這一章我們來嘮嘮如何優化BERT對文本長度的限制,BERT使用的Transformer結構核心在于注意力機制強大的互動和記憶能力,不過Attention本身O(n^2)的計算和記憶體復雜度,也限制了Transformer在長文本中的應用,
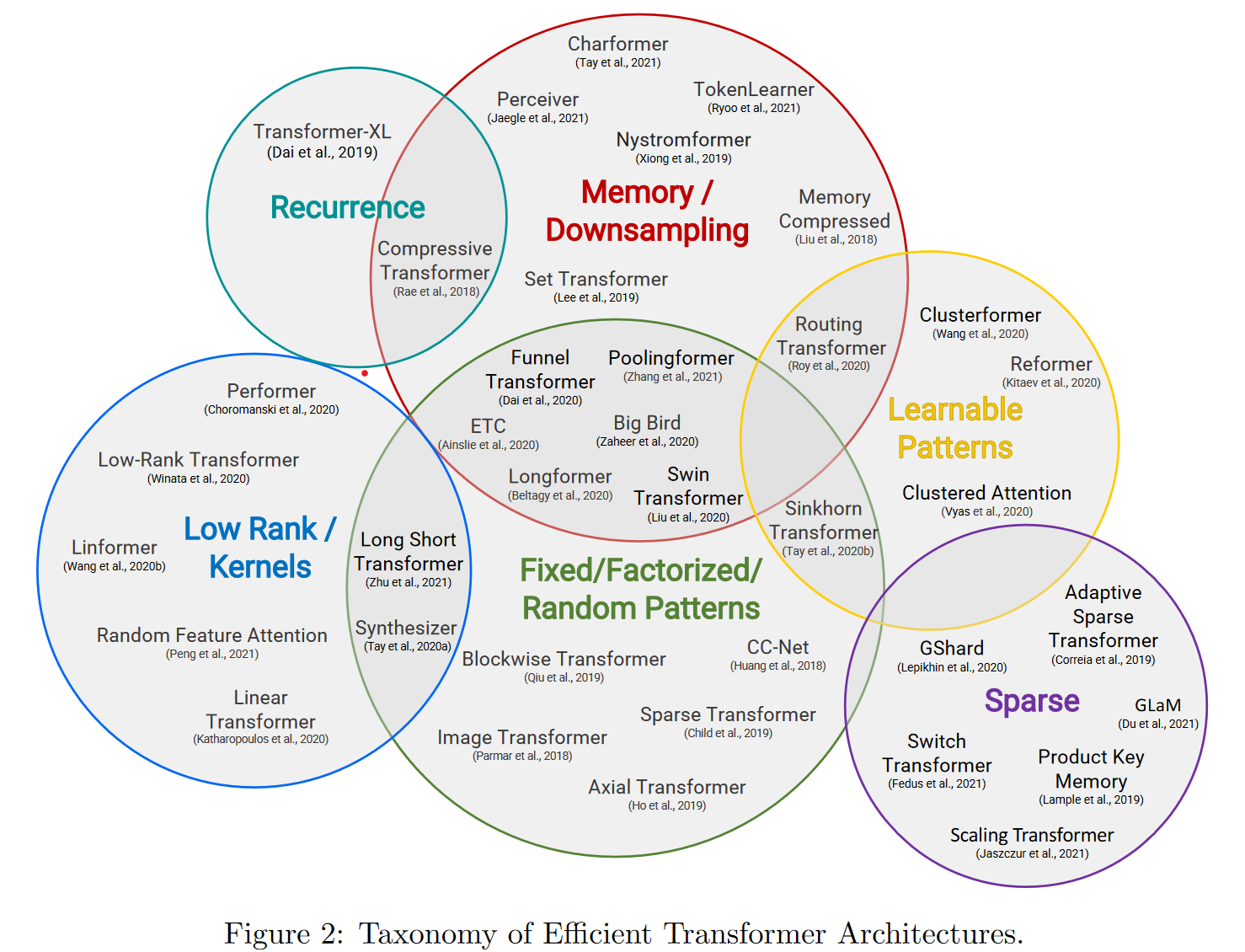
之前對長檔案的一些處理方案多是暴力截斷,或者分段得到文本表征后再進行融合,這一章我們看下如何通過優化attention的計算方式,降低記憶體/計算復雜度,實作長文本建模,Google出品的Efficient Transformers: A Survey里面對更高效的Transformer魔改進行了分類,這一章我們主要介紹以下5個方向:
- 以Transformer-XL為首的片段遞回
- Longformer等通過稀疏注意力,降低記憶體使用方案
- Performer等通過矩陣分解,降低attention內積計算復雜度的低秩方案
- Reformer等可學習pattern的注意力方案
- Bigbird等固定pattern注意力機制
Transformer-xl
- paper: Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
- github:https://github.com/kimiyoung/transformer-xl
- Take Away: 相對位置編碼 + 片段遞回機制
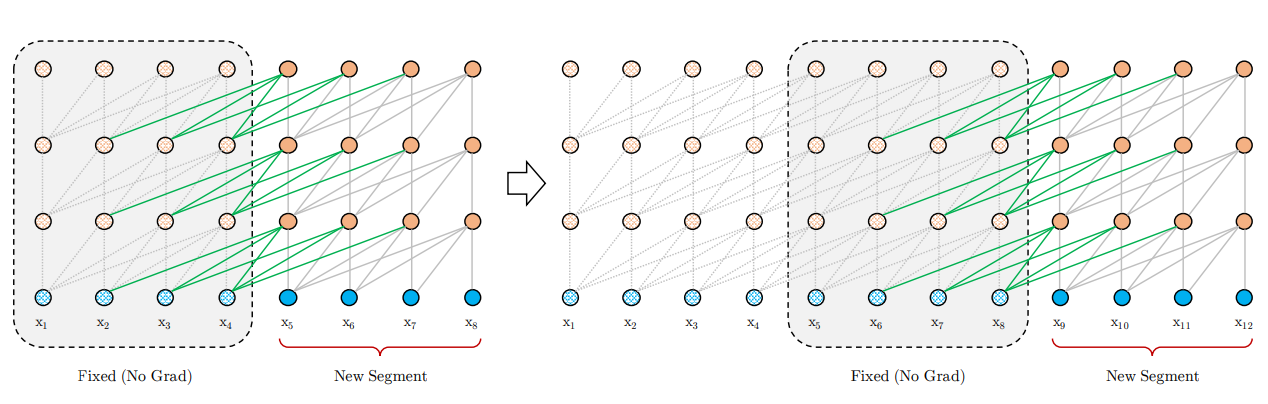
為了突破Transformer對固定長度建模的限制,Transformer-xl提出了相對位置編碼和片段遞回的方案,后續也被XLNET沿用~
- 片段遞回
片段遞回的思路其實很早就有,不過之前的方案多是保留上一個片段的last hidden state,作為當前片段的補充資訊,而Transformer-xl則是直接保留并cache了上個片段的所有hidden state,和當前片段進行拼接,梯度更新時只更新當前片段的隱藏層,
具體的Attentenion計算中如下,\(\tau\)是片段,\(n\)是hidden layer,\(\circ\)是向量拼接,\(SG()\)是不進行梯度更新的意思,于是當前片段Q,K,V是由上個片段的隱藏層和當前片段的隱藏層拼接得到,每個片段完成計算后會把隱藏層計算結果進行存盤,用于下個片段的計算,用空間換時間,既避免了重復計算,又使得新的片段能保留大部分的歷史片段資訊,這里的歷史片段資訊并不一定只使用T-1,理論上在記憶體允許的情況下可以拼接更多歷史片段~
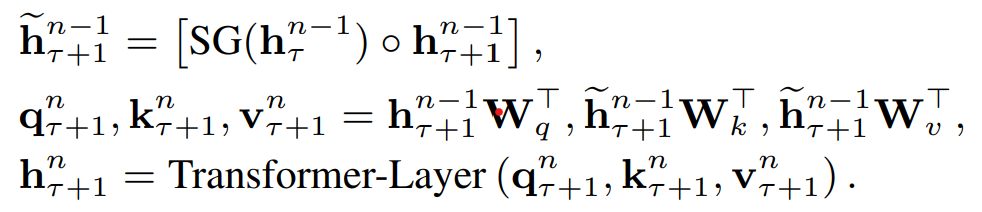
- 相對位置編碼
片段遞回如果和絕對位置編碼一起使用會存在問題,因為不同片段相同位置的
絕對位置編碼相同,模型無法區分它們來自不同的片段,因此作者提出了相對位置編碼,之前在討論絕對位置編碼不適用于NER任務時有分析過相對位置編碼>>中文NER的那些事兒5. Transformer相對位置編碼&TENER代碼實作,這里我們再回顧下~
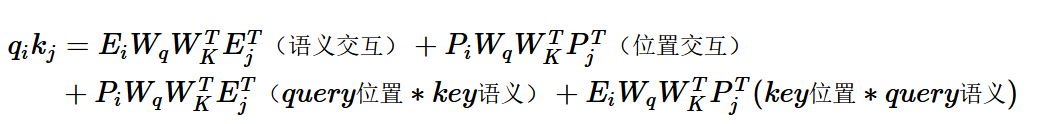
絕對位置編碼是直接加到詞向量上,在Attention計算中進行互動,把內積展開可以得到如上形式,包括4個部分:Query和Key的純語意互動,各自的位置資訊和語意的互動,以及反映相對距離的位置互動,
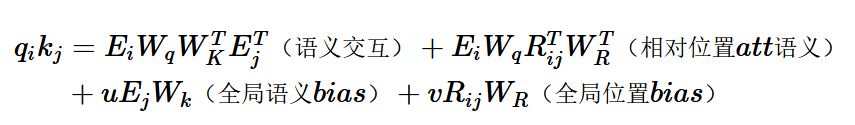
Transformer-XL的相對位置編碼和以上的展開形式基本一一對應,也使用了三角函式的編碼方式,只需要兩點調整
- key對應的絕對位置編碼\(p_j\)替換為兩個token相對位置i-j的相對位置編碼\(R_{i,j}\)
- query的位置編碼\(P_iW_q\)替換成兩個learnable的引數u和v
和以上絕對位置編碼的Attention計算對比:
- 語意互動不變
- 位置互動:絕對位置編碼內積替換為相對位置編碼對應的全域位置偏置, 在表征距離的同時加入了方向資訊
- query位置*key語意:因為互動是計算一個query token對全部key token的attention,所以這里的位置編碼部分是個常量,作者替換為了trainable的引數u,于是這部分有了更明確的含義就是key對應的全域語意偏置
- query語意*key位置: 替換為query語意 * query和key的相對位置編碼,也就是語意和位置互動
結合片段遞回和相對位置編碼,Transformer-xl突破了Transformer對固定文本長度的限制,同時片段遞回和以下4種Transformer優化方案是正交的關系,可以在以下的四種方案中疊加使用片段遞回去優化長文本建模
Longformer
- paper: Longformer: The Long-Document Transformer
- github:https://github.com/allenai/longformer
- 中文預訓練模型:https://github.com/SCHENLIU/longformer-chinese
- Take Away: 滑動視窗稀疏注意力機制
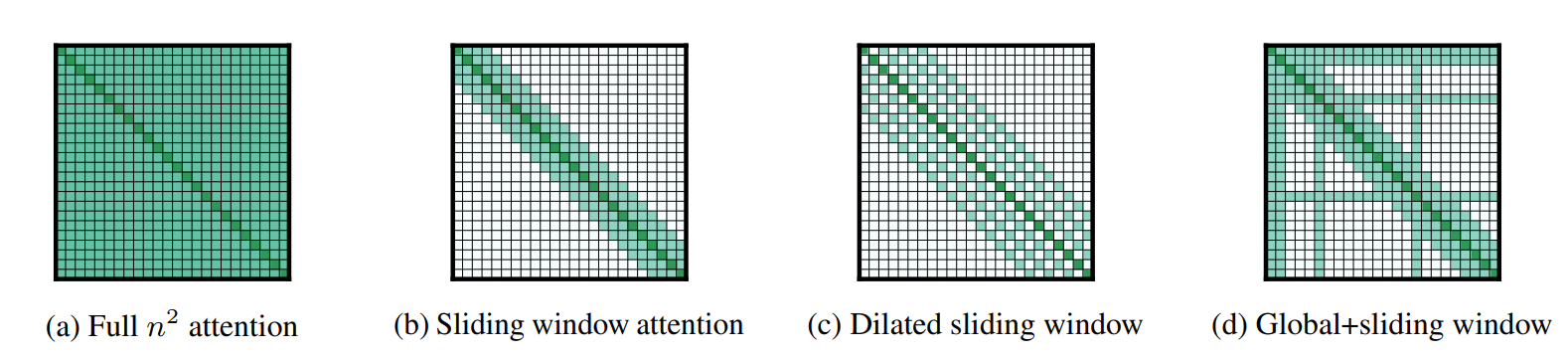
Longformer的3點主要創新是
- 滑動視窗attention(圖b)
解決attention計算復雜度最簡單直觀的方案,就是把原本all-2-all的attention計算限制到適當的window size(w)內,這樣對于長度為n的序列,原本O(n^2)的復雜度就縮減到了O(n*w),因為attention本質是引入當前token的背景關系資訊,但token其實很難和八丈遠外的內容進行互動,所以合理的視窗選擇并不會損失太多的資訊,并且和stack-cnn相同更高的layer會擁有更大的感知野,Longformer這里選擇了512作為視窗大小,attention的復雜度和BERT相同,
- 空洞滑窗attention(圖C)
和Dilated-CNN相同,這里作者也采用了dilation來擴大相同計算量下的感知野,不過感覺這里和CNN還是有些區別,影像使用Dilation因為單一像素本身資訊有限,需要通過kernel來提取圖片區域特征,而對文本序列來說,每個token就是最小粒度的資訊元包含資訊更多,因此dilation會帶來更多的資訊損失,不過作者在使用程序中也加了一些tricks,包括對多頭的不同頭使用不同的dilation策略,以及底層layer不使用dilation保留更多資訊,更高層使用更大的dilation擴大感知野,不過在后面的消融實驗中空洞滑窗的效果提升并不十分顯著,
- 任務導向全域attention(圖d)
以上區域attenion在一些任務中存在不足,例如QA任務中可能問題無法和背景關系進行完整互動,以及分類任務中CLS無法獲得全部背景關系資訊,因此作者在下游任務微調中加入了針對部分token的全域attention,因此在下游微調時,需要進行全域互動的token,會用預訓練的Q,K,V進行初始化,不過會用兩套線性映射的引數分別對全域和滑動視窗的Q,K,V進行映射,
Longformer的預訓練是在Roberta的基礎上用長文本進行continue train,原始Roberta的position embedding只有512維,這里longformer把PE直接復制了8遍,得到4096維度的PE用于初始化,這樣在有效保留原始PE區域資訊的同時,也和以上512的window-size有了對應,至于longformer的效果,可以直接看和下面BigBird的對比,
Bigbird
- paper: Big Bird:Transformers for Longer Sequences
- github: https://github.com/google-research/bigbird
- Take Away: 使用補充固定token計算全域注意力
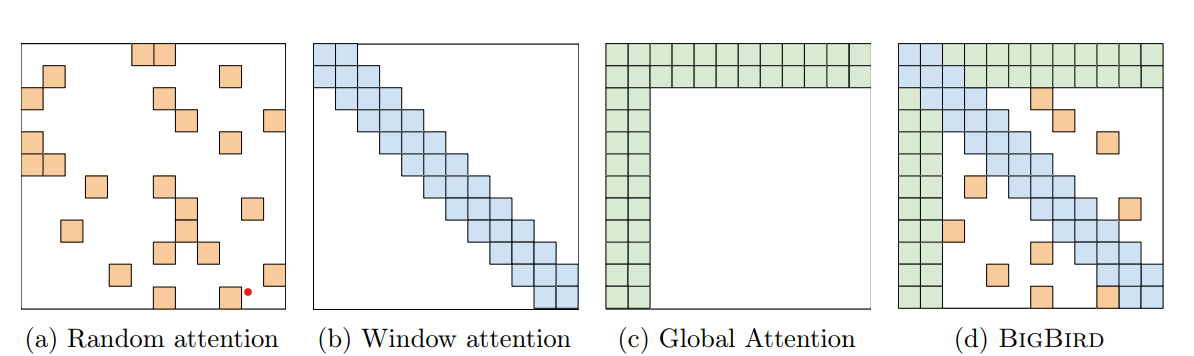
又是一個非常清新脫俗的模型起名~ 大鳥模型和longformer相比增加了隨機注意力機制,不過感覺主要的創新是對全域注意力機制進行了改良,提出了固定注意力patten的ETC全域注意力機制,
- 隨機注意力機制
在滑動視窗注意力之外,模型會每行隨機采樣r個token來進行互動,不過這里的隨機注意力并不和以下的ETC全域注意力一同使用~
- 全域注意力
只使用滑動視窗注意力+隨機注意力,作者發現效果和BERT相比還是有所損失,因此加入了全域注意力,和longformer的區別在于,Bigbird除了支持對部分已有token(一般是序列的第一個和最后一個字符)進行全域attention之外,簡稱Bigbird-ITC,還
支持加入額外token(類似CLS)來做全域注意力,簡稱Bigbird-ETC,ETC不和隨機注意力一同使用,從下游任務效果上來看ETC的效果略好于ITC+隨機注意力,效果對比基本是用的BigBird-ETC,不過這也限制了BigBird只能用在NLU場景~
整體效果,在QA和長文本摘要任務上上Bigbird基本是新SOTA
Reformer
- paper: REFORMER: THE EFFICIENT TRANSFORMER
- github: https://github.com/google/trax/tree/master/trax/models/reformer
- Take Away: LSH搜索序列中的高權重token,做固定長度區域注意力計算
先來看下原始Transformer的空間復雜度: \(max(b*l* d_{ffn}, b *n_{h} * l^2)*n_{l}\),其中b是batch,l是文本長度,\(d_{ffn}\)是Feed Forward層大小,\(n_{h}\)是多頭的head size,\(n_l\)是層數,Reformer引入了三個方案來降低Transformer的計算和記憶體復雜度
- LSH Attention:近似計算,針對l,只計算注意力中高權重的部分
- 可逆網路:時間換空間,針對\(n_l\),只存盤最后一層的引數
- 分塊計算:時間換空間,針對\(d_{ffn}\),對FFN層做分塊計算
后兩個方案和長文本無關這里我們簡單過,重點是LSH Attention部分的創新~
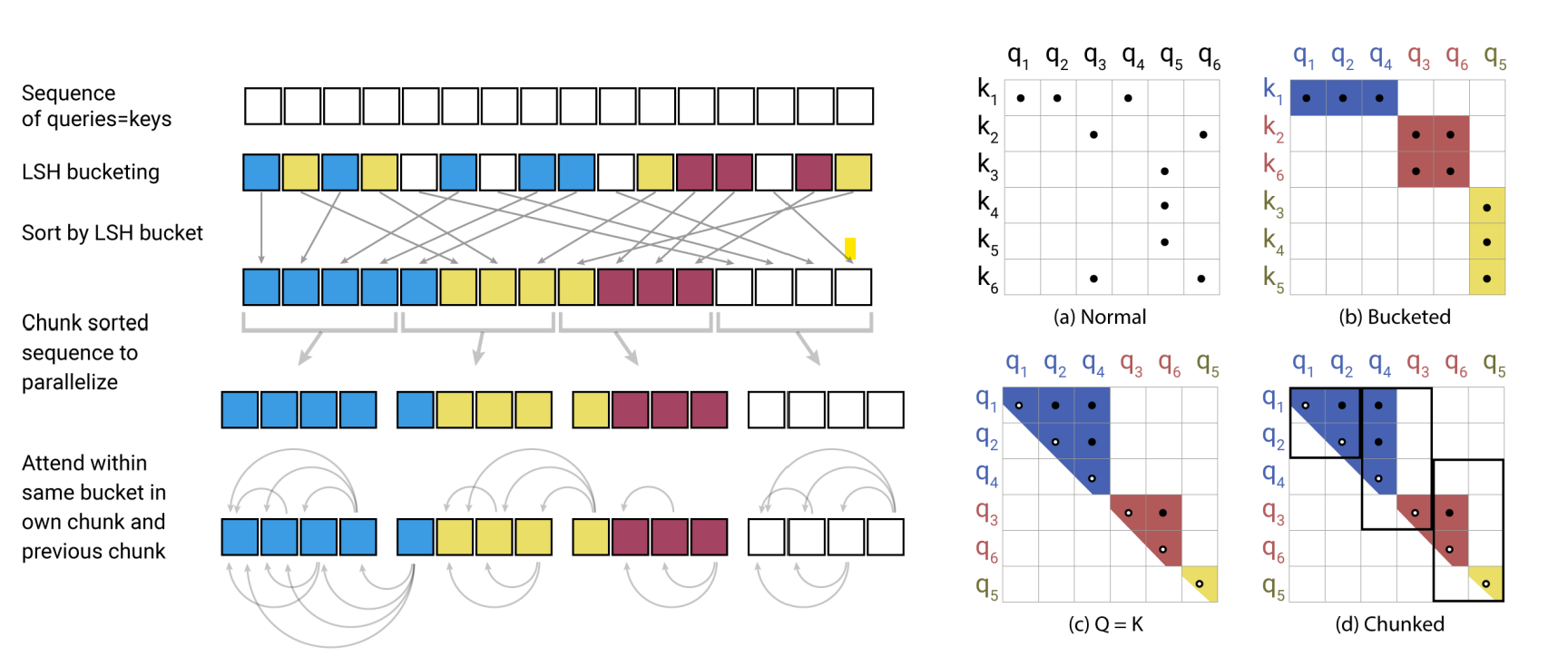
- LSH Attention
Local Sensitentive Hashing Attention是Reformer的主要貢獻,也就是最初分類中的可學習pattern注意力機制,考慮Attention的結果是被高權重的key主導的,因此每個token的注意力權重可以被部分高權重的token近似,只計算區域注意力從而避免計算\(L^2\)的注意力矩陣,難點轉換成了如何更高效的找到高權重的key,也就是和query token向量空間更相似的key token來進行區域互動,這里作者使用了LSH,一種在高維資料中快速近似查找的演算法,
LSH使用哈希函式對高位空間的向量x計算哈希函式h(x),\(h(x)\)滿足在高維空間中更近的向量有更高的概率落在相同的哈希桶中,反之在高維空間中距離更遠的向量有更低的概率會落在相同的哈希桶中,LSH有很多種演算法,這里作者使用的是基于角距離的區域敏感哈希演算法,隨機初始化向量R維度是\(d_{model} * bucket/2\),哈希結果為旋轉(xR)之后最近的一個正或者負的單位向量\(h(x) = argmax([xR;-xR])\)
使用LSH計算Attention會存在幾個問題
- query和key的hashing不同:為了解決這個問題作者把計算注意力之前query和key各自的線性映射統一成了一個,\(k_j=\frac{q_j}{||q_j||}\),這樣二者的哈希也會相同,只需要對key進行計算就得到token的哈希分桶,例如上圖(b)長度為6的序列被分成3個桶[1,2,4],[3,6],[5]
- 哈希的誤差:哈希只是使得相似的向量落入相同桶的概率更高,為了進一步提高這個概率,可以進行多次不同的哈希函式對輸出結果取交際,進一步降低近似帶來的資訊損失,也就是用更多的時間和空間來換取更好的近似效果
- 每個序列哈希分桶的大小可能不盡相同,無法進行batch計算:這里作者又做了一步近似,根據以上的哈希結果對token進行重排序,相同哈希的token放一起,桶內按原始位置排序,按固定長度m進行切分,每個chunk的query對當前chunk和前一個chunk的key計算注意,也就是位于[m,2m]的query對[0,2m]的key計算注意力,這里m和哈希桶數反向相關\(m=\frac{l}{n_{bucket}}\),也就是和平均哈希桶的大小正相關,實際上LSH只是用來排序,提高固定長度內注意力權重占整個序列的比例,從而通過有限長度的注意力矩陣近似全序列的注意力結果,同樣是固定視窗,LSH使得該視窗內的token權重會高于以上Longformer,BigBird這類完全基于位置的固定視窗的注意力機制,不過LSH的搜索和排序也會進一步提高時間復雜度
- 可逆殘差網路
可逆殘差的概念是來自The reversible residual network: Backpropagation without storing activations(Gomez2017),通過引入可逆變換,RevNet使得模型不需要存盤中間層的引數計算梯度
,每一層的引數可以由下一層通過可逆運算得到,屬于時間換空間的方案,因為反向傳播計算梯度時需要先還原本層的引數,因此時間上會增加50%左右~ 細節我們就不多展開想看math的往蘇神這看可逆ResNet:極致的暴力美學, 簡單易懂的往大師兄這看可逆殘差網路RevNet
- 分塊計算
分塊主要針對FFN層,因為Feed Forward一般會設定幾倍于Attention層的hidden size,通過先升維再降維的操作提高中間層的資訊表達能力,優化資訊的空間分布,以及抵消Relu帶來的資訊損失,但是過大的hidden size會帶來極高的空間占用,因為是在embedding維度進行變換每個位置之間的計算獨立,因此可以分塊進行計算再拼接,用時間來換空間
效果評測部分我們在下面的performer里一起討論
Performer
- paper: Rethinking Attention with Performers
- github: https://github.com/google-research/google-research/tree/master/performer
- Take Away: 提出核函式使得QK變換后的內積可以近似注意力矩陣,配合乘法結合律把復雜度從平方降低到線性
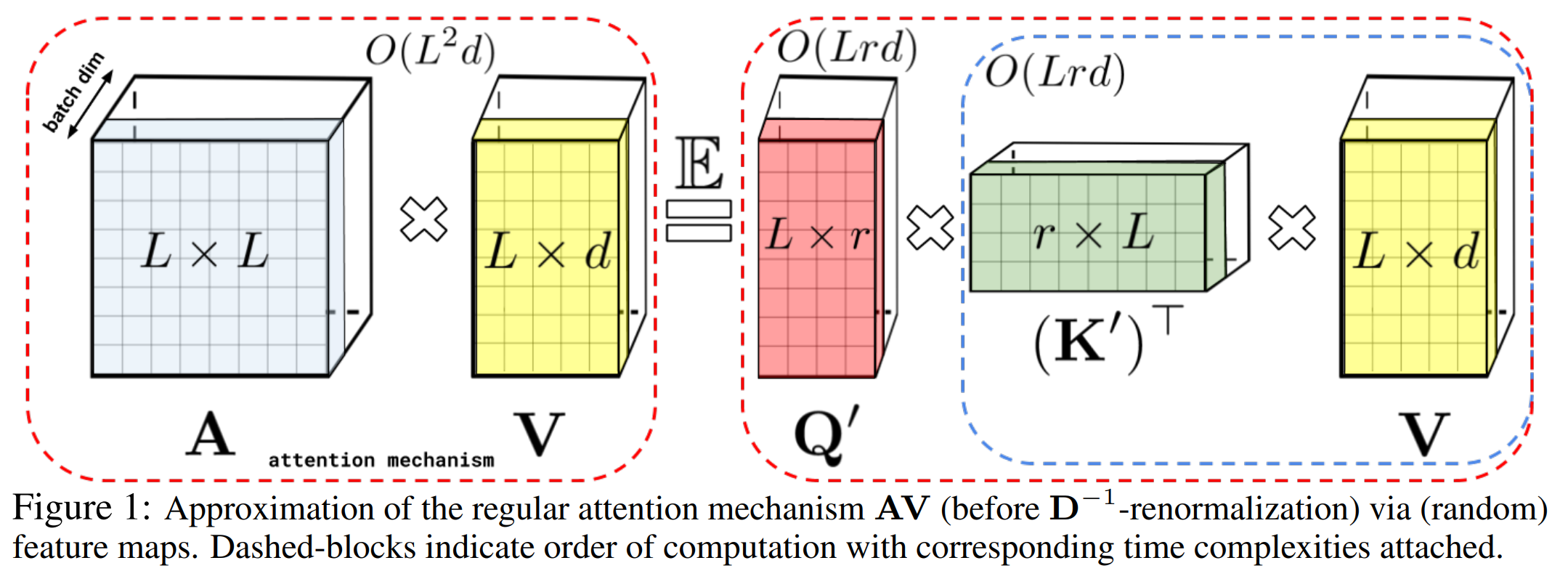
多頭注意力機制的計算是query和key先計算Attention矩陣A,再對V進行加權,也就是上圖等號左邊的計算順序,復雜度是序列長度的平方,為了避免計算\(L^2\)的注意力矩陣,作者采用矩陣分解\(q^{\prime} \in R^{L,r},k^{\prime} \in R^{L,r}\),這里r<d<<L,配合矩陣乘法的結合律,K先和V計算再和Q內積,把空間復雜度從平方級降低到線性,但是注意力矩陣過softmax之后無法直接做可逆轉換得到\(q^{\prime},k^{\prime}\), 因此作者提出了使用positive Random Feature對QK進行映射,使得映射后的矩陣\(q^{\prime},k^{\prime}\)內積可以近似Attention矩陣,簡單解釋就是以下的變換
\[softmax(QK^T)V = \phi(Q) \cdot \phi(K)^T \cdot V = \phi(Q) \cdot(\phi(K)^T \cdot V) \]所以Performer的核心在\(\phi\)核函式的設計使得映射后的QK內積可以高度近似注意力矩陣,具體設計如下
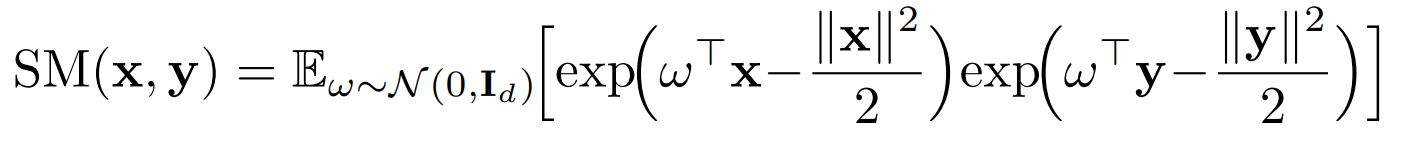
這里\(SM(x,y) = exp(x^Ty)\)也就是原,始的注意力矩陣,按照\(f(x)=exp(w^Tx-\frac{||x||^2}{2})\)對Q和K進行變換后,QK內積的期望就等于原始的注意力矩陣,不過在實際計算中只能對隨機變數w進行有限次采樣, 因此是近似原始注意力矩陣,論文有大量篇幅在進行推導和證明,這里就不做展開了,
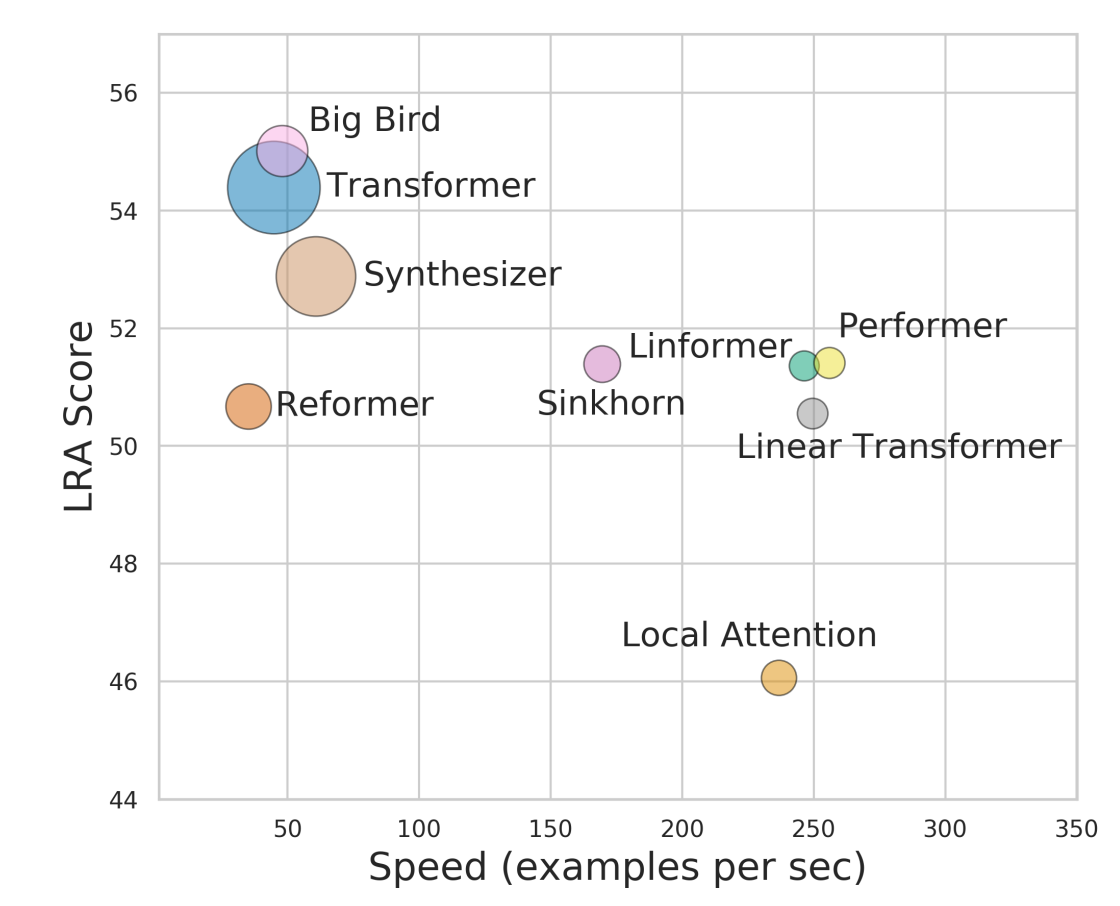
效果對比我們直接參考Google給出的效果對比,橫軸是速度,縱軸是效果(多任務平均值),點的大小是記憶體,整體上BigBird還是拔得頭籌,它并不是所有任務的SOTA但是整體效果穩定優秀,想看詳細對比結果的參考REF2~
BERT手冊相關論文和博客詳見BertManual
Reference
- Efficient Transformers: A Survey
- Long Range Arena: A Benchmark for Efficient Transformers
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/511060.html
標籤:其他
上一篇:常見的排序演算法與時間復雜度