關于平均數
根據國家統計局發布的資訊,2019年全國城鎮非私營單位在崗職工社會年平均工資提高到了82461元,比2018年名義增長11%,實際增長8.7%,城鎮私營單位在崗職工社會平均工資達到了49575元,比2018年上漲8.3%,扣除價格因素后,實際增長6.1%,
這些資料引起了廣大網友的質疑,有人說自己拖了社會主義的后腿,自己又“被平均了”;也有土豪表示“沒拖后腿,自己不差錢”,很多人調侃國家統計局的平均數計算方式:“張家有財一千萬,九個鄰居窮光蛋,平均起來算一算,個個都是張百萬”,國家統計局的計算方式可不是簡單地“平均起來算一算”,這種平均數僅僅是算數平均數,也叫均值,
均值
均值大家都清楚,就是求和平均,這是最深入人心的一種平均數,
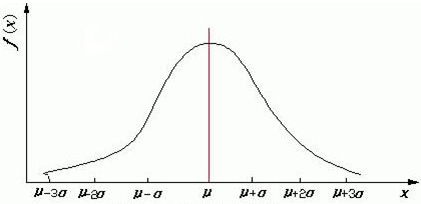
在正態分布的假設下,均值也是數學期望,用μ表示,它位于倒鐘的中心位置:
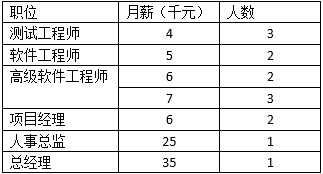
均值并不總是能反應資料的資訊,有時很還會給人誤導,下表是某個企業的月薪情況:
該企業的月薪均值是:
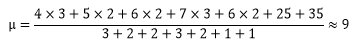
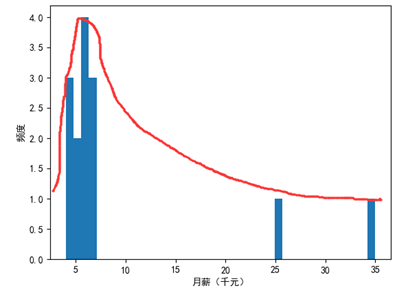
看起來是個待遇不錯的公司,但實際情況是工程師和專案經理們天天要求加薪,原因是兩位高管的月薪遠遠超過了其他人,他們是資料中的“例外值”,下面的代碼繪制了月薪表的直方圖:
1 import numpy as np 2 import matplotlib.pyplot as plt 3 4 salary = np.array([4, 4, 4, 5, 5, 6, 6, 7, 7, 7, 6, 6, 25, 35]) 5 miu = np.mean(salary) # 均值 6 print('μ =', miu) 7 8 plt.hist(salary, bins=40) 9 plt.xlabel('月薪(千元)')10 plt.ylabel('頻度')11 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽12 plt.show()
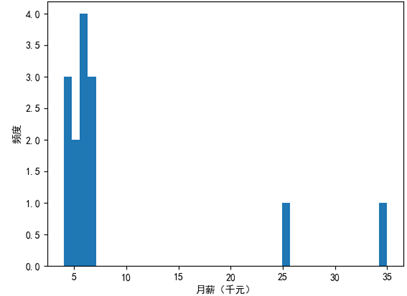
兩位高管被孤立了,他們的月薪將影響計算結果的準確性,此時我們說資料是偏斜的,確切地說,由于例外值在右側,均值向右偏斜,形成了右偏態分布,
這種扭曲的倒鐘曲線成為偏態分布,根據尾巴的位置,分為左偏態(負偏態)和右偏態(正偏態):
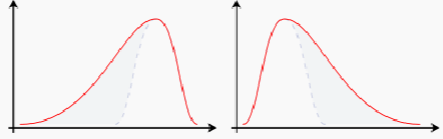
左偏態將把均值拉向左側,此時均值小于大部分數值;右偏態把均值拉向右側,此時均值大于大部分數值,工資表的資料是右偏態,
例外值可以通過一些例外檢測演算法來剔除,比如基于正態分布的例外檢測和使用區域例外因子的無監督學習演算法,
中位數
當例外資料對均值產生誤導時,不妨試試中位數,這是另一種平均數,
正如它的名字一樣,中位數永遠在資料的中間位置,先把資料按大小排序,如果是奇數個,那么中位數正好是中間那個;如果是偶數個,那么中位數是中間兩個資料的平均值,
按照中位數的演算法把工資表展開:

共有14個數,位于中間的恰好都是6,因此中位數也是6,
1 salary = np.array([4, 4, 4, 5, 5, 6, 6, 7, 7, 7, 6, 6, 25, 35])2 median = np.median(salary)3 print('median =', median) # median = 6.0
中位數也有抓瞎的時候,
為了提升游樂園的競爭力,管理者決定根據游客的年齡來適當增加或減少一些專案,游樂園采取網上售票,所有游客在購票時都需要填寫年齡,經過三個月的資料采集,計算出游客年齡的中位數是20,這可是個追求刺激的年齡,于是游樂園下架了旋轉木馬這類溫柔的專案,添加了更大規模的過山車和大鐘擺,在下一個周末:

游客中的大多數是家長帶著小朋友,一大加一小的模式,假設某個專案正好有14個人參加,他們的年齡如下:

好了,現在中位數是20,結論是這個專案適合20歲的年輕人參加,于是:


1 ages = np.array([5, 5, 5, 6, 6, 7, 8, 32, 32, 32, 34, 35, 36, 36])2 print('μ =', ages.mean()) # 均值,等同于np.mean(ages)3 print('median =', np.median(ages)) # 中位數4 plt.hist(ages, bins=40)5 plt.xlabel('年齡')6 plt.ylabel('頻度')7 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽8 plt.show()
μ = 19.928571428571427,median = 20.0,直方圖如下:
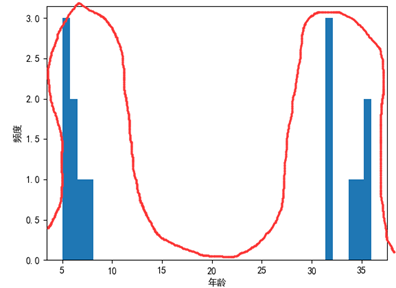
資料呈駝峰形,均值和中位數都在峰谷,其原因是資料應該劃分為兩批,一批是孩子,另一批是父母,這種情況下均值和中位數都不靠譜了,需要使用“眾數”,
眾數
眾數也是一種平均數,是一組資料中頻數最大的數值,與前兩種平均數不同,一組資料的眾數可能有多個,如果資料呈現出多種趨勢,我們可以為每種趨勢給出一個眾數,游樂場年齡資料可以分為兩批,稱這種資料是雙峰資料,
求得眾數的方法很多,比如觀察法,金氏插入法,皮爾遜經驗法等,這里簡單地介紹一下觀察法,觀察法大致分為2步:先將資料按照數值分組統計頻數,再把頻數最高的一個或幾個挑選出來作為眾數,可以使用pandas求得眾數:
1 import pandas as pd2 df = pd.DataFrame(ages)3 print(df.mode()) # 眾數
結果是5和32,
眾數是唯一自帶分組屬性的平均數,但是如果一組資料的眾數太多,則只會混淆視聽,此時的眾數將沒有任何用處,
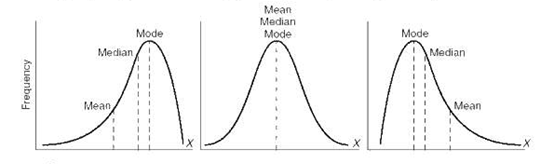
最后附上不同分布下均值、中位數、眾數的關系:
作者:我是8位的
出處:http://www.cnblogs.com/bigmonkey
本文以學習、研究和分享為主,如需轉載,請聯系本人,標明作者和出處,非商業用途!
掃描二維碼關注公作者眾號“我是8位的”

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/5153.html
標籤:其他
上一篇:機器學習筆記(二)
下一篇:讀書筆記——麥肯錫精英高效閱讀法