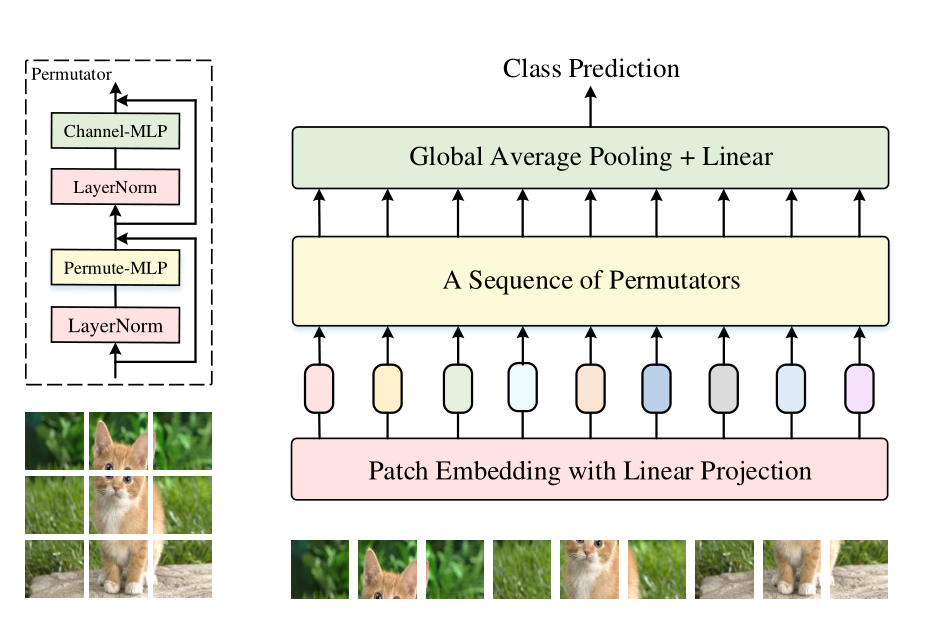
Vision Permutator從與Vision Transformers類似的tokenization操作開始,它將輸入影像統一地分割為小塊,然后將它們映射到帶有線性投影的token embedding,然后將形狀為“height×width×channels”的結果token embeddings到Permutator block序列中,每個Permutator block由一個用于空間資訊編碼的Permute-MLP和一個用于通道資訊混合的Channel - MLP組成,Permute-MLP層如下圖所示,
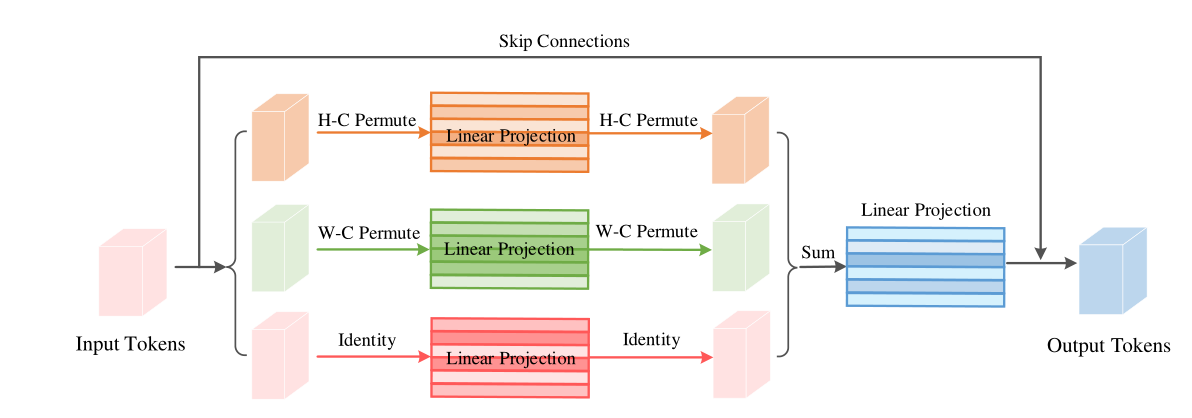
Permute-MLP層由三個獨立的分支組成,每個分支沿特定的維度編碼特征,即高度、寬度或通道維度,Channel-MLP模塊的結構與Transformer中的前饋層相似,包括兩個完全連接的層,中間有一個GELU激活,公式如下:

對于Channel資訊編碼,只需要一個權重WC∈RC×C的全連接層,就可以對輸入X進行線性投影,得到XC,對于高度資訊編碼,首先對傳入的分割好的每個tokens作維度變換(ex:Transpose the first (Height) dimension and the third (Channel) dimension: (H, W, C) → (C, W, H).)然后沿著通道維度連接它們作為Premute的輸出,傳入Linear Projection:連接權重為WH∈RC×C的全連接層,混合高度資訊,再通過維度變換復原輸入維度,對寬度資訊編碼作類似處理,最后講三個分支的輸出加和作為最后全連接層的輸入,Linear Projection的輸出公式表示如下:(最后輸出再與input tokens作跳躍連接得到最終Permute-MLP的輸出,)
![]()
Weighted Permute-MLP:上述方法只是簡單地將所有三個分支的輸出通過元素相加來融合,在這里,我們通過重新校準不同分支的重要性,進一步改進了上述Permute-MLP,并提出加權Permute-MLP,這可以通過利用分散注意力(split attention)實作,不同的是,分散注意力應用于XH、XW和XC,而不是由分組卷積生成的一組張量,在下文中,我們默認使用Permutator中的加權Permute-MLP,
Experiment
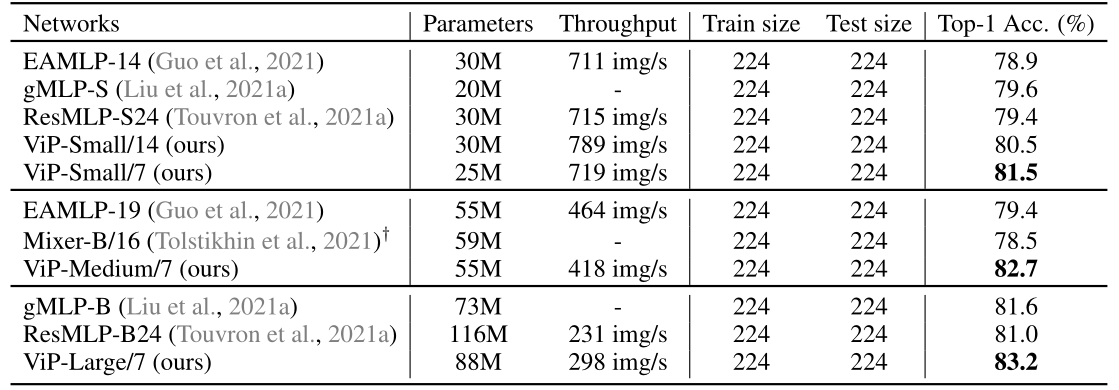
與ImageNet上最近的類MLP模型比較Top-1精度,所有模型都是在沒有外部資料的情況下進行訓練的,在相同的計算量和引數約束下,我們的模型始終優于其他方法,
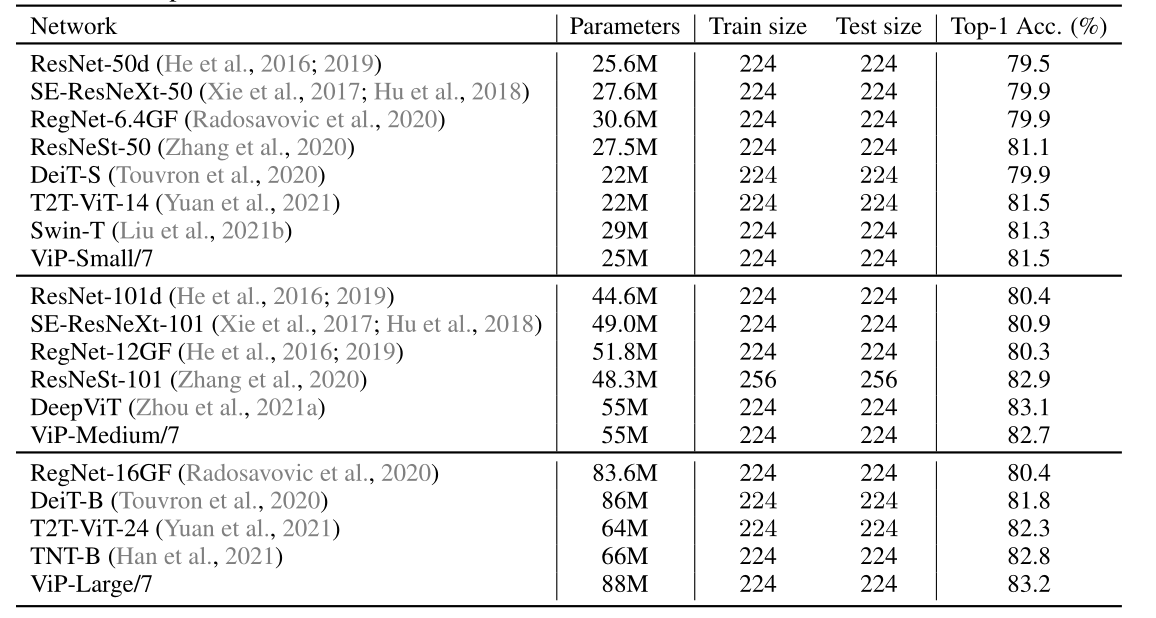
與ImageNet上的經典CNN和Vision Transformer的精度比較,所有模型都是在沒有外部資料的情況下進行訓練的,在相同的計算和引數約束下,我們的模型可以與一些強大的基于CNN和基于Transformer的模型競爭,
.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/509612.html
標籤:其他
上一篇:App Deploy as Code! SAE & Terraform 實作 IaC 式部署應用
下一篇:輕量級作業流引擎的設計與實作