今天,一個朋友想使用我的SSE優化Demo里的雙線性插值演算法,他已經在專案里使用了OpenCV,因此,我就建議他直接使用OpenCV,朋友的程式非常注意效率和實時性(因為是處理視頻),因此希望我能測驗下我的速度和OpenCV相比到底那一個更有速度優勢,恰好前一段時間也有朋友有這方面的需求,因此我就隨意撰寫了一個測驗程式,如下所示:
IplImage *T = cvLoadImage("F:\\1.JPG"); IplImage *SrcImg = cvCreateImage(cvSize(T->width, T->height), IPL_DEPTH_8U, 1); cvCvtColor(T, SrcImg, CV_BGR2GRAY); //IplImage *SrcImg = cvLoadImage("F:\\3.jpg"); cvNamedWindow("處理前", CV_WINDOW_AUTOSIZE); cvShowImage("處理前", SrcImg); IplImage *DestImg = cvCreateImage(cvSize(SrcImg->width / 2, SrcImg->height / 2), SrcImg->depth, SrcImg->nChannels); LARGE_INTEGER t1, t2, tc; QueryPerformanceFrequency(&tc); QueryPerformanceCounter(&t1); for(int i=0; i<100; i++) cvResize(SrcImg, DestImg, CV_INTER_CUBIC); QueryPerformanceCounter(&t2); printf("Use Time:%f\n", (t2.QuadPart - t1.QuadPart) * 1000.0f / tc.QuadPart); cvNamedWindow("處理后", CV_WINDOW_AUTOSIZE); cvShowImage("處理后", DestImg); cvReleaseImage(&SrcImg); cvReleaseImage(&DestImg); cvReleaseImage(&T);
我使用了一張3000*2000的大圖進行測驗,令我非常詫異的是,執行100次這個函式耗時居然只有 Use Time:82.414300 ms,每一幀都不到1ms,目標影像的大小可是1500*1000的呢,立馬打開我自己的Demo,同樣的環境下測驗,100次耗時達到了450ms,相差太多了,要知道,我那個可是SSE優化后的啊,有點不敢相信這個事實,
接著,我把CV_INTER_LINEAR(雙線性)改為CV_INTER_NN(最近臨),出來的結果是Use Time:78.921600 ms,注意到沒有,時間比雙線性的還要多,感覺這完全不合乎邏輯啊,
稍微冷靜下來,我認為這絕對不符合真理,但是我心中已經隱隱約約知道大概為什么會出現這個情況,于是,我又做了下面幾個測驗,
第一、換一副影像看看,我把源影像的大小改為3001*2000,測驗結果為:Use Time:543.837400 ms,
把源影像的大小改為3000*2001,測驗結果為:Use Time:541.567800 ms,
把源影像的大小改為3001*2001,測驗結果為:Use Time:547.325600 ms,
第二:源影像還是使用3000*2000大小,把DestImg的大小修改為1501*1000,測驗結果為:Use Time:552.432800 ms,
把DestImg的大小修改為1500*1001,測驗結果為:Use Time:549.956400 ms,
把DestImg的大小修改為1501*1001,測驗結果為:Use Time:551.371200 ms,
這兩個測驗表明,這種情況只在:
一、源影像的寬度和高度均為2的倍數時;
二、目標影像的寬度和高度都必須為源影像的一半時;
時方有可能出現,那么他們是充分條件了嗎?接著做試驗,
第三:把插值方法改為其他的方式,比如CV_INTER_CUBIC(三次立方),若其他引數都不變,測驗結果為:Use Time:921.885900 ms,
同樣適使用三次立方,源圖大小修改為3000*2001,測驗結果為:Use Time:953.748100 ms,
適用三次立方,源圖大小不變,目標圖修改1501*1000,測驗結果為:Use Time:913.735600 ms,
可見此時無論怎么調整輸入輸出,基本的耗時都差不多,換成CV_INTER_AREA或CV_INTER_NN也能得到同樣的結果,
這第三個測驗表明,此例外現象還只有在:
三:使用了雙線性插值演算法;
時才可能出現,這些條件就足夠了嗎?接著看,
第四:其他條件暫時不動,把測驗代碼修改如下:
IplImage *SrcImg = cvLoadImage("F:\\1.jpg"); cvNamedWindow("處理前", CV_WINDOW_AUTOSIZE); cvShowImage("處理前", SrcImg); IplImage *DestImg = cvCreateImage(cvSize(SrcImg->width / 2, SrcImg->height / 2), SrcImg->depth, SrcImg->nChannels); LARGE_INTEGER t1, t2, tc; QueryPerformanceFrequency(&tc); QueryPerformanceCounter(&t1); for(int i=0; i<100; i++) cvResize(SrcImg, DestImg, CV_INTER_CUBIC); QueryPerformanceCounter(&t2); printf("Use Time:%f\n", (t2.QuadPart - t1.QuadPart) * 1000.0f / tc.QuadPart); cvNamedWindow("處理后", CV_WINDOW_AUTOSIZE); cvShowImage("處理后", DestImg); cvReleaseImage(&SrcImg); cvReleaseImage(&DestImg);
即使用彩色影像進行測驗,運行的結果為:Use Time:271.705700 ms,看這個的時間和灰度的82ms相比,一猜就知道還是做了特別的處理,
但是我們還是多做幾個測驗,我們將輸出影像的大小修改為1501*1000、1500*1001、1501*1001時,100次的耗時在1367ms,如果輸入影像修改為長或寬為非偶數時,耗時也差不多要1300多ms,說明OpenCV對彩色影像的這種情況也有做優化處理,
因此,這個演算法對彩色也是有效的,
以上三個條件在一起構成了出現上述例外現象的充分必要條件,下面根據我個人的想法來談談OpenCV為什么會出現這個現象(我沒有去翻OpenCV的代碼),
個人認為,出現該現象核心還是由雙線性插值演算法的本質引起的,雙線性插值演算法在插值時涉及到周邊四個像素,當源影像寬度和高度都為2的倍數,如果此時的目標影像的長度和高度又恰好是源影像寬度和高度的一半,這個時候的雙線性插值就退化為對原影像行列方向每隔一個像素求平均值(四個像素)的程序,如果不是雙線性插值,他涉及到領域范圍就不是4個,比如三次立方就涉及到16個領域,而非2的倍數或非一半的大小則無法規整到0.25的權重(4個像素的平均值),
對于這個特例,我們用C語言可以簡單的寫出其計算程序:
int IM_ZoomIn_Half_Bilinear(unsigned char *Src, unsigned char *Dest, int SrcW, int SrcH, int StrideS, int DstW, int DstH, int StrideD) { int Channel = StrideS / SrcW; if ((Src =https://www.cnblogs.com/Imageshop/p/= NULL) || (Dest == NULL)) return IM_STATUS_NULLREFRENCE; if ((SrcW <= 0) || (SrcH <= 0) || (DstW <= 0) || (DstH <= 0)) return IM_STATUS_INVALIDPARAMETER; if ((Channel != 1) && (Channel != 3) && (Channel != 4)) return IM_STATUS_INVALIDPARAMETER; if ((SrcW % 2 != 0) || (SrcH % 2 != 0)) return IM_STATUS_INVALIDPARAMETER; if ((DstW != SrcW / 2) || (DstH != SrcH / 2)) return IM_STATUS_INVALIDPARAMETER; if (Channel == 1) { for (int Y = 0; Y < DstH; Y++) { unsigned char *LinePD = Dest + Y * StrideD; unsigned char *LineP1 = Src + Y * 2 * StrideS; unsigned char *LineP2 = LineP1 + StrideS; for (int X = 0; X < DstW; X++, LineP1 += 2, LineP2 += 2) { LinePD[X] = (LineP1[0] + LineP1[1] + LineP2[0] + LineP2[1] + 2) >> 2; } } } else if (Channel == 3) { for (int Y = 0; Y < DstH; Y++) { unsigned char *LinePD = Dest + Y * StrideD; unsigned char *LineP1 = Src + Y * 2 * StrideS; unsigned char *LineP2 = LineP1 + StrideS; for (int X = 0; X < DstW; X++) { LinePD[0] = (LineP1[0] + LineP1[3] + LineP2[0] + LineP2[3] + 2) >> 2; LinePD[1] = (LineP1[1] + LineP1[4] + LineP2[1] + LineP2[4] + 2) >> 2; LinePD[2] = (LineP1[2] + LineP1[5] + LineP2[2] + LineP2[5] + 2) >> 2; LineP1 += 6; LineP2 += 6; LinePD += 3; } } } }
代碼非常簡單,注意到計算式里最后的+2是為了進行四舍五入,
我們先測驗下灰度圖,使用上述代碼在同樣的環境下可以獲得: Use Time:225.456300 ms 的成績,使用回圈內2路或4路并行的方式大約能將成績提高到190ms左右,但是和OpenCV的速度相比還是有蠻大的差距,這么簡答的代碼,我們可以直接用SIMD指令進行優化:
我們先使用SSE進行嘗試:
__m128i Zero = _mm_setzero_si128(); for (int Y = 0; Y < DstH; Y++) { unsigned char *LinePD = Dest + Y * StrideD; unsigned char *LineP1 = Src + Y * 2 * StrideS; unsigned char *LineP2 = LineP1 + StrideS; for (int X = 0; X < Block * BlockSize; X += BlockSize, LineP1 += BlockSize * 2, LineP2 += BlockSize * 2) { __m128i Src1 = _mm_loadu_si128((__m128i *)LineP1); __m128i Src2 = _mm_loadu_si128((__m128i *)LineP2); // A0+B0 A1+B1 A2+B2 A3+B3 A4+B4 A5+B5 A6+B6 A7+B7 __m128i Sum_L = _mm_add_epi16(_mm_cvtepu8_epi16(Src1), _mm_cvtepu8_epi16(Src2)); // A8+B8 A9+B9 A10+B10 A11+B11 A12+B12 A13+B13 A14+B14 A15+1B15 __m128i Sum_H = _mm_add_epi16(_mm_unpackhi_epi8(Src1, Zero), _mm_unpackhi_epi8(Src2, Zero)); // A0+A1+B0+B1 A2+A3+B2+B3 A4+A5+B4+B5 A6+A7+B6+B7 A8+A9+B8+B9 A10+A11+B10+B11 A12+A13+B12+B13 A14+A15+B14+1B15 __m128i Sum = _mm_hadd_epi16(Sum_L, Sum_H); // (A0+A1+B0+B1+2)/4 (A2+A3+B2+B3)/4 (A4+A5+B4+B5)/4 (A6+A7+B6+B7)/4 (A8+A9+B8+B9)/4 (A10+A11+B10+B11)/4 (A12+A13+B12+B13)/4 (A14+A15+B14+1B15)/4 __m128i Result = _mm_srli_epi16(_mm_add_epi16(Sum, _mm_set1_epi16(2)), 2); _mm_storel_epi64((__m128i *)(LinePD + X), _mm_packus_epi16(Result, Zero)); } for (int X = Block * BlockSize; X < DstW; X++, LineP1 += 2, LineP2 += 2) { LinePD[X] = (LineP1[0] + LineP1[1] + LineP2[0] + LineP2[1] + 2) >> 2; } }
對SSE優化來說,也沒啥,加載資料,將其轉換成16位(位元組相加肯定會溢位,到16位后4個數相加肯定會在16位的范圍內),注意上面的最為精華的部分為_mm_hadd_epi16的使用,他的水平累加程序恰好可以完成最后的列方向的處理,如果我們先用這個函式完成A0+A1這樣的作業,那如果要完成同樣的作業,后續就要多了一些shuffle程序了,這樣就降低了速度,
這段SIMD指令經過測驗,100次回圈耗時在90-100ms之間徘徊,和OpenCV的結果有點差不多了,
如果我們使用AVX指令進行優化,整體基本和SSE差不多,但是區域細節上還是有所差異的,如下所示:
for (int Y = 0; Y < DstH; Y++) { unsigned char *LinePD = Dest + Y * StrideD; unsigned char *LineP1 = Src + Y * 2 * StrideS; unsigned char *LineP2 = LineP1 + StrideS; __m256i Zero = _mm256_setzero_si256(); for (int X = 0; X < Block * BlockSize; X += BlockSize, LineP1 += BlockSize * 2, LineP2 += BlockSize * 2) { __m256i Src1 = _mm256_loadu_si256((__m256i *)LineP1); __m256i Src2 = _mm256_loadu_si256((__m256i *)LineP2); // 注意這里使用unpack的方式來實作8位和16位的轉換,如果使用_mm256_cvtepu8_epi16則低位部分需要一個__m128i變數,而 // 高位使用_mm256_unpackhi_epi8則需要一個__m256i變數,這樣會存在重復加載現象的, __m256i Sum_L = _mm256_add_epi16(_mm256_unpacklo_epi8(Src1, Zero), _mm256_unpacklo_epi8(Src2, Zero)); __m256i Sum_H = _mm256_add_epi16(_mm256_unpackhi_epi8(Src1, Zero), _mm256_unpackhi_epi8(Src2, Zero)); __m256i Sum = _mm256_hadd_epi16(Sum_L, Sum_H); __m256i Result = _mm256_srli_epi16(_mm256_add_epi16(Sum, _mm256_set1_epi16(2)), 2); // 注意_mm256_packus_epi16 并不是_mm_packus_epi16的線性擴展,很惡心的做法 _mm_storeu_si128((__m128i *)(LinePD + X), _mm256_castsi256_si128(_mm256_permute4x64_epi64(_mm256_packus_epi16(Result, Zero), _MM_SHUFFLE(3, 1, 2, 0)))); } for (int X = Block * BlockSize; X < DstW; X++,LineP1 += 2, LineP2 += 2) { LinePD[X] = (LineP1[0] + LineP1[1] + LineP2[0] + LineP2[1] + 2) >> 2; } }
特別注意到的是最后_mm256_packus_epi16指令的使用,他和_mm256_add_epi16或者 _mm256_srli_epi16不一樣,并不是對SSE指令簡單的從128位擴展到256位,我們從其簡單的數學解釋就可以看到:
_mm_add_epi16 _mm256_add_epi16
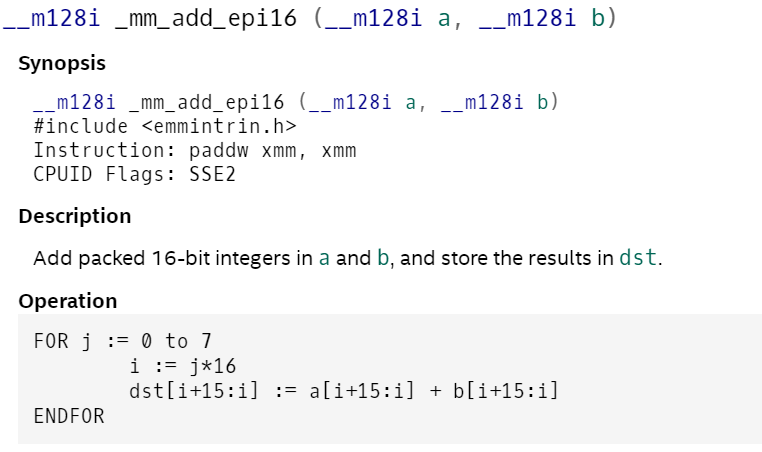
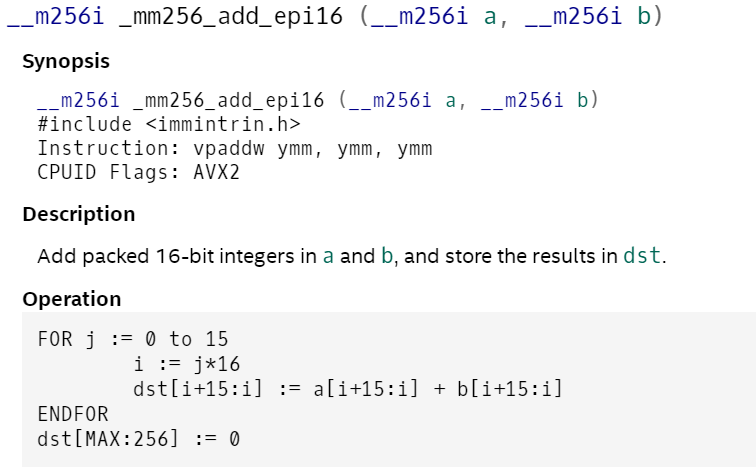
add指令就是直接從8次一次性計算簡單的擴展到16次一次性計算,在來看packus指令:
_mm_packus_epi16 _mm256_packus_epi16
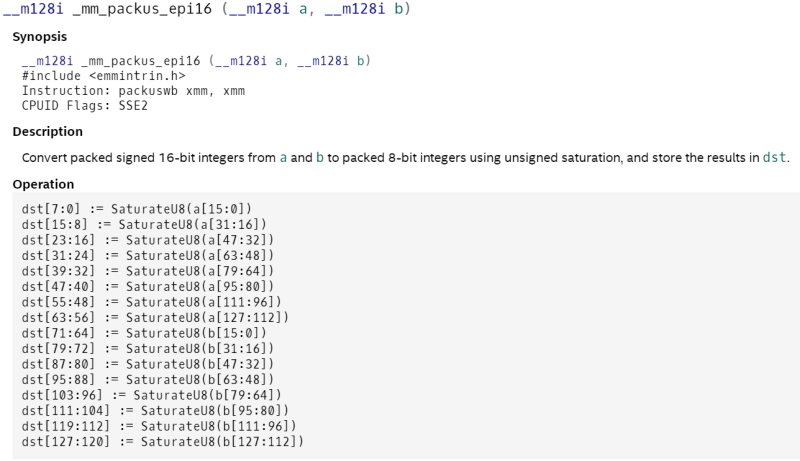
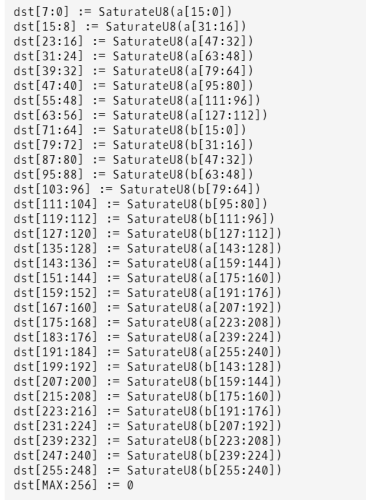
_mm256_packus_epi16 實際上可以看成是對兩個__m128i變數單獨進行處理,而不是把他們看成一個整體,這樣同樣的演算法,我們就在AVX中就不能使用同樣SSE指令了,比如最后的保存的陳述句,我們必須使用一個_mm256_permute4x64_epi64指令來進行一下shuffle調序操作,
這種不便利性也是我不愿意將大部分SSE指令擴展到AVX的一個重要障礙之一,
使用AVX撰寫的程式優化后的耗時大約在80ms左右波動,這個已經非常接近OpenCV的速度了,至此,我們有理由相信OpenCV在實作這個的程序中應該也采取了類似我上述的優化方式進行處理(沒有仔細的翻OpenCV的代碼,請有看過的朋友指導下),
那么我們再談談為什么這個速度比最近鄰插值還要快吧,最近鄰演算法中,不存在插值,直接在源影像中選擇一個坐標位置的點作為新的像素值,在放大時其會出現多行像素相同的特性,這個特性可以用來加快演算法執行速度,但是對于縮小,只有一個點一個點的計算,至多可以用查找表提前計算好坐標,經過嘗試,這演算法是不易用多媒體指令進行優化的,而且即使用,也無明顯的速度提升,而對于本文的雙線性的特例,其并行的特性非常好,而且本身的計算量也不是很大,因此,就出現用SIMD優化后速度還比最近鄰還快的結果,
對于彩色影像,普通的C語言代碼也很簡單,上面也已經貼出代碼,這段代碼執行100次大概耗時在500ms左右,注意這個時候對他進行SIMD指令優化就不是一件很直接和很簡單的事情了,因為BGRBGR這樣的排列順序到底無法直接使用灰度模式的指令擴展,必須要將BGR重新排序,變為BBB GGG RRR這樣的模式,然后單獨對分量進行處理,處理完成后再合成為BGR排列,因此,這樣排列需要一次性加載48個位元組(SSE),用3個SSE暫存器保存資料,這個時候如果使用AVX指令就顯得有點繁瑣了,而且就是用AVX帶來的性能收益也微乎其微, 同樣的,這種計算量不大的演算法,用SIMD指令優化后的收益并不是特別明顯,對于彩色影像,SSE優化后其時間大概能縮短到300ms,這個速度要比OpenCV的稍微慢一點,
隨著現在的視頻顯示設備越來越先進,采集的影像也越來越大,比如現在4K的高清攝像頭也不在少數,在有些實時要求性很好的場合,我們必須考慮處理能力,將影像縮小在處理是常用的手段,而且,我想長寬各一半的這種縮小場合在此情況下也應該是很常見的,因此,特列的特別優化就顯得非常有意義,
還有,一般情況下影像多次縮小2倍要比直接縮小大于2倍的效果更好,或者說通過多次縮放得到的結果一般要比直接一次性縮放得到的結果要更好,比如,下面左圖是直接縮放到原圖1/4長寬的結果,右圖是先縮小一半,在縮小一半的結果,在風車的邊緣可以看到后者更為平滑,


在耗時上,比如上面這個操作,直接縮小到1/4因不是特殊處理,而通過2次一半的處理每次都是特殊演算法,雖然次數多了,但是總耗時也就比直接縮小1/4多了0.5倍,效果卻要好一點,對于那些重效果的地方,還是非常有意義的,特別是如果是處理4K的圖,這種處理也有很好的借鑒意義,
最后說一下,進一步測驗表面我自行優化的縮放演算法和OpenCV的相比灰度圖上基本差不多,彩色影像大概要快20%左右,
本文Demo下載地址: http://files.cnblogs.com/files/Imageshop/SSE_Optimization_Demo.rar,位于Edit-Resample選單下,里面的所有演算法都是基于SSE實作的,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/5180.html
標籤:其他