筆記轉載于GitHub專案:https://github.com/NLP-LOVE/Introduction-NLP
3. 二元語法與中文分詞
上一章中我們實作了塊兒不準的詞典分詞,詞典分詞無法消歧,給定兩種分詞結果“商品 和服 務”以及“商品 和 服務”,詞典分詞不知道哪種更加合理,
我們人類確知道第二種更加合理,只因為我們從小到大接觸的都是第二種分詞,出現的次數多,所以我們判定第二種是正確地選擇,這就是利用了統計自然語言處理,統計自然語言處理的核心話題之一,就是如何利用統計手法對語言建模,這一章講的就是二元語法的統計語言模型,
3.1 語言模型
-
什么是語言模型
模型指的是對事物的數學抽象,那么語言模型指的就是對語言現象的數學抽象,準確的講,給定一個句子 w,語言模型就是計算句子的出現概率 p(w) 的模型,而統計的物件就是人工標注而成的語料庫,
假設構建如下的小型語料庫:
商品 和 服務 商品 和服 物美價廉 服務 和 貨幣每個句子出現的概率都是 1/3,這就是語言模型,然而 p(w) 的計算非常難:句子數量無窮無盡,無法列舉,即便是大型語料庫,也只能“列舉”有限的數百萬個句子,實際遇到的句子大部分都在語料庫之外,意味著它們的概率都被當作0,這種現象被稱為資料稀疏,
句子幾乎不重復,單詞卻一直在重復使用,于是我們把句子表示為單詞串列 \(w=w_1w_2...w_k\) ,每個 \(w_t,t\in[1,k]\) 都是一個單詞,然后定義語言模型:
\[\begin{aligned} p(\boldsymbol{w}) &=p\left(w_{1} w_{2} \cdots w_{k}\right) \\ &=p\left(w_{1} | w_{0}\right) \times p\left(w_{2} | w_{0} w_{1}\right) \times \cdots \times p\left(w_{k+1} | w_{0} w_{1} w_{2} \dots w_{k}\right) \\ &=\prod_{t=1}^{k+1} p\left(w_{t} | w_{0} w_{1} \cdots w_{t-1}\right) \end{aligned} \]
其中,\(w_0=BOS\) (Begin Of Sentence,有時用<s>),\(w_{k+1}=EOS (End Of Sentence,有時也用</s>)\),是用來標記句子收尾的兩個特殊“單詞”,在NLP領域的文獻和代碼中經常出現,
然而隨著句子長度的增大,語言模型會遇到如下兩個問題,
- 資料稀疏,指的是長度越大的句子越難出現,可能統計不到頻次,導致 \(p(w_k|w_1w_2...w_{k-1})=0\),比如 p(商品 和 貨幣)=0,
- 計算代價大,k 越大,需要存盤的 p 就越多,即便用上字典樹索引,依然代價不菲,
-
馬爾可夫鏈與二元語法
為了解決以上兩個問題,需要使用馬爾可夫假設來簡化語言模型,給定時間線上有一串事件順序發生,假設每個事件的發生概率只取決于前一個事件,那么這串事件構成的因果鏈被稱作馬爾可夫鏈,
在語言模型中,第 t 個事件指的是 \(w_t\) 作為第 t 個單詞出現,也就是說,每個單詞出現的概率只取決于前一個單詞:
\[p(w_t|w_0w_1...w_{t-1})=p(w_t|w_{t-1}) \]
基于此假設,式子一下子變短了不少,此時的語言模型稱為二元語法模型:
\[\begin{aligned} p(\boldsymbol{w}) &=p\left(w_{1} w_{2} \cdots w_{k}\right) \\ &=p\left(w_{1} | w_{0}\right) \times p\left(w_{2} | w_{1}\right) \times \cdots \times p\left(w_{k+1} | w_{k}\right) \\ &=\prod_{t=1}^{k+1} p\left(w_{t} | w_{t-1}\right) \end{aligned} \]
由于語料庫中二元連續的重復程度要高于整個句子的重要程度,所以緩解了資料稀疏的問題,另外二元連續的總數量遠遠小于句子的數量,存盤和查詢也得到了解決,
-
n元語法
利用類似的思路,可以得到n元語法的定義:每個單詞的概率僅取決于該單詞之前的 n 個單詞:
\[p(w)=\prod_{t=1}^{k+n-1} p\left(w_{t} | w_{t-n+1} \dots w_{t-1}\right) \]
特別地,當 n=1 時的 n 元語法稱為一元語法 ( unigram);當 n=3 時的 n 元語法稱為三元語法(tigam); n≥4時資料稀疏和計算代價又變得顯著起來,實際工程中幾乎不使用,
-
資料稀疏與平滑策略
對于 n 元語法模型,n 越大,資料稀疏問題越嚴峻,比如上述語料庫中“商品 貨幣”的頻次就為0,一個自然而然的解決方案就是利用低階 n 元語法平滑高階 n 元語法,所謂平滑,就是字面上的意思:使 n 元語法頻次的折線平滑為曲線,最簡單的一種是線性插值法:
\[p\left(w_{t} | w_{t-1}\right)=\lambda p_{\mathrm{ML}}\left(w_{t} | w_{t-1}\right)+(1-\lambda) p\left(w_{t}\right) \]
其中,\(\lambda\in(0,1)\) 為常數平滑因子,通俗理解,線性插值就是劫富濟貧的稅賦制度,其中的 λ 就是個人所得稅的稅率,\(p_{ML}(w_t|w_{t-1})\) 是稅前所得,\(p(w_t)\) 是社會福利, 通過繳稅,高收人(高概率)二元語法的一部分收人 (概率)被移動到社會福利中,而零收入(語料庫統計不到頻次)的一元語法能夠從社會福利中取得點低保金, 不至于餓死,低保金的額度與二元語法掙錢潛力成正比:二元語法中第二個詞詞頻越高,它未來被統計到的概率也應該越高,因此它應該多拿一點,
類似地,一元語法也可以通過線性插值來平滑:
\[p\left(w_{t}\right)=\lambda p_{\mathrm{ML}}\left(w_{t}\right)+(1-\lambda) \frac{1}{N} \]
其中,N 是語料庫總詞頻,
3.2 中文分詞語料庫
語言模型只是一個函式的骨架,函式的引數需要在語料庫上統計才能得到,為了滿足實際工程需要,一個質量高、分量足的語料庫必不可少,以下是常用的語料庫:
- 《人民日報》語料庫 PKU
- 微軟亞洲研究院語料庫 MSR
- 香港城市大學 CITYU(繁體)
- 臺灣中央研究院 AS(繁體)
| 語料庫 | 字符數 | 詞語種數 | 總詞頻 | 平均詞長 |
|---|---|---|---|---|
| PKU | 183萬 | 6萬 | 111萬 | 1.6 |
| MSR | 405萬 | 9萬 | 237萬 | 1.7 |
| AS | 837萬 | 14萬 | 545萬 | 1.5 |
| CITYU | 240萬 | 7萬 | 146萬 | 1.7 |
一般采用MSR作為分詞語料的首選,有以下原因:
- 標注一致性上MSR要優于PKU,
- 切分顆粒度上MSR要優于PKU,MSR的機構名稱不予切分,而PKU拆開,
- MSR中姓名作為一個整體,更符合習慣,
- MSR量級是PKU的兩倍,
3.3 訓練與預測
訓練指的是統計二元語法頻次以及一元語法頻次,有了頻次,通過極大似然估計以及平滑策略,我們就可以估計任意句子的概率分布,即得到了語言模型,這里以二元語法為例:
這里我們選用上面自己構造的小型語料庫:data/dictionnary/my_cws_corpus.txt
代碼請見:code/ch03/ngram_segment.py
步驟如下:
-
加載語料庫檔案并進行詞頻統計,
-
對詞頻檔案生成詞網
詞網指的是句子中所有一元語法構成的網狀結構,是HanLP工程上的概念,比如“商品和服務”這個句子,我們將句子中所有單詞找出來,起始位置(offset)相同的單詞寫作一行:
0:[ ] 1:[商品] 2:[] 3:[和,和服] 4:[服務] 5:[務] 6:[ ]其中收尾(行0和行6)分別對應起始和末尾,詞網必須保證從起點出發的所有路徑都會連通到鐘點房,
詞網有一個極佳的性質:那就是第 i 行的詞語 w 與第 i+len(w) 行的所有詞語相連都能構成二元語法,
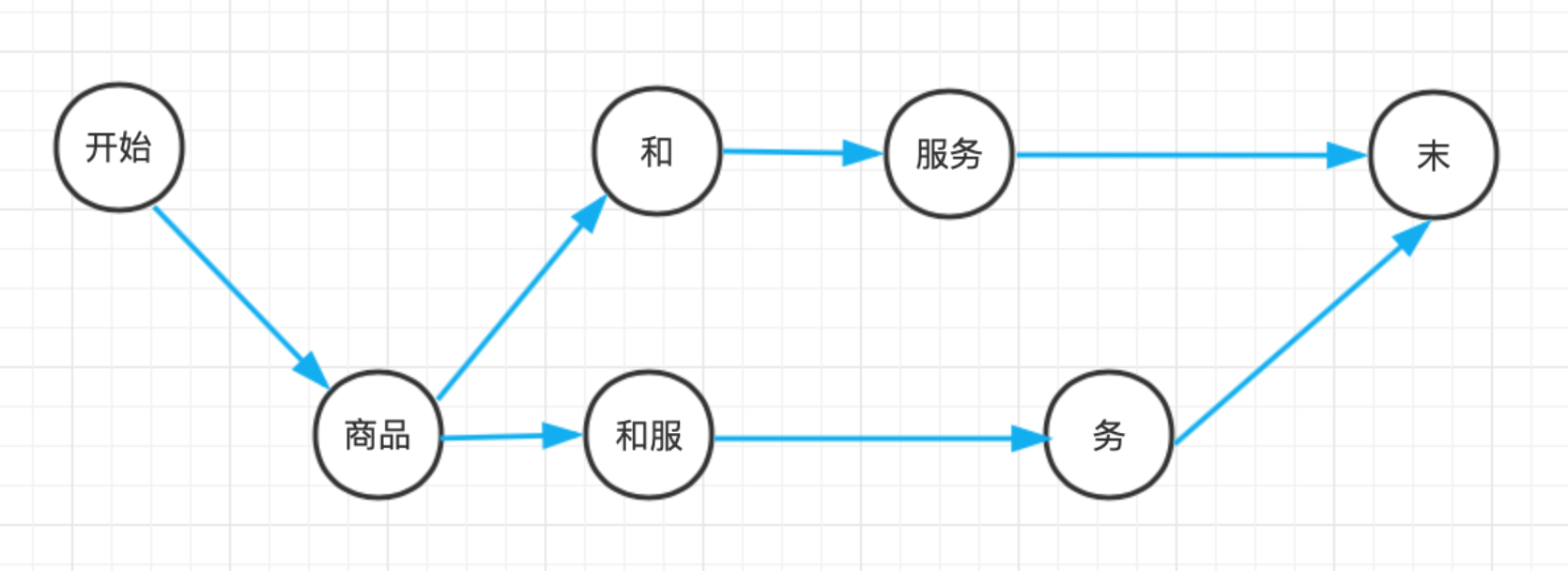
-
詞圖上的維特比演算法
上述詞圖每條邊以二元語法的概率作為距離,那么中文分詞任務轉換為有向無環圖上的最長路徑問題,再通過將浮點數乘法轉化為負對數之間的加法,相應的最長路徑轉化為負對數的最短路徑,使用維特比演算法求解,
這里僅作一下簡述,詳細程序參考書本第三章,
該模型代碼輸入是句子“貨幣和服務”,得到結果如下:
[' ', '貨幣', '和', '服務', ' ']
結果正確,可見我們的二元語法模型具備一定的泛化能力,
3.4 HanLP分詞與用戶詞典的集成
詞典往往廉價易得,資源豐富,利用統計模型的消歧能力,輔以用戶詞典處理新詞,是提高分詞器準確率的有效方式,HanLP支持 2 檔用戶詞典優先級:
- 低優先級:分詞器首先在不考慮用戶詞典的情況下由統計模型預測分詞結果,最后將該結果按照用戶詞典合并,默認低優先級,
- 高優先級:分詞器優先考慮用戶詞典,但具體實作由分詞器子類自行決定,
HanLP分詞器簡潔版:
from pyhanlp import *
ViterbiSegment = SafeJClass('com.hankcs.hanlp.seg.Viterbi.ViterbiSegment')
segment = ViterbiSegment()
sentence = "社會搖擺簡稱社會搖"
segment.enableCustomDictionary(False)
print("不掛載詞典:", segment.seg(sentence))
CustomDictionary.insert("社會搖", "nz 100")
segment.enableCustomDictionary(True)
print("低優先級詞典:", segment.seg(sentence))
segment.enableCustomDictionaryForcing(True)
print("高優先級詞典:", segment.seg(sentence))
輸出:
不掛載詞典: [社會/n, 搖擺/v, 簡稱/v, 社會/n, 搖/v]
低優先級詞典: [社會/n, 搖擺/v, 簡稱/v, 社會搖/nz]
高優先級詞典: [社會搖/nz, 擺/v, 簡稱/v, 社會搖/nz]
可見,用戶詞典的高優先級未必是件好事,HanLP中的用戶詞典默認低優先級,做專案時請讀者在理解上述說明的情況下根據實際需求自行開啟高優先級,
3.5 二元語法與詞典分詞比較
按照NLP任務的一般流程,我們已經完成了語料標注和模型訓練,現在來比較一下二元語法和詞典分詞的評測:
| 演算法 | P | R | F1 | R(oov) | R(IV) |
|---|---|---|---|---|---|
| 最長匹配 | 89.41 | 94.64 | 91.95 | 2.58 | 97.14 |
| 二元語法 | 92.38 | 96.70 | 94.49 | 2.58 | 99.26 |
相較于詞典分詞,二元語法在精確度、召回率及IV召回率上全面勝出,最終F1值提高了 2.5%,成績的提高主要受惠于消歧能力的提高,然而 OOV 召回依然是 n 元語法模型的硬傷,我們需要更強大的語言模型,
3.6 GitHub專案
HanLP何晗--《自然語言處理入門》筆記:
https://github.com/NLP-LOVE/Introduction-NLP
專案持續更新中......
目錄
| 章節 |
|---|
| 第 1 章:新手上路 |
| 第 2 章:詞典分詞 |
| 第 3 章:二元語法與中文分詞 |
| 第 4 章:隱馬爾可夫模型與序列標注 |
| 第 5 章:感知機分類與序列標注 |
| 第 6 章:條件隨機場與序列標注 |
| 第 7 章:詞性標注 |
| 第 8 章:命名物體識別 |
| 第 9 章:資訊抽取 |
| 第 10 章:文本聚類 |
| 第 11 章:文本分類 |
| 第 12 章:依存句法分析 |
| 第 13 章:深度學習與自然語言處理 |
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/51653.html
標籤:其他
下一篇:冬日曙光——回溯CNN的誕生