1 導引
在知識圖譜領域,最重要的任務之一就是物體對齊 [1](entity alignment, EA),物體對齊旨在從不同的知識圖譜中識別出表示同一個現實物件的物體,如下圖所示,知識圖譜\(\mathcal{G}_1\)和\(\mathcal{G}_2\)(都被虛線框起來)是采自兩個大型知識圖譜Wikida和DBpedia的小子集,圓角矩形框表示物體,方角矩形表示屬性值,圓角矩形之間的箭頭代表一個關系謂詞(relation predicate),而這就進一步形成了關系元組,如\((\text{dbp}: \text{Victoria}, \text{country}, \text{dbp}:\text{Australia})\),一個圓角矩形和方角矩陣之間的箭頭表示一個屬性謂詞,而這形成一個屬性元組,比如\((\text{dbp}:\text{Victoria}, \text{total\_area}, \text{237659 km}^2)\),
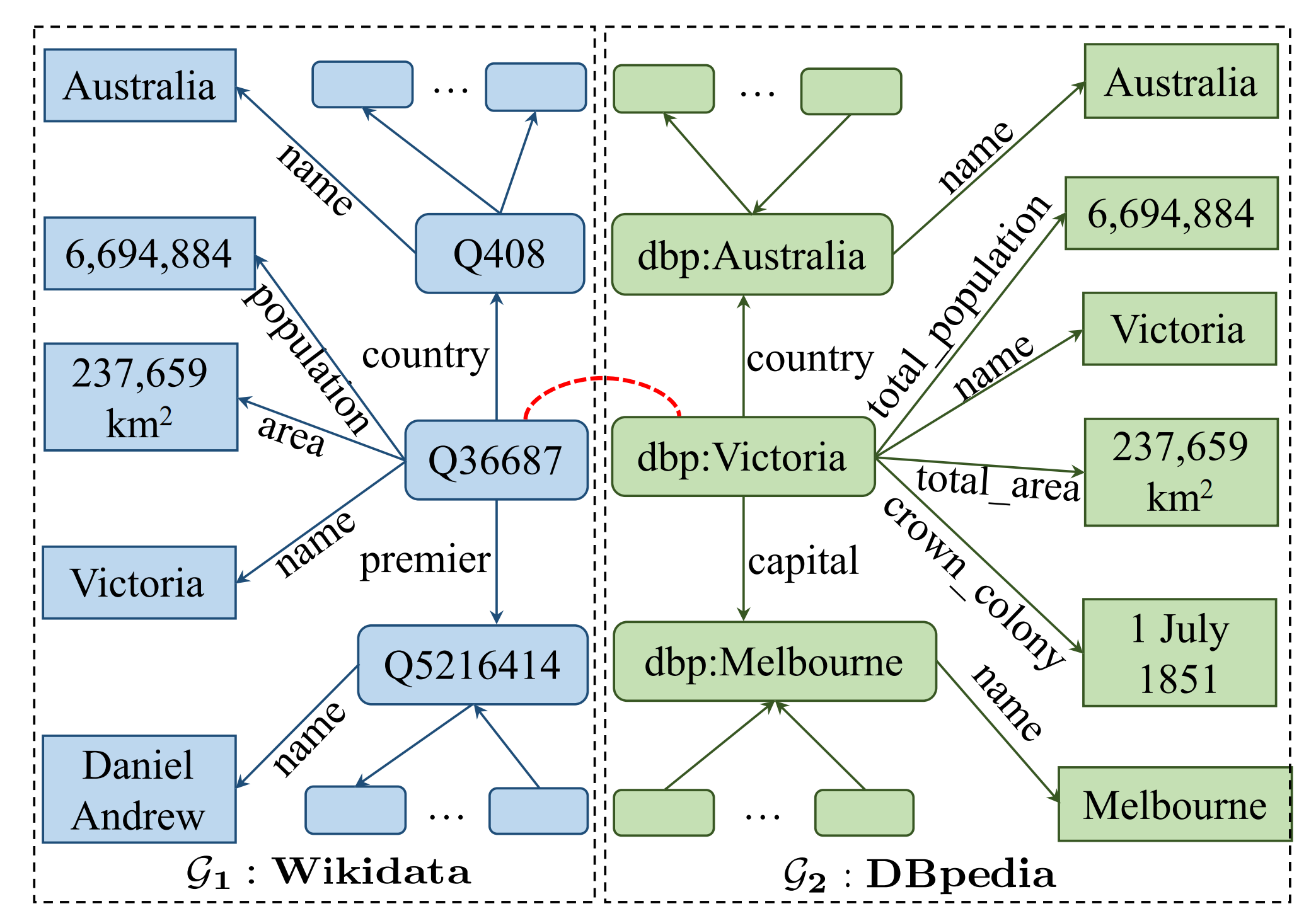
我們可以看到同一個現實物體可能會在兩個不同知識圖譜中都有其表示(比如\(\text{Q36687}\)和\(\text{dbp:Victoria}\)),這兩個知識圖譜擁有關于這個現實物件互補的資訊,\(\mathcal{G}_1\)知識圖譜擁有關于其總理的資訊,\(\mathcal{G}_2\)擁有其首都的資訊,
如果我們能夠確定\(\mathcal{G}_1\)中的\(\text{Q36687}\)和\(\mathcal{G}_2\)中的\(\text{dbp:Victoria}\)指的是同一個現實世界的物體(也即\(\text{Q36687}\)和\(\text{dbp:Victoria}\)是對齊的物體),那么我們所獲取的關于該物體的資訊就可以大大增加,所謂\(\mathcal{G}_1\)和\(\mathcal{G}_2\) 之間的物體對齊任務即尋找這兩個知識圖譜中的所有對齊物體,在這個例子里,這里有兩個對齊的物體\(\langle \text{Q36687, dbp:Victoria}\rangle\)和$ \langle Q408, dbp:Australia \rangle$,
形式化的說,我們將知識圖譜表示為\(\mathcal{G}=(\mathcal{E}, \mathcal{R}, \mathcal{T} )\)(為了簡單起見,本文暫不考慮屬性謂詞),給定兩個知識圖譜\(\mathcal{G}_1=(\mathcal{E}_1,\mathcal{R}_1,\mathcal{T}_1)\)和\(\mathcal{G}_2=(\mathcal{E}_2,\mathcal{R}_2,\mathcal{T}_2)\),知識圖譜對齊任務的目標為識別出所有的對齊物體對\((e_1,e_2), e_1\in \mathcal{E}_1, e_2\in\mathcal{E_2}\),這里\(e_1\)和\(e_2\)表示的是同一個真實世界的物體(即\(e_1\)和\(e_2\)是對齊的物體),
一些過于傳統的知識圖譜物體對齊方法(如基于相似度的方法)我們就不再敘述了,目前主流的都是基于embedding的知識圖譜物體對齊方法,基于embedding的知識圖譜物體對齊框架如下:
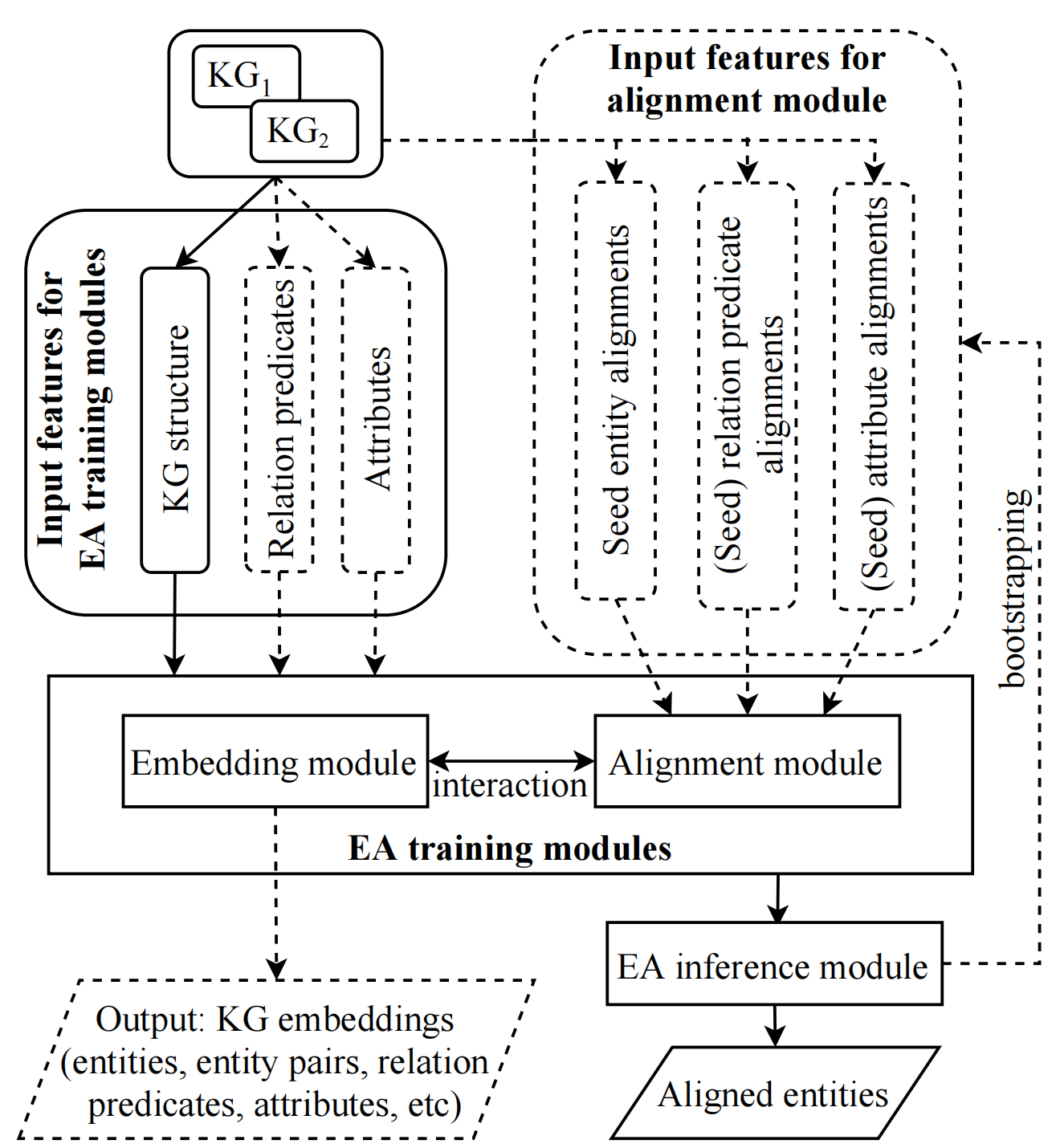
可見基于embedding的知識圖譜物體對齊框架由三個部分組成:embedding模塊,alignment模塊,inference模塊,embedding模塊和對齊模塊可能會交替或共同訓練,這兩個模塊一起構成了知識圖譜物體對齊中的training模塊,
知識圖譜embedding模塊負責學習物體和關系的表征(常常是低維的),也即它們的embeddings,常常會利用到一下四種資訊:知識圖譜的結構(即原始知識圖譜資料中的關系元組),關系謂詞,屬性謂詞和數性值(屬性謂詞和屬性值本文暫不討論),而其嵌入方法包括基于平移的(translation-based)和基于GNN的(GNN-based),這塊大家可以去閱讀知識圖譜嵌入的入門資料,此處不再贅述,
下面我們來看alignment模塊,由于embedding模塊獨立地學習知識圖譜的emebddings,這使得\(\mathcal{G}_1\)和\(\mathcal{G}_2\)的embeddings落入到不同的向量空間中,而alignment模塊旨在將兩個知識圖譜的embeddings統一(unify)到同樣的向量空間中,這樣就能夠識別出對齊的物體了,而這個統一操作也是知識圖譜對齊最大的挑戰,
這類似于NLP中對跨語言詞向量的對齊操作,即使用一個線性變換\(W\)將不同embedding空間中的向量投影到一個統一的embedding空間中[2],
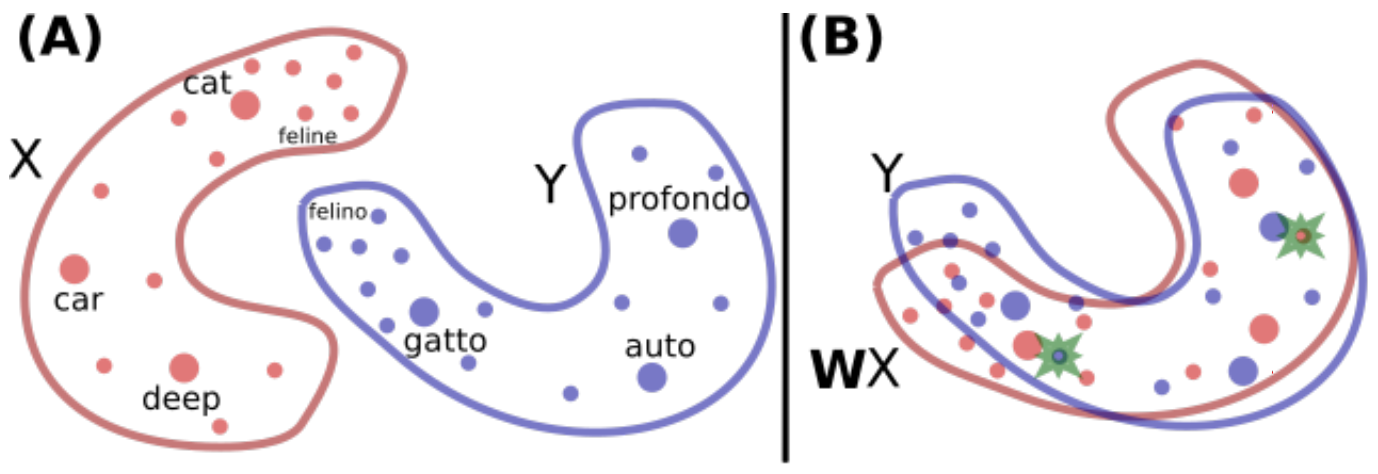
如上圖所示,(A)為兩個不同的詞向量分布,紅色的英語單詞由\(X\)表示,藍色的意大利單詞由\(Y\)表示,我們想要進行翻譯/對齊(在意大利語里面,gatto意為“cat”,profondo意為“deep”,felino意為“feline”,“auto”意為“car”),每一個點代表詞向量空間中的一個單詞,點的大小和單詞在訓練語料中出現的頻率成正比,(B)意為學習一個旋轉矩陣\(W\)將兩個分布大致地對齊,
在知識圖譜對齊的程序中經常會使用一個手工對齊好的物體或關系謂詞集合做為引子,我們把這個叫做種子對齊集合(seed alignments),種子對齊集合將會被做為輸入特征來訓練alignment模塊,最常用的方法就是使用一個對齊好的物體集合來做種子\( \mathcal{S}=\left\{\left(e_1, e_2\right) \mid e_1 \in \mathcal{E}_1, e_2 \in \mathcal{E}_2, e_1 \equiv e_2\right\} \),這個種子集合由物體對\((e_1, e_2)\)組成,這里\(e_1\)是\(\mathcal{E}_1\)中的物體,\(e_2\)是\(\mathcal{E}_2\)中的物體,種子集合被用來計算alignment模塊的損失函式以學習一個統一的向量空間,然后我們就能夠識別出更多潛在的對齊物體,一個典型的損失函式可以被定義如下的Hinge loss形式:
\[\mathcal{L}=\sum_{\left(e_1, e_2\right) \in \mathcal{S}} \sum_{\left(e_1^{\prime}, e_2^{\prime}\right) \in \mathcal{S}^{\prime}} \max \left(0,\left[\gamma+f_{\mathrm{align}}\left(\boldsymbol{e}_1, \boldsymbol{e}_2\right)-f_{\mathrm{align}}\left(\boldsymbol{e}_1^{\prime}, \boldsymbol{e}_2^{\prime}\right)\right]\right) \]這里\(\gamma\)是間隔超引數,上面的損失函式被設計來最小化種子對齊集合\(\mathcal{S}\)中物體間的距離,最大化負例集合\(\mathcal{S}'\)中物體對\((e_1', e_2,')\)的距離,這里的負樣本生成的手段為將種子物體對中的一個物體替換為隨機物體,這里,物體對間的距離由\(f_{\text{align}}\)計算,這個函式被稱為alignment score function,
若按照所要對齊的知識圖譜的型別劃分,則可包括跨語言知識圖譜[3][4][5][6]、多視角物體相關資訊知識圖譜[7][8],和相似領域且存在資訊重疊的知識圖譜[9][10],
若按照對齊策略來劃分,則我們能夠將基于embedding的對齊方法進一步細分為基于平移(translation)的和基于GNN的兩類,這篇文章我們只介紹基于平移的,基于GNN的我們留在下一篇文章介紹,
2 基于平移(translation)的方法
2.1 MTransE
論文[3]是第一個被提出的基于平移的物體對齊模型,它的embedding模塊使用TransE將各個知識圖譜的物體與關系謂詞嵌入不同的embedding空間后,為了使這些embeddings都落入到一個統一的(unfied)空間,它的對齊模塊會最小化下列的alignment score function(對所有的種子元組集合)來進行物體與關系的對齊:
\[\mathcal{L}=\sum_{(tr_1, tr_2)\in S_t} f_{\text{align}}\left(t r_1, t r_2\right) \]這里\(\mathcal{S}_t\)是來自\(\mathcal{G}_1\)和\(\mathcal{G}_2\)的種子元組集合(注意不同于之前的種子物體集合,除了物體之外還包括關系謂詞),\(f_{\text{align}}(tr_1,tr_2)\)是alignment score function,注意,不同于我們在前面的第一部分的知識圖譜對齊框架只計算物體的相似程度, 我們前面提到的alignment score function計算兩個元組\(tr_1(h_1, r_1, t_1)\in \mathcal{G}_1\) 和\(tr_2(h_1,r_1,t_1)\in \mathcal{G}_2\)的相似程度,為了計算align score,MTranseE有三種策略來進行跨知識圖譜轉換(cross-KG transition),包括基于距離的軸校準(distance-based axis calibration)和線性變換等,根據作者的實驗,基于線性變換的策略具有最佳的表現,該策略學習了一個從\(\mathcal{G}_1\)到\(\mathcal{G}_2\)的emebdding空間的線性變換,使用下列的score function:
\[\begin{aligned} f_{\operatorname{align}}\left(t r_1, t r_2\right)=&\left\|\boldsymbol{M}_{i j}^e \boldsymbol{h}_1-\boldsymbol{h}_2\right\|+\\ &\left\|\boldsymbol{M}_{i j}^r \boldsymbol{r}_1-\boldsymbol{r}_2\right\|+\left\|\boldsymbol{M}_{i j}^e \boldsymbol{t}_1-\boldsymbol{t}_2\right\| \end{aligned} \]這里\(\boldsymbol{M}_{i j}^e\)和\(\boldsymbol{M}_{i j}^r\)分別為作用于物體和關系embeddings的線性變換,最小化\(f_{\text{align}}\)會最小化變換之后的\(\mathcal{G}_1\)的物體/關系謂詞和\(\mathcal{G}_2\)的物體/關系謂詞之間的距離,使這兩個知識圖譜的embeddings落入到同一個向量空間,
2.2 IPTransE
在embedding模塊,IPTransE[10]首先用TransE的擴展PtransE獨立學習了\(\mathcal{G}_1\)和\(\mathcal{G}_2\)的embeddings,PTransE不同于TransE,它能夠考慮物體之間的路徑,從而對間接連接的物體建模(這里的路徑由在它們之間形成平移的關系謂詞決定),
在alignment模塊, IPTranseE也使用了多種策略完成在\(\mathcal{G}_1\)到\(\mathcal{G}_2\)的轉換,包括基于平移的,基于線性變換的和基于引數共享的,
基于平移的策略將平移的思想引入跨知識圖譜對齊領域,它將對齊視為一個來自\(\mathcal{G}_1\)的種子物體集合\(\mathcal{E}_1\)和來自\(\mathcal{G}_2\)的種子物體集合\(\mathcal{E}_2\)之間的特殊的關系謂詞\(r^{(\varepsilon_1\rightarrow \epsilon_2 )}\),關于種子物體的alignment score function定義如下:
這里\(\bm{e}_1\)和\(\bm{e}_2\)是物體\(e_1\in\mathcal{E}_1\)和\(\mathcal{e}_2\in\mathcal{E}_2\)的emebddings,目標函式則是嵌入模塊PTransE的損失函式和對齊模塊的損失函式\(f_{\text{align}}\)的加權和,
而基于線性變換的策略則學習一個變換矩陣\(M^{\left(\mathcal{E}_1 \rightarrow \mathcal{E}_2\right)}\),該矩陣使兩個對齊物體互相接近,其采用的alignment score function如下所示:
\[f_{\text {align }}\left(e_1, e_2\right)=\left\|\boldsymbol{M}^{\left(\mathcal{E}_1 \rightarrow \mathcal{E}_2\right)} \bm{e}_1-\boldsymbol{e}_2\right\| \]而引數共享策略會迫使\(\bm{e}_1 = \bm{e}_2\),這表示對齊的物體共享相同的embeddings,因此在兩個種子物體上計算\(f_{\text{align}}\)總是得到0,此時目標函式可以規約到PTranE的損失函式,共享策略展示了在三種策略中最佳的emebdding聯合學習效果,
在訓練程序中,IPTransE采用了bootstraping策略并有一軟一硬兩種策略來將新對齊的物體添加到種子對齊集合,在硬策略中(也是通常所使用的),將最新對齊的物體被直接加入到種子對齊集合中,而這可能導致錯誤的傳播;在軟策略中,新對齊的物體會被分配一個置信分數來緩解錯誤傳播,這里的置信分數對應對齊物體之間的embedding距離,它將會做為損失項添加到目標函式中,
2.3 BootEA
BootEA[9]方法將物體對齊建模為一對一的分類問題,物體所關聯到的另一個物體被視為其標簽,它會從有標簽資料(seed entity alignments)和無標簽資料(predicated aligned entities)進行bootstrapping采樣迭代地學習分類器,它的embedding模塊采用TransE中的score function,此處不再贅述,不過不同于傳統的知識圖譜對齊方法,它的alignment模塊是一個一對一的分類器,該模塊使用在\(\mathcal{G}_1\)的物體分布和\(\mathcal{G}_2\)的預測類分布(即對齊物體)之間的交叉熵損失函式,所有在種子物體集合\(S\)中的物體對\(e_1\)、\(e_2\)會被代入到下列等式中計算交叉熵損失:
\[\mathcal{L}_a=-\sum_{e_1 \in \mathcal{E}_1} \sum_{e_2 \in \mathcal{E}_2} \phi_{e_1}\left(e_2\right) \log \pi\left(e_2 \mid e_1\right) \]合理\(\phi_{e_1}(\cdot)\)是一個計算\(e_1\)標簽分布的函式,如果\(e_1\)被標注為\(e_2\),標簽分布\(\phi_{e_1}(\cdot)\)會將其所有概率質量聚集到\(e_2\),即\(\phi_{e_1}{(e_2)}=1\),如果\(e_1\)沒有被標注,則\(\phi_{e_1}(\cdot)\) 是均勻分布,\(\pi(\cdot)\) 是一個給定\(e_1\in \mathcal{E}_1\),從\(\mathcal{E}_2\)中預測對齊物體的分類器,BootEA的整體損失函式\(\mathcal{E} = \mathcal{L}_e + \beta_2\mathcal{L}_a\),這里\(\beta_2\)是一個平衡超引數,\(\mathcal{L}_e\)是embedding模塊的損失,
2.4 NAEA
NAEA[5]也將物體對齊形式化為了一個一對一分類問題,但是將基于平移的范式和基于GAT(Graph Attention Network, 圖注意力網路)的范式進行了結合,具體來說,NAEA除了關系層次的資訊之外還嵌入了鄰居層次的資訊,其鄰居資訊的嵌入是通過attention機制對其鄰居的emebddings進行聚合來完成的,這里將其物體\(w\)在鄰居層次的表征和在關系層面的表征分別記為\(\text{Ne}(e)\)和\(\text{Nr}(r)\),其alignment模塊和NAEA類似,也使用了\(\mathcal{G}_1\)物體分布和\(\mathcal{G}_2\)物體分布之間的交叉熵損失,如下圖所示:
\[\mathcal{L}_a=-\sum_{e_i \in \mathcal{E}_1} \sum_{e_j \in \mathcal{E}_2} \phi_{e_1}\left(e_2\right) \log \pi\left(e_j \mid e_i\right) \]這里\(\phi_{e_1}(e_2)\)和BootEA相似,不同之處在于其分類器\(\pi(e_j \vert e_i)\)定義如下:
\[\begin{aligned} \pi\left(e_j \mid e_i\right)=& \beta_3 \sigma\left(\operatorname{sim}\left(\operatorname{Ne}\left(e_i\right), \operatorname{Ne}\left(e_j\right)\right)\right) \\ &+\left(1-\beta_3\right) \sigma\left(\operatorname{sim}\left(\mathbf{e}_i, \mathbf{e}_j\right)\right) \end{aligned} \]這里\(\text{sim}(\cdot)\)是余弦相似度,\(\beta_3\)是一個平衡超引數,
2.5 TransEdge
TransEdge[11]為了解決TransE的缺點,在embedding模塊中提出了考慮了關系環境(關系的頭節點和尾節點)的平移嵌入模型,舉個例子,
\(\text{director}\)在\((\text{Steve Jobs}, \text{director}, \text{Apple})\)和\((\text{James Cameron}, \text{director}, \text{Avator})\) 這兩個不同的關系元組中就擁有不同的含義,因此考慮關系的環境資訊是值得的,這個模型將關系謂詞的環境embebddings(文章中稱之為edge embeddings)視為頭物體到尾物體的平移,
它的alignment模塊使用引數共享策略來統一兩個不同的知識圖譜,也即迫使在種子物體集合中的物體對擁有同樣的embedding,TransEdge使用bootstrapping策略迭代地選擇可能對齊的新物體加入(表示為\( \mathcal{D}=\left\{\left(e_1, e_2\right) \in \mathcal{E}_1 \times \mathcal{E}_2 \mid \cos \left(\mathbf{e}_1, \mathbf{e}_2\right)>s\right\} \), \(s\)為相似度閾值),但由于可能產生錯誤,故在每輪迭代中新加入的對齊物體并沒有使用引數共享處理,為了使新對齊的物體在emebdding空間中更接近,論文添加了一個基于新對齊物體集合\(\mathcal{D}\)中的emebdding距離的損失項:
\[\mathcal{L}=\sum_{\left(e_1, e_2\right) \in \mathcal{D}}\left\|\boldsymbol{e}_1-\boldsymbol{e}_2\right\| \]參考
[1] Zhang R, Trisedya B D, Li M, et al. A benchmark and comprehensive survey on knowledge graph entity alignment via representation learning[J]. The VLDB Journal, 2022: 1-26.
[2] Alexis Conneau, Guillaume Lample, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. 2018. Word Translation Without Parallel Data. Proceedings of ICLR.
[3] Muhao Chen, Yingtao Tian, Mohan Yang, and Carlo Zaniolo. 2017. Multilingual Knowledge Graph Embeddings for Cross-lingual Knowledge Alignment. In Proceedings of IJCAI. 1511–1517.
[4] Wu Y, Liu X, Feng Y, Wang Z, Yan R, Zhao D (2019a) Relation-aware entity alignment for heterogeneous knowledge graphs. In: IJCAI 2019
[5] Zhu Q, Zhou X, Wu J, et al. Neighborhood-Aware Attentional Representation for Multilingual Knowledge Graphs[C]//IJCAI 2019: 1943-1949.
[6] Pei S, Yu L, Yu G, et al. Rea: Robust cross-lingual entity alignment between knowledge graphs[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 2175-2184.
[7] Cao Y, Liu Z, Li C, Liu Z, Li J, Chua TS (2019) Multi-channel graph neural network for entity alignment. In: ACL 2019
[8] Qingheng Zhang, Zequn Sun, Wei Hu, Muhao Chen, Lingbing Guo, and Yuzhong Qu. 2019. Multi-view knowledge graph embedding for entity alignment. In Proceedings of IJCAI. AAAI Press, 5429–5435.
[9] (2018) Bootstrapping entity alignment with knowledge graph embedding. In: IJCAI 2018
[10] Zhu H, Xie R, Liu Z, et al. Iterative entity alignment via knowledge embeddings[C]//Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI). 2017.
[11] Sun Z, Huang J, Hu W, et al. Transedge: Translating relation-contextualized embeddings for knowledge graphs[C]//International Semantic Web Conference. Springer, Cham, 2019: 612-629.
數學是符號的藝術,音樂是上界的語言,轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/510715.html
標籤:其他