Zookeeper 選舉機制
1)半數機制:集群中半數以上機器存活,集群可用,所以Zookeeper適合安裝奇數臺服務器,
2)Zookeeper雖然在組態檔中并沒有指定Master和Slave,但是,Zookeeper作業時,是有一個節點為Leader,其他則為Follower,Leader是通過內部的選舉機制臨時產生的,
3)以一個簡單的例子來說明整個選舉的程序,
假設有五臺服務器組成的Zookeeper集群,它們的id從1-5,同時它們都是最新啟動的,也就是沒有歷史資料,在存放資料量這一點上,都是一樣的,如圖所示:
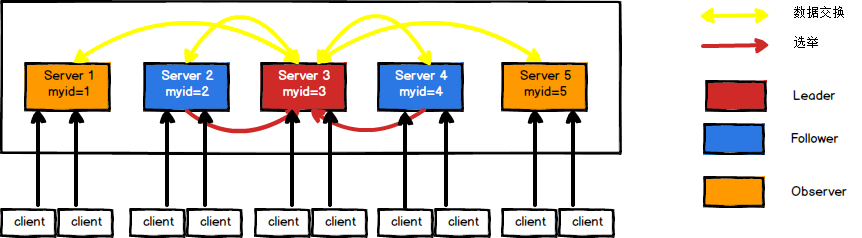
(1)服務器1啟動,此時只有它一臺服務器啟動了,它發出去的報文沒有任何回應,所以它的選舉狀態一直是LOOKING狀態,
(2)服務器2啟動,它與最開始啟動的服務器1進行通信,互相交換自己的選舉結果,由于兩者都沒有歷史資料,所以id值較大的服務器2勝出,但是由于沒有達到超過半數以上的服務器都同意選舉它(這個例子中的半數以上是3),所以服務器1、2還是繼續保持LOOKING狀態,
(3)服務器3啟動,根據前面的理論分析,服務器3成為服務器1、2、3中的老大,而與上面不同的是,此時有三臺服務器選舉了它,所以它成為了這次選舉的Leader,
(4)服務器4啟動,根據前面的分析,理論上服務器4應該是服務器1、2、3、4中最大的,但是由于前面已經有半數以上的服務器選舉了服務器3,所以它只能接收當小弟的命了,
(5)服務器5啟動,同4一樣當小弟,
Zookeeper 的監聽原理是什么
- 首先要有一個 main() 執行緒;
- 在 main() 執行緒中創建 Zookeeper 客戶端,這時就會創建兩個執行緒,一個負責 網路連接通信(connet) , 一個負責監聽(listener) .
- 通過 connet 執行緒將注冊的監聽事件發送給 Zookeeper.
- 在 Zookeeper 的注冊監聽器串列中將注冊的監聽事件添加到串列中 .
- Zookeeper 監聽到有資料或路徑變化,就會將這個訊息發送到 listener 執行緒 .
- listener 執行緒內部呼叫了 process() 方法 .
ZooKeeper的部署方式有哪幾種?集群中的角色有哪些?集群最少需要幾臺機器?
(1)部署方式單機模式、集群模式
(2)角色:Leader和Follower
(3)集群最少需要機器數:3
Paxos演算法(擴展)
這個很少有公司會問到
Paxos演算法一種基于訊息傳遞且具有高度容錯特性的一致性演算法,
分布式系統中的節點通信存在兩種模型:共享記憶體(Shared memory)和訊息傳遞(Messages passing),基于訊息傳遞通信模型的分布式系統,不可避免的會發生以下錯誤:行程可能會慢、被殺死或者重啟,訊息可能會延遲、丟失、重復,在基礎 Paxos 場景中,先不考慮可能出現訊息篡改即拜占庭錯誤的情況,Paxos 演算法解決的問題是在一個可能發生上述例外的分布式系統中如何就某個值達成一致,保證不論發生以上任何例外,都不會破壞決議的一致性,
講一講什么是CAP法則?Zookeeper符合了這個法則的哪兩個?(擴展)
CAP法則:強一致性、高可用性、磁區容錯性;
Zookeeper符合強一致性、高可用性!
本文由博客群發一文多發等運營工具平臺 OpenWrite 發布
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/5110.html
標籤:其他
上一篇:DRY原則的一個簡單實踐