vivo 互聯網產品團隊 - Wang xiao
隨著廣告和內容等推薦場景的擴展,演算法模型也在不斷演進迭代中,業務的不斷增長,模型的訓練、產出迫切需要進行平臺化管理,vivo互聯網機器學習平臺主要業務場景包括游戲分發、商店、商城、內容分發等,本文將從業務場景、平臺功能實作兩個方面介紹vivo內部的機器學習平臺在建設與實踐中的思考和優化思路,
一、寫在前面
隨著互聯網領域的快速發展,資料體量的成倍增長以及算力的持續提升,行業內都在大力研發AI技術,實作業務賦能,演算法業務往往專注于模型和調參,而工程領域是相對薄弱的一個環節,建設一個強大的分布式平臺,整合各個資源池,提供統一的機器學習框架,將能大大加快訓練速度,提升效率,帶來更多的可能性,此外還有助于提升資源利用率,希望通過此文章,初學者能對機器學習平臺,以及生產環境的復雜性有一定的認識,
二、業務背景
截止2022年8月份,vivo在網用戶2.8億,應用商店榷訓躍用戶數7000萬+,AI應用場景豐富,從語音識別、影像演算法優化、以及互聯網常見場景,圍繞著應用商店、瀏覽器、游戲中心等業務場景的廣告和推薦訴求持續上升,
如何讓推薦系統的模型迭代更高效,用戶體驗更好,讓業務場景的效果更佳,是機器學習平臺的一大挑戰,如何在成本、效率和體驗上達到平衡,
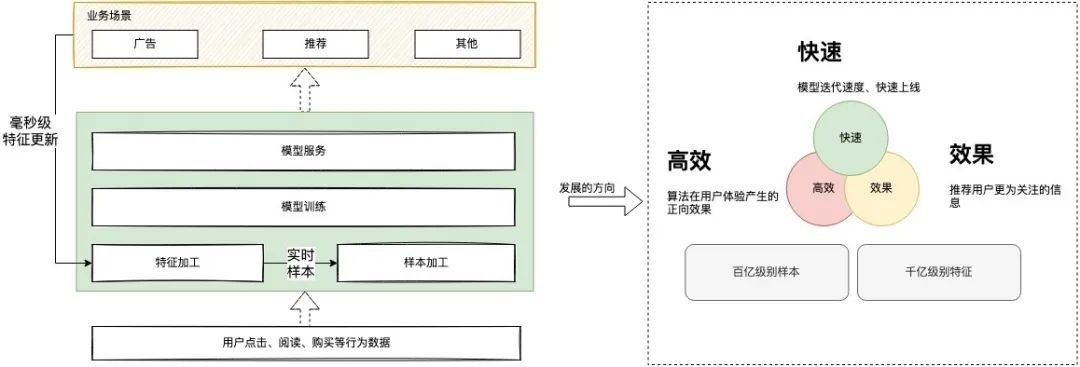
從下圖可以了解到,整個模型加工運用的場景是串行可倍訓的,對于用戶的反饋需要及時進行特征更新,不斷提升模型的效果,基于這個鏈路關系的基礎去做效率的優化,建設一個通用高效的平臺是關鍵,
三、vivo機器學習平臺的設計思路
3.1 功能模塊
基于上圖業務場景的鏈路關系,我們可以對業務場景進行歸類,根據功能不同,通用的演算法平臺可劃分為三步驟:資料處理「對應通用的特征平臺,提供特征和樣本的資料支撐」、模型訓練「對應通用的機器學習平臺,用于提供模型的訓練產出」、模型服務「對應通用的模型服務部署,用于提供在線模型預估」,三個步驟都可自成體系,成為一個獨立的平臺,
本文將重點闡述模型訓練部分,在建設vivo機器學習平臺程序中遇到的挑戰以及優化思路,
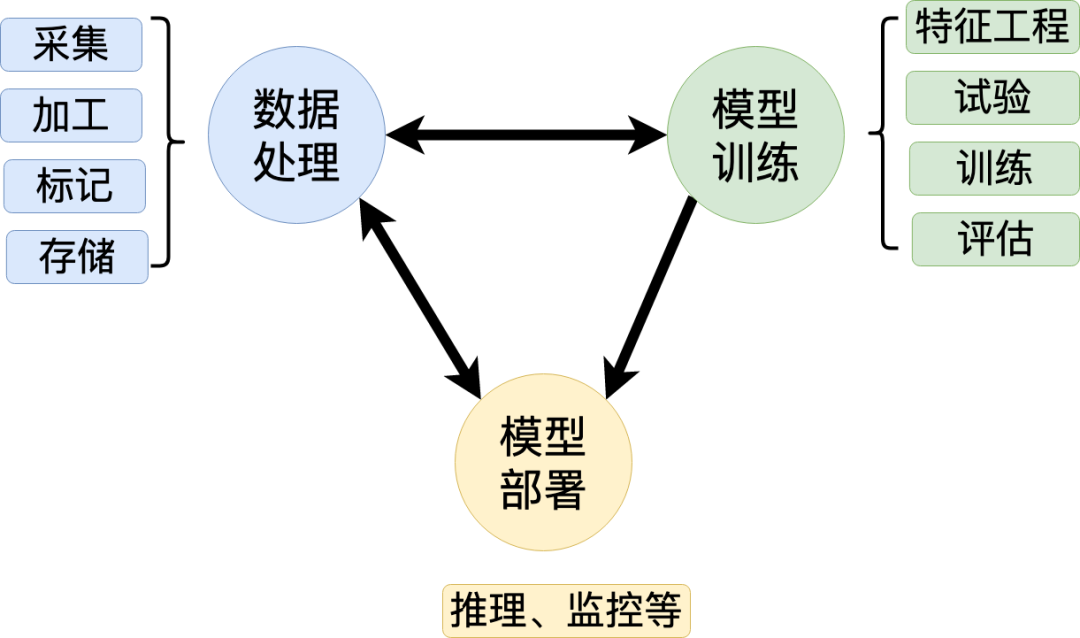
1.資料處理,圍繞資料相關的作業,包括采集、加工、標記和存盤,
其中,采集、加工、存盤與大資料平臺的場景相吻合,標記場景是演算法平臺所獨有的,
-
資料采集,即從外部系統獲得資料,使用Bees{vivo資料采集平臺}來采集資料,
-
資料加工,即將資料在不同的資料源間匯入匯出,并對資料進行聚合、清洗等操作,
-
資料標記,是將人類的知識附加到資料上,產生樣本資料,以便訓練出模型能對新資料推理預測,
-
資料存盤,根據存取的特點找到合適的存盤方式,
2. 模型訓練,即創建模型的程序,包括特征工程、試驗、訓練及評估模型,
-
特征工程,即通過演算法工程師的知識來挖掘出資料更多的特征,將資料進行相應的轉換后,作為模型的輸入,
-
試驗,即嘗試各種演算法、網路結構及超參,來找到能夠解決當前問題的最好的模型,
-
模型訓練,主要是平臺的計算程序,平臺能夠有效利用計算資源,提高生產力并節省成本,
3.模型部署,是將模型部署到生產環境中進行推理應用,真正發揮模型的價值,
通過不斷迭代演進,解決遇到的各種新問題,從而保持在較高的服務水平,
4. 對平臺的通用要求,如擴展能力,運維支持,易用性,安全性等方面,
由于機器學習從研究到生產應用處于快速發展變化的階段,所以框架、硬體、業務上靈活的擴展能力顯得非常重要,任何團隊都需要或多或少的運維作業,出色的運維能力能幫助團隊有效的管理服務質量,提升生產效率,
易用性對于小團隊上手、大團隊中新人學習都非常有價值,良好的用戶界面也有利于深入理解資料的意義,
安全性則是任何軟體產品的重中之重,需要在開發程序中盡可能規避,
3.2 模型訓練相關
模型訓練包括了兩個主要部分,一是演算法工程師進行試驗,找到對應場景的最佳模型及引數,稱之為“模型試驗”,二是計算機訓練模型的程序,主要側重平臺支持的能力,稱之為“訓練模型”,
建模是演算法工程師的核心作業之一,建模程序涉及到很多資料作業,稱為特征工程,主要是調整、轉換資料,主要任務是要讓資料發揮出最大的價值,滿足業務訴求,
3.2.1 模型試驗
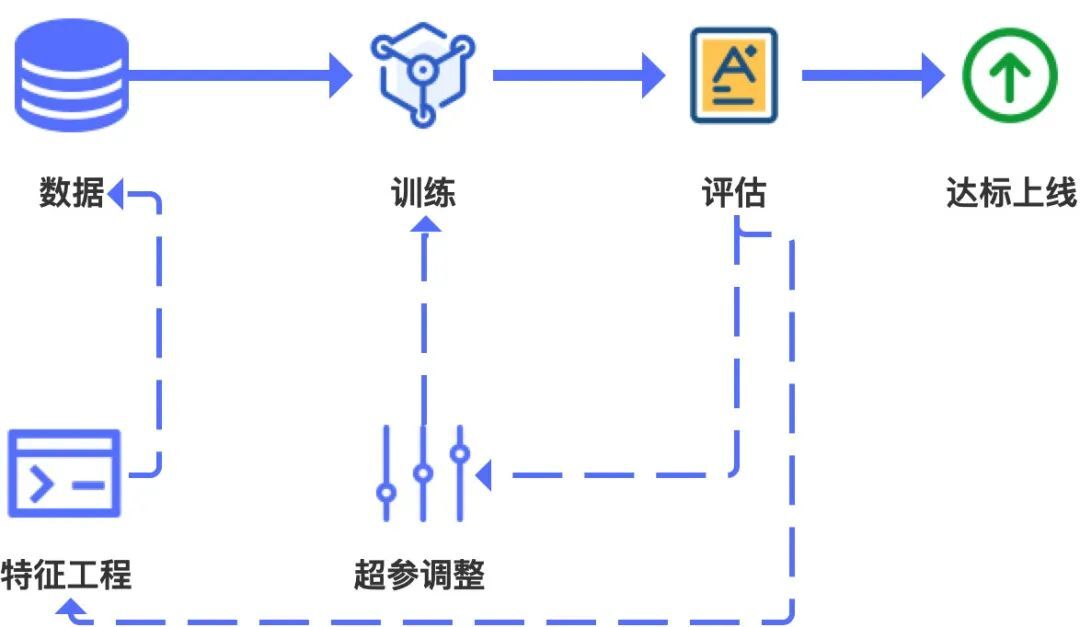
特征作業和超參調整是建模程序中的核心作業,特征作業主要對資料進行預處理,便于這部分輸入模型的資料更好的表達資訊,從而提升模型輸出結果的質量,
資料和特征工程決定模型質量的上限,而演算法和超參是無限逼近這個上限,
超參調整包括選擇演算法、確認網路結構、初始引數,這些依賴于演算法工程師豐富的經驗,同時需要平臺支持試驗來測驗效果,
特征工程和超參調整是相輔相成的程序,加工完特征后,需要通過超參的組合來驗證效果,效果不理想時,需要從特征工程、超參兩個方面進行思索、改進,反復迭代后,才能達到理想的效果,
3.2.2 訓練模型
可通過標準化資料介面來提高快速試驗的速度,也能進行試驗效果的比較,底層支持docker作業系統級的虛擬化方案,部署速度快,同時能將模型直接部署上線,用戶無需對訓練模型進行更多定制化的操作,批量提交任務能節約使用者的時間,平臺可以將一組引陣列合的試驗進行比較,提供更友好的使用界面,
其次,由于訓練的方向較多,需要算力管理自動規劃任務和節點的分配,甚至可以根據負載情況,合理利用空閑資源,
四、vivo機器學習平臺實踐
前面我們介紹了機器學習平臺的背景和發展方向,現在我們來介紹下,平臺在解決用戶問題部分的困擾和解決思路,
4.1 平臺能力矩陣
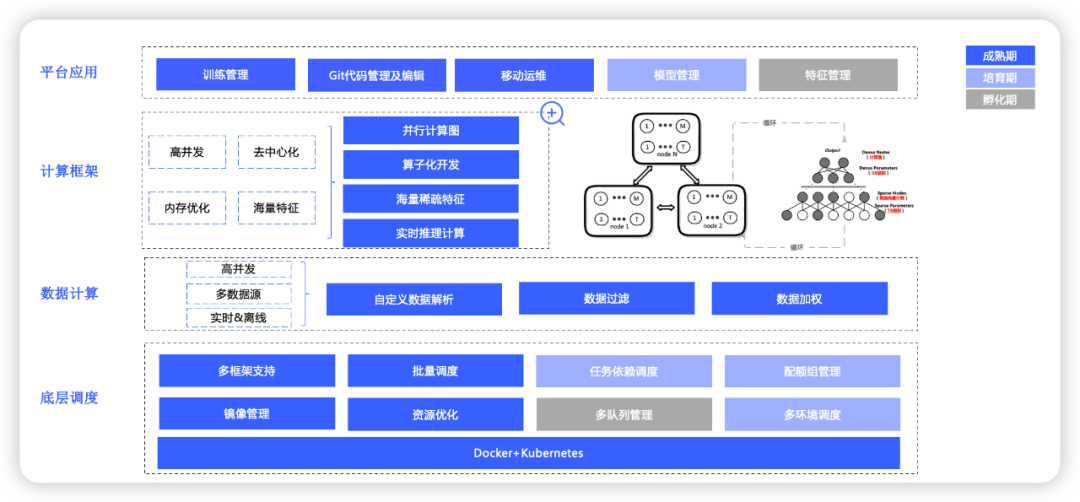
機器學習平臺主要目標是圍繞模型訓練進行深耕,并輔助用戶進行模型決策,更快的進行模型部署,
以此為目標分為兩個方向,訓練框架的優化能夠支撐大規模模型的分布式計算,調度能力優化能夠支持批次模型的執行,
在調度能力上,平臺由原生k8s調度,單個訓練調度的效率較低,升級為kube-batch批量調度,到以混合云精細化編排為目標,當前主要處于靈活性調度策略的形式,
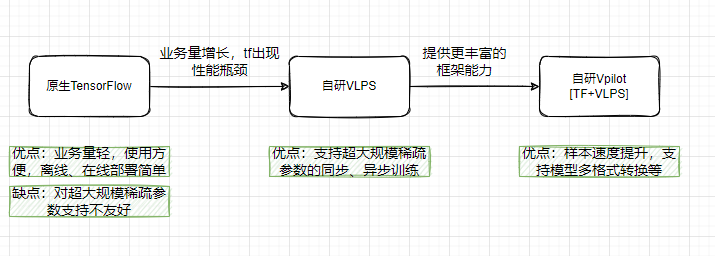
在訓練框架上,從原生Tensorflow模型,隨著特征和樣本規模的擴大,自研了超大規模的訓練框架vlps,當前處于TensorFlow+vlps結合的新框架狀態,
4.2 平臺能力介紹
平臺能力建設主要圍繞模型試驗和訓練模型的運用,運用程序中遇到的痛點和難點如何解決,是我們在實踐中的關鍵,同時,訓練框架也是平臺關鍵能力的體驗,基于業務的復雜度,持續對框架進行優化,
已覆寫公司內部演算法工程師模型除錯的作業,已達到億級樣本,百億特征的規模,
4.2.1 資源管理
痛點:
機器學習平臺屬于計算密集型的平臺,
-
業務場景不同,是否完全按照業務分組進行資源劃分;
-
資源池劃分過小,會導致資源利用率低且沒辦法滿足業務激增的資源訴求;
-
資源不足以滿足業務訴求時,會存在排隊情況導致模型更新不及時;
-
如何管理好算力,提效與降本的平衡,是平臺資源管理的一個核心問題,
解決思路:
資源管理的基本思路是將所有計算資源集中起來,按需分配,讓資源使用率盡量接近100%,任何規模的資源都是有價值的,
比如,一個用戶,只有一個計算節點,有多條計算任務時,資源管理通過佇列可減少任務輪換間的空閑時間,比手工啟動每條計算任務要高效很多,多計算節點的情況,資源管理能自動規劃任務和節點的分配,讓計算節點盡量都在使用中,而不需要人為規劃資源,并啟動任務,多用戶的情況下,資源管理可以根據負載情況,合理利用其它用戶或組的空閑資源,隨著節點數量的增加,基于有限算力提供更多業務支持是必經之路,
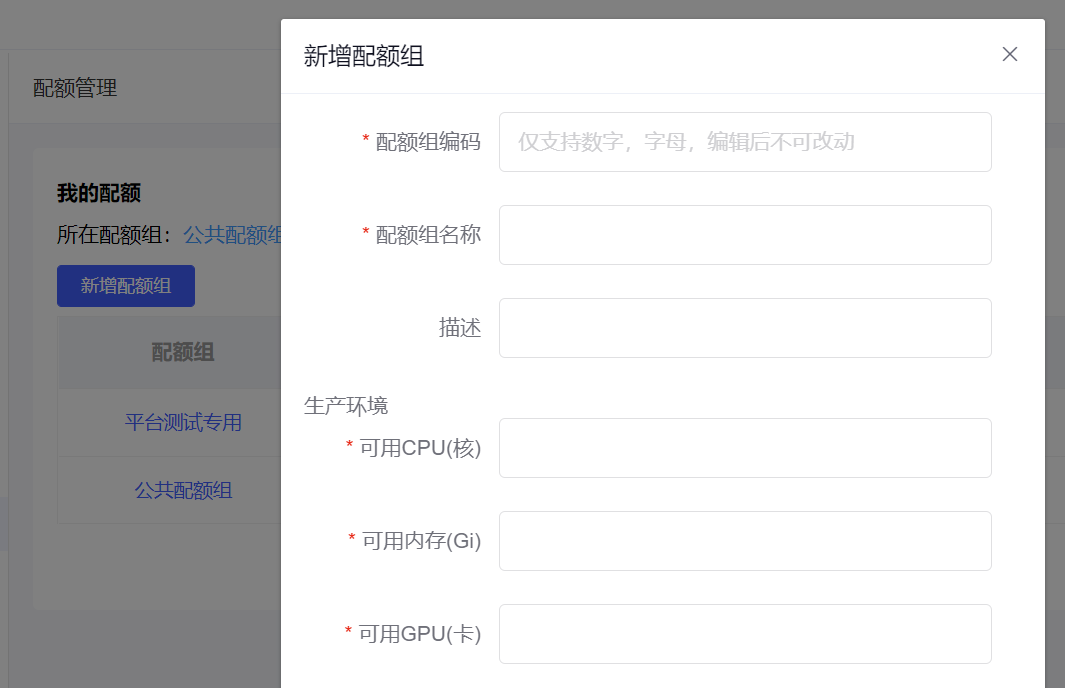
1.以配額限資源濫用:
新增配額組和個人配額,減少業務之間的相互干擾,盡可能滿足各組的資源需要,并且配額組支持臨時擴容和共享,解決偶發性激增的資源訴求;限額后用戶僅支持在有限資源下使用,讓用戶自我調節高優先級訓練,
2.以調度促資源優化:
新增生產環境,確認模型已經正常迭代,在合理利用率的情況下切換至高優環境,提供更高性能的資源池;同時提供調度打分機制,圍繞資源顆粒度、配置合理性等維度,讓合理的訓練資源更快的拉起,減少調度卡住情況;
上線多維度調度打分機制后,平臺不合理訓練任務有大幅度下降,資源效率提升,
圍繞并不限于以下維度:最大運行時長、排隊時長、cpu&記憶體&gpu顆粒度和總需求量等,
4.2.2 框架自研
痛點:
隨著樣本和特征規模增加后,框架的性能瓶頸凸顯,需要提升推理計算的效率,
發展路徑:
每一次的發展路徑主要基于業務量的發展,尋求最佳的訓練框架,框架的每一次版本升級都打包為鏡像,支持更多模型訓練,
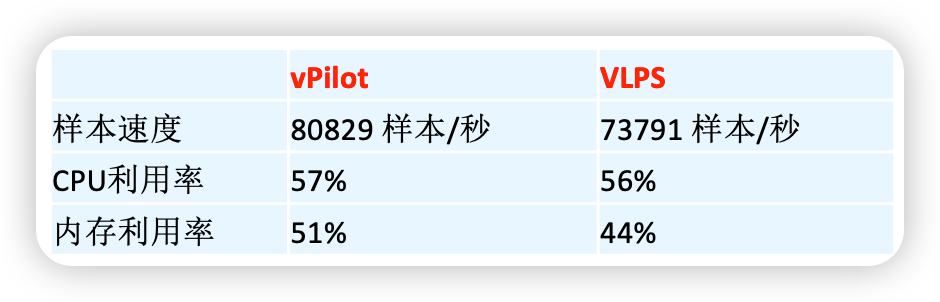
當前效果:
4.2.3 訓練管理
痛點:
如何支持多種分布式訓練框架,滿足演算法工程師的業務訴求,讓用戶無需關心底層機器調度和運維;如何讓演算法工程師快速新建訓練,執行訓練,可查看訓練狀態,是訓練管理的關鍵,
解決思路:
上傳代碼至平臺的檔案服務器和git都可以進行讀取,同時在平臺填寫適量的引數即可快速發起分布式訓練任務,同時還支持通過OpenAPI,便于開發者在脫離控制臺的情況下也能完成機器學習業務,
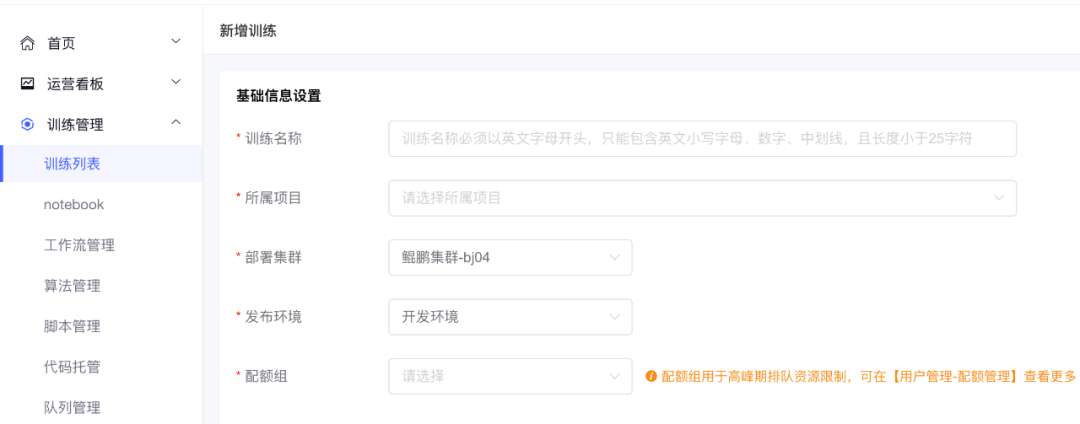
圍繞訓練模型相關的配置資訊,分為基礎資訊設定、資源資訊設定、調度依賴設定、告警資訊設定和高級設定,在試驗超參的程序中,經常需要對一組引陣列合進行試驗,
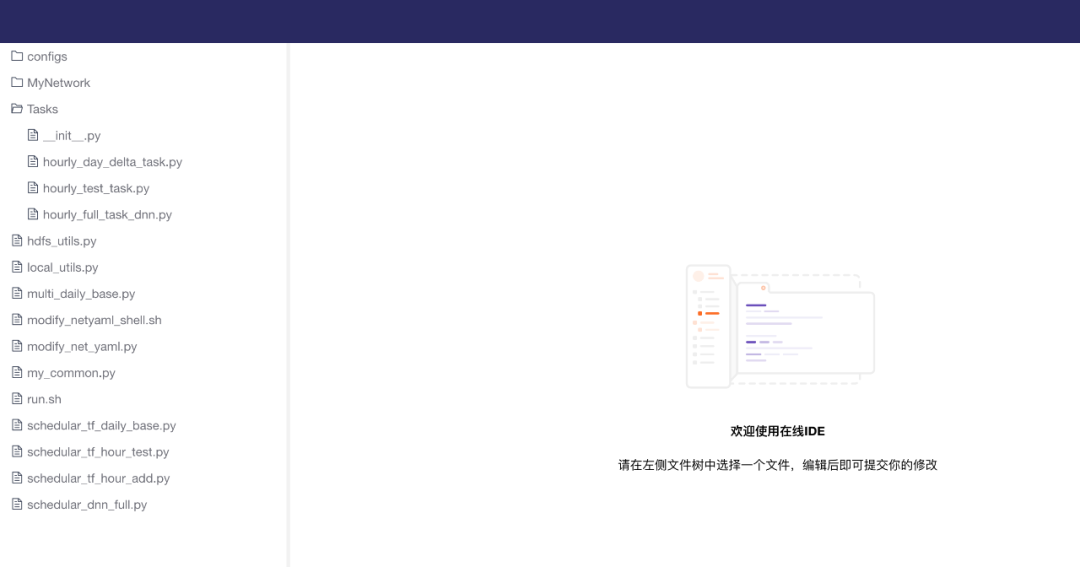
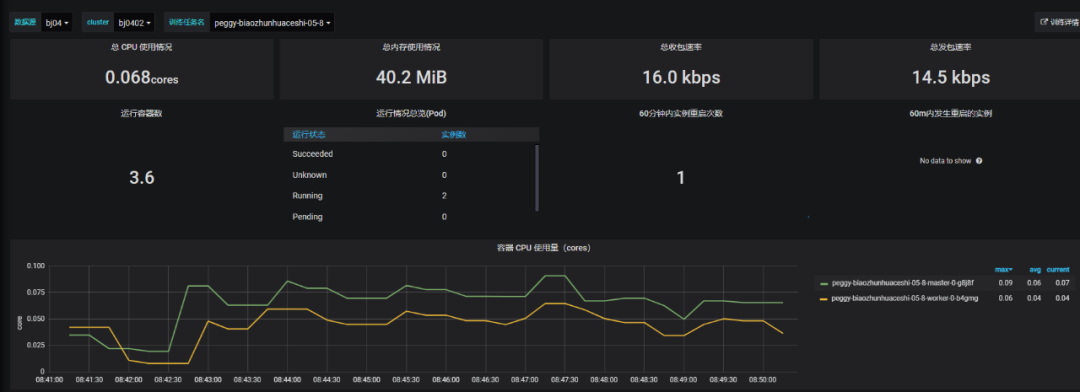
批量提交任務能節約使用者時間,平臺也可以將這組結果直接進行比較,提供更友好的界面,訓練讀取檔案服務器或git的腳本,即可快速執行訓練,
1.可視化高效創建訓練
2. 準確化快速修改腳本
3. 實時化監控訓練變動
4.2.4 互動式開發
痛點:
演算法工程師除錯腳本成本較高,演算法工程師和大資料工程師有在線除錯腳本的訴求,可直接通過瀏覽器運行代碼,同時在代碼塊下方展示運行結果,
解決思路:
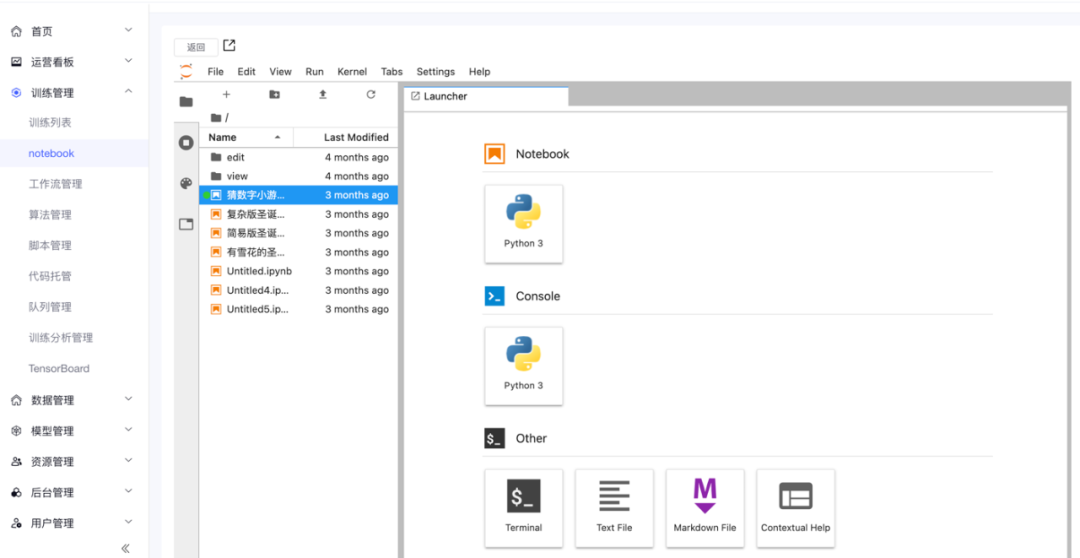
在互動式工具中進行試驗、開發,如:jupyter notebook,提供所見即所得的互動式體驗,對除錯代碼的程序非常方便,
在互動試驗的場景下,需要獨占計算資源,機器學習平臺需要提供能為用戶保留計算資源的功能,如果計算資源有限,可對每個用戶申請的計算資源總量進行限制,并設定超時時間,
例如,若一周內用戶沒有進行資源使用后, 就識訓保留資源,在識訓資源后,可繼續保留用戶的資料,重新申請資源后,能夠還原上次的作業內容,在小團隊中,雖然每人保留一臺機器自己決定如何使用更方便,但是用機器學習平臺來統一管理,資源的利用率可以更高,團隊可以聚焦于解決業務問題,不必處理計算機的作業系統、硬體等出現的與業務無關的問題,
五、總結
目前vivo機器學習平臺支撐了互聯網領域的演算法離線訓練,使演算法工程師更關注于模型策略的迭代優化,從而實作為業務賦能,未來我們會在以下方面繼續探索:
1.實作平臺能力的貫通
-
當前特征、樣本還是模型的讀取都是通過hdfs實作的,在平臺上的告警、日志資訊都未關聯上,后續可以進行平臺能力貫通;
-
平臺的資料和模型還有標準化的空間,降低學習成本,提升模型開發的效率,
2. 加強框架層面的預研
-
研究不同分布式訓練框架對模型效果的影響,適配不同的業務場景;
-
提供預置的引數,實作演算法、工程、平臺的解耦,降低用戶的使用門檻,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/513685.html
標籤:其他
上一篇:行程和計劃任務