開篇語
假設檢驗,相信大伙兒或多或少都接觸過,比如你的實驗有兩組(實驗組、對照組)資料,你要分析一下它們之間的差異,那么假設檢驗是怎么也繞不過去的步驟,反正你不想做,你導師也會要求你做的,你導師不要求,你投稿時,那些reviewers也會要求你做的……
既然躲不開繞不去,那我們也不用怕它,小編今天就來跟大伙兒好好理一理,假設檢驗到底是啥東東,應該怎么玩!
基本概念與套路
什么是假設檢驗呢?從字面上看,肯定得先有個假設對吧,然后我們就來檢驗這個假設是不是成立,聽上去很簡單嘛!說得專業一點其實也不難理解,就是根據得到的資料,對我們預先設定的假設進行統計學檢驗,最后判斷結果是否有統計學意義,
基本套路一般是:
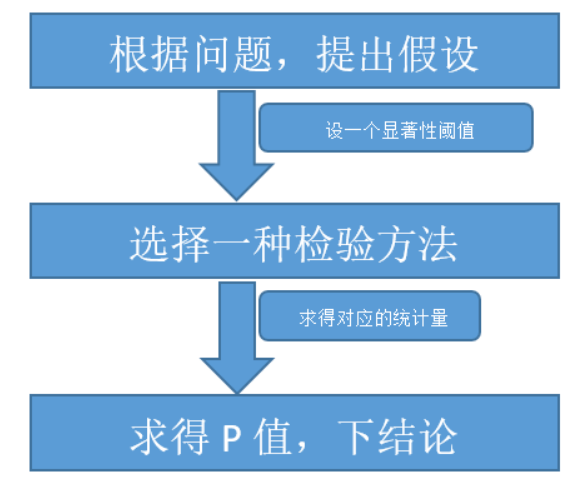
套路清楚后,我們現在來拆解套路:
根據問題 提出假設
什么是“假設(hypothesis)”呢?牛津詞典中有這樣的解釋:A supposition or proposed explanation made on the basis of limited evidence as a starting point for further investigation,看著有點暈是不是?我們來個通俗的理解就是,當我們沒有足夠的證據(即先驗知識)來說明一個問題時,我們可以先給出一個假定的說明,這個預先給出的假定說明,我們通常稱為原假設或者零假設,與之對應的,我們還可以提出一個對立假設,又稱為備擇假設,
舉個例子,當我們拿到一個硬幣,想研究一下它的正反面是否均勻,我們可以先假設它是不均勻的,這個就是零假設;那么對應的,它正反面是均勻的,就是備擇假設,
PS:一般來說(并不絕對),原假設就是需要我們收集證據來反對的假設,而備擇假設就是需要收集證據來支持的假設,
擴展閱讀 為啥有了零假設,我們還需要弄一個對應的備擇假設呢?對備擇假設的重要性,
90多年前,英國著名的統計學家哥色特(其筆名就是Student)曾舉例解釋過這個問題,
他的主要思想就是人們往往都傾向于選擇相信概率比較大的事件,
比如一些來自于正態總體的資料,現想檢驗它們的均值是不是等于a0?
假設得到檢驗的概率值為0.0001,雖然這個值很小,但是你不能認為這批資料的均值不等于a0,為什么呢?
因為這時候你只有一個a0供你檢驗,概率值再小,也不能否認它發生的可能性,
而此時,如果你再有一個“備胎”(值為a1)讓你去檢驗,最后檢驗的概率值為0.05,比前面的值大很多,
這時候你就會傾向于選擇后面a1這個值,而認為原來的a0不真,
所以,我們需要有“比較”,多一個“備胎”,多一份選擇!(此例子原型來源于《數理統計學簡史》),
“假設”通常有三種形式,以我們最熟悉的生物樣本資料的差異分析來舉例,當我們分析的是單個樣本時,我們可以比較這個樣本的資料與一個已知值的關系,是大于,小于,還是等于,
擴展閱讀
單個樣本的假設的形式如下所示(其中H0為原假設,H1為備擇假設,θ0為已知的值):
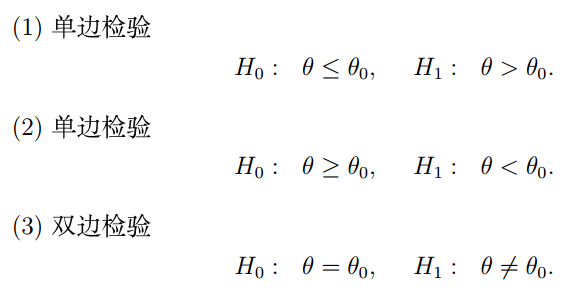
所謂單邊檢驗,就是檢驗我們拿到的資料與一個已知值相比,是否大于等于它(或者小于等于它,你可以理解為,只需要判斷數軸一側的大小關系,所以叫單邊檢驗),雙邊檢驗就是看兩個值是否相等(你可以理解為,既不能大于,也不能小于,兩邊不等的情況都得排除,所以叫雙邊檢驗),
當我們分析的是兩個樣本,考察它們之間是否存在差異,也有三種情況,就是樣本1的值大于等于樣本2,或者小于等于樣本2,或者樣本1與樣本2相等,
擴展閱讀
兩個樣本的假設的形式如下圖(其中H0為原假設,H1為備擇假設):
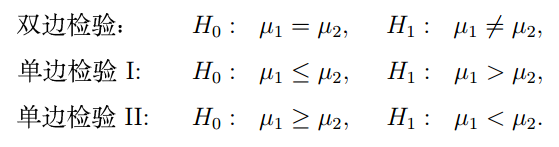
再有一種情況就是分析多個樣本之間的差異,這時候就無所謂大于小于這些單邊檢驗了,只有全部相等(或不全相等)的情況,
擴展閱讀
多個樣本之間的情況如下圖所示:
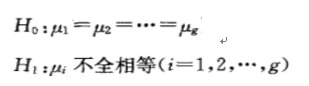
如果上面的解釋和公式你還是覺得有點暈,那么我們來舉個例子,以蛋白質定量資料為例,分析兩組資料之間是否存在差異,我們假設現在有兩大組資料(R, C),每一組得到5次生物學重復資料,得到資料如下:
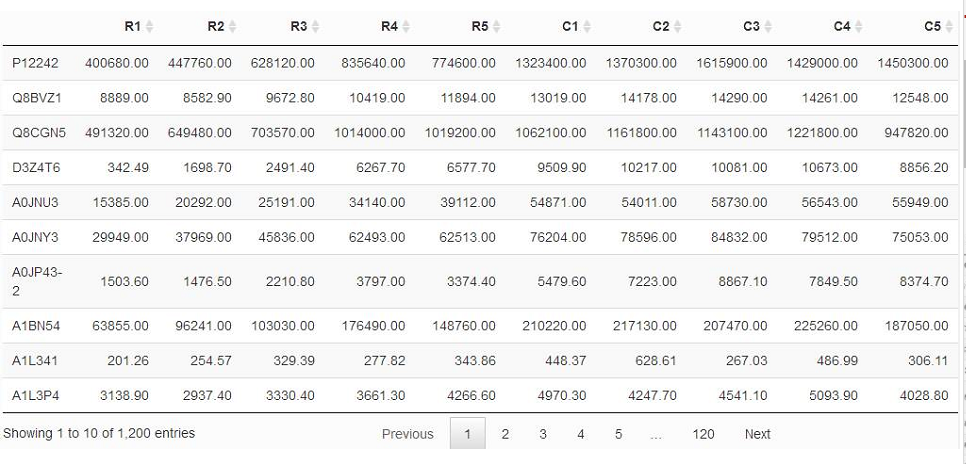
比如我們想看蛋白質P12242在R組和C組的平均表達量(分別設為μ1,μ2)是否一致,也就是說,要么相等,要么不等,大伙兒可以對照著看看上面提到的兩個樣本雙邊檢驗的說明,此時我們做原假設H0,即該蛋白質在兩組中表達量相等(μ1=μ2),那么備擇假設就是H1,即該蛋白質在兩組中表達量不相等(有差異,即μ1≠μ2),
假設給出來以后,我們一般會先選定一個顯著性水平a,也就是一個判斷的閾值,當統計分析出來的p值小于這個閾值時,說明是有統計顯著性的,可以推翻原假設,通常可以設為0.05,嚴格一點可以設定為0.01,具體設多少要根據你的實驗設計和目的,可以做一定的調整,
擴展閱讀
為啥我們要設一個顯著性水平a作為閾值呢?這就得說到假設檢驗中通常愛犯的兩類錯誤(如下表):第一類錯誤(又稱I型錯誤)是,否定了真實的原假設,即“棄真”,對應上面的例子就是,原假設是蛋白質P12242在兩組中的表達量平均值是沒有差異的,本來它是成立的,結果被你否定了,你認為有差異,這就產生了錯誤;第二類錯誤(又稱II型錯誤)是,接受了錯誤的原假設,即“取偽”,怎么控制第一類犯錯誤的概率呢?就是我們通常說的設定一個顯著性水平α,第二類犯錯誤的概率通常標記為β,

可以告訴你的是,在給定樣本的情況下,減少犯其中一類錯誤的概率,就會導致增加犯另一類錯誤的概率,所以若想同時減少犯兩類錯誤概率,就需要增加樣本的容量,這就是為什么我們在分析差異表達的時候,通常都對樣本量有一定的要求,否則你就算是做了這些假設檢驗,結果也比較難有說服力,當然,增加樣本容量就會增加實驗成本,所以通常建議在能力容許的范圍內,盡可能的多增加一些樣本量,
選擇一種檢驗方法
好,我們繼續說“蛋白質P12242在兩組中的表達量平均值是沒有差異”這個故事,上面的部分我們已經把假設列好了,原假設就是它們沒差異,備擇假設是它們有差異,接下來,我們就得開始檢驗這個假設了,
檢驗假設當然是需要有檢驗方法的!檢驗方法當然是不止一種的!針對這個例子,我們列出幾種常用的假設檢驗的方法,做假設檢驗的一般思路就是,根據某種分布,求出資料對應的統計量,以此來判斷該值是否落入拒絕域中(即拒絕原假設的取值范圍),從而也可以得到對應的概率值P(以前可通過查表得到,現在通過計算機可以快速計算),所以,接下來我們就以各種分布為主線,跟大伙兒聊聊假設檢驗的常見思路,詳細的方法介紹我們會在下一篇推文中進行全面的總結,
正態分布和t分布(T檢驗)
正態分布,大伙兒從小就聽說過吧!它也許是最常見,最重要的一種分布形式了,它雖不是著名數學家Gauss第一個提出的,但是他將之應用于天文學研究,使其廣為人知,所以正態分布通常又稱為高斯分布,
擴展閱讀
正態分布的概率密度函式運算式為:
![]()
其中m和s為兩個常數,m表征資料的均值,s表征資料的標準差,此時可稱隨機變數X服從引數為m, s的正態分布,記作X~N(m, s2),
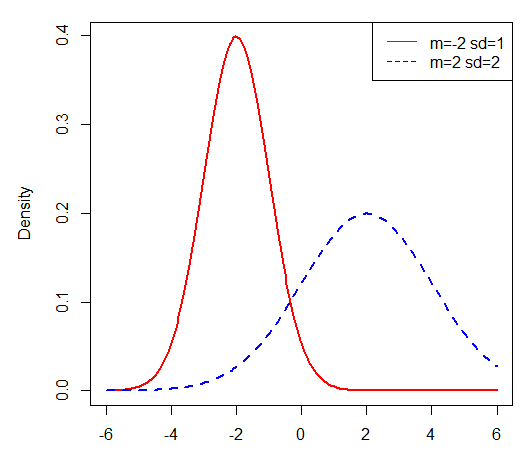
(其中紅線表示的是均值為-2,方差為1的正態分布曲線,藍線表示的是均值為2,方差為4的正態分布曲線,
從中可以看出,方差越小,影像越“瘦高”,方差越大,圖形越“矮胖”,)
t分布是由英國著名統計學家哥色特發表,其筆名是“Student”,所以該分布又稱為“Student t分布”,該分布的公布,標志著小樣本統計推斷的開始,
擴展閱讀
其隨機變數T的運算式為:
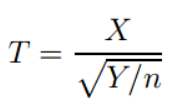
其中X~N(0, 1),Y~C-2-(n),且X,Y相互獨立,其自由度為n,記作T~t(n),
t分布曲線圖形: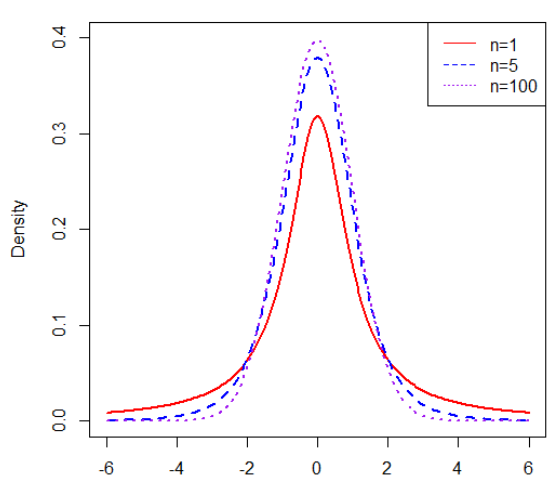
(紅線、藍線、紫線分別是自由度為1、5、100的T分布曲線,大家也許發現了,T分布與正態分布曲線看上去是不是很像,這里主要是因為T分布是為了小樣本的資料分布,當自由度n趨于無窮大時,T分布曲線就越接近標準正態分布曲線,)
下面我們繼續使用上面蛋白質定量資料的例子,來說明一下t.test函式的使用:
現在我們想檢驗蛋白質P12242在R組和C組的平均表達量(分別設為μ1,μ2)是否一致,我們已經設定好了原假設H0,即該蛋白質在兩組中表達量相等(μ1=μ2),那么備擇假設就是H1,即該蛋白質在兩組中表達量不相等(有差異,即μ1≠μ2),
然后我們選擇一種檢驗方法,這里我們假設兩組資料滿足正態分布,所以我們選擇用T檢驗來評估它們是否有差異(如何判斷資料是否滿足某種分布,這個問題后面我們會再講),
讀入資料,

在R語言中可以直接使用t.test函式可進行T檢驗,函式原型為:

其中x, y是我們樣本資料構成的向量,alternative表示備擇假設的形式,“two.sided”表示雙邊檢驗(H1: μ1≠μ2), “less”表示單邊檢驗(H1:μ1<μ2),“greater”表示單邊檢驗(H1:μ1>μ2),paired表示樣本是否是配對的,var.equal表示兩總體方差是否相等,
在這個例子中,t.test函式呼叫如下:
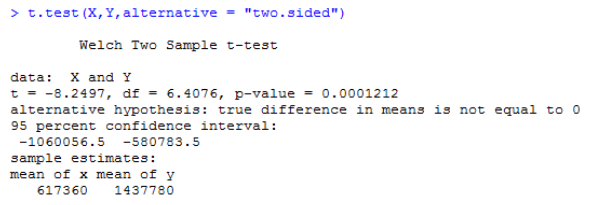
最后得到P值等于0.0001212,小于0.05,可以支持我們拒絕原假設,即我們認為蛋白質P12242在R組和C組的平均表達量不相等,
通過以上的假設檢驗,我們就可以挑選出表達差異的基因/蛋白質,進行后續生物學意義上的注釋、分類、聚類、相互作用關系分析等,
擴展閱讀
怎么判斷兩樣本是否配對?一般出現以下情況中的任意一種,就認為是配對的:
-
配對的兩個受試物件分別接受兩種不同的處理;
-
同一受試物件接受兩種不同的處理;
-
同一受試物件處理前后的結果進行比較(即自身配對);
-
同一物件的兩個部位給予不同的處理,
F分布(方差分析)
另一種常用來評估各資料組均數之間差異的方法叫方差分析,用這種方法,可以評估所有觀測資料之間的波動程度,不同組之間的波動,以及組內資料的波動,
與方差分析相關的是F分布,由1924年英國統計學家R.A.Fisher提出,所以用Fisher的第一個字母F來命名,假設有兩個獨立的隨機變數,這兩個變數都分別符合卡方分布,它們相除以后的比率,我們就用F分布來描述,
擴展閱讀
假設樣本X~c2(n),Y~c2(m),且X和Y相互獨立,則稱隨機變數F:
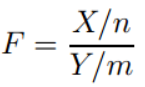
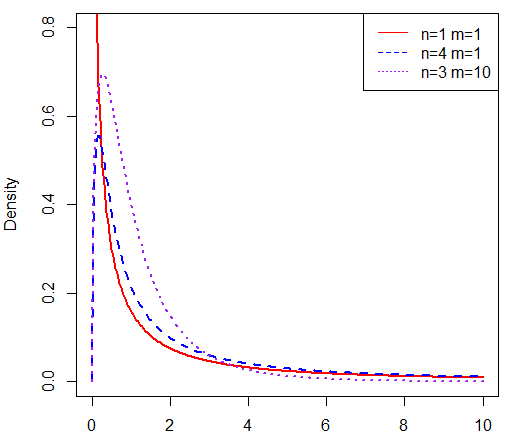
服從自由度為(n, m)的F分布,記作F~F(n, m),使用R語言畫出F分布曲線及R代碼如下:

在R語言中,我們通常使用aov函式進行計算分析:

其中formula是方差分析的公式,data就是我們的資料集,其是資料框的形式,
formula中各符號表達的含義可以參考《R語言實戰》一書,在使用的程序中要注意不要搞混了:

我們來舉個例子說說aov的使用,比如分析小白鼠接種了3中不同菌型的傷寒桿菌后,平均存活的天數有無顯著差異?原始資料如下:
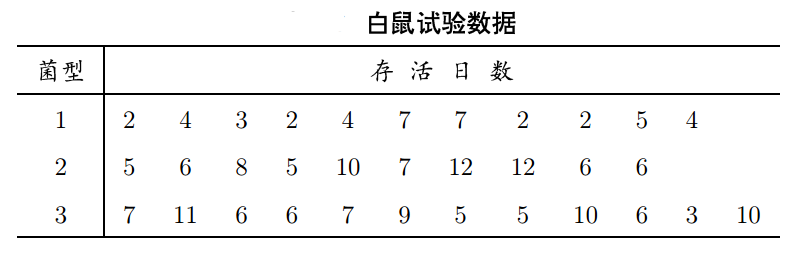
代碼實作:

從結果中得p值為0.0012,小于0.05,即認為3組小鼠的平均存活天數有顯著性差異,
擴展閱讀
在進行aov函式分析之前,我們一般要對資料進行正態性檢驗和方差齊性檢驗,在R語言中常用到的函式分別為shapiro.test和bartlett.test,只有滿足要求的資料,我們才能進行該方法的計算,對于不滿足要求的資料,
我們可以采用秩和檢驗的方法,比如KW秩和檢驗(使用kruskal.test函式)或者Friedman秩和檢驗(使用friedman.test函式),它們的詳細使用我們計劃在下一篇推文中詳細介紹,
卡方分布(卡方檢驗)
上面我們講了針對資料差異分析的檢驗方法,接下來跟大伙兒聊聊如何檢驗資料是否符合某種分布,包括對列聯表的小樣本量資料的檢驗,
話說,如果有n個相互獨立的隨機變數,它們都服從標準正態分布,那么這n個隨機變數的平方和可以構成一個新的隨機變數,這個新的隨機變數分布的規律稱為卡方分布,是不是很厲害的樣子?
擴展閱讀
卡方分布的形式是這樣的,我們假設樣本Xi~N(0,1),其中i=1,2,3…n,則隨機變數Y:
![]()
則稱Y~c2(n),即Y服從自由度為n的卡方分布
R語言代碼如下:

圖形如下(其中紅線、藍線、紫線分別是自由度為1、4、10的卡方分布曲線),
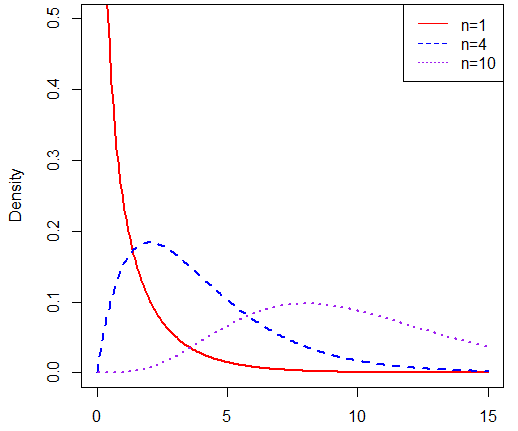
如果以卡方分布為理論依據進行假設檢驗,這種檢驗方法我們稱為卡方檢驗,
卡方檢驗主要用在兩個方面:
a. 檢驗資料是否服從某種分布,比如卡方分布、均勻分布、泊松分布、正態分布等
b. 檢驗列聯表資料,
Tips
啥叫列聯表呢?其實就是互動分類表,互動分類是同時依據兩個或多個變數的值,
將所研究的個案分類,互動分類的目的是將兩個或者多個變數分組,
然后比較各組的分布狀況,以尋找變數間的關系,比如下面這個列聯表,
就是依據是否吸煙與是否患肺癌進行分類,然后可以通過比較這些數值,尋找吸煙與患肺癌之間是否相關,
R語言中使用chisq.test函式進行計算:

其中x, y為資料向量,correct表示是否進行連續性修正;p表示原假設落在某區間的理論概率,默認的是均勻分布;rescale.p=FASLE的意思是要求輸入的p之和要等于1;simulate.p.value表示是否使用仿真的方法計算p值,B是指仿真的次數,
檢驗資料是否服從某種分布
說了這么多,到底我怎么檢驗我們的資料是符合什么分布呢?接下來我們就來舉個例子,
我們都知道,不管是中考、高考、還是某類大型考試,某部門一般都愛要求老師給學生打的成績要服從正態分布,那么現在假設我們得到了這樣一批學生的成績,我們想來檢驗下這批學生的成績是否服從正態分布呢?
代碼如下:

從結果中可得p值等于0.06161,大于0.05,可認為此次老師批閱試卷的成績服從正態分布,
在檢驗資料服從某種分布時,我們還可以使用Kolmogorov-Smirnov檢驗,也是可以用于檢驗各種常見的分布,其函式是ks.test,比如還是上面那個例子,其代碼實作如下:

得到的p值為0.2162,也是大于0.05,得的結論與上面一致,即此次的成績符合正態分布,
檢驗列聯表資料
列聯表是啥剛才已經解釋過了,我們常見的就是2x2的列聯表形式,還是吸煙與肺癌的例子:
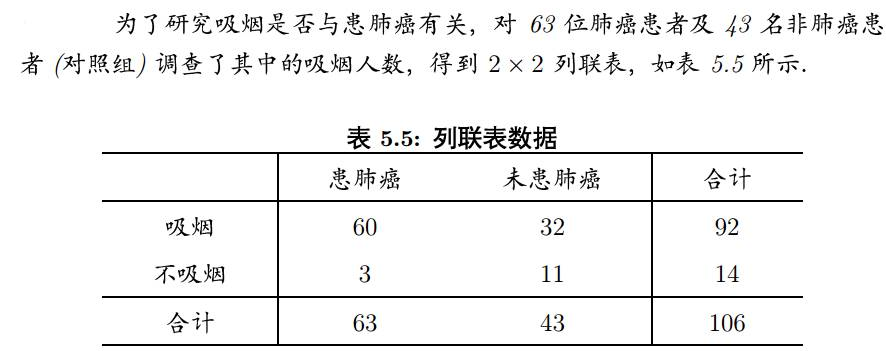
代碼實作如下:

所得的p值為0.004855,小于0.05,可以認為吸煙與患癌病有關,
檢驗列聯表資料時,我們還常會用到Fisher檢驗,該檢驗是建立在超幾何分布的基礎上,當樣本量比較小時(這里有個經驗值,頻數小于4),一般建議使用該檢驗方法,
Tips 1)超幾何分布:是統計學上一種離散概率分布,描述的是,從有限個物件中抽出n個物件,
成功抽出指定型別的物件的次數(不歸還),比如,在產品質量的抽檢中(抽出來的不放回去),
如果N件產品中有M件次品,抽檢n件時所得次品數X,就服從超幾何分布, 2)頻數:也稱“次數”,對整個資料按某種標準分組,然后統計出各個組內含個體的個數,
比如上面例子中,有一個頻數為3(不吸煙患肺癌這一組),所以這里建議使用Fisher檢驗,其代碼實作如下:
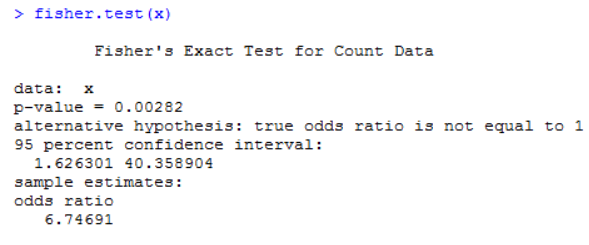
所得的p值為0.00282,小于0.05,所得結論與上面一致,且這里還給出了優勢比(odds ratio)的值,該值大于1,其含義是吸煙越多,患肺癌的可能性就越大,
求得P值,下結論
其實在第2部分我們舉例說明的時候就已經做了這一步,在這里,我們想著重說明一下的是:
a. 在我們下結論的時候,其實是用了一個大家廣泛接受的原則:在一次試驗中,小概率事件基本上不會發生,若它正好發生了,那么我們就有理由懷疑原假設的準確性;
b. 對于顯著性水平a的大小(比如0.01, 0.05, 0.1之類),這個大小沒有一個絕對的定值,只要你能說出一些合理的理由,你完全可以調整這個值的界限,若是對這些約定俗成的值感興趣的,可以去看看那些老前輩的文章(比如《Statistical methods for research workers》);
c. 從前面描述,我們都可以看出,我們所下結論時都是根據p值而來,所以,在描述結論的時候一定不能下絕對的結論,比如“認為3組小鼠的平均存活天數一定(或肯定)有差異”,這種結論是不嚴謹的;
d. 我們所說的“具有顯著性差異”,這個表現不出具體差異的大小,只能說明它們存在差異,所以,這也是我們在分析資料時,經常會看到大家不僅關注p值,還同時關注倍數(fold change)變化的原因,這種可視化表現形式尤其以火山圖最為著名,
P值校正方法小匯總:https://mp.weixin.qq.com/s/YzaIXvkoEWuaxoZqYMCedg
假設檢驗方法集合:https://mp.weixin.qq.com/s/zHNwKhj6sywHLa8MuDjMcg
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/514173.html
標籤:其他