MobileNet v1 論文詳解
MobileNet論文的主要貢獻在于提出了一種深度可分離卷積架構(DW+PW 卷積),先通過理論證明這種架構比常規的卷積計算成本(Mult-Adds)更小,然后通過分類、檢測等多種實驗證明模型的有效性,
1、相關作業
標準卷積
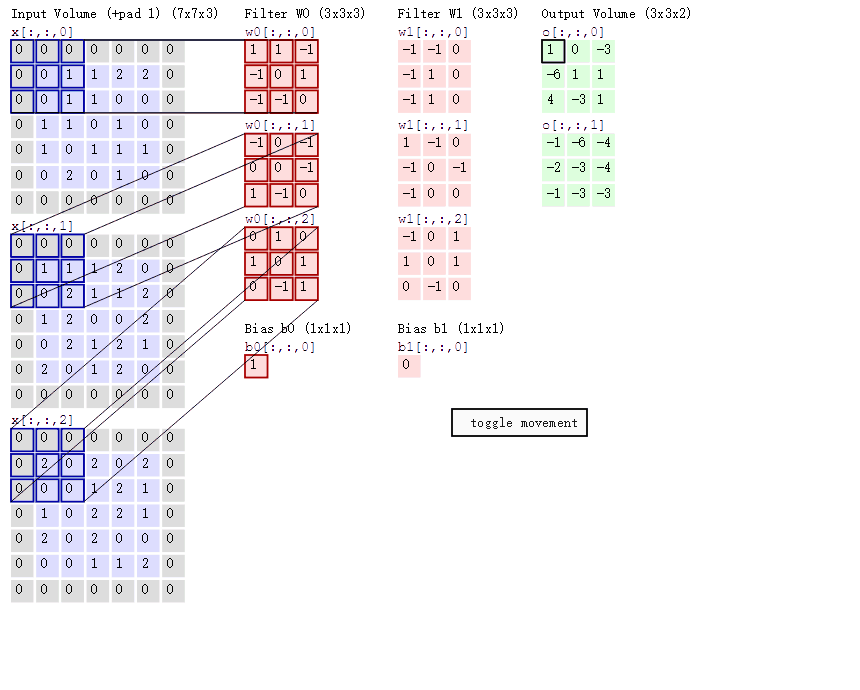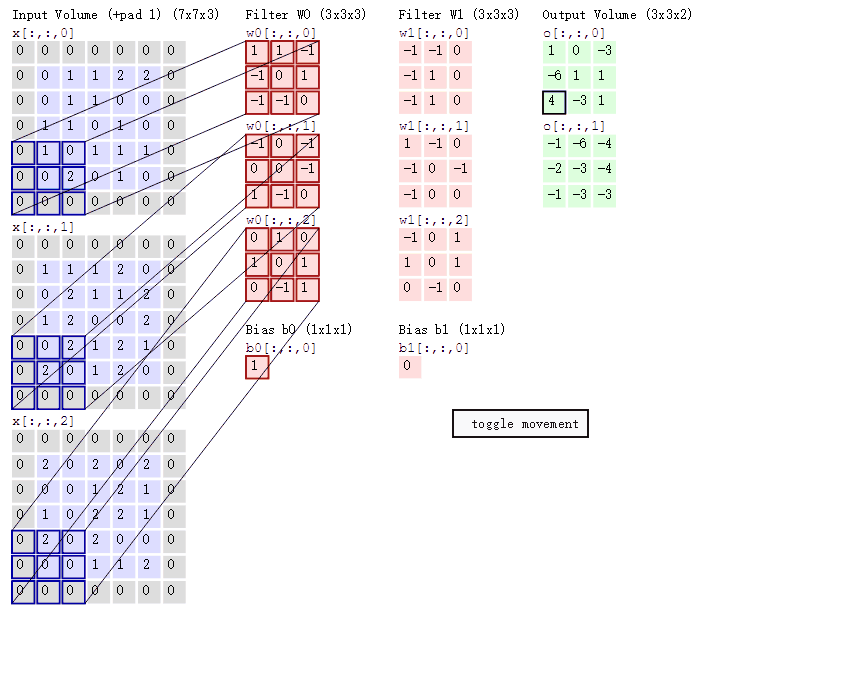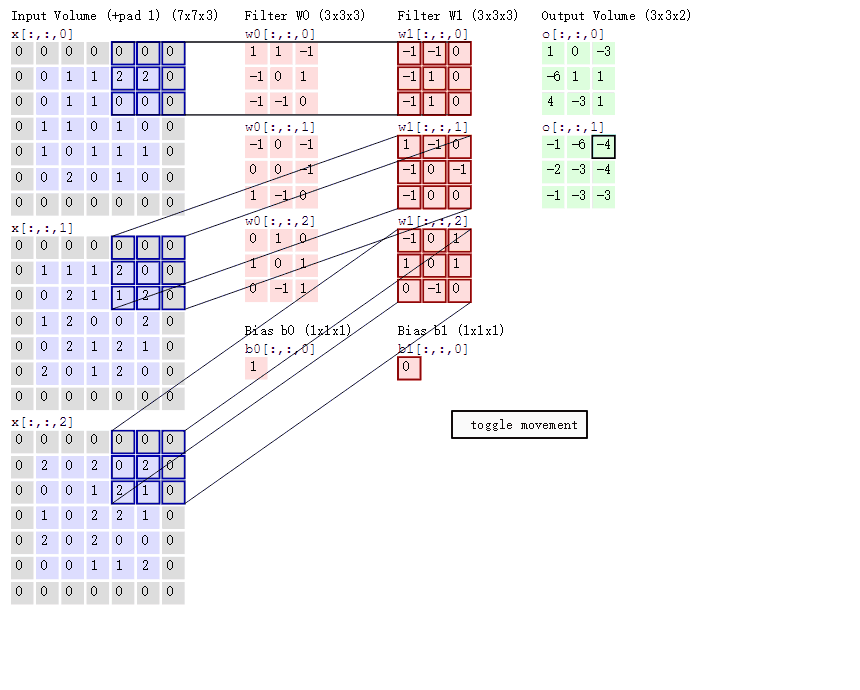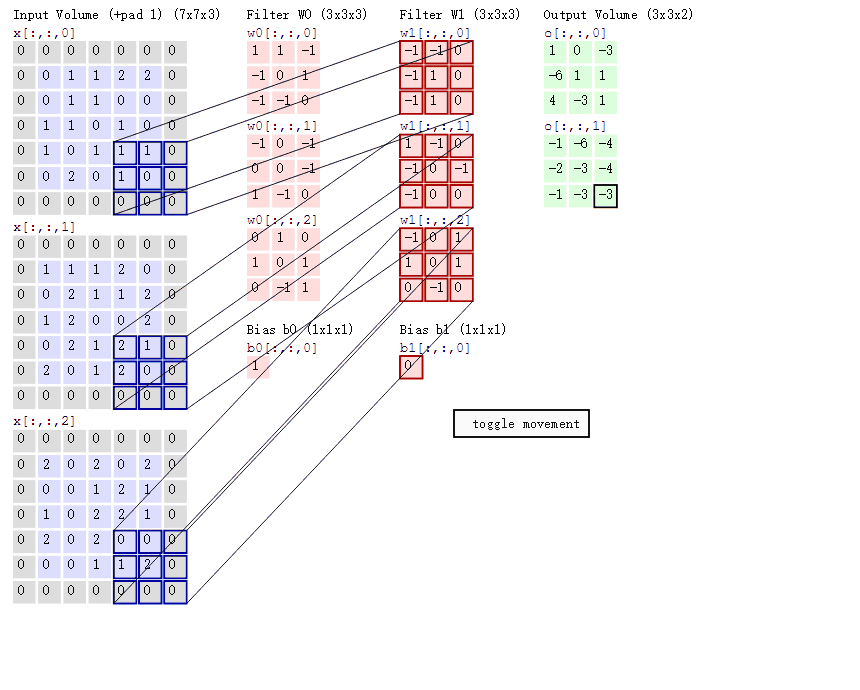
一個大小為 \(h_1\times w_1\) 過濾器(2 維卷積核),沿著 feature map 的左上角移動到右下角,過濾器每移動一次,將過濾器引數矩陣和對應特征圖 \(h_1 \times w_1 \times c_1\) 大小的區域內的像素點相乘后累加得到一個值,又因為 feature map 的數量(通道數)為 \(c_1\),所以我們需要一個 shape 為 $ (c_1, h_1, w_1)$ 的濾波器( 3 維卷積核),將每個輸入 featue map 對應輸出像素點位置計算和的值相加,即得到輸出 feature map 對應像素點的值,又因為輸出 feature map 的數量為 \(c_2\) 個,所以需要 \(c_2\) 個濾波器,標準卷積抽象程序如下圖所示,
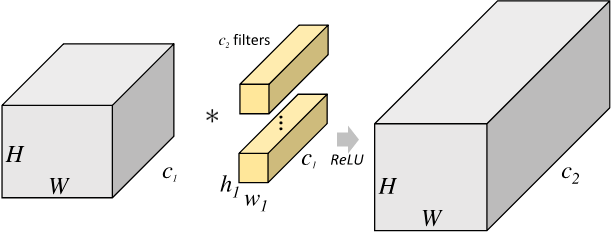
2D 卷積計算程序動態圖如下,通過這張圖能夠更直觀理解卷積核如何執行滑窗操作,又如何相加并輸出 \(c_2\) 個 feature map ,動態圖來源 這里,
分組卷積
Group Convolution 分組卷積,最早見于 AlexNet,常規卷積與分組卷積的輸入 feature map 與輸出 feature map 的連接方式如下圖所示,圖片來自CondenseNet,
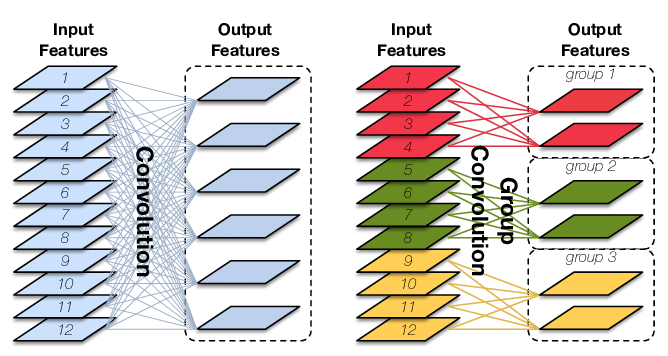
分組卷積的定義:對輸入 feature map 進行分組,然后分組分別進行卷積,假設輸入 feature map 的尺寸為 \(H \times W \times c_{1}\),輸出 feature map 數量為 \(c_2\) 個,如果將輸入 feature map 按通道分為 \(g\) 組,則每組特征圖的尺寸為 \(H \times W \times \frac{c_1}{g}\),每組對應的濾波器(卷積核)的 尺寸 為 \(h_{1} \times w_{1} \times \frac{c_{1}}{g}\),每組的濾波器數量為 \(\frac{c_{2}}{g}\) 個,濾波器總數依然為 \(c_2\) 個,即分組卷積的卷積核 shape 為 \((c_2,\frac{c_1}{g}, h_1,w_1)\),每組的濾波器只與其同組的輸入 map 進行卷積,每組輸出特征圖尺寸為 \(H \times W \times \frac{c_{2}}{g}\),將 \(g\) 組卷積后的結果進行拼接 (concatenate) 得到最終的得到最終尺寸為 \(H \times W \times c_2\) 的輸出特征圖,其分組卷積程序如下圖所示:
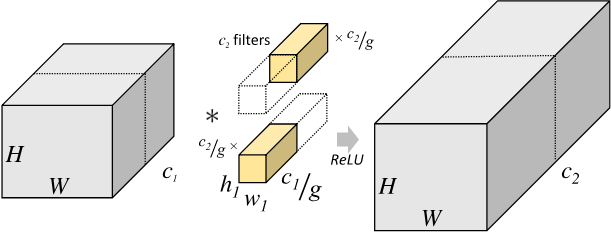
分組卷積的意義:分組卷積是現在網路結構設計的核心,它通過通道之間的稀疏連接(也就是只和同一個組內的特征連接)來降低計算復雜度,一方面,它允許我們使用更多的通道數來增加網路容量進而提升準確率,但另一方面隨著通道數的增多也對帶來更多的 \(MAC\),針對 \(1 \times 1\) 的分組卷積,\(MAC\) 和 \(FLOPs\) 計算如下:
\[\begin{align*} & MACC = H \times W \times 1 \times 1 \times \frac{c_{1}}{g}\frac{c_{2}}{g} \times g = \frac{hwc_{1}c_{2}}{g} \\\\ & FLOPs = 2 \times MACC \\\\ & Params = g \times \frac{c_2}{g}\times\frac{c_1}{g} \times 1\times 1 + c_2 = \frac{c_{1}c_{2}}{g} \\\\ & MAC = HW(c_1 + c_2) + \frac{c_{1}c_{2}}{g} \\\\ \end{align*}\]從以上公式可以得出分組卷積的引數量和計算量是標準卷積的 \(\frac{1}{g}\) 的結論 ,但其實對分組卷積程序進行深入理解之后也可以直接得出以上結論,
分組卷積的深入理解:對于 \(1\times 1\) 卷積,常規卷積輸出的特征圖上,每一個像素點是由輸入特征圖的 \(c_1\) 個點計算得到,而分組卷積輸出的特征圖上,每一個像素點是由輸入特征圖的 $ \frac{c_1}{g}$個點得到(參考常規卷積計算程序),卷積運算程序是線性的,自然,分組卷積的引數量和計算量是標準卷積的 \(\frac{1}{g}\) 了,
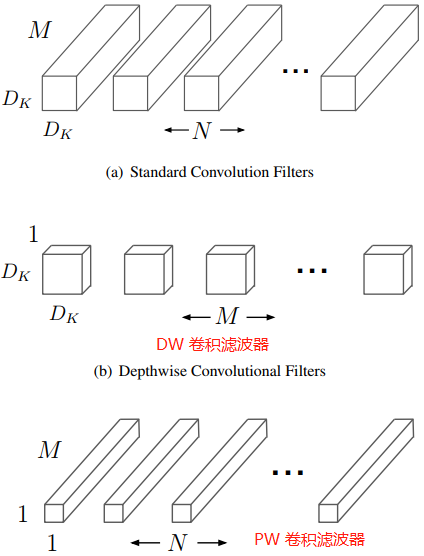
當分組卷積的分組數量 = 輸入 feature map 數量 = 輸出 feature map 數量,即 \(g=c_1=c_2\),有 \(c_1\) 個濾波器,且每個濾波器尺寸為 \(1 \times K \times K\) 時,Group Convolution 就成了 Depthwise Convolution(DW 卷積),DW 卷積的卷積核權重尺寸為 \((c_{1}, 1, K, K)\),
常規卷積的卷積核權重 shape 都為(
C_out, C_in, kernel_height, kernel_width),分組卷積的卷積核權重shape為(C_out, C_in/g, kernel_height, kernel_width),DW卷積的卷積核權重shape為(C_in, 1, kernel_height, kernel_width),
從 Inception module 到 depthwise separable convolutions
深度可分離卷積(depthwise separable convolutions)的提出最早來源于 Xception 論文,Xception 的論文中提到,對于卷積來說,卷積核可以看做一個三維的濾波器:通道維+空間維(Feature Map 的寬和高),常規的卷積操作其實就是實作通道相關性和空間相關性的聯合映射,Inception 模塊的背后存在這樣的一種假設:卷積層通道間的相關性和空間相關性是可以退耦合(完全可分)的,將它們分開映射,能達到更好的效果(the fundamental hypothesis behind Inception is that cross-channel correlations and spatial correlations are sufficiently decoupled that it is preferable not to map them jointly.),
引入深度可分離卷積的 Inception,稱之為 Xception,其作為 Inception v3 的改進版,在 ImageNet 和 JFT 資料集上有一定的性能提升,但是引數量和速度并沒有太大的變化,因為 Xception 的目的也不在于模型的壓縮,深度可分離卷積的 Inception 模塊如圖 Figure 4 所示,
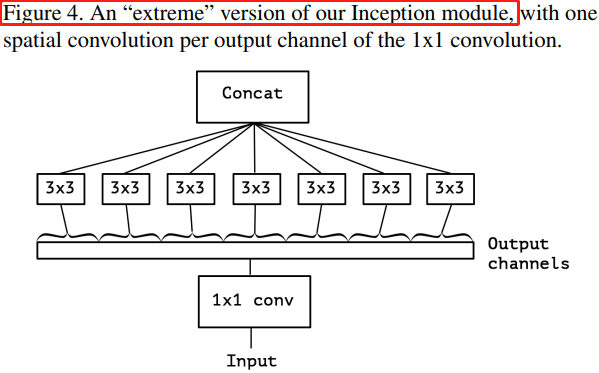
Figure 4 中的“極限” Inception 模塊與本文的主角-深度可分離卷積模塊相似,區別在于:深度可分離卷積先進行 channel-wise 的空間卷積,再進行 \(1 \times 1\) 的通道卷積,Figure 4 的 Inception 則相反;
2、MobileNets 結構
depthwise separable convolutions
MobileNets 是谷歌 2017 年提出的一種高效的移動端輕量化網路,其核心是深度可分離卷積,depthwise separable convolutions(深度可分離卷積) 的核心思想是將一個完整的卷積運算分解為兩步進行,分別為 Depthwise Convolution(DW 卷積) 與 Pointwise Convolution(PW 卷積),深度可分離卷積的計算步驟和濾波器尺寸如下所示,
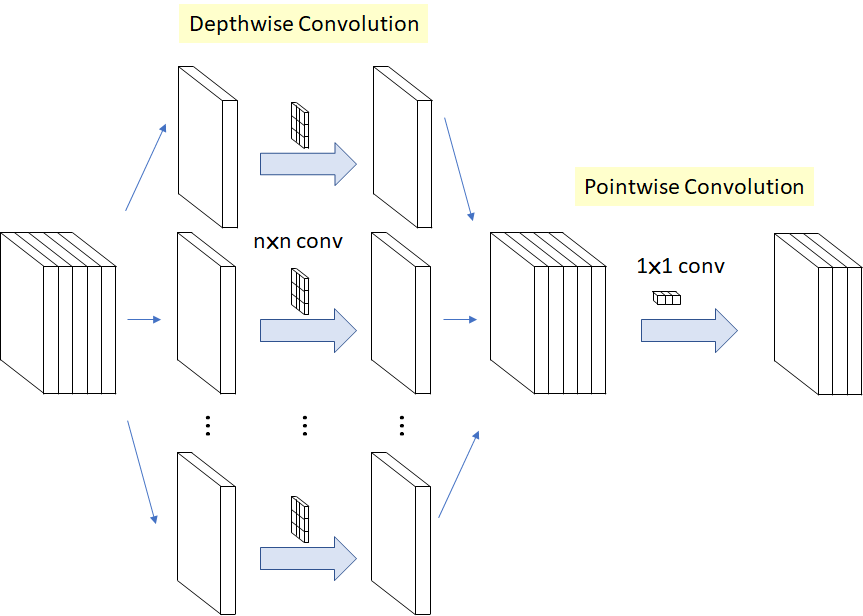
Depthwise 卷積
注意本文 DW 和 PW 卷積計算量的計算與論文有所區別,本文的輸出 Feature map 大小是 \(D_G \times D_G\), 論文公式是\(D_F \times D_F\),
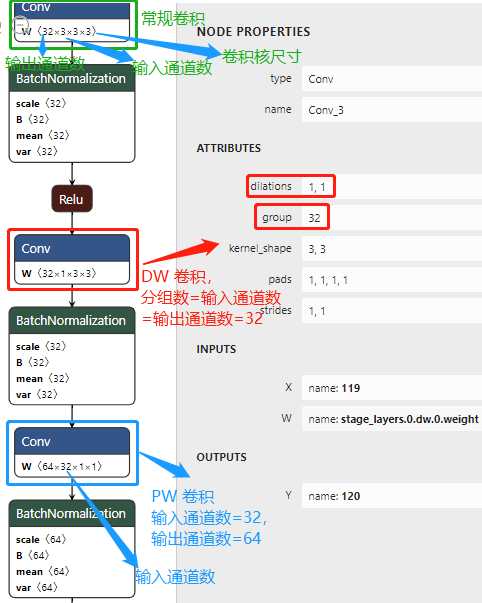
不同于常規卷積操作, Depthwise Convolution 的一個卷積核只負責一個通道,一個通道只能被一個卷積核卷積(不同的通道采用不同的卷積核卷積),也就是輸入通道、輸出通道和分組數相同的特殊分組卷積,因此 Depthwise(DW)卷積不會改變輸入特征圖的通道數目,深度可分離卷積的 DW卷積步驟如下圖:

DW 卷積的計算量 \(MACC = M \times D_{G}^{2} \times D_{K}^{2}\)
Pointwise 卷積
上述 Depthwise 卷積的問題在于它讓每個卷積核單獨對一個通道進行計算,但是各個通道的資訊沒有達到交換,從而在網路后續資訊流動中會損失通道之間的資訊,因此論文中就加入了 Pointwise 卷積操作,來進一步融合通道之間的資訊,PW 卷積是一種特殊的常規卷積,卷積核的尺寸為 \(1 \times 1\),PW 卷積的程序如下圖:
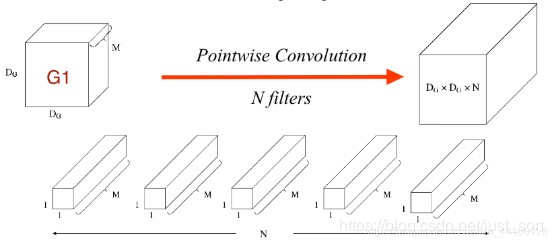
假設輸入特征圖大小為 \(D_{G} \times D_{G} \times M\),輸出特征圖大小為 \(D_{G} \times D_{G} \times N\),則濾波器尺寸為 \(1 \times 1 \times M\),且一共有 \(N\) 個濾波器,因此可計算得到 PW 卷積的計算量 \(MACC = N \times M \times D_{G}^{2}\),
綜上:Depthwise 和 Pointwise 卷積這兩部分的計算量相加為 \(MACC1 = M \times D_{G}^{2} \times D_{K}^{2} + N \times M \times D_{G}^{2}\),而標準卷積的計算量 \(MACC2 = N \times D_{G}^{2} \times D_{K}^{2} \times M\),所以深度可分離卷積計算量于標準卷積計算量比值的計算公式如下,
可以看到 Depthwise + Pointwise 卷積的計算量相較于標準卷積近乎減少了 \(N\) 倍,\(N\) 為輸出特征圖的通道數目,同理引數量也會減少很多,在達到相同目的(即對相鄰元素以及通道之間資訊進行計算)下, 深度可分離卷積能極大減少卷積計算量,因此大量移動端網路的 backbone 都采用了這種卷積結構,再加上模型蒸餾,剪枝,能讓移動端更高效的推理,
深度可分離卷積的詳細計算程序可參考 Depthwise卷積與Pointwise卷積,
2.2、網路結構
\(3 \times 3\) 的深度可分離卷積 Block 結構如下圖所示:
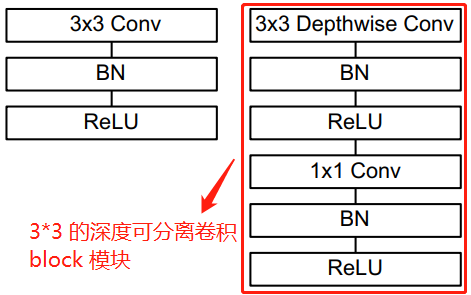
左邊是帶 bn 和 relu 的標準卷積層,右邊是帶 bn 和 relu 的深度可分離卷積層,
\(3 \times 3\) 的深度可分離卷積 Block 網路的 pytorch 代碼如下:
class MobilnetV1Block(nn.Module):
"""Depthwise conv + Pointwise conv"""
def __init__(self, in_channels, out_channels, stride=1):
super(MobilnetV1Block, self).__init__()
# dw conv kernel shape is (in_channels, 1, ksize, ksize)
self.dw = nn.Conv2d(in_channels, in_channels, kernel_size=3,stride=stride,padding=1, groups=in_channels, bias=False)
self.bn1 = nn.BatchNorm2d(in_channels)
self.pw = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out1 = F.relu(self.bn1(self.dw(x)))
out2 = F.relu(self.bn2(self.pw(out1)))
return out2
MobileNet v1 的 pytorch 模型匯出為 onnx 模型后,深度可分離卷積 block 結構圖如下圖所示,
僅用 MobileNets 的 Mult-Adds(乘加操作)次數更少來定義高性能網路是不夠的,確保這些操作能夠有效實施也很重要,例如非結構化稀疏矩陣運算(unstructured sparse matrix operations)通常并不會比密集矩陣運算(dense matrix operations)快,除非是非常高的稀疏度,
這句話是不是和
shufflenet v2的觀點一致,即不能僅僅以 FLOPs 計算量來表現網路的運行速度,除非是同一種網路架構,
MobileNet 模型結構將幾乎所有計算都放入密集的 1×1 卷積中(dense 1 × 1 convolutions),卷積計算可以通過高度優化的通用矩陣乘法(GEMM)函式來實作, 卷積通常由 GEMM 實作,但需要在記憶體中進行名為 im2col 的初始重新排序,然后才映射到 GEMM, caffe 框架就是使用這種方法實作卷積計算, 1×1 卷積不需要在記憶體中進行重新排序,可以直接使用 GEMM(最優化的數值線性代數演算法之一)來實作,
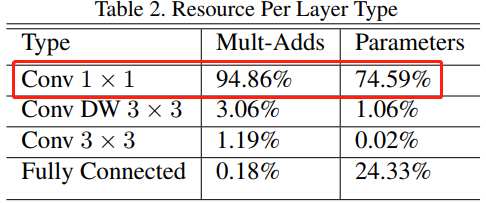
如表 2 所示,MobileNet 模型的 1x1 卷積占據了 95% 的計算量和 75% 的引數,剩下的引數幾乎都在全連接層中, 3x3 的 DW 卷積核常規卷積占據了很少的計算量(Mult-Adds)和引數,
2.3、寬度乘系數-更小的模型
盡管基本的 MobileNet 體系結構已經很小且網路延遲 latency 很低,但很多情況下特定用例或應用可能要求模型變得更小,更快,為了構建這些更小且計算成本更低的模型,我們引入了一個非常簡單的引數 \(\alpha\),稱為 width 乘數,寬度乘數 \(\alpha\) 的作用是使每一層的網路均勻變薄,對于給定的層和寬度乘數 \(\alpha\),輸入通道的數量變為 \(\alpha M\),而輸出通道的數量 \(N\) 變為 \(\alpha N\),具有寬度乘數 \(\alpha\) 的深度可分離卷積(其它引數和上文一致)的計算成本為:
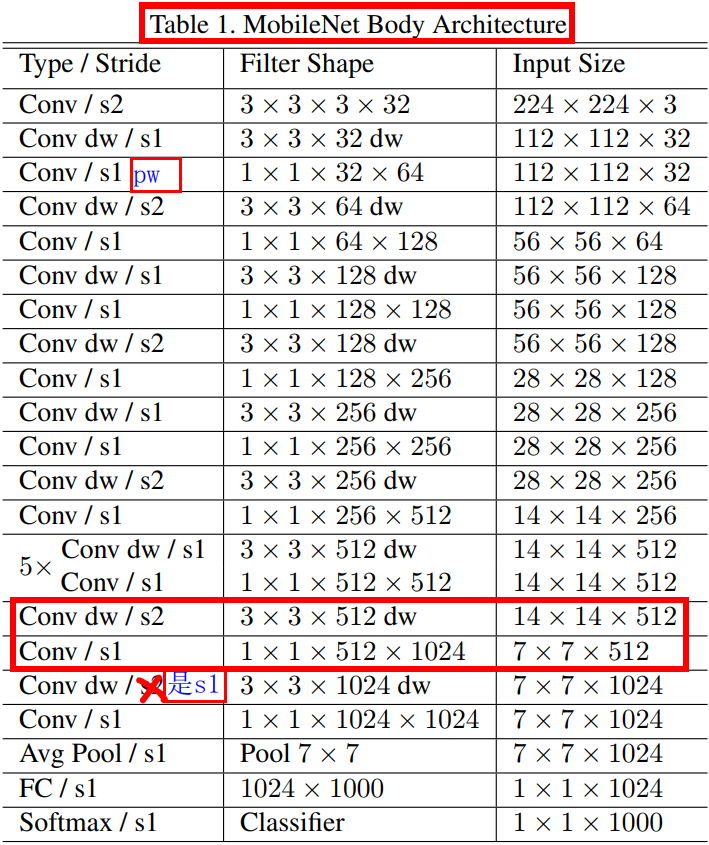
其中 \(\alpha \in (0,1]\),典型值設定為 1、0.75、0.5 和 0.25,\(\alpha = 1\) 是基準 MobileNet 模型,\(\alpha < 1\) 是縮小版的 MobileNets,寬度乘數的作用是將計算量和引數數量大約減少 \(\alpha^2\) 倍,從而降低了網路計算成本( computational cost of a neural network), 寬度乘數可以應用于任何模型結構,以定義新的較小模型,且具有合理的準確性、網路延遲 latency 和模型大小之間的權衡, 它用于定義新的精簡結構,需要從頭開始進行訓練模型,基準 MobileNet 模型的整體結構定義如表 1 所示,
2.4、解析度乘系數-減少表示
減少模型計算成本的的第二個超引數(hyper-parameter)是解析度因子 \(\rho\),論文將其應用于輸入影像,則網路的每一層 feature map 大小也要乘以 \(\rho\),實際上,論文通過設定輸入解析度來隱式設定 \(\rho\),
將網路核心層的計算成本表示為具有寬度乘數 \(\alpha\) 和解析度乘數 \(\rho\) 的深度可分離卷積的公式如下:
其中 \(\rho \in (0,1]\),通常是隱式設定的,因此網路的輸入解析度為 224、192、160 或 128,\(\rho = 1\) 時是基準(baseline) MobilNet,\(\rho < 1\) 時縮小版 MobileNets,解析度乘數的作用是將計算量減少 \(\rho^2\),
2.5、模型結構總結
- 整個網路不算平均池化層與
softmax層,且將DW卷積和PW卷積計為單獨的一層,則MobileNet有28層網路,+ 在整個網路結構中步長為2的卷積較有特點,卷積的同時充當下采樣的功能; - 第一層之后的
26層都為深度可分離卷積的重復卷積操作,分為4個卷積stage; - 每一個卷積層(含常規卷積、深度卷積、逐點卷積)之后都緊跟著批規范化和
ReLU激活函式; - 最后一層全連接層不使用激活函式,
3、實驗
作者分別進行了 Stanford Dogs dataset 資料集上的細粒度識別、大規模地理分類、人臉屬性分類、COCO 資料集上目標檢測的實驗,來證明與 Inception V3、GoogleNet、VGG16 等 backbone 相比,MobilNets 模型可以在計算量(Mult-Adds)數 10 被下降的情況下,但是精度卻幾乎不變,
4、結論
論文提出了一種基于深度可分離卷積的新模型架構,稱為 MobileNets, 在相關作業章節中,作者首先調查了一些讓模型更有效的重要設計原則,然后,演示了如何通過寬度乘數和解析度乘數來構建更小,更快的 MobileNet,通過權衡合理的精度以減少模型大小和延遲, 然后,我們將不同的 MobileNets 與流行的模型進行了比較,這些模型展示了出色的尺寸,速度和準確性特性, 最后,論文演示了 MobileNet 在應用于各種任務時的有效性,
5、基準模型代碼
自己復現的基準 MobileNet v1 代模型 pytorch 代碼如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
from torch import flatten
class MobilnetV1Block(nn.Module):
"""Depthwise conv + Pointwise conv"""
def __init__(self, in_channels, out_channels, stride=1):
super(MobilnetV1Block, self).__init__()
# dw conv kernel shape is (in_channels, 1, ksize, ksize)
self.dw = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3,
stride=stride, padding=1, groups=4, bias=False),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True)
)
# print(self.dw[0].weight.shape) # print dw conv kernel shape
self.pw = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.dw(x)
x = self.pw(x)
return x
def convbn_relu(in_channels, out_channels, stride=2):
return nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride,
padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True))
class MobileNetV1(nn.Module):
# (32, 64, 1) means MobilnetV1Block in_channnels is 32, out_channels is 64, no change in map size.
stage_cfg = [(32, 64, 1),
(64, 128, 2), (128, 128, 1), # stage1 conv
(128, 256, 2), (256, 256, 1), # stage2 conv
(256, 512, 2), (512, 512, 1), (512, 512, 1), (512, 512, 1), (512, 512, 1), (512, 512, 1), # stage3 conv
(512, 1024, 2), (1024, 1024, 1) # stage4 conv
]
def __init__(self, num_classes=1000):
super(MobileNetV1, self).__init__()
self.first_conv = convbn_relu(3, 32, 2) # Input image size reduced by half
self.stage_layers = self._make_layers(in_channels=32)
self.linear = nn.Linear(1024, num_classes) # 全連接層
def _make_layers(self, in_channels):
layers = []
for x in self.stage_cfg:
in_channels = x[0]
out_channels = x[1]
stride = x[2]
layers.append(MobilnetV1Block(in_channels, out_channels, stride))
in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
"""Feature map shape(h、w) is 224 -> 112 -> 56 -> 28 -> 14 -> 7 -> 1"""
x = self.first_conv(x)
x = self.stage_layers(x)
x = F.avg_pool2d(x, 7) # x shape is 7*7
x = flatten(x, 1) # x = x.view(x.size(0), -1)
x = self.linear(x)
return x
if __name__ == "__main__":
model = MobileNetV1()
model.eval() # set the model to inference mode
input_data = https://www.cnblogs.com/armcvai/p/torch.rand(1, 3, 224, 224)
outputs = model(input_data)
print("Model output size is", outputs.size())
程式運行結果如下:
Model output size is torch.Size([1, 1000])
參考資料
- Group Convolution分組卷積,以及Depthwise Convolution和Global Depthwise Convolution
- 理解分組卷積和深度可分離卷積如何降低引數量
- 深度可分離卷積(Xception 與 MobileNet 的點滴)
- MobileNetV1代碼實作
- Depthwise卷積與Pointwise卷積
- 【CNN結構設計】深入理解深度可分離卷積
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/517570.html
標籤:其他
上一篇:顏值經濟下,車企的必備武器