二、目標檢測演算法之R-CNN
1、R—CNN發展程序和各自的優缺點
1.1 R-CNN
(1)R-CNN原理
通過滑動視窗來檢測不同的目標型別(從左到右、從上到下滑動視窗,利用分類識別目標),我們使用不同大小和寬高比的視窗,
這樣就變成每張子圖片輸出類別以及位置,變成分類問題,但是滑動視窗需要初始設定一個固定大小的視窗,這就遇到了一個問題,有些物體適應的框不一樣,所以需要提前設定K個視窗(為了物體適應框不一樣,所以這k個視窗大小是不一樣的),每個視窗滑動提取M個,總共K x M 個圖片,通常會直接將影像變形轉換成固定大小的影像,變形影像塊被輸入 CNN 分類器中,
提取特征后,我們使用一些分類器識別類別和該邊界框的另一個線性回歸器,
簡而言之,當一張圖片中存在多個目標時,我們需要想辦法將其轉變成多張固定大小的子圖片,然后通過CNN提取特征,再進行類別分類(識別)和邊框回歸(后面會說),這樣,一個多目標的檢測問題,就轉變成了機器學習常見的多分類問題,
(2)R-CNN缺點
- 1、訓練階段多:步驟繁瑣: 微調網路+訓練SVM+訓練邊框回歸器,
- 2、訓練耗時:占用磁盤空間大:5000張影像產生幾百G的特征檔案,(VOC資料集的檢測結果,因為SVM的存在)
- 3、處理速度慢: 使用GPU, VGG16模型處理一張影像需要47s,
- 4、圖片形狀變化:候選區域要經過crop/warp進行固定大小,無法保證圖片不變形
1.2 Fast R-CNN
(1)Fast R-CNN原理
使用特征提取器(CNN)先提取整個影像的特征,然后將創建候選區域的方法直接應用到提取到的特征圖上, 這些關注區域隨后會結合對應的特征圖以裁剪為特征圖塊,并用于目標檢測任務中,我們使用 ROI 池化將特征圖塊轉換為固定的大小,并饋送到全連接層進行分類和定位,
(2)Fast R-CNN優缺點
優點:
因為 Fast-RCNN 不會重復提取特征,因此它能顯著地減少處理時間,
Fast R-CNN 最重要的一點就是包含特征提取器、分類器和邊界框回歸器在內的整個網路能通過多任務損失函式進行端到端的訓練,這種多任務損失即結合了分類損失和定位損失的方法,大大提升了模型準確度
缺點:
Fast R-CNN 依賴于外部候選區域方法,如選擇性搜索,但這些演算法在 CPU 上運行且速度很慢,在測驗中,Fast R-CNN 需要 2.3 秒來進行預測,其中 2 秒用于生成 2000 個 ROI,
1.2 Faster R-CNN
(1)Faster R-CNN原理
Faster R-CNN在Fast R-CNN的基礎上用內部深層網路代替了候選區域方法,
(2)Faster R-CNN優缺點
優點:新的候選區域網路(RPN)在生成 ROI 時效率更高,并且以每幅影像 10 毫秒的速度運行,
拓展:
ROI 池化:
因為 Fast R-CNN 使用全連接層,全連接層同一批影像的輸入必須是同一大小的,所以我們應用 ROI 池化將不同大小的 ROI 轉換為固定大小,
(他會先對特征圖分成好幾個小塊,然后對每個小塊取最大值的出一個新的維度的特征值,)
2、R-CNN演算法原理
2.1R-CNN步驟
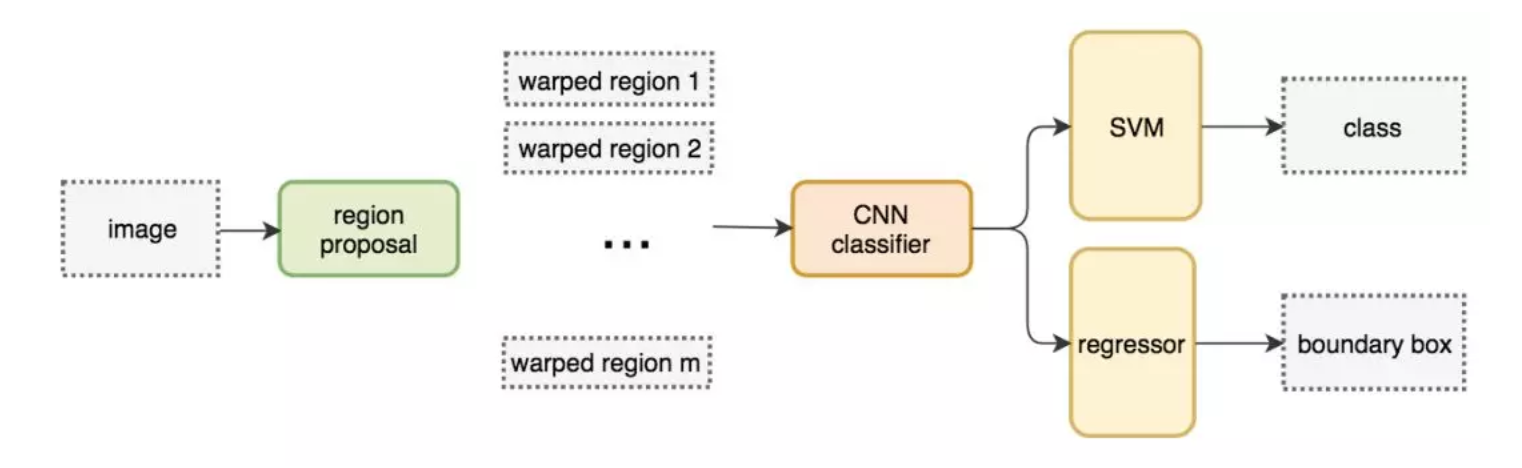
步驟(以AlexNet網路為基準)
1.找出圖片中可能存在目標的侯選區域region proposal
2.進行圖片大小調整為了適應AlexNet網路的輸入影像的大小227×227,通過CNN對候選區域提取特征向量,2000個建議框的CNN特征組合成2000×4096維矩陣
3.將2000×4096維特征與20個SVM組成的權值矩陣4096×20相乘(20種分類,SVM是二分類器,則有20個SVM),獲得2000×20維矩陣
4.分別對2000×20維矩陣中每一列即每一類進行非極大值抑制(NMS:non-maximum suppression)剔除重疊建議框,得到該列即該類中得分最高的一些建議框
5.修正bbox,對bbox做回歸微調
2.2 候選區域
選擇性搜索(SelectiveSearch,SS)中,首先將每個像素作為一組,然后,計算每一組的紋理,并將兩個最接近的組結合起來,但是為了避免單個區域吞噬其他區域,我們首先對較小的組進行分組,我們繼續合并區域,直到所有區域都結合在一起,下圖第一行展示了如何使區域增長,第二行中的藍色矩形代表合并程序中所有可能的 ROI,

SelectiveSearch在一張圖片上提取出來約2000個侯選區域,需要注意的是這些候選區域的長寬不固定, 而使用CNN提取候選區域的特征向量,需要接受固定長度的輸入,所以需要對候選區域做一些尺寸上的修改,
2.3 特征向量訓練分類器SVM
假設原圖片有2000個候選區,將其輸入進一個CNN中(進行卷積、池化...得到各種抽象的特征),輸出2000x4096的特征向量,此時找到N個(需要分類多少個找多少個,如分為20類)SVM分類器,每個分類器都會對2000個候選區域的特征向量分別判斷一次,即2000x4094的特征向量分別與N個不同類的SVM分類器,每個分類器都會對2000個候選區域的特征向量分別判斷一次,,這樣得出[2000, N]的得分矩陣,

每個SVM分類器做的事情
- 判斷2000個候選區域是某類別,還是背景
2.3 非最大抑制(NMS)

NMS首先會對檢測寬概率值進行排序,選出得分最高的,然后再計算LU面積大(也就是重疊率高)那些框進行洗掉,面對還有一些沒有處理過的檢測框再重新進行排序,然后選出得分最高的的,然后再計算這個同其他檢測框的的LU面積,然后將LU面積大于某些預值的框進行洗掉,不斷迭代,直到所有框都被處理過,輸出最終框,
NMS改進的演算法soft-NMS:認為直接通過采用預值進行判斷太粗暴,變成了檢測框位置的調整,對于低檢測率的也能保證物體的性能,

2.4 R-CNN測驗程序
- 輸入一張影像,利用selective search得到2000個region proposal,
- 對所有region proposal變換到固定尺寸并作為已訓練好的CNN網路的輸入,每個候選框得到的4096維特征
- 采用已訓練好的每個類別的svm分類器對提取到的特征打分,所以SVM的weight matrix(權重矩陣)是4096xN,N是類別數,這里一共有20個SVM,得分矩陣是2000x20
- 采用non-maximun suppression(NMS)去掉候選框
- 得到region proposal(oU超過某個閾值且IOU最大)進行邊框回歸,
參考鏈接:https://www.cnblogs.com/kongweisi/p/10895055.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/509620.html
標籤:其他
下一篇:賬號和權限管理7