弄了SSE指令集,必然會在不同的場合不同的人群中了解到還有更為高級的AVX指令集的存在,早些年也確實有偶爾寫點AVX的函式,但是一直沒有深入的去了解,今年十一期間也沒到那里去玩,一個人在家里抽空就折騰下這個東西,也慢慢的開始了解了這個東西,下面是基于目前的認知對這個東西進行下一個簡單的小結,有些東西也許是不正確或者不全面的,但應該無傷大雅,
第一、用AVX指令集必須做好合適的IDE配置,
如果你們有看過我之前的一些文章,應該可以看到我在部分博文中有多次提高過“使用AVX對該演算法似乎沒有什么速度和效率方面的提升”,那么現在我這里要稍微糾正一下:即如果一個演算法可以用AVX有效的寫出來,那么其效率肯定是不會比同樣思路的SSE代碼效率低,核心是需要更改一些配置,核心的是下面的配置:
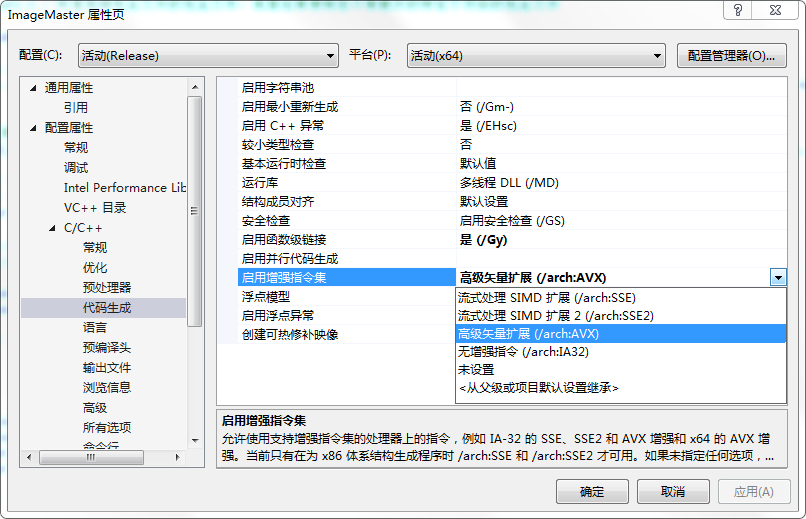
即如果你自己使用AVX的Intrinsic編碼, 那么在C/C++ ->代碼生成的啟用增強指令集里一定要選擇 高級矢量擴展(/arch:AVX)選項,或者高級版本的VS可以選擇高級矢量擴展(/arch:AVX2),
如果您沒有選擇上面的這些選項,比如選擇了流式處理SIMD擴展(SSE),那么很有可能,你使用的AVX演算法會得到效率很低的版本,我想一個核心的原因是你如果勾選了SSE,那么你在演算法里的部分代碼會被編譯器優化為SSE代碼,這樣就可能存在AVX和SSE代碼共存的情況,但是幾乎可以肯定的是,AVX <-> SSE轉換延遲是由于將傳統SSE與沒有vzeroupper的256位AVX指令混合使用引起的,而如果選擇" / arch:AVX",則編譯器可能很好照顧你自己寫的SSE代碼,他會在適當的地方加上類似于vzeroupper這樣的代碼,
第二:AVX代碼很難完全脫離SSE單獨使用,
AVX無法像SSE一樣,獨立的使用其體系內的函式完成一個獨立的功能,我們去看AVX的指令系統,其很多引數或者回傳值都有__m128,__m128i,__m128d這些SSE資料型別的影子,因此AVX必然和SSE共存,比如大量的資料型別轉換函式,提取函式等等,
第三:AVX并不是簡單的SSE的擴展,很多函式的使用方式完全不同了,
原本以為一些和SSE形態基本一樣的函式只是把128位擴展到256位,那么原來的SSE代碼只要改下回圈步長就可以了,但是實際上很多函式已經不是這樣了,
其中資料計算類、型別轉換類、資料加載保存類、數值比較類、大部分移位類基本上是直接的擴展,這些比較典型的比如 加減陳處、最大、最小、平均值、8位轉為16位,16位轉為32位、資料大小比較等等,
但是shuffle類函式、unpack拆包類、pack打包類就完蛋了,他們都是以一個128位為一個平面進行的,就相當于他們就是對2個SSE進行同樣的操作,這樣的操作初步看起來對于SSE代碼轉AVX是個災難,因為其實我們知道特別是shuffle,是SSE的精華,這樣的話,如果用到了shuffle類的函式,所有的代碼都要從演算法層次上更改,同樣的打包函式也是有類似的情況,
特別是_mm_shuffle_epi8這個函式,他其實可以代替其他所有的shuffle,因為他是以位元組為單位的,同樣_mm256_shuffle_epi8則是以高低2個128位lanes獨立操作,相互之間的shuffle互不相干,這樣導致高低位之間無法直接交流,
另外,還有一個比較特別的移位函式,也是以128位一個平面進行操作的,他們就是_mm256_srli_si256、_mm256_slli_si256 ,這也導致一些以位元組為單位的移位演算法,無法直接使用了,
第四、沒有AVX2的AVX對影像處理來說簡直是個災難,
上面說了AVX和SSE的這些不同,這些不同給影像處理帶來了很大的困惑,因為影像的資料基本都是以位元組為單位的,而且很多計算都是以整形為基礎的,在AVX中,強調的主要是高性能計算,提供的函式基本上都是針對浮點數的,很少有整形的函式,也缺少一些資料的相互轉換,所以AVX2給我們帶來了希望,增加了豐富和完整的資料型別轉換函式、以及各種整形的比較、數值計算、移位等功能,可以說,AVX2對于AVX就有點類似于SSE4.2對于SSE,有了他,對于影像來說,就有了靈魂了,
另外,AVX2還增加了一些的permute方面的函式,這個為我們打通AVX中2個獨立128位lanes提供了有力的工具和手段,比如說如果我們需要把2個__m256i中的整形資料(8個int32)保存到16個位元組中,這肯定是需要使用打包功能的,但是AVX的打包不是按照SSE的方式進行的打包,這個時候我們就可以用_mm256_permutevar8x32_epi32來協調處理,
inline void _mm256_store2si256_16char(unsigned char *Dest, __m256i Result_L, __m256i Result_H) { // short A0 A1 A2 A3 B0 B1 B2 B3 A4 A5 A6 A7 B4 B5 B6 B7 __m256i Result = _mm256_packs_epi32(Result_L, Result_H); // byte A0 A1 A2 A3 B0 B1 B2 B3 0 0 0 0 0 0 0 0 A4 A5 A6 A7 B4 B5 B6 B7 0 0 0 0 0 0 0 0 Result = _mm256_packus_epi16(Result, _mm256_setzero_si256()); // A0 A1 A2 A3 B0 B1 B2 B3 A4 A5 A6 A7 B4 B5 B6 B7 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 _mm_storeu_si128((__m128i *)Dest, _mm256_castsi256_si128(_mm256_permutevar8x32_epi32(Result, _mm256_setr_epi32(0, 4, 1, 5, 2, 3, 6, 7)))); }
可以這樣認為,_mm256_permutevar8x32_epi32就是類似于SSE環境下的256位的32位shuffle,即真正的_mm256_shuffle_epi32,
AVX2里還增加了一各比較特別的功能,gather系列指令,這個系列的指令可以從不同的位置收集資料到暫存器中,這個是在SSE中缺失的,這個功能可以實作更為快速的資料查表功能,我們后續應該會有一個單獨的文章講這個算子,
第五、AVX相較于SSE的提速可能沒有你想象的高
表面上看,AVX一次性可以處理256位資料,SSE只能處理128位,帶寬是提高了一倍,但是從實際的測驗表現來看,同樣的演算法,使用AVX的提速比相對于SSE來說絕對是不可能達到1倍的,能有40%的提速就已經很不錯了,這也導致我們從SSE轉型為AVX時能得到的喜悅絕對沒有從C++轉型到SSE時那么充足,很多演算法只有5%的提速,這當然于演算法本身的結構有關,如果是以讀取記憶體為主的程式,提速比會很低,以數值計算、比較等等為主的程式就要稍微高一些,我目前寫的一些AVX程式和SSE比較,提速比大概5%到35%之間,
另外一點,在不同的CPU上(都支持AVX及AVX2),同一個演算法的提速比例也是不同,我甚至遇到過AVX還比SSE慢一點的CPU(都是64位程式),這個目前我不知道是為什么,
第六、AVX和SSE的選擇問題
這個沒有絕對的,只是談點自己的看法,
在PC上,一個演算法如果需要使用SIMD優化,除了考慮硬體的因素外(現在市面上能看到的硬體不支持AVX或者AVX2的還是有很多在使用的,特備是AVX2,我他媽的去年買的一個機器,CPU居然還只支持AVX,也是醉了),還要考慮演算法本身的粒度,SSE真的很自由,特別是shuffle,說實在的,我倒現在還沒想到,如何用AVX2實作 32個位元組的自由shuffle, AVX的那個_mm256_shuffle_epi8就是個太監啊, 所以你的演算法里需要借用大量這樣的shuffle,還是考慮用SSE吧, 如果以32位整形資料或者浮點計算為主,AVX肯定在效率上還是要更為高效,
在學習曲線上,如果你沒有AVX的基礎,直接從C開始使用AVX,你會發現你要做很多彎路,因為正如前面所述,使用AVX脫離不了SSE,最好先了解一點SSE的知識,
如果有SSE的基礎,去轉學AVX,則輕松很多,只需要把AVX2里的那個permute、broadcast等等理解透了,你也就基本掌握了真諦,
其他:
十一期間,我大概把我原有的基于SSE演算法里抽取20個左右,轉換為AVX的版本,另外,還提供了普通的C語言版本的演算法,并提供了速度比較,注意,其實這里的C語言演算法,并不是真正的C演算法了,他只能說是編譯器自動向量化后的演算法,也就是比較編譯器自己的向量化和我們手工向量化的速度差異了,因為在同一個DEMO里,為了照顧AVX的代碼,只能選擇/arch:AVX選項,
本文可執行Demo下載地址: https://files.cnblogs.com/files/Imageshop/SSE_Optimization_Demo.rar,選單中藍色字體顯示的部分為已經使用AVX加速的演算法,如果您的硬體中不支持AVX,可能這個DEMO你無法運行,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/511068.html
標籤:其他