- 摘要
- 1,介紹
- 2,高效網路設計的影響因素
- 2.1,記憶體訪問代價
- 2.2,GPU計算效率
- 3,建議的方法
- 3.1,重新思考密集連接
- 3.2,One-Shot Aggregation
- 3.3,構建 VoVNet 網路
- 4,實驗
- 5,代碼解讀
- 參考資料
摘要
Youngwan Lee*作者于2019年發表的論文 An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection. 是對DenseNet網路推理效率低的改進版本,
因為 DenseNet 通過用密集連接,來聚合具有不同感受野大小的中間特征,因此它在物件檢測任務上表現出良好的性能,雖然特征重用(feature reuse)的使用,讓 DenseNet 以少量模型引數和 FLOPs,也能輸出有力的特征,但是使用 DenseNet 作為 backbone 的目標檢測器卻表現出了運行速度慢和效率低下的弊端,作者認為是密集連接(dense connection)帶來的輸入通道線性增長,從而導高記憶體訪問成本和能耗,為了提高 DenseNet 的效率,作者提出一個新的更高效的網路 VoVet,由 OSA(One-Shot Aggregation,一次聚合)組成,OSA 僅在模塊的最后一層聚合前面所有層的特征,這種結構不僅繼承了 DenseNet 的多感受野表示多種特征的優點,也解決了密集連接效率低下的問題,基于 VoVNet 的檢測器不僅速度比 DenseNet 快 2 倍,能耗也降低了 1.5-4.1 倍,另外,VoVNet 網路的速度和效率還優于 ResNet,并且其對于小目標檢測的性能有了顯著提高,
1,介紹
隨著 CNN 模型:VGG、ResNet 和 DensNet 的巨大進步,它們開始被廣泛用作目標檢測器的 backbone,用來提取影像特征,
ResNet 和 DenseNet 主要的區別在于它們聚合特征的方式,ResNet 是通過逐元素相加(element-wise add)和前面特征聚合,DenseNet 則是通過拼接(concatenation)的方式,Zhu 等人在論文32 中認為前面的特征圖攜帶的資訊將在與其他特征圖相加時被清除,換句話說,通過 concatenation 的方式,早期的特征才能傳遞下去,因為它保留了特征的原始形式(沒有改變特征本身),
最近的一些作業 [25, 17, 13] 表明具有多個感受野的抽象特征可以捕捉各種尺度的視覺資訊,因為檢測任務比分類更加需要多樣化尺度去識別物件,因此保留來自各個層的資訊對于檢測尤為重要,因為網路每一層都有不同的感受野,因此,在目標檢測任務上,DenseNet 比 ResNet 有更好更多樣化的特征表示,
這是不是說明對于,多標簽分類問題,用 VoVNet 作為 backbone,效果要比 ResNet 要好,因為前者可以實作多感受野表示特征,
盡管使用 DenseNet 的檢測器的引數量和 FLOPs 都比 ResNet 小,但是前者的能耗能耗和速度卻更慢,這是因為,還有其他因素 FLOPs 和模型尺寸(引數量)影響能耗,
首先,記憶體訪問代價 MAC 是影響能耗的關鍵因素,如圖 1(a) 所示,因為 DenseNet 中的所有特征圖都被密集連接用作后續層的輸入,因此記憶體訪問成本與網路深度成二次方增加,從而導致計算開銷和更多的能耗,
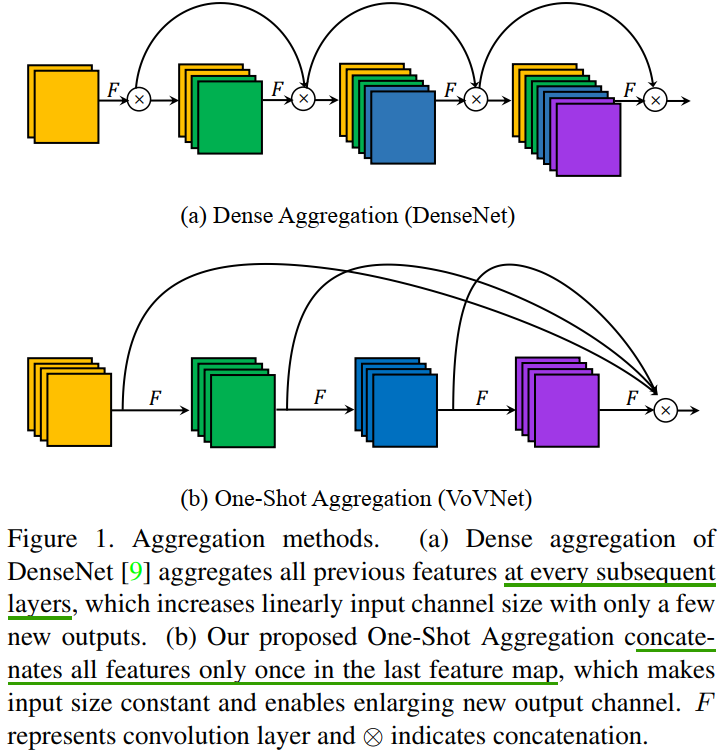
從圖 (a) 中可以看出,DenseBlock 中的每一層的輸入都是前面所有層 feature map 的疊加,而圖 (b)只有最后一層的輸入是前面所有層 feature map 的疊加,
其次,關于 GPU 的并行計算,DenseNet 有計算瓶頸的限制,一般來說,當操作的張量更大時,GPU 的并行利用率會更高[19,29,13],
然而,由于為了線性增加輸入通道,需要 DenseNet 采用 1×1 卷積 bottleneck 架構來減少輸入維度和 FLOPs,這導致使用較小的運算元張量增加層數,作為結果就是 GPU 計算變得低效,總結就是,bottleneck 結構中的 \(1\times 1\) 卷積會導致 GPU 并行利用率,
本文的目的在于將 DenseNet 改進的更高效,同時,還保留對目標檢測有益的連接聚合(concatenative aggregation)操作,
作者認為 DenseNet 網路 DenseBlock 中間層的密集連接(
dense connections)會導致網路效率低下,并假設相應的密集連接是多余的,
作者使用 OSA 模塊構建了 VoVNet 網路,為了驗證有效性,將其作為 DSOD、RefineDet 和 Mask R-CNN 的 backbone 來做對比實驗,實驗結果表明,基于 VoVNet 的檢測器優于 DenseNet 和 ResNet,速度和能耗都更優,
2,高效網路設計的影響因素
作者認為,MobileNet v1 [8], MobileNet v2 [21], ShuffleNet v1 [31], ShuffleNet v2 [18], and Pelee 模型主要是通過使用 DW 卷積和 帶 \(1\times 1\) 卷積的 bottleneck 結構來減少 FLOPs 和模型尺寸(引數量),
這里我覺得作者表達不嚴謹,因為 shufflenetv2 在論文中已經宣告過,FLOPs 和模型引數量不是模型運行速度的唯一決定因素,
實際上,減少 FLOPs 和模型大小并不總能保證減少 GPU 推理時間和實際能耗,典型的例子就是 DenseNet 和 ResNet 的對比,還有就是在 GPU 平臺上, Shufflenetv2 在同等引數條件下,運行速度比 MobileNetv2 更快,這些現象告訴我們,FLOPs 和 模型尺寸(引數)是衡量模型實用性(practicality)的間接指標,為了設計更高效的網路,我們需要使用直接指標 FPS,除了上面說的 FLOPs 和模型引數量會影響模型的運行速度(FPS),還有以下幾個因素,
2.1,記憶體訪問代價
這個 Shufflenetv2 作者已經解釋得很清楚了,本文的作者的描述基本和 Shufflenetv2 一致,我這里直接給結論:
MAC對能耗的影響超過了計算量FLOPs[28],- 卷積層輸入輸出通道數相等時,
MAC取得最小值, - 即使模型引數量一致,只要 MAC 不同,那么模型的運行時間也是不一致的(ShuffleNetv2 有實驗證明),
論文 [28] Designing energy-efficient convolutional neural networks using energyaware pruning.
2.2,GPU計算效率
其實這個內容和 shufflenetv2 論文中的 G3 原則(網路碎片化會降低 GPU 并行度)基本一致,
為提高速度而降低 FLOPs 的網路架構基于這樣一種理念,即設備中的每個浮點運算都以相同的速度進行處理,但是,當模型部署在 GPU 上時,不是這樣的,因為 GPU 是并行處理機制能同時處理多個浮點運算行程,我們用 GPU 計算效率來表示 GPU 的運算能力,
- 通過減少
FLOPs是來加速的前提是,設備中的每個浮點運算都以相同的速度進行處理; - GPU 特性:
- 擅長
parallel computation,tensor越大,GPU使用效率越高, - 把大的卷積操作拆分成碎片的小操作將不利于
GPU計算,
- 擅長
- 因此,設計
layer數量少的網路是更好的選擇,MobileNet使用額外的 1x1 卷積來減少計算量,不過這不利于 GPU 計算, - 為了衡量 GPU 利用率,引入有一個新指標:\(FLOP/s = \frac{FLOPs}{GPU\ inference\ time}\)(每秒完成的計算量
FLOPs per Second),FLOP/s 高,則GPU利用率率也高,
3,建議的方法
3.1,重新思考密集連接
1,DenseNet 的優點:
在計算第 \(l\) 層的輸出時,要用到之前所有層的輸出的 concat 的結果,這種密集的連接使得各個層的各個尺度的特征都能被提取,供后面的網路使用,這也是它能得到比較高的精度的原因,而且密集的連接更有利于梯度的回傳(ResNet shorcut 操作的加強版),
2,DenseNet 缺點(導致了能耗和推理效率低的):
- 密集連接會增加輸入通道大小,但輸出通道大小保持不變,導致的輸入和輸出通道數都不相等,因此,DenseNet 具有具有較高的 MAC,
- DenseNet 采用了
bottleneck結構,這種結構將一個 \(3\times 3\) 卷積分成了兩個計算(1x1+3x3 卷積),這帶來了更多的序列計算(sequential computations),導致會降低推理速度,
密集連接會導致計算量增加,所以不得不采用 \(1\times 1\) 卷積的
bottleneck結構,
圖 7 的第 1 行是 DenseNet 各個卷積層之間的相互關系的大小,第 \((s,l)\) 塊代表第 \(s\) 層和第 \(l\) 層之間這個卷積權值的平均 \(L_1\) 范數(按特征圖數量歸一化后的 L1 范數)的大小,也就相當于是表征 \(X_s\) 和 \(X_l\) 之間的關系,
圖 2. 訓練后的 DenseNet(頂部) 和 VoVNet(中間和底部) 中卷積層的濾波器權重的絕對值的平均值,像素塊的顏色表示的是相互連接的網路層(i, j)的權重的平均 \(L_1\) 范數(按特征圖數量歸一化后的 L1 范數)的值,OSA Module (x/y) 指的是 OSA 模塊由 \(x\) 層和 \(y\) 個通道組成,
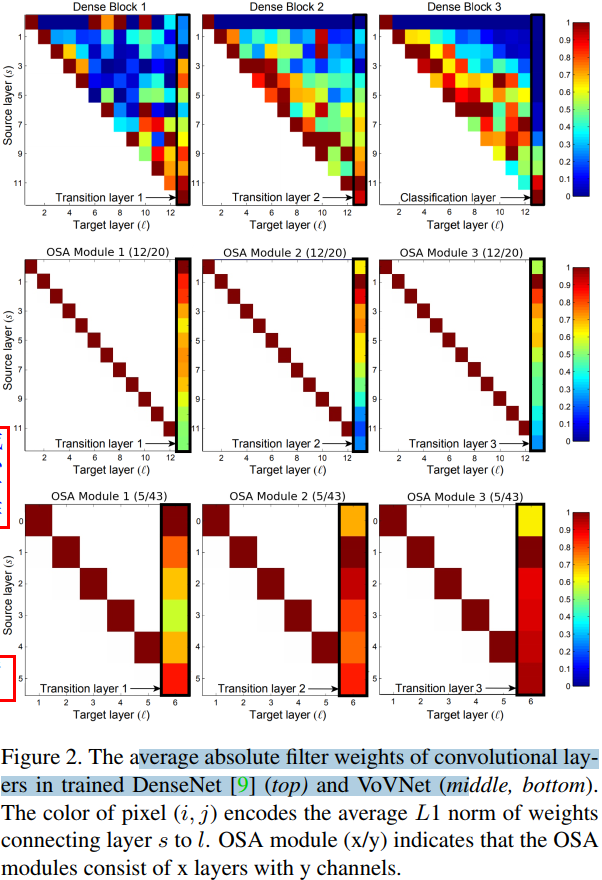
如圖 2 頂部圖所示, Hu 等人[9]通過評估每層輸入權重歸一化后的 L1 范數來說明密集連接的連通性(connectivity),這些值顯示了前面所有層對相應層的歸一化影響,1 表示影響最大,0 表示沒有影響(兩個層之間的權重沒有關系),
這里重點解釋下連通性的理解,兩層之間的輸入權重的絕對值相差越大,即 L1 越大,那么說明卷積核的權重越不一樣,前面層對后面層影響越大(
connectivity),即連通性越好(大),從實用性角度講,我們肯定希望相互連接的網路層的連通性越大越好(歸一化后是 0~1 范圍),這樣我的密集連接才起作用了嘛,不然,耗費了計算量、犧牲了效率,但是連通性結果又差,那我還有必要設計成密集連接(dense connection),作者通過圖 2 后面的兩張圖也證明了DenseBlock 模塊中各個層之間的聯系大部分都是沒用,只有少部分是有用的,即密集連接中大部分網路層的連接是無效的,
在 Dense Block3 中,對角線附近的紅色框表示中間層(intermediate layers)上的聚合處于活動狀態,但是分類層(classification layer)只使用了一小部分中間特征, 相比之下,在 Dense Block1 中,過渡層(transition layer)很好地聚合了其大部分輸入特征,而中間層則沒有,
Dense Block3 的分類層和 Dense Block1 的過渡層都是模塊的最后一層,
通過前面的觀察,我們先假設中間層的聚集強度和最后一層的聚集強度之間存在負相關(中間層特征層的聚合能力越好,那么最后層的聚合能力就越弱),如果中間層之間的密集連接導致了每一層的特征之間存在相關性,則密集連接會使后面的中間層產生更好的特征的同時與前一層的特征相似,則假設成立,在這種情況下,因為這兩種特征代表冗余資訊,所以最后一層不需要學習聚合它們,從而前中間層對最終層的影響變小,
因為最后一層的特征都是通過聚集(aggregated)所有中間層的特征而產生的,所以,我們當然希望中間層的這些特征能夠互補或者相關性越低越好,因此,進一步提出假設,相比于造成的損耗,中間特征層的 dense connection 產生的作用有限,為了驗證假設,我們重新設計了一個新的模塊 OSA,該模塊僅在最后一層聚合塊中其他層的特征(intermediate features),把中間的密集連接都去掉,
3.2,One-Shot Aggregation
為了驗證我們的假設,中間層的聚合強度和最后一層的聚合強度之間存在負相關,并且密集連接是多余的,我們與 Hu 等人進行了相同的實驗,實驗結果是圖 2 中間和底部位置的兩張圖,
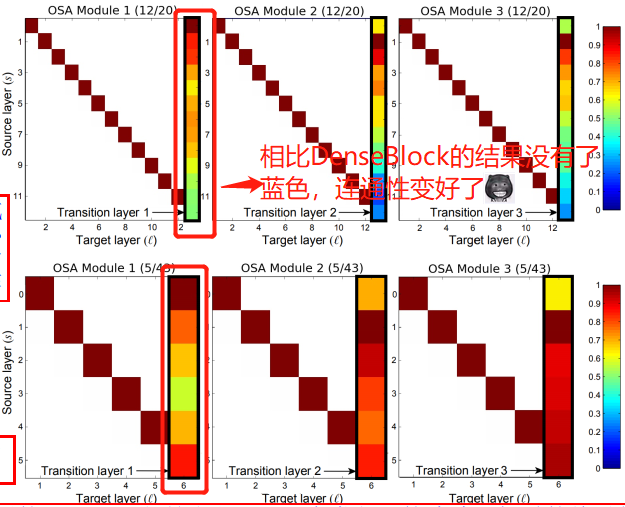
從圖 2(中間)可以觀察到,隨著中間層上的密集連接被剪掉,最終層中的聚合變得更加強烈,同時,藍色的部分 (聯系大部分不緊密的部分) 明顯減少了很多,也就是說 OSA 模塊的每個連接都是相對有用的,
從圖 2(底部)的可以觀察到,OSA 模塊的過渡層的權重顯示出與 DenseNet 不同的模式:來自淺層的特征更多地聚集在過渡層上,由于來自深層的特征對過渡層的影響不大,我們可以在沒有顯著影響的情況下減少 OSA 模塊的層數,得到,令人驚訝的是,使用此模塊(5 層網路),我們實作了 5.44% 的錯誤率,與 DenseNet-40 (模塊里有 12 層網路)的錯誤率(5.24%)相似,這意味著通過密集連接構建深度中間特征的效果不如預期(This implies that building deep intermediate feature via dense connection is less effective than expected),
One-Shot Aggregation(只聚集一次)是指 OSA 模塊的 concat 操作只進行一次,即只有最后一層的輸入是前面所有層 feature map 的 concat(疊加),OSA 模塊的結構圖如圖 1(b) 所示,
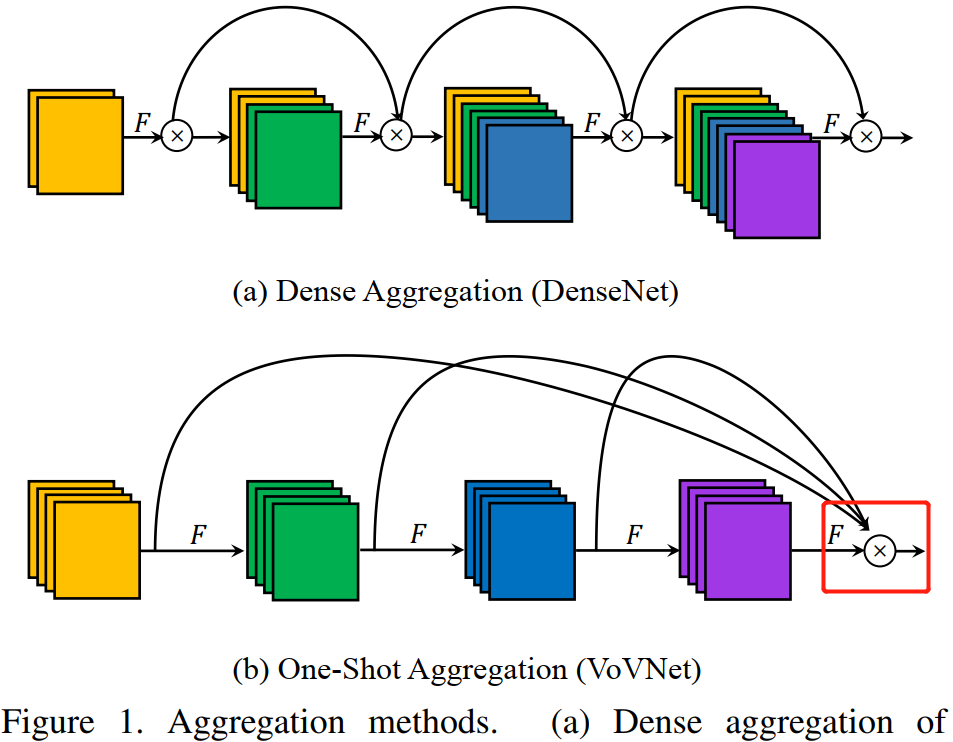
在 OSA 模塊中,每一層產生兩種連接,一種是通過 conv 和下一層連接,產生 receptive field 更大的 feature map,另一種是和最后的輸出層相連,以聚合足夠好的特征,
為了驗證 OSA 模塊的有效性,作者使用 dense block 和 OSA 模塊構成 DenseNet-40網路,使兩種模型引數量一致,做對比實驗,OSA 模板版本在 CIFAR-10 資料集上的精度達到了 93.6,和 dense block 版本相比,只下降了 1.2%,再根據 MAC 的公式,可知 MAC 從 3.7M 減少為 2.5M,MAC 的降低是因為 OSA 中的中間層具有相同大小的輸入輸出通道數,從而使得 MAC 可以取最小值(lower boundary),
因為 OSA 模塊中間層的輸入輸出通道數一致,所以沒必要使用 bottleneck 結構,這又進一步提高了 GPU 利用率,
3.3,構建 VoVNet 網路
因為 OSA 模塊的多樣化特征表示和效率,所以可以通過僅堆疊幾個模塊來構建精度高、速度快的 VoVNet 網路,基于圖 2 中淺層深度更容易聚合的認識,作者認為可以配置比 DenseNet 具有更大通道數的但更少卷積層的 OSA 模塊,
如下圖所示,分別構建了 VoVNet-27-slim,VoVNet-39, VoVNet-57,注意,其中downsampling 層是通過 3x3 stride=2 的 max pooling 實作的,conv 表示的是 Conv-BN-ReLU 的順序連接,
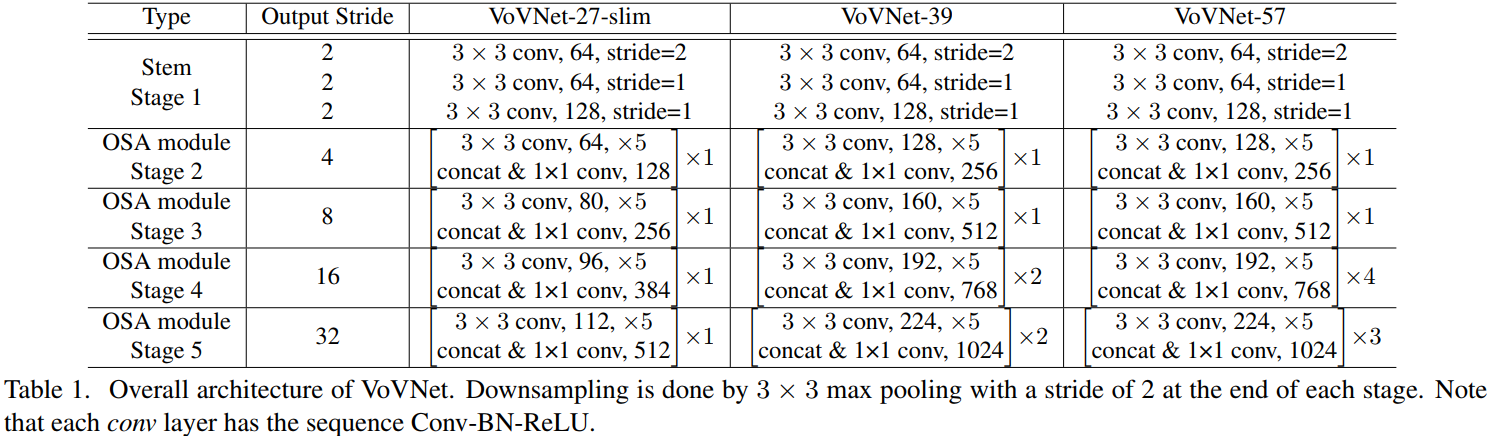
VOVNet 由 5 個階段組成,各個階段的輸出特征大小依次降為原來的一半,VOVNet-27 前 2 個 stage 的連接圖如下所示,

4,實驗
GPU 的能耗計算公式如下:

實驗1: VoVNet vs. DenseNet. 對比不同 backbone 下的目標檢測模型性能(PASCALVOC)
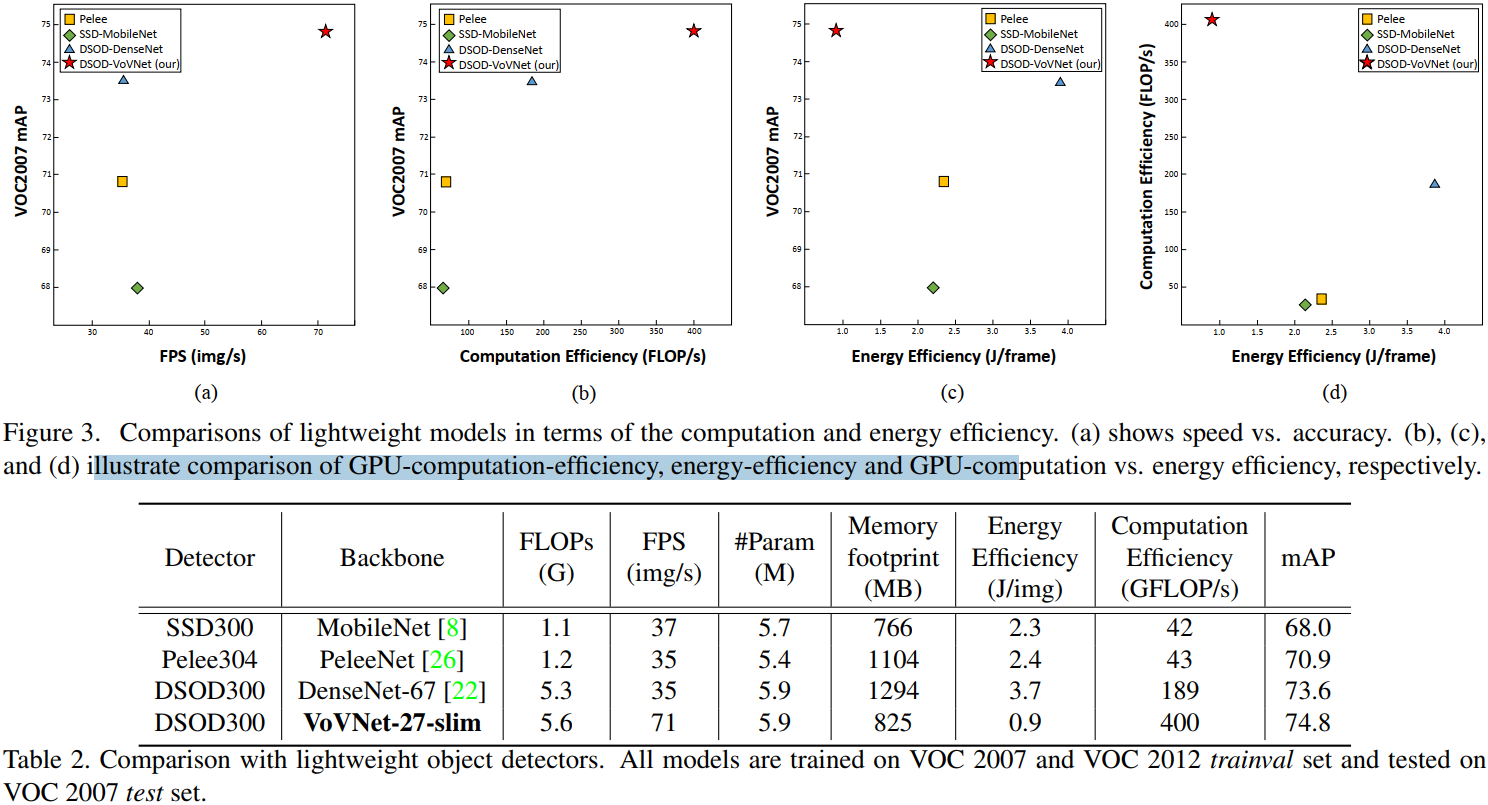
對比指標:
- Flops:模型需要的計算量
- FPS:模型推斷速度img/s
- Params:引數數量
- Memory footprint:記憶體占用
- Enegry Efficiency:能耗
- Computation Efficiency:GPU 計算效率(GFlops/s)
- mAP(目標檢測性能評價指標)
現象與總結:
- 現象 1:相比于 DenseNet-67,PeleeNet 減少了 Flops,但是推斷速度沒有提升,與之相反,VoVNet-27-slim 稍微增加了Flops,而推斷速度提升了一倍,同時,VoVNet-27-sli m的精度比其他模型都高,
- 現象 2:VoVNet-27-slim 的記憶體占用、能耗、GPU 利用率都是最高的,
- 結論 1:相比其他模型,VoVNet做到了準確率和效率的均衡,提升了目標檢測的整體性能,
實驗2:Ablation study on 1×1 conv bottleneck.
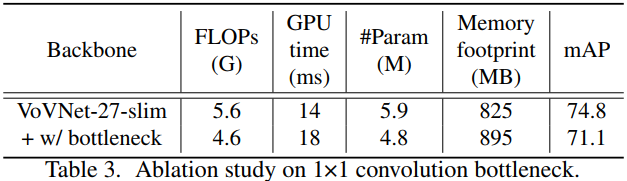
結論 2:可以看出,1x1 bottleneck 增加了 GPU Inference 時間,降低了 mAP,盡管它減少了引數數量和計算量,
因為 1x1 bottleneck 增加了網路的總層數,需要更多的激活層,從而增加了記憶體占用,
實驗3: GPU-Computation Efficiency.
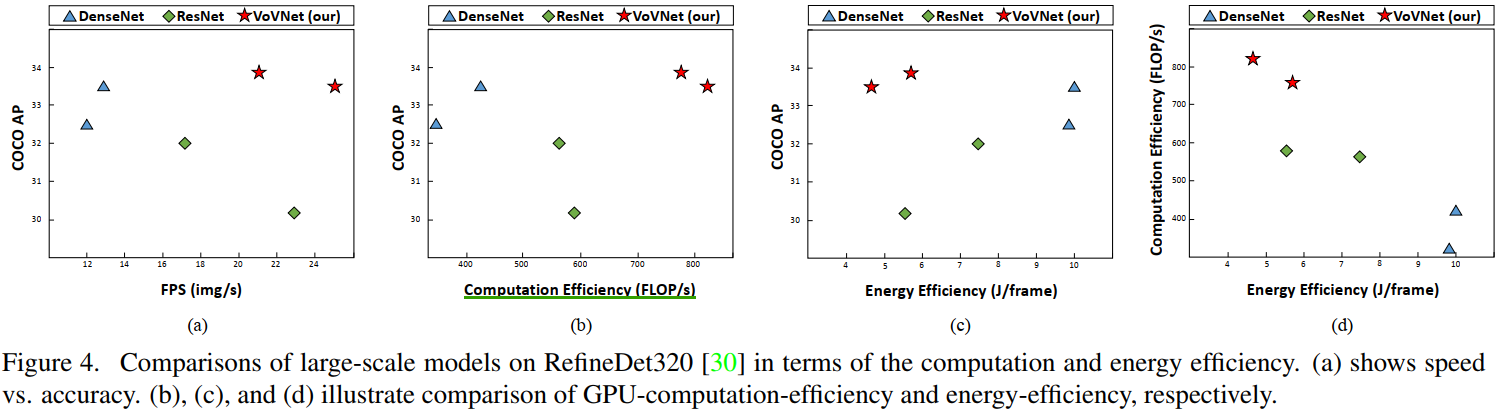
- 圖3(a) VoVNet 兼顧準確率和 Inference 速度
- 圖3(b) VoVNet 兼顧準確率和 GPU 使用率
- 圖3(c) VoVNet 兼顧準確率和能耗
- 圖3(d) VoVNet 兼顧能耗和 GPU 使用率
實驗室4:基于RefineDet架構比較VoVNet、ResNet和DenseNet,
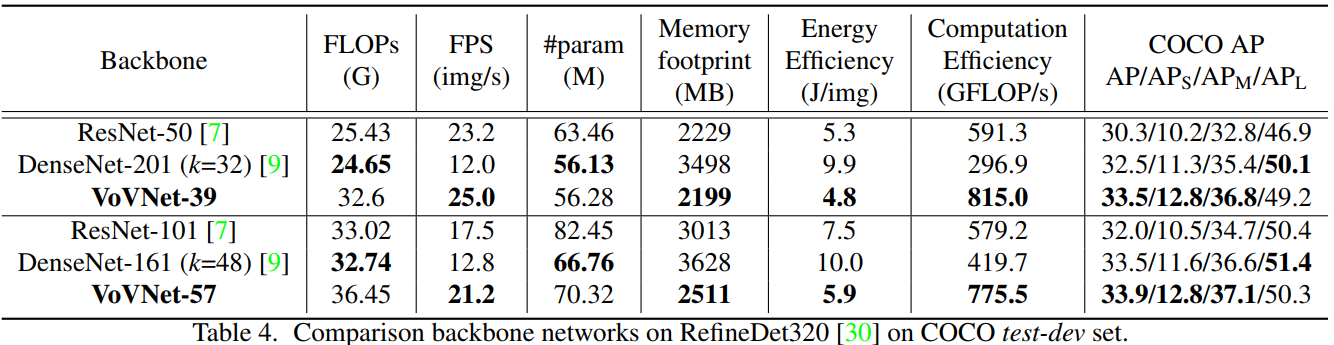
結論 4:從 COCO 資料集測驗結果看,相比于 ResNet,VoVnet在 Inference 速度,記憶體占用,能耗,GPU 使用率和準確率上都占據優勢,盡管很多時候,VoVNet 需要更多的計算量以及引數量,
- 對比 DenseNet161(k=48) 和 DenseNet201(k=32)可以發現,深且”瘦“的網路,GPU 使用率更低,
- 另外,作者發現相比于 ResNet,VoVNet 在小目標上的表現更好,
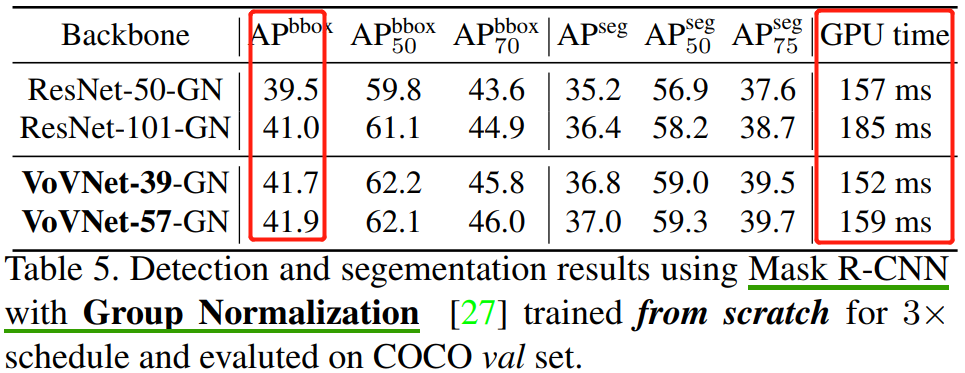
實驗 5:Mask R-CNN from scratch.
通過替換 Mask R-CNN 的 backbone,也發現 VoVNet 在Inference 速度和準確率上優于 ResNet,
5,代碼解讀
雖然 VoVNet 在 CenterMask 論文 中衍生出了升級版本 VoVNetv2,但是本文的代碼解讀還是針對原本的 VoVNet,代碼來源這里,
1,定義不同型別的卷積函式
def conv3x3(in_channels, out_channels, module_name, postfix,
stride=1, groups=1, kernel_size=3, padding=1):
"""3x3 convolution with padding. conv3x3, bn, relu的順序組合
"""
return [
('{}_{}/conv'.format(module_name, postfix),
nn.Conv2d(in_channels, out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False)),
('{}_{}/norm'.format(module_name, postfix),
nn.BatchNorm2d(out_channels)),
('{}_{}/relu'.format(module_name, postfix),
nn.ReLU(inplace=True)),
]
def conv1x1(in_channels, out_channels, module_name, postfix,
stride=1, groups=1, kernel_size=1, padding=0):
"""1x1 convolution"""
return [
('{}_{}/conv'.format(module_name, postfix),
nn.Conv2d(in_channels, out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False)),
('{}_{}/norm'.format(module_name, postfix),
nn.BatchNorm2d(out_channels)),
('{}_{}/relu'.format(module_name, postfix),
nn.ReLU(inplace=True)),
]
2,其中 OSA 模塊結構的代碼如下,
class _OSA_module(nn.Module):
def __init__(self,
in_ch,
stage_ch,
concat_ch,
layer_per_block,
module_name,
identity=False):
super(_OSA_module, self).__init__()
self.identity = identity # 默認不使用恒等映射
self.layers = nn.ModuleList()
in_channel = in_ch
# stage_ch: 每個 stage 內部的 channel 數
for i in range(layer_per_block):
self.layers.append(nn.Sequential(
OrderedDict(conv3x3(in_channel, stage_ch, module_name, i))))
in_channel = stage_ch
# feature aggregation
in_channel = in_ch + layer_per_block * stage_ch
# concat_ch: 1×1 卷積輸出的 channel 數
# 也從 stage2 開始,每個 stage 最開始的輸入 channnel 數
self.concat = nn.Sequential(
OrderedDict(conv1x1(in_channel, concat_ch, module_name, 'concat')))
def forward(self, x):
identity_feat = x
output = []
output.append(x)
for layer in self.layers: # 中間所有層的順序連接
x = layer(x)
output.append(x)
# 最后一層的輸出要和前面所有層的 feature map 做 concat
x = torch.cat(output, dim=1)
xt = self.concat(x)
if self.identity:
xt = xt + identity_feat
return xt
3,定義 _OSA_stage,每個 stage 有多少個 OSA 模塊,由 _vovnet 函式的 block_per_stage 引數指定,
class _OSA_stage(nn.Sequential):
"""
in_ch: 每個 stage 階段最開始的輸入通道數(feature map 數量)
"""
def __init__(self,
in_ch,
stage_ch,
concat_ch,
block_per_stage,
layer_per_block,
stage_num):
super(_OSA_stage, self).__init__()
if not stage_num == 2:
self.add_module('Pooling',
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True))
module_name = f'OSA{stage_num}_1'
self.add_module(module_name,
_OSA_module(in_ch,
stage_ch,
concat_ch,
layer_per_block,
module_name))
for i in range(block_per_stage-1):
module_name = f'OSA{stage_num}_{i+2}'
self.add_module(module_name,
_OSA_module(concat_ch,
stage_ch,
concat_ch,
layer_per_block,
module_name,
identity=True))
4,定義 VOVNet,
class VoVNet(nn.Module):
def __init__(self,
config_stage_ch,
config_concat_ch,
block_per_stage,
layer_per_block,
num_classes=1000):
super(VoVNet, self).__init__()
# Stem module --> stage1
stem = conv3x3(3, 64, 'stem', '1', 2)
stem += conv3x3(64, 64, 'stem', '2', 1)
stem += conv3x3(64, 128, 'stem', '3', 2)
self.add_module('stem', nn.Sequential(OrderedDict(stem)))
stem_out_ch = [128]
# vovnet-57,in_ch_list 結果是 [128, 256, 512, 768]
in_ch_list = stem_out_ch + config_concat_ch[:-1]
self.stage_names = []
for i in range(4): #num_stages
name = 'stage%d' % (i+2)
self.stage_names.append(name)
self.add_module(name,
_OSA_stage(in_ch_list[i],
config_stage_ch[i],
config_concat_ch[i],
block_per_stage[i],
layer_per_block,
i+2))
self.classifier = nn.Linear(config_concat_ch[-1], num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.stem(x)
for name in self.stage_names:
x = getattr(self, name)(x)
x = F.adaptive_avg_pool2d(x, (1, 1)).view(x.size(0), -1)
x = self.classifier(x)
return x
5,VoVNet 各個版本的實作,vovnet57 中有 4 個 stage,每個 stage 的 OSP 模塊數目依次是 [1,1,4,3],每個 個 stage 內部對應的通道數都是一樣的,分別是 [128, 160, 192, 224],每個 stage 最后的輸出通道數分別是 [256, 512, 768, 1024],由 concat_ch 引數指定,
所有版本的 vovnet 的 OSA 模塊中的卷積層數都是 5,
def _vovnet(arch,
config_stage_ch,
config_concat_ch,
block_per_stage,
layer_per_block,
pretrained,
progress,
**kwargs):
model = VoVNet(config_stage_ch, config_concat_ch,
block_per_stage, layer_per_block,
**kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model
def vovnet57(pretrained=False, progress=True, **kwargs):
r"""Constructs a VoVNet-57 model as described in
`"An Energy and GPU-Computation Efficient Backbone Networks"
<https://arxiv.org/abs/1904.09730>`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vovnet('vovnet57', [128, 160, 192, 224], [256, 512, 768, 1024],
[1,1,4,3], 5, pretrained, progress, **kwargs)
def vovnet39(pretrained=False, progress=True, **kwargs):
r"""Constructs a VoVNet-39 model as described in
`"An Energy and GPU-Computation Efficient Backbone Networks"
<https://arxiv.org/abs/1904.09730>`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vovnet('vovnet39', [128, 160, 192, 224], [256, 512, 768, 1024],
[1,1,2,2], 5, pretrained, progress, **kwargs)
def vovnet27_slim(pretrained=False, progress=True, **kwargs):
r"""Constructs a VoVNet-39 model as described in
`"An Energy and GPU-Computation Efficient Backbone Networks"
<https://arxiv.org/abs/1904.09730>`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vovnet('vovnet27_slim', [64, 80, 96, 112], [128, 256, 384, 512],
[1,1,1,1], 5, pretrained, progress, **kwargs)
參考資料
- 論文筆記VovNet(專注GPU計算、能耗高效的網路結構)
- An Energy and GPU-Computation Efficient Backbone Network
for Real-Time Object Detection - 實時目標檢測的新backbone網路:VOVNet
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/516389.html
標籤:其他