摘要:RNN可以用于描述時間上連續狀態的輸出,有記憶功能,能處理時間序列的能力,讓我驚嘆,
本文分享自華為云社區《用RNN進行影像分類——CNN之后的探索》,作者: Yin-Manny,
一、 寫前的思考:
當看完RNN的PPT,我驚嘆于RNN可以用于描述時間上連續狀態的輸出,有記憶功能,能處理時間序列的能力,
當拿到思考題,在CNN框架下加入RNN程式,這是可以實作的嗎,如果可以,它的理論依據是什么,它的實作方法是什么,它的效果是怎樣的,加入這個有必要嗎,
我尋找了CNN combine with RNN的資料,看了CLDNN論文,我知道了:
CNN和RNN直接的不同點:
CNN進行空間擴展,神經元與特征卷積;RNN進行時間擴展,神經元與多個時間輸出計算;
RNN可以用于描述時間上連續狀態的輸出,有記憶功能;CNN則用于靜態輸出;
CNN高級結構可以達到100+深度;RNN的深度有限,
CNN和RNN組合的意義:
大量資訊同時具有時間空間特性:視頻,圖文結合,真實的場景對話;
帶有影像的對話,文本表達更具體;
視頻相對圖片描述的內容更完整,
但是這對思考題沒有什么幫助,
于是我又從RNN分類影像下手,試圖弄明白RNN能用于影像分類的原理,首先需要將圖片資料轉化為一個序列資料,例如MINST手寫數字圖片的大小是28x28,那么可以將每張圖片看作是長為28的序列,序列中的每個元素的特征維度是28,這樣就將圖片變成了一個序列,同時考慮回圈神經網路的記憶性,所以圖片從左往右輸入網路的時候,網路可以記憶住前面觀察東西,然后與后面部分結合得到最后預測數字的輸出結果,理論上是行得通的,但是對于影像分類,CNN才是主流,RNN影像分類的理論,對于CNN能有什么幫助呢?
甚至我們知道,回圈神經網路還是不適合處理圖片型別的資料:
第一個原因是圖片并沒有很強的序列關系,圖片中的資訊可以從左往右看,也可以從右往左看,甚至可以跳著隨機看,不管是什么樣的方式都能夠完整地理解圖片資訊;
第二個原因是回圈神經網路傳遞的時候,必須前面一個資料計算結束才能進行后面一個資料的計算,這對于大圖片而言是很慢的,但是卷積神經網路并不需要這樣,因為它能夠并行,在每一層卷積中,并不需要等待第一個卷積做完才能做第二個卷積,整體是可以同時進行的,
那么我要怎么在CNN中加入RNN程式呢?
初步設想:
把CNN比較深層次的網路提取到的特征序列化,再喂給RNN進行分類,因為我認為這時候CNN提取到的特征比原始影像有更強的序列關系(如下圖,越深層得到的特征序列關系越強,比如跳著看可能就難以進行分類了)
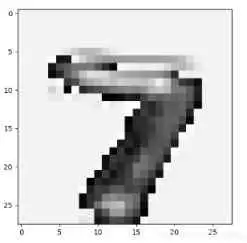

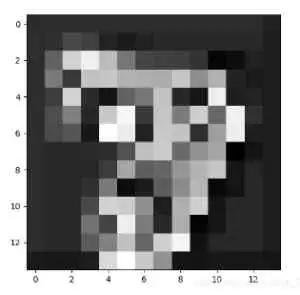
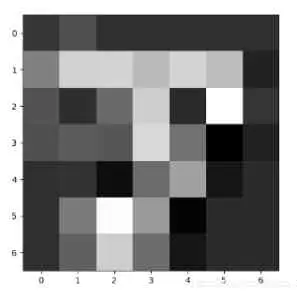
二、 如何將影像資料改成序列資料?如何加入RNN系列程式,以改進圖片分類的性能?
設image.shape為(h,w)
則令time_steps=h, input_size=w即可將影像資料改成序列資料
令X=[batch_size,h,w]
outputs, states = tf.nn.dynamic_rnn(rnn_cell, X, dtype=tf.float32)即可將X應用于RNN程式
如果是三通道圖片,如RGB,則利用影像處理知識將三通道影像轉為單通道灰度影像,
例如:
import matplotlib.pyplot as plt # plt 用于顯示圖片 from PIL import Image import numpy as np image1 = Image.open('./1.jpg') img=np.array(image1) # 通道轉換 def change_image_channels(image): # 3通道轉單通道 if image.mode == 'RGB': r, g, b = image.split() return r,g,b ima = change_image_channels(image1) for i in range(3): plt.imshow(ima[i]) plt.show() r=img[:,:,0] g=img[:,:,1] b=img[:,:,2] GRAY = b * 0.114 + g * 0.387 + r * 0.29 im=Image.fromarray(GRAY) # numpy 轉 image類 im.show()
效果如下:


正如初步設想所說,把CNN比較深層次的網路提取到的特征序列化,再喂給RNN進行分類,因為我認為這時候CNN提取到的特征比原始影像有更強的序列關系,也許能夠改進圖片分類的性能?
例如我們將第一層的特征圖喂到RNN中

import sys sys.path.append('..') import torch from torch.autograd import Variable from torch import nn from torch.utils.data import DataLoader from torchvision import transforms as tfs from torchvision.datasets import MNIST # 定義資料 data_tf = tfs.Compose([ tfs.ToTensor(), tfs.Normalize([0.5], [0.5]) # 標準化 ]) train_set = MNIST('./data', train=True, transform=data_tf, download=True) test_set = MNIST('./data', train=False, transform=data_tf, download=True) train_data = DataLoader(train_set, 64, True, num_workers=2) test_data = DataLoader(test_set, 128, False, num_workers=2) # 定義模型 class rnn_classify(nn.Module): def __init__(self, in_feature=28, hidden_feature=100, num_class=10, num_layers=2): super(rnn_classify, self).__init__() self.rnn = nn.LSTM(in_feature, hidden_feature, num_layers) # 使用兩層 lstm self.classifier = nn.Linear(hidden_feature, num_class) # 將最后一個 rnn 的輸出使用全連接得到最后的分類結果 def forward(self, x): ''' x 大小為 (batch, 1, 28, 28),所以我們需要將其轉換成 RNN 的輸入形式,即 (28, batch, 28) ''' x = x.squeeze() # 去掉 (batch, 1, 28, 28) 中的 1,變成 (batch, 28, 28) x = x.permute(2, 0, 1) # 將最后一維放到第一維,變成 (28, batch, 28) out, _ = self.rnn(x) # 使用默認的隱藏狀態,得到的 out 是 (28, batch, hidden_feature) out = out[-1, :, :] # 取序列中的最后一個,大小是 (batch, hidden_feature) out = self.classifier(out) # 得到分類結果 return out net = rnn_classify() criterion = nn.CrossEntropyLoss() optimzier = torch.optim.Adadelta(net.parameters(), 1e-1) # 開始訓練 from utils import train train(net, train_data, test_data, 10, optimzier, criterion)
迭代10次準確率高達98%,因此分類效果還是不錯的,
三、 不同的RNN細胞結構、不同的RNN整體結構,對分類性能有什么影響?
不同的細胞結構具有不同的門結構,對長短期記憶有不同的權重
不同的RNN整體結構有不同的層數與架構,對長短期記憶有不同的遺忘屬性
常見RNN細胞總結:
BasicRNNCell--一個普通的RNN單元,
GRUCell--一個門控遞回單元細胞,
BasicLSTMCell--一個基于遞回神經網路正則化的LSTM單元,沒有窺視孔連接或單元剪裁,
LSTMCell--一個更復雜的LSTM單元,允許可選的窺視孔連接和單元剪切,
MultiRNNCell--一個包裝器,將多個單元組合成一個多層單元,
DropoutWrapper - -一個為單元的輸入和/或輸出連接添加dropout的包裝器,
常見RNN整體結構:
LSTM和GRU,其它的還有向GridLSTM、AttentionCell等
這些在tf.keras.layers.***中都可以直接呼叫API
因此只需修改下面一行代碼的API即可實作不同的RNN細胞結構、不同的RNN整體結構對分類性能的影響的實驗,
self.rnn = nn.LSTM(in_feature, hidden_feature, num_layers) # API
由于時間問題我沒有運行完代碼,直接附上相關資料的實驗結果:
![]()

一般來說,多層結構的復雜度更高,分類性能會更好,但是產生的時間成本也會更多,
四、 nn.dynamic_rnn輸出的final_state.h和output[:,-1,:]是否是相同的?
RNN 是這樣一個單元:y_t, s_t = f(x_t, s_{t-1}) ,畫成圖的話,就是這樣:

考慮 Vanilla RNN/GRU Cell(vanilla RNN 就是最普通的 RNN,對應于 TensorFlow 里的 BasicRNNCell),作業程序如下:
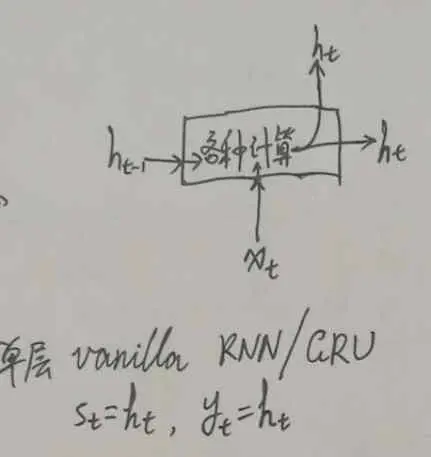
這時,s_t = y_t = h_t
對于 LSTM,它的回圈部件其實有兩部分,一個是內部 cell 的值,另一個是根據 cell 和 output gate 計算出的 hidden state,輸出層只利用 hidden state 的資訊,而不直接利用 cell,這樣一來,LSTM 的作業程序就是:
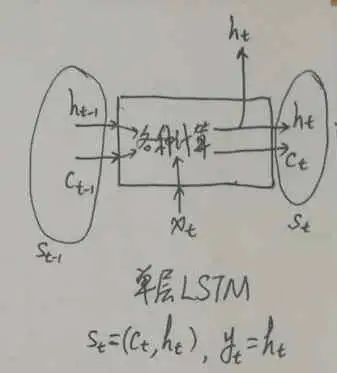
其中真正用于回圈的狀態 s_t 其實是 (c_t, h_t) 組成的 tuple(就是 TensorFlow 里的 LSTMStateTuple),而輸出 y_t 僅僅是 h_t(例如網路后面再接一個全連接層然后用 softmax 做分類,這個全連接層的輸入僅僅是 h_t,而沒有 c_t),這時就可以看到區分 RNN 的輸出和狀態的意義了,
如果是一個多層的 Vanilla RNN/GRU Cell,那么一種簡單的抽象辦法就是,把多層 Cell 當成一個整體,當成一層大的 Cell,然后原先各層之間的關系都當成這個大的 Cell 的內部計算程序/資料流動程序,這樣對外而言,多層的 RNN 和單層的 RNN 介面就是一模一樣的:在外部看來,多層 RNN 只是一個內部計算更復雜的單層 RNN,圖示如下:
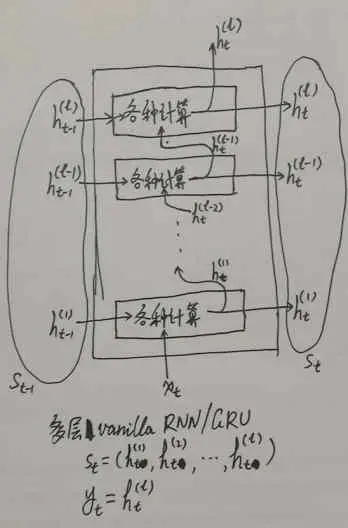
大方框表示把多層 RNN 整體視為一層大的 Cell,而里面的小方框則對應于原先的每一層 RNN,這時,如果把大方框視為一個整體,那么這個整體進行回圈所需要的狀態就是各層的狀態組成的集合,或者說把各層的狀態放在一起組成一個 tuple:st=(st(l),st(2),…, st(l))而這個大的 RNN 單元的輸出則只有原先的最上層 RNN 的輸出,即整體的yt= yt(l)=ht(l),
最后對于多層 LSTM:
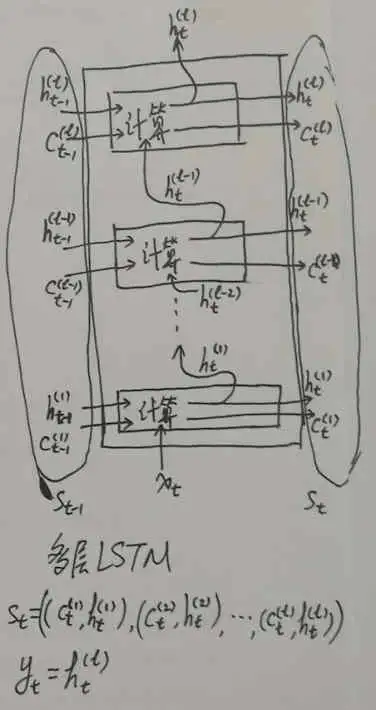
和之前的例子類似,把多層 LSTM 看成一個整體,這個整體的輸出就是最上層 LSTM 的輸出:yt=ht(l);而這個整體進行回圈所依賴的狀態則是每一層狀態組合成的 tuple,而每一層狀態本身又是一個 (c, h) tuple,所以最后結果就是一個 tuple 的 tuple
這樣一來,便可以回答問題:final_state.h和output[:,-1,:]是否是相同的
output是RNN Cell的output組成的串列,假設一共有T個時間步,那么 outputs = [y_1, y_2, ..., y_T],因此 outputs[:,-1,:] = y_T;而 final_state.h 則是最后一步的隱層狀態的輸出,即 h_T,
那么,到底 output[:,-1,:]等不等于final_state.h 呢?或者說 y_T 等不等于 h_T 呢?看一下上面四個圖就可以知道,當且僅當使用單層 Vanilla RNN/GRU 的時候,他們才相等,
代碼運行結果具體見附件代碼第三問,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/514182.html
標籤:其他
上一篇:【YOLOv5】LabVIEW+YOLOv5快速實作實時物體識別(Object Detection)含原始碼
下一篇:假設檢驗