Notation:
m=number of training examples
n=number of features
x="input" variables / features
y="output"variable/"target" variable
\((x^{(i)},y^{(i)})\) = the ith trainging example
\(h_\theta\) = fitting function
一、梯度下降法(Gradient Descent)(主要)
其中\(h_\theta(x)=\theta_0+\theta_1x_1+...+\theta_nx_n=\sum_{i=0}^{n}{\theta_ix_i}=\theta^T\)
假設損失函式為\(J(\theta)=\frac{1}{2}\sum_{i=1}^{m}{(h_\theta(x)-y)^2}\) , To minimize the \(J(\theta)\)
main idea: Initalize \(\theta\) (may \(\theta=\vec{0}\)) ,then keep changing \(\theta\) to reduce \(J(\theta)\) ,untill minimum
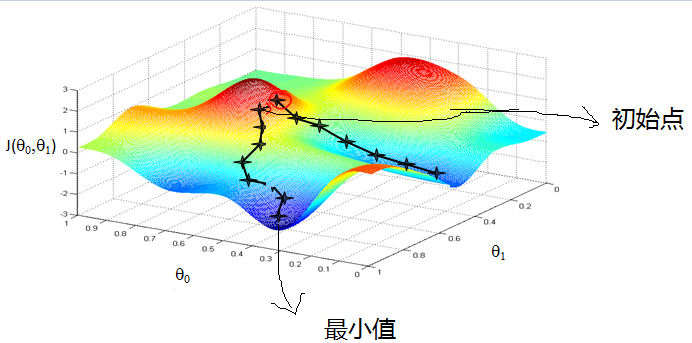
Gradient decent:
只有一個樣本時,對第i個引數進行更新 \(\theta_i:=\theta_i-\alpha\frac{\partial }{\partial \theta_i}J(\theta)=\theta_i-\alpha(h_\theta(x)-y)x_i\)
Repeat until convergence(收斂):
{
\(\theta_i:=\theta_i-\alpha\sum_{j=1}^{m}(h_\theta(x^{(j)})-y^{j})x_i^{(j)}\) ,(for every i)
}
矩陣描述(簡單):
Repeat until convergence(收斂):
{
\(\theta:=\theta -\nabla_\theta J\)
}
IF \(A\epsilon R^{n*n}\)
? tr(A)=\(\sum_{i=1}^nA_{ii}\) :A的跡
\(J(\theta)=\frac{1}{2}(X\theta - \vec{y})^T(X\theta - \vec{y})\)
\(\nabla_\theta J=\frac{1}{2}\nabla_\theta (\theta^TX^TX\theta-\theta^TX^Ty-y^Tx\theta+y^Ty) =X^TX\theta-X^Ty\)
備注:
當目標函式是凸函式時,梯度下降法的解才是全域最優解
二、隨機梯度下降(Stochastic Gradient Descent )
Repeat until convergence:
{
? for j=1 to m{
? \(\theta_i:=\theta_i-\alpha(h_\theta(x^{(j)})-y^{j})x_i^{(j)}\) ,for every i
? }
}
備注:
1.訓練速度很快,每次僅僅采用一個樣本來迭代;
2.解可能不是最優解,僅僅用一個樣本決定梯度方向;
3.不能很快收斂,迭代方向變化很大,
三、mini-batch梯度下降
Repeat until convergence:
{
? for j=1 to m/n{
? \(\theta_i:=\theta_i-\alpha\sum_{j=1}^{n}(h_\theta(x^{(j)})-y^{j})x_i^{(j)}\) ,for every i
? }
}
備注:
機器學習中往往采用該演算法
參考地址:
https://www.cnblogs.com/pinard/p/5970503.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/51603.html
標籤:其他