資料(data)是事實或觀察的結果,是對客觀事物的邏輯歸納,是用于表示客觀事物的未經加工的的原始素材……在計算機系統中,資料以二進制資訊單元0,1的形式表示(百度百科)
后半句看懂了,至于前半句,還是忘記比較好,
簡單地說,任何事物的結果都是資料,注意是結果,不是程序,程序是一個動作,是驅動結果的行為,
更簡單一點,用任何媒體記錄的東西都是資料,比如一本書中的文字,一張光碟中的資訊,當然了,程式員們也許第一個想到的是資料庫中的資料,

假設有客戶發了一條微信:
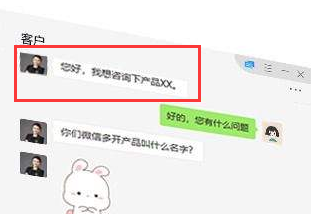
通常管這叫“資訊”,那么資訊和資料有什么區別?
假設你在另一個手機上恢復和某人的聊天記錄,你管這個叫什么?叫“歷史資料”對吧,所以說,資料是資訊的集合,通常把某一類資料叫做資料集,比如圖片資料集,聊天記錄資料集,實際上這些名詞沒必要區分得那么詳細,這些概念通常都很直白,不會弄錯,即使弄錯了也沒關系,你管資料集叫資訊集也不影響理解,
人是很善于分類的,什么事情都要分分類,最近比較熱門的分類是垃圾分類:

23種設計模式還分成5、7、11三類:
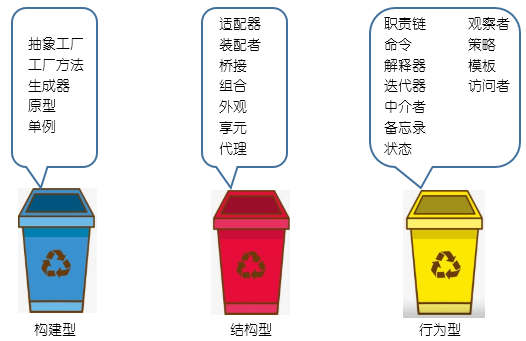
對于天天打交道的資料,也少不了要分分類,大體上,資料可以分為結構化資料和非結構化資料,對于結構化資料的每一維度,還可以根據型別和尺度進一步劃分,
結構化和非結構化
結構化資料指能夠用行列存盤,有嚴格維度劃分的資料,科學家的實驗資料,關系型資料庫的表記錄,都是結構化資料,
與結構化對應的是非結構化資料,比如某個系統產生的日志,一封郵件,一張圖片,一段視頻,一段微信聊天記錄……可見世界上的大部分資料都是非結構化資料,
顯然結構化資料更易于分析和處理,實際上大部分統計學模型和機器學習模型都只能使用格式化資料,很多時候,在面對非格式化資料時,不得不將其轉換成結構化資料,
對于一條非格式化資料,首先能夠提取出的資訊是資料的大小,當然,大小的度量根據資料集的不同可能會有所差異,
來看一下美團上對蘇州松鶴樓的評價:
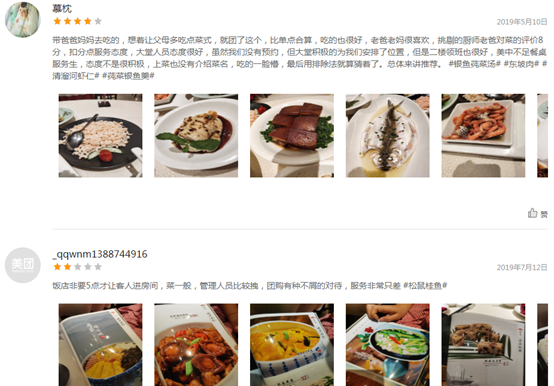
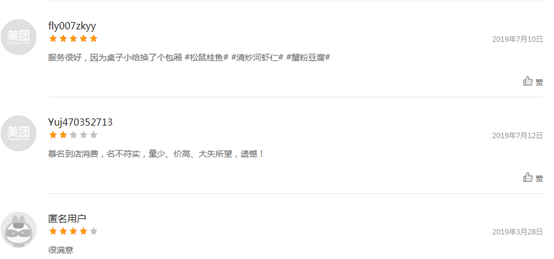

第一條評論的文字比較多,其他大多數評論都很短,這符合常理,畢竟大多數人都很懶,
“帶爸爸媽媽去吃的,想著讓父母多吃點菜式,就團了這個,比單點合算,吃的也很好,老爸老媽很喜歡,挑剔的廚師老爸對菜的評價8分,扣分點服務態度,大堂人員態度很好,雖然我們沒有預約,但大堂積極的為我們安排了位置,但是二樓領班也很好,美中不足餐桌服務生,態度不是很積極,上菜也沒有介紹菜名,吃的一臉懵,最后用排除法就算猜著了,總體來講推薦, #銀魚莼菜湯# #東坡肉# #清溜河蝦仁# #莼菜銀魚羹#”
這條評論有194個字(包括標點),松鶴樓共有274人評論,平均評論是21個字,在沒有大量重復陳述句的前提下,差不多可以認定這條品論是精品評論了,
接下來對評論進行分詞決議:
1 mport pandas as pd 2 from jieba.analyse import ChineseAnalyzer 3 4 content = '帶爸爸媽媽去吃的,想著讓父母多吃點菜式,就團了這個,比單點合算,吃的也很好,老爸老媽很喜歡,挑剔的廚師老爸對菜的評價8分,扣分點服務態度,大堂人員態度很好,雖然我們沒有預約,但大堂積極的為我們安排了位置,但是二樓領班也很好,美中不足餐桌服務生,態度不是很積極,上菜也沒有介紹菜名,吃的一臉懵,最后用排除法就算猜著了,總體來講推薦,' \ 5 '#銀魚莼菜湯# #東坡肉# #清溜河蝦仁# #莼菜銀魚羹#' 6 length = len(content) 7 print('length =', length) 8 9 segments = []10 analyzer = ChineseAnalyzer()11 # 進行中文分詞12 for word in analyzer(content):13 segments.append({'word': word.text, 'count': 1})14 15 df = pd.DataFrame(segments)16 # 詞頻統計17 word_feq = df.groupby('word')['count'].sum()18 # 按count降序排序,取出現次數最多的前30個詞19 word_feq_n = word_feq.sort_values(ascending=False)[:30]20 print(word_feq_n)
使用'ChineseAnalyzer'時可能出現:ImportError: cannot import name 'ChineseAnalyzer',安裝whoosh即可:pop install whoosh
代碼先對這條評論進行分詞,再統計詞頻最高的前30個詞,結果如下:
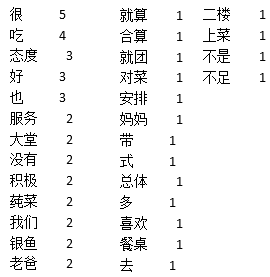
其中“好”、“積極”、“合算”、“喜歡”這類正面的詞共出現了5次,“不足”出現了1次,說明用顧客對本次用餐還是比較滿意的,評論中出現了“我們”、“爸爸”、“媽媽”,說明該顧客是多人用餐,“態度”、”菜”、 “上菜”都出現了,通常來說,如果態度和菜比較差,顧客不會用“不足”來評價,最可能的不足是“上菜”,
根據這些分析,可以得到格式化資料:

對于后三個欄位,簡單地用2表示好,1表示一般,0表示差,
借助類似的方法,我們可以將非結構化資料轉換成結構化資料,從而挖掘出更多的資訊,
定性和定類
對于結構化資料來說,某一列的型別可分為定量資料和定性資料,如果能夠參與加減乘除這類運算,那么這個資料就是定量資料,否則是定性資料,
看起來很簡單,比如某個企業的員工資訊:

姓名這類文本型別肯定是定性資料,年齡可以相減,得到的年齡差是有意義的,是定量資料;學號、性別、電話,雖然也是數字,但是進行減法沒有任何意義,因此也是定性資料,對于定量資料來說,可以計算這一維度的平均數、最大值、最小值等資訊,
4個尺度
比定性和定量更進一步,根據每一列參與數學運算的程度,結構化資料的一列可歸為4個尺度之一:定類尺度、定序尺度、定距尺度、定比尺度,
每個維度的資料都有一個測度中心,它是一個描述資料趨勢的數值,也被稱為資料平衡點,平均數是常用的測度中心,
定類尺度
定類尺度主要包含文字和類別資料,比如姓名、訂單號、產品類別、發貨地址等,這類資料通常是字串格式,無法參與加減乘除這類數學運算,
兩種數學運算可能適合定類尺度——等式運算和包含運算,比如我們可以比較幾個訂單的發貨地址是否相同,或者產品是否隸屬于某個大類之下,
有些資料雖然可以用數字表示,但仍然屬于定類尺度,比如電話號碼,對電話號進行加減乘除和除了等式之外的大小比較都是毫無意義的,
很明顯,定類尺度無法使用均值、中位數,但是可以通過統計的方式計算定類尺度資料的眾數,因此定類尺度的測度中心是資料的眾數,
(關于中位數和眾數,可參考 關于平均數)
定序尺度
定類尺度資料無法按照自然屬性排序,而定序尺度資料可以支持大小比較運算,從而對資料進行排序,這里的排序,指對資料進行大小比較是有意義的前提下進行的排序,而不是指程式上的asc和desc,
定序尺度不能進行乘除運算,這容易理解,但是很多數資料上說定序尺度不能進行加減法運算(減法和加法是一回事,a-b相當于a+(-b)),并把這一點作為判斷定序尺度的依據,這就不容易理解了,需要換一種容易判定的方式,
我們經常看到企業的人員的學歷統計圖:
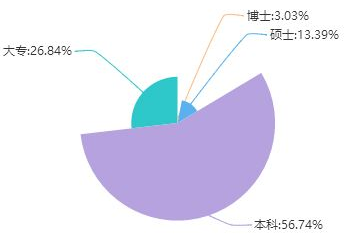
上圖是某個互聯網公司的人員學歷,分為大專、本科、博士、碩士4個等級,可以編號為1、2、3、4,學歷的排序是有意義的,但是學歷相減呢?或許也是有意義的,3-1=2,4-2=2,兩個2都表示學歷的等級差,但這個等級差是否有用就值得商榷了,你能馬上聯想到什么地方需要這個差值嗎?因此我們說,判斷定序尺度的依據之一是:資料并不一定是不能相減,只是相減后的差值很少有(或根本沒有)明確的用途,另一個依據是,定序尺度通常用中位數而不是均值作為測度中心,上圖的中位數是2,表示本科占了大多數;而均值可能是2.1,它并沒有一個明確的類別,因此HR在介紹時會說:“我們公司的平均學歷是本科”,而不是說:“我們公司的平均學歷比本科高那么一丟丟,
定距尺度
定距尺度除了具備定序尺度的特征外,還可以進行有意義的加減法運算,
上海近20年11月份的平均氣溫、某個企業員工的年齡,這些都是定距尺度,兩個定距尺度的差是有意義的,并且很常用:去年11月的平均氣溫比今年高了2℃,老李比小王大10歲,顯然,定距尺度資料可以使用均值作為測度中心,
對于給定的資料集來說,我們往往想了解資料的波動性,此時需要用到標準差:
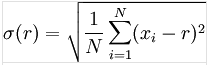
其中r是均值,N是資料總量,
下表示2個射擊運動員5輪射擊后的資料:

均值是都9.5,似乎而二者實力相當,但通過觀察資料會發現,甲是發揮型選手,成績波動較大,可以打出“超級環”,也會打出大失水準的“低級環”;相反,乙的發揮比較穩定,總是與平均成績接近,
每一次射擊的成績均會產生波動,用每一次射擊的得分減去平均成績表示本次波動,得到了下面的資料:

現在可以計算出二人的總體波動了:
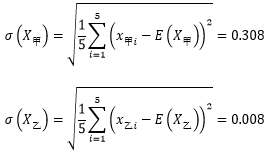
可以看出,乙的波動遠遠小于甲的波動,說明乙的穩定性更高,
關于標準差和資料波動的更多資訊,可參考:方差、均方差和協方差
能否使用標準差也可以作為定序尺度和定距尺度的參考判定依據之一,對于人類的智商來說,平均智商通常使用中位數,而且計算智商的波動是沒有意義的,因此智商屬于定序尺度,當然,智商也許會出現波動,比如看見美女智商下降70%,但這屬于玄學問題了,
定比尺度
定比尺度資料是最牛的一種,處理定距尺度的特性外,還可以進行乘除運算,同時還具有絕對或自然的起點,即存在可以作為比較的共同起點或基數,
收入和存款是典型定比尺度,我們經常說某某的收入是自己的2倍,
定比尺度和定距尺度也很微妙,關鍵還是看乘除法是否有明確的意義,比如考試分數,0分可以作為自然的起點,但是我們通常直說A比B高了30分,而不說A比B的分數高一倍,因此分數是用來確定兩人之間的距離的,而不是比例,我家的面積是100平米,同學家是200平米,同學家比我家的面積大一倍,面積是定比尺度,
作者:我是8位的
出處:https://mp.weixin.qq.com/s/XJROL6iAFZ5XuFNq4WT86g
本文以學習、研究和分享為主,如需轉載,請聯系本人,標明作者和出處,非商業用途!
掃描二維碼關注作者公眾號“我是8位的”

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/5158.html
標籤:其他
上一篇:讀書筆記——如何閱讀一本書
下一篇:程式設計入門