1 導引
我們在博客《知識圖譜物體對齊1:基于平移(translation)嵌入的方法》和博客《知識圖譜物體對齊2:基于GNN嵌入的方法》中介紹的都是有監督的知識圖譜對齊方法,它們都需要需要已經對齊好的物體做為種子(錨點),但是在實際場景下可能并沒有那么多種子給我們使用,為了解決這個問題,有許多無監督/自監督的知識圖譜對齊方法被提出,
2 一些常見無監督和自監督方法
2.1 基于GAN的方法
首先我們來看一個基于GAN的方法[1],雖然該方法是用于解決NLP中無監督跨語言詞向量對齊操作的,但是我覺得在知識圖譜領域也很有借鑒意義,
在最原始的有監督跨語言詞向量的對齊任務中,給定已經對齊好的字典(錨點)\(\left\{x_i, y_i\right\}_{i=1}^n\),我們需要找到一個線性變換\(W\)來將一個語言的embedding投影到另一個語言的embedding空間中:
\[W^{\star}=\underset{W \in M_d(\mathbb{R})}{\operatorname{argmin}}\|W X-Y\|_{\mathrm{F}} \]其中\(d\)為embeddings維度,\(X, Y\in \mathbb{R}^{d\times n}\)為字典embeddings矩陣,\(M_d(\mathbb{R})\)為\(d\times d\)的實矩陣空間,源單詞\(s\)的對應翻譯單詞定義為\(t=\operatorname{argmax}_t \cos \left(W x_s, y_t\right)\),
這個優化問題在對\(W\)施以正交約束的情況下,可通過對\(YX^T\)進行奇異值分解來獲得決議解:
\[W^{\star}=\underset{W \in O_d(\mathbb{R})}{\operatorname{argmin}}\|W X-Y\|_{\mathrm{F}}=U V^T, \text { with } U \Sigma V^T=\operatorname{SVD}\left(Y X^T\right) \]事實上,若兩個語言embedding空間的維度不相同,即\(x_i\in\mathbb{R}^{d_1}\)、\(y_i\in \mathbb{R}^{d_2}\)時,即\(W\in \mathbb{R^{d_2\times d_1}}\)不可逆時,亦可通過SGD來求數值解[2],
以上是有對齊的字典的情況,對于沒有字典的情況呢?我們可以先用GAN來學到一個\(W\)使得兩個單詞分布粗略地對齊,然后通過目前的\(W\)找一些高頻單詞在另一個向量空間中的最近鄰,作為錨點,進行優化以獲得更好的\(W\),測驗時,再通過最近鄰搜索來得到單詞在另一個向量空間中的翻譯結果,文中的最近鄰搜索采用CSLS(cross-domain similarity local scaling)作為距離度量,
整體演算法流程如下圖所示:
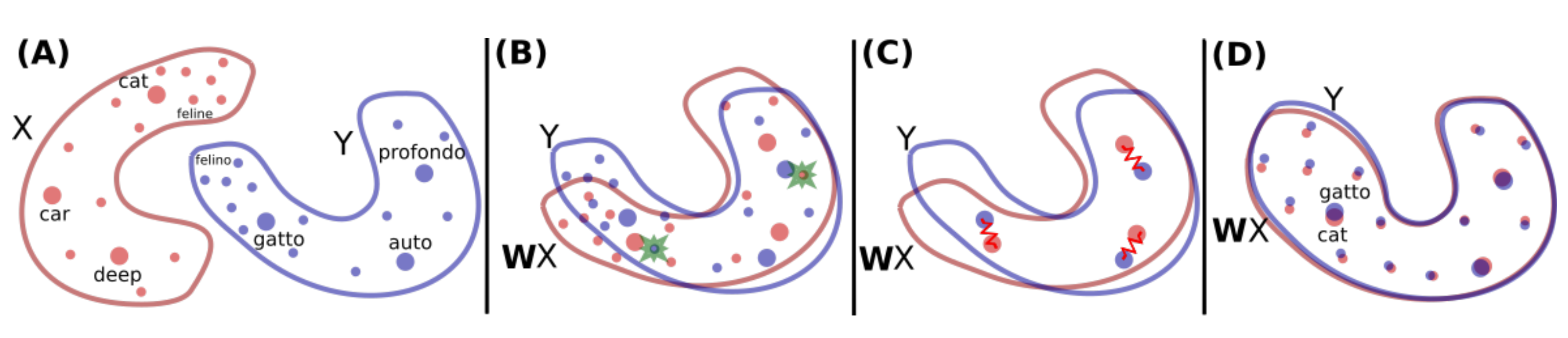
如上圖所示,(A) 為兩個不同的詞向量分布,紅色的英語單詞由\(X\)表示,藍色的意大利單詞由\(Y\)表示,我們想要進行翻譯/對齊(在意大利語里面,gatto意為“cat”,profondo意為“deep”,felino意為“feline”,“auto”意為“car”),每一個點代表詞向量空間中的一個單詞,點的大小和單詞在訓練語料中出現的頻率成正比, (B) 意為通過對抗學習機制學習一個旋轉矩陣\(W\)將兩個分布大致地對齊, (C) 使用一些高頻單詞及其映射后的最近鄰做為錨點,來對映射\(W\)進一步調整,(D) 尋找單詞在目標向量空間中的最近鄰以完成翻譯,
首先我們來看GAN是如何訓練的,設\(\mathcal{X}=\{x_1,\cdots, x_n\}\)和\(\mathcal{Y}=\{y_1,\cdots, y_m\}\)分別為源語言和目標語言embeddings的集合,GAN的判別器需要區分從\(W\mathcal{X}=\{Wx_1,\cdots, Wx_n\}\)和\(\mathcal{Y}\)中隨機采樣的元素,而生成器(引數為\(W\))要盡可能去阻止判別器做出正確的判斷:
\( \mathcal{L}_D\left(\theta_D \mid W\right)=-\frac{1}{n} \sum_{i=1}^n \log P_{\theta_D}\left(\right.\text{source} \left.=1 \mid W x_i\right)-\frac{1}{m} \sum_{i=1}^m \log P_{\theta_D}\left(\right. \text{source} \left.=0 \mid y_i\right)\).
\( \mathcal{L}_W\left(W \mid \theta_D\right)=-\frac{1}{n} \sum_{i=1}^n \log P_{\theta_D}\left(\right.\text{source }\left.=0 \mid W x_i\right)-\frac{1}{m} \sum_{i=1}^m \log P_{\theta_D}\left(\right.\text{source}\left.=1 \mid y_i\right) \)
之后,我們從GAN初步訓練得到的\(W\)來找到一些高頻單詞在另一個語言中的最近鄰,把他們作為錨點,然后優化目標函式來獲得更好的\(W\),
注意,在GAN的優化程序中對\(W\)進行調整時,采用一種特殊的更新方法來使其有正交性(正交變換在歐氏空間中保范數,且使得訓練程序更加穩定):
\[W \leftarrow(1+\beta) W-\beta\left(W W^T\right) W \]其中經驗表明\(\beta=0.01\)表現良好,
在\(W\)訓練完畢后,對每個單詞映射在其目標向量空間中做最近鄰搜索,如果兩個語言中的兩個單詞互為最近鄰,則我們把他們加入字典,認為是高質量的翻譯,
接下來我們看文中的最近鄰搜索采用的距離度量方式,文中認為單詞在配對程序中要盡量滿足“雙向奔赴”,防止某個單詞是其它語言中很多單詞最近鄰的“海王”情況,文中將源單詞\(x_s\)和目標單詞\(y_t\)間的距離定義為:
\[\text{C S L S}(Wx_s, x_t)=2 \cos \left(W x_s, y_t\right)-r_T(Wx_s)-r_S(y_t) \]這里\(r_T(Wx_s)\)為\(x_s\)和其目標向量空間中的\(K\)個鄰居間的平均距離:
\[r_T(W x_s)=\frac{1}{K} \sum_{y_t \in \mathcal{N}_T(Wx_s)} \cos \left(W x_s, y_t\right) \]同理定義\(r_S(y_t)\)為\(y_t\)和其\(K\)個鄰居間的平均距離,
如果一個單詞和另一語言中的很多單詞都很接近,那么\(r\)值就會很高,\(r\)可以視為一種懲罰,用于抑制了某些單詞是很多單詞最近鄰的情況,
2.2 基于對比學習的方法
本文介紹了通過一種基于對比學習的方法[3]將來自不同知識圖譜物體embeddings映射到一個統一的空間,首先,用對比學習的視角來審視知識圖譜\(G_x\)和\(G_y\)的對齊,可以看做是將\(G_x\)中的物體\(x\)和其在\(G_y\)中的對齊物體\(y\)的距離拉近(先假設已獲得對齊物體),而將\(x\)和\(\mathcal{G}_y\)中其它物體的距離推遠,如下圖中左半部分:
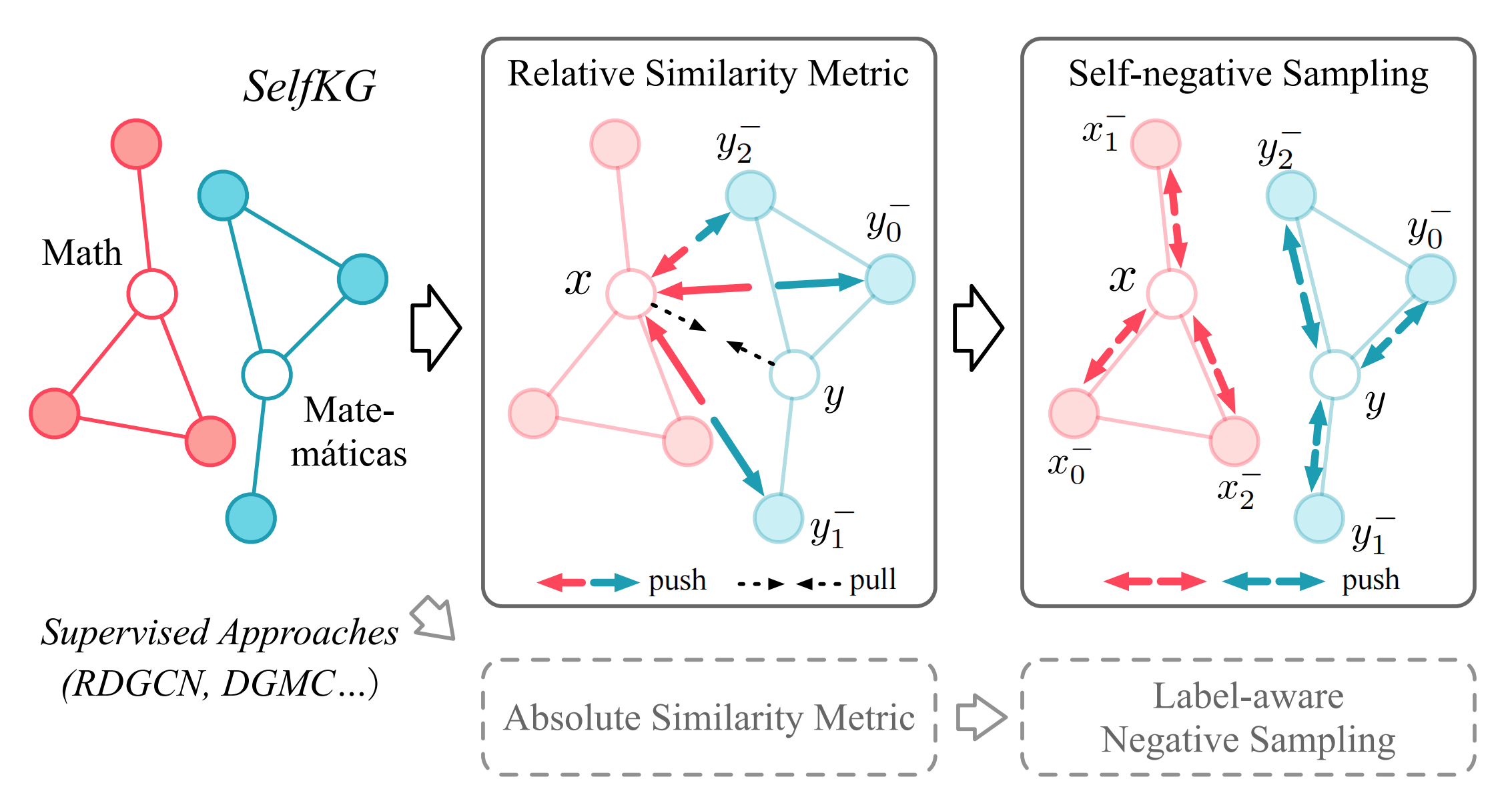
這里采用NCE損失來做物體對齊,令\(p_x\),\(p_y\)為兩個知識圖譜\(G_x\)和\(G_y\)的表征分布,\(p_{\text{pos}}\)表示正物體對\((x,y)\in \mathbb{R}^n \times \mathbb{R}^n\)的表征分布,給定對齊的物體對\((x,y)\sim p_{\text{pos}}\),負樣本集合\(\left\{y_i^{-} \in \mathbb{R}^n\right \}_{i=1}^M \stackrel{\text { i.i.d. }}{\sim} p_y\),溫度\(\tau\),滿足\(\lVert f(\cdot)\rVert=1\)的編碼器\(f\),我們有NCE損失為:
\[\begin{aligned} \mathcal{L}_{\mathrm{NCE}} & \triangleq-\log \frac{e^{f(x)^{\top} f(y) / \tau}}{e^{f(x)^{\top} f(y) / \tau}+\sum_i e^{f(x)^{\top} f\left(y_i^{-}\right) / \tau}} \\ &=\underbrace{-\frac{1}{\tau} f(x)^{\top} f(y)}_{\text {alignment }}+\underbrace{\log \left(e^{f(x)^{\top} f(y) / \tau}+\sum_i e^{f(x)^{\top} f\left(y_i^{-}\right) / \tau}\right)}_{\text {uniformity }} . \end{aligned} \]然而,上面的NCE損失還是需要實作知道已對齊的物體,稱不上完全的無監督對齊,作者在文中證明了,對于固定的\(\tau\)和滿足\(\lVert f(\cdot)\rVert=1\)的編碼器\(f\),我們可以為原始的優化目標函式\(\mathcal{L}_{ASM}\)(即NCE)找一個代理上界做為替代:
\[\begin{aligned} \mathcal{L}_{\mathrm{RSM}} &=-\frac{1}{\tau}+\underset{\left\{y_i^{-}\right\}_{i=1}^M { \stackrel{\text{i. i.d .}}{\sim}} p_y}{ \mathbb{E}}\left[\log \left(e^{1 / \tau}+\sum_i e^{f(x)^{\top} f\left(y_i^{-}\right) / \tau}\right)\right] \\ & \leq \mathcal{L}_{\mathrm{ASM}} \leq \mathcal{L}_{\mathrm{RSM}}+\frac{1}{\tau}\left[1-\min _{(x, y) \sim p_{\mathrm{pos}}}\left(f(x)^{\top} f(y)\right)\right] . \end{aligned} \]這里上界等于\(\mathcal{L}_{\text{RSM}}\)加一個常數(\(f(x)^Tf(y)\approx 1\)),因此可以直接優化\(\mathcal{L}_{\text{RSM}}\),這樣我們就可以不用去拉近正樣本間的距離,只需要推遠負樣本間的距離就行了,
在具體的負樣本采樣上,作者采用了self-negative sampling方式,傳統的label-aware counterpart negative sampling(上圖的左半部分)給定\(x\in\text{KG}_x\),需要從\(KG_y\)中采負樣本\(y_i^-\)來將其距離推遠,而這里的Self-negative Sampling(上圖的右半部分)只需要從\(KG_x\)從采負樣本\(x_i^-\)來將其距離推遠即可,接下來我們看為什么可以這么做,
設\({\{x_i^-\in \mathbb{R}^n\}}_{i=1}^M\)與\({\{y_i^-\in \mathbb{R}^n\}}_{i=1}^M\)分別為從分布\(p_x\)和\(p_y\)中獨立同分布采樣的隨機樣本,\(S^{d-1}\)為\(\mathbb{R}^n\)中的球面,如果存在映射\(f:\mathbb{R}^n\rightarrow S^{d-1}\)能夠將\(\mathbb{R}^N\)中的樣本映射到球面上,使得\(f(x_i^-)\)和\(f(y_i^-)\)在\(S^{d-1}\)上滿足相同的分布,那么我們有:
\[\lim _{M \rightarrow \infty}\left|\mathcal{L}_{\mathrm{RSM} \mid \lambda, \mathrm{x}}\left(f ; \tau, M, p_{\mathrm{x}}\right)-\mathcal{L}_{\mathrm{RSM} \mid \lambda, \mathrm{x}}\left(f ; \tau, M, p_{\mathrm{y}}\right)\right|=0 \]這就啟發我們在兩個知識圖譜共享相似的分布、且負樣本數量\(M\)充分大的情況下,self-negative sampling 可以看做是 Lable-aware sampling的近似,也即用\(\mathcal{L}_{\mathrm{RSM} \mid \lambda, \mathrm{x}}\left(f ; \tau, M, p_{\mathrm{x}}\right)\)來代替\(\mathcal{L}_{\mathrm{RSM} \mid \lambda, \mathrm{x}}\left(f ; \tau, M, p_{\mathrm{y}}\right)\),
最后,我們可以聯合優化\(G_x\)和\(G_y\)的損失函式,如下所示:
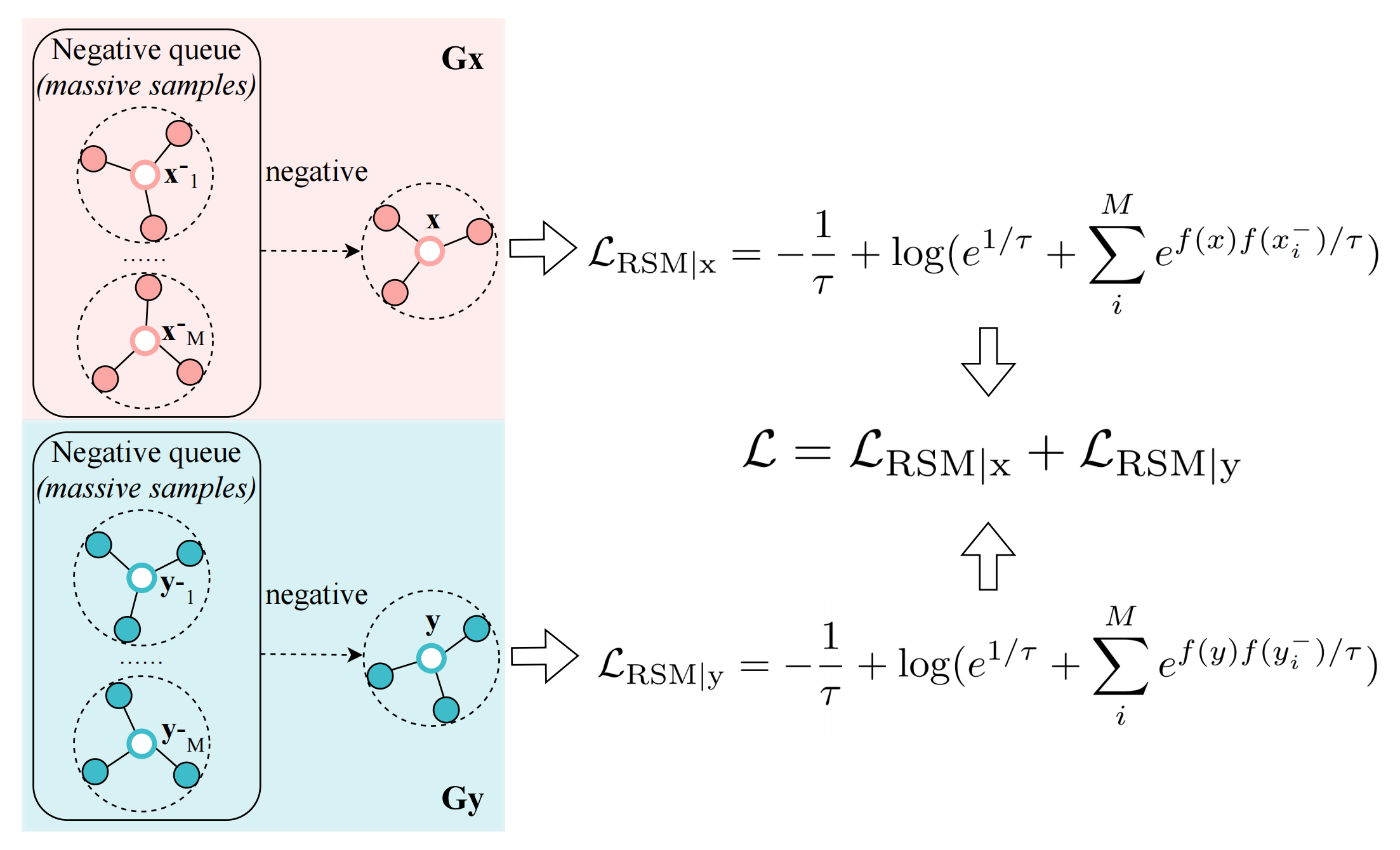
\[\mathcal{L}=\mathcal{L}_{\mathrm{RSM} \mid \lambda, \mathrm{x}}\left(f ; \tau, M, p_{\mathrm{x}}\right)+\mathcal{L}_{\mathrm{RSM} \mid \lambda, \mathrm{y}}\left(f ; \tau, M, p_{\mathrm{y}}\right) \]在優化該目標函式的程序中,需要不斷對負樣本對進行采樣,這里為知識圖譜\(G_x\)和知識圖譜\(G_y\)分別維護了一個負樣本佇列,整個訓練程序如下圖所示:
3 參考
- [1] Alexis Conneau, Guillaume Lample, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. 2018. Word Translation Without Parallel Data. Proceedings of ICLR.
- [2] Tomas Mikolov, Quoc V Le, and Ilya Sutskever. Exploiting similarities among languages for ma-chine translation. arXiv preprint arXiv:1309.4168, 2013b.
- [3] Liu X, Hong H, Wang X, et al. SelfKG: Self-Supervised Entity Alignment in Knowledge Graphs[C]//Proceedings of the ACM Web Conference 2022. 2022: 860-870.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/518874.html
標籤:其他