宣告
本文參考(8條訊息) 【中文】【吳恩達課后編程作業】Course 1 - 神經網路和深度學習 - 第四周作業(1&2)_何寬的博客-CSDN博客
力求自己理解,剛剛走進深度學習希望可以一起探索,
本文所使用的資料已上傳到百度網盤【點擊下載】,提取碼:xx1w,請在開始之前下載好所需資料,并將資料與代碼放在相同界面
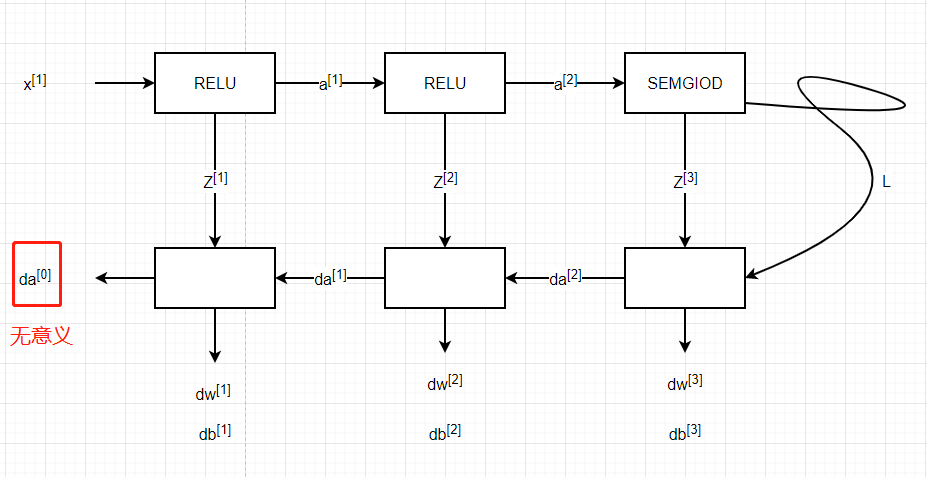
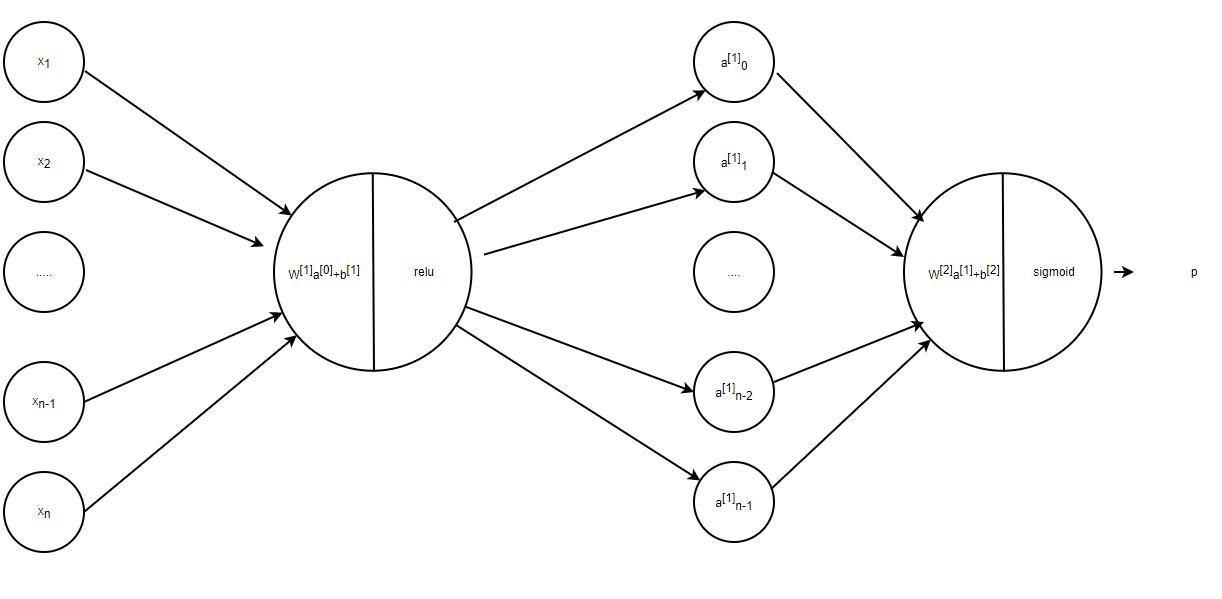
在正式開始之前,我們先來了解一下我們要做什么,在本次教程中,我們要構建兩個神經網路,一個是構建兩層的神經網路,一個是構建多層的神經網路,多層神經網路的層數可以自己定義,本次的教程的難度有所提升,但是我會力求深入簡出,在這里,我們簡單的講一下難點,本文會提到**[LINEAR-> ACTIVATION]轉發函式,比如我有一個多層的神經網路,結構是輸入層->隱藏層->隱藏層->···->隱藏層->輸出層**,在每一層中,我會首先計算Z = np.dot(W,A) + b,這叫做【linear_forward】,然后再計算A = relu(Z) 或者 A = sigmoid(Z),這叫做【linear_activation_forward】,合并起來就是這一層的計算方法,所以每一層的計算都有兩個步驟,先是計算Z,再計算A
流程圖
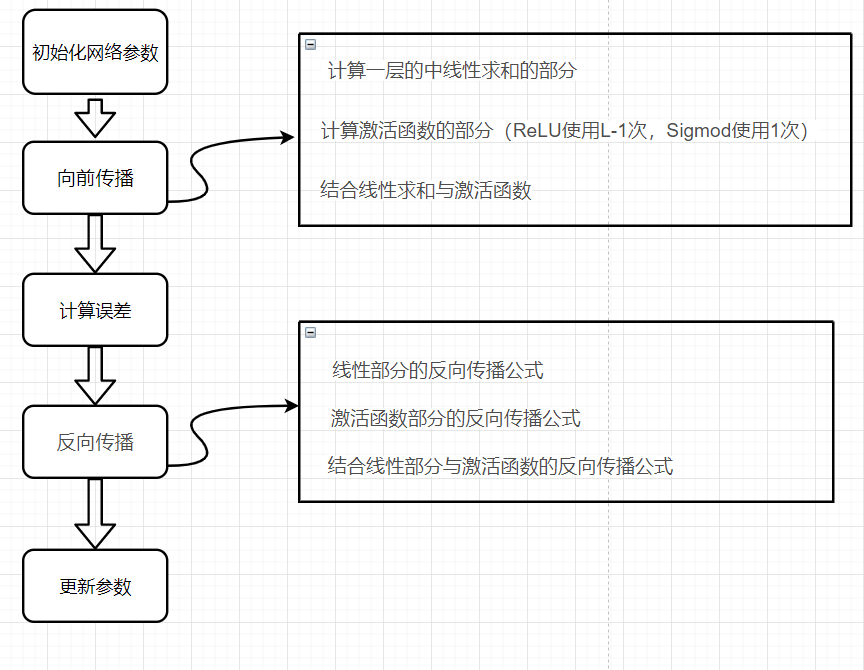
請注意,對于每個前向函式,都有一個相應的后向函式, 這就是為什么在我們的轉發模塊的每一步都會在cache中存盤一些值,cache的值對計算梯度很有用,
在反向傳播模塊中,我們將使用cache來計算梯度, 現在我們正式開始分別構建兩層神經網路和多層神經網路,這里很重要,
import numpy as np import h5py import matplotlib.pyplot as plt import testCases #參見資料包 from dnn_utils import sigmoid, sigmoid_backward, relu, relu_backward #參見資料包 import lr_utils #參見資料包
為了和我的資料匹配,你需要指定隨機種子
np.random.seed(1)
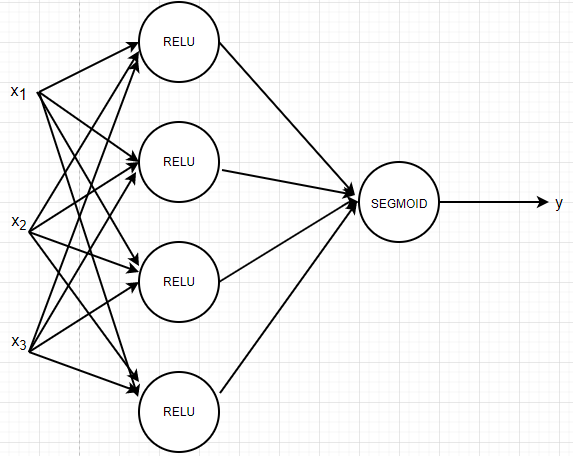
對于一個兩層的的神經網路而言,如下圖
初始化引數如下
def initialize_parameters(n_x,n_h,n_y): """ 此函式是為了初始化兩層網路引數而使用的函式, 引數: n_x - 輸入層節點數量 n_h - 隱藏層節點數量 n_y - 輸出層節點數量 回傳: parameters - 包含你的引數的python字典: W1 - 權重矩陣,維度為(n_h,n_x) b1 - 偏向量,維度為(n_h,1) W2 - 權重矩陣,維度為(n_y,n_h) b2 - 偏向量,維度為(n_y,1) """ W1 = np.random.randn(n_h, n_x) * 0.01 b1 = np.zeros((n_h, 1)) W2 = np.random.randn(n_y, n_h) * 0.01 b2 = np.zeros((n_y, 1)) #使用斷言確保我的資料格式是正確的 assert(W1.shape == (n_h, n_x)) assert(b1.shape == (n_h, 1)) assert(W2.shape == (n_y, n_h)) assert(b2.shape == (n_y, 1)) parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2} return parameters
接下來,我們測驗一下
print("==============測驗initialize_parameters==============") parameters = initialize_parameters(3,2,1) print("W1 = " + str(parameters["W1"])) print("b1 = " + str(parameters["b1"])) print("W2 = " + str(parameters["W2"])) print("b2 = " + str(parameters["b2"]))
==============測驗initialize_parameters============== W1 = [[ 0.01624345 -0.00611756 -0.00528172] [-0.01072969 0.00865408 -0.02301539]] b1 = [[0.] [0.]] W2 = [[ 0.01744812 -0.00761207]] b2 = [[0.]]
兩層的神經網路測驗已經完畢了,那么對于一個L層的神經網路而言呢?初始化會是什么樣的?
當然我們在大學都學過矩陣的乘法和加法吧,我們來看代碼
def initialize_parameters_deep(layers_dims): """ 此函式是為了初始化多層網路引數而使用的函式, 引數: layers_dims - 包含我們網路中每個圖層的節點數量的串列 回傳: parameters - 包含引數“W1”,“b1”,...,“WL”,“bL”的字典: W1 - 權重矩陣,維度為(layers_dims [1],layers_dims [1-1]) bl - 偏向量,維度為(layers_dims [1],1) """ np.random.seed(3) parameters = {} L = len(layers_dims) for l in range(1,L): parameters["W" + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) / np.sqrt(layers_dims[l - 1]) # ?這個根號其實和上面的?0.01是一樣目的的 parameters["b" + str(l)] = np.zeros((layers_dims[l], 1)) #確保我要的資料的格式是正確的 assert(parameters["W" + str(l)].shape == (layers_dims[l], layers_dims[l-1])) assert(parameters["b" + str(l)].shape == (layers_dims[l], 1)) return parameters
我們來測驗一下
#測驗initialize_parameters_deep print("==============測驗initialize_parameters_deep==============") layers_dims = [5,4,3] parameters = initialize_parameters_deep(layers_dims) print("W1 = " + str(parameters["W1"])) print("b1 = " + str(parameters["b1"])) print("W2 = " + str(parameters["W2"])) print("b2 = " + str(parameters["b2"]))
==============測驗initialize_parameters_deep============== W1 = [[ 0.79989897 0.19521314 0.04315498 -0.83337927 -0.12405178] [-0.15865304 -0.03700312 -0.28040323 -0.01959608 -0.21341839] [-0.58757818 0.39561516 0.39413741 0.76454432 0.02237573] [-0.18097724 -0.24389238 -0.69160568 0.43932807 -0.49241241]] b1 = [[0.] [0.] [0.] [0.]] W2 = [[-0.59252326 -0.10282495 0.74307418 0.11835813] [-0.51189257 -0.3564966 0.31262248 -0.08025668] [-0.38441818 -0.11501536 0.37252813 0.98805539]] b2 = [[0.] [0.] [0.]]
我們分別構建了兩層和多層神經網路的初始化引數的函式,現在我們開始構建前向傳播函式,
向前傳播函式
- LINEAR
- LINEAR - >ACTIVATION,其中激活函式將會使用ReLU或Sigmoid,
- [LINEAR - > RELU] ×(L-1) - > LINEAR - > SIGMOID(整個模型)
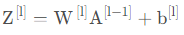
線性部分【LINEAR】
前向傳播中,線性部分計算如下:
def linear_forward(A,W,b): """ 實作前向傳播的線性部分, 引數: A - 來自上一層(或輸入資料)的激活,維度為(上一層的節點數量,示例的數量) W - 權重矩陣,numpy陣列,維度為(當前圖層的節點數量,前一圖層的節點數量) b - 偏向量,numpy向量,維度為(當前圖層節點數量,1) 回傳: Z - 激活功能的輸入,也稱為預激活引數 cache - 一個包含“A”,“W”和“b”的字典,存盤這些變數以有效地計算后向傳遞 """ Z = np.dot(W,A) + b assert(Z.shape == (W.shape[0],A.shape[1])) cache = (A,W,b) return Z,cache
我們來測驗一下:
#測驗linear_forward print("==============測驗linear_forward==============") A,W,b = testCases.linear_forward_test_case() Z,linear_cache = linear_forward(A,W,b) print("Z = " + str(Z))
==============測驗linear_forward============== Z = [[ 3.26295337 -1.23429987]]
線性激活部分【LINEAR - >ACTIVATION】
我們為了實作LINEAR->ACTIVATION這個步驟, 使用的公式是:A[l]=g(z[l])=g(W[l]A[l-1]+b[l]),其中,函式g會是sigmoid() 或者是 relu(),當然sigmoid()只在輸出層使用,現在我們正式構建前向線性激活部分,
我們發現在同一層中A的序列號總是會少1,
def linear_activation_forward(A_prev,W,b,activation): """ 實作LINEAR-> ACTIVATION 這一層的前向傳播 引數: A_prev - 來自上一層(或輸入層)的激活,維度為(上一層的節點數量,示例數) W - 權重矩陣,numpy陣列,維度為(當前層的節點數量,前一層的大小) b - 偏向量,numpy陣列,維度為(當前層的節點數量,1) activation - 選擇在此層中使用的激活函式名,字串型別,【"sigmoid" | "relu"】 回傳: A - 激活函式的輸出,也稱為激活后的值 cache - 一個包含“linear_cache”和“activation_cache”的字典,我們需要存盤它以有效地計算后向傳遞 """ if activation == "sigmoid": Z, linear_cache = linear_forward(A_prev, W, b) A, activation_cache = sigmoid(Z) elif activation == "relu": Z, linear_cache = linear_forward(A_prev, W, b) A, activation_cache = relu(Z) assert(A.shape == (W.shape[0],A_prev.shape[1])) cache = (linear_cache,activation_cache) return A,cache
我們來測驗一下:
#測驗linear_activation_forward print("==============測驗linear_activation_forward==============") A_prev, W,b = testCases.linear_activation_forward_test_case() A, linear_activation_cache = linear_activation_forward(A_prev, W, b, activation = "sigmoid") print("sigmoid,A = " + str(A)) A, linear_activation_cache = linear_activation_forward(A_prev, W, b, activation = "relu") print("ReLU,A = " + str(A))
==============測驗linear_activation_forward============== sigmoid,A = [[0.96890023 0.11013289]] ReLU,A = [[3.43896131 0. ]]
我們把兩層模型需要的前向傳播函式做完了,那多層網路模型的前向傳播是怎樣的呢?我們呼叫上面的那兩個函式來實作它,為了在實作L層神經網路時更加方便,
我們需要一個函式來復制前一個函式(帶有RELU的linear_activation_forward)L-1次,然后用一個帶有SIGMOID的linear_activation_forward跟蹤它,
我們來看一下它的結構是怎樣的: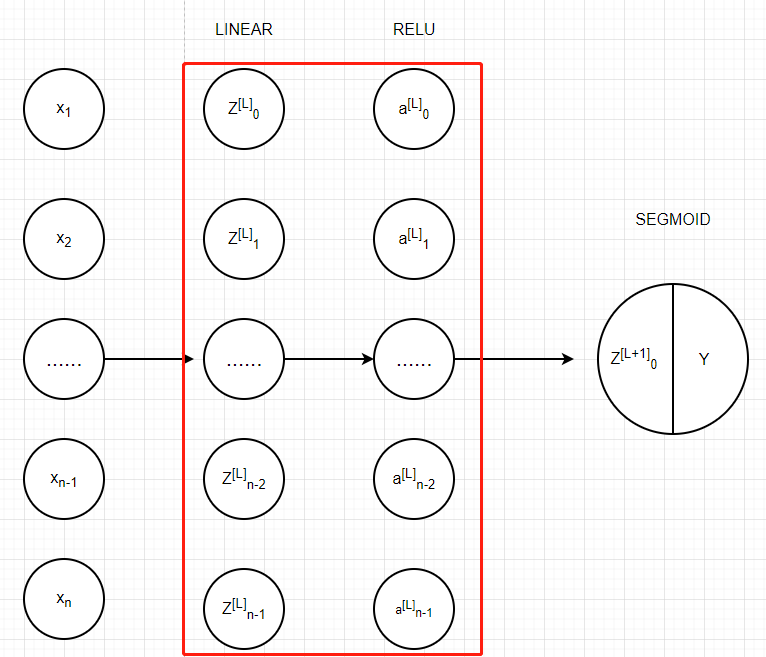
在下面的代碼中,AL表示A[L]=g(Z[L])=g(W[L]A[L-1]+b[L]),(也可稱作 Y_hat)
多層模型的前向傳播計算模型代碼如下:
def L_model_forward(X,parameters): """ 實作[LINEAR-> RELU] *(L-1) - > LINEAR-> SIGMOID計算前向傳播,也就是多層網路的前向傳播,為后面每一層都執行LINEAR和ACTIVATION 引數: X - 資料,numpy陣列,維度為(輸入節點數量,示例數) parameters - initialize_parameters_deep()的輸出 回傳: AL - 最后的激活值 caches - 包含以下內容的快取串列: linear_relu_forward()的每個cache(有L-1個,索引為從0到L-2) linear_sigmoid_forward()的cache(只有一個,索引為L-1) """ caches = [] A = X L = len(parameters) // 2 # 因為有兩個引數(W,b)因此要整除以2 for l in range(1,L): A_prev = A A, cache = linear_activation_forward(A_prev, parameters['W' + str(l)], parameters['b' + str(l)], "relu") caches.append(cache) AL, cache = linear_activation_forward(A, parameters['W' + str(L)], parameters['b' + str(L)], "sigmoid") caches.append(cache) assert(AL.shape == (1,X.shape[1])) return AL,caches
我們來測驗一下:
#測驗L_model_forward print("==============測驗L_model_forward==============") X,parameters = testCases.L_model_forward_test_case() AL,caches = L_model_forward(X,parameters) print("AL = " + str(AL)) print("caches 的長度為 = " + str(len(caches)))
==============測驗L_model_forward============== AL = [[0.17007265 0.2524272 ]] caches 的長度為 = 2
計算成本
我們已經把這兩個模型的前向傳播部分完成了,我們需要計算成本(誤差),以確定它到底有沒有在學習,成本的計算公式如下:
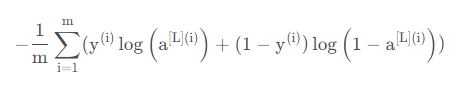
def compute_cost(AL,Y): """ 上面定義的成本函式, 引數: AL - 與標簽預測相對應的概率向量,維度為(1,示例數量) Y - 標簽向量(例如:如果不是貓,則為0,如果是貓則為1),維度為(1,數量) 回傳: cost - 交叉熵成本 """ m = Y.shape[1] cost = -np.sum(np.multiply(np.log(AL),Y) + np.multiply(np.log(1 - AL), 1 - Y)) / m cost = np.squeeze(cost) assert(cost.shape == ()) return cost
我們來測驗一下:
#測驗compute_cost print("==============測驗compute_cost==============") Y,AL = testCases.compute_cost_test_case() print("cost = " + str(compute_cost(AL, Y)))
==============測驗compute_cost============== cost = 0.414931599615397
我們已經把誤差值計算出來了,現在開始進行反向傳播
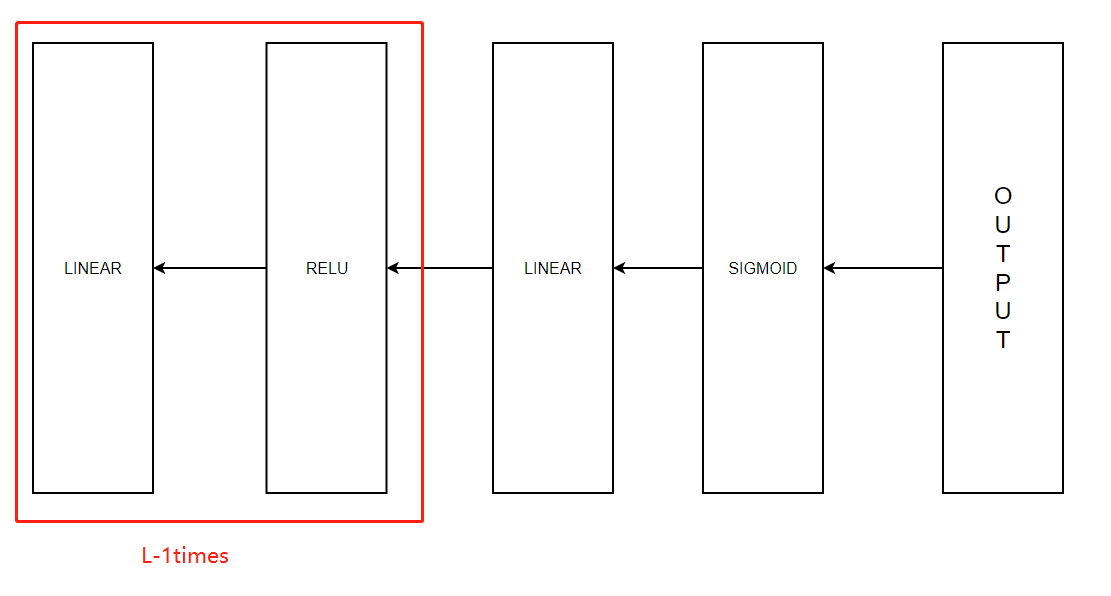
反向傳播
反向傳播用于計算相對于引數的損失函式的梯度,我們來看看向前和向后傳播的流程圖:
與前向傳播類似,我們有需要使用三個步驟來構建反向傳播:
LINEAR 后向計算
LINEAR -> ACTIVATION 后向計算,其中ACTIVATION 計算Relu或者Sigmoid 的結果
[LINEAR -> RELU] × \times× (L-1) -> LINEAR -> SIGMOID 后向計算 (整個模型)
我們來實作后向傳播線性部分:
def linear_backward(dZ,cache): """ 為單層實作反向傳播的線性部分(第L層) 引數: dZ - 相對于(當前第l層的)線性輸出的成本梯度 cache - 來自當前層前向傳播的值的元組(A_prev,W,b) 回傳: dA_prev - 相對于激活(前一層l-1)的成本梯度,與A_prev維度相同 dW - 相對于W(當前層l)的成本梯度,與W的維度相同 db - 相對于b(當前層l)的成本梯度,與b維度相同 """ A_prev, W, b = cache m = A_prev.shape[1] dW = np.dot(dZ, A_prev.T) / m db = np.sum(dZ, axis=1, keepdims=True) / m dA_prev = np.dot(W.T, dZ) assert (dA_prev.shape == A_prev.shape) assert (dW.shape == W.shape) assert (db.shape == b.shape) return dA_prev, dW, db
我們來測驗一下:
#測驗linear_backward print("==============測驗linear_backward==============") dZ, linear_cache = testCases.linear_backward_test_case() dA_prev, dW, db = linear_backward(dZ, linear_cache) print ("dA_prev = "+ str(dA_prev)) print ("dW = " + str(dW)) print ("db = " + str(db))
==============測驗linear_backward============== dA_prev = [[ 0.51822968 -0.19517421] [-0.40506361 0.15255393] [ 2.37496825 -0.89445391]] dW = [[-0.10076895 1.40685096 1.64992505]] db = [[0.50629448]]
線性激活部分【LINEAR -> ACTIVATION backward】
如果 g ( . ) 是激活函式, 那么sigmoid_backward 和 relu_backward 這樣計算:dZ[L]=dA[L]*g(Z[L])
我們先在正式開始實作后向線性激活:
def linear_activation_backward(dA,cache,activation="relu"): """ 實作LINEAR-> ACTIVATION層的后向傳播, 引數: dA - 當前層l的激活后的梯度值 cache - 我們存盤的用于有效計算反向傳播的值的元組(值為linear_cache,activation_cache) activation - 要在此層中使用的激活函式名,字串型別,【"sigmoid" | "relu"】 回傳: dA_prev - 相對于激活(前一層l-1)的成本梯度值,與A_prev維度相同 dW - 相對于W(當前層l)的成本梯度值,與W的維度相同 db - 相對于b(當前層l)的成本梯度值,與b的維度相同 """ linear_cache, activation_cache = cache if activation == "relu": dZ = relu_backward(dA, activation_cache) dA_prev, dW, db = linear_backward(dZ, linear_cache) elif activation == "sigmoid": dZ = sigmoid_backward(dA, activation_cache) dA_prev, dW, db = linear_backward(dZ, linear_cache) return dA_prev,dW,db
下面我們來測驗一下:
#測驗linear_activation_backward print("==============測驗linear_activation_backward==============") AL, linear_activation_cache = testCases.linear_activation_backward_test_case() dA_prev, dW, db = linear_activation_backward(AL, linear_activation_cache, activation = "sigmoid") print ("sigmoid:") print ("dA_prev = "+ str(dA_prev)) print ("dW = " + str(dW)) print ("db = " + str(db) + "\n") dA_prev, dW, db = linear_activation_backward(AL, linear_activation_cache, activation = "relu") print ("relu:") print ("dA_prev = "+ str(dA_prev)) print ("dW = " + str(dW)) print ("db = " + str(db))
==============測驗linear_activation_backward============== sigmoid: dA_prev = [[ 0.11017994 0.01105339] [ 0.09466817 0.00949723] [-0.05743092 -0.00576154]] dW = [[ 0.10266786 0.09778551 -0.01968084]] db = [[-0.05729622]] relu: dA_prev = [[ 0.44090989 -0. ] [ 0.37883606 -0. ] [-0.2298228 0. ]] dW = [[ 0.44513824 0.37371418 -0.10478989]] db = [[-0.20837892]]
我們已經把兩層模型的后向計算完成了,對于多層模型我們也需要這兩個函式來完成,我們來看一下流程圖:
在之前的前向計算中,我們存盤了一些包含包含(X,W,b和Z)的cache,我們將會使用它們來計算梯度值,
所以,在L層模型中,我們需要從L層遍歷所有的隱藏層,在每一步中,我們需要使用那一層的cache值來進行反向傳播,
我們開始構建多層模型向后傳播函式:
def L_model_backward(AL,Y,caches): """ 對[LINEAR-> RELU] *(L-1) - > LINEAR - > SIGMOID組執行反向傳播,就是多層網路的向后傳播 引數: AL - 概率向量,正向傳播的輸出(L_model_forward()) Y - 標簽向量(例如:如果不是貓,則為0,如果是貓則為1),維度為(1,數量) caches - 包含以下內容的cache串列: linear_activation_forward("relu")的cache,不包含輸出層 linear_activation_forward("sigmoid")的cache 回傳: grads - 具有梯度值的字典 grads [“dA”+ str(l)] = ... grads [“dW”+ str(l)] = ... grads [“db”+ str(l)] = ... """ grads = {} L = len(caches) m = AL.shape[1] Y = Y.reshape(AL.shape) dAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL)) current_cache = caches[L-1] grads["dA" + str(L)], grads["dW" + str(L)], grads["db" + str(L)] = linear_activation_backward(dAL, current_cache, "sigmoid") for l in reversed(range(L-1)): current_cache = caches[l] dA_prev_temp, dW_temp, db_temp = linear_activation_backward(grads["dA" + str(l+2)], current_cache, "relu") grads["dA" + str(l + 1)] = dA_prev_temp grads["dW" + str(l + 1)] = dW_temp grads["db" + str(l + 1)] = db_temp return grads
相信第一次看到for回圈的小伙伴會跟我一樣懵,我以我自己的理解來說明:
在同一層a的序號總是比W,b少1;
reversed將串列逆序變成了[L-2,L-3,L-4.....,2,1,0],又因為W沒有dw[0],subsequent全員+1;
千萬不要認為str(l+2)是L-2+2=L,串列的順序依舊是[0,1,2,3,4...],所以str(l+2)是str(0+2)=str(2)
測驗一下:
測驗L_model_backward print("==============測驗L_model_backward==============") AL, Y_assess, caches = testCases.L_model_backward_test_case() grads = L_model_backward(AL, Y_assess, caches) print ("dW1 = "+ str(grads["dW1"])) print ("db1 = "+ str(grads["db1"])) print ("dA0 = "+ str(grads["dA1"]))
==============測驗L_model_backward============== dW1 = [[0.41010002 0.07807203 0.13798444 0.10502167] [0. 0. 0. 0. ] [0.05283652 0.01005865 0.01777766 0.0135308 ]] db1 = [[-0.22007063] [ 0. ] [-0.02835349]] dA0 = [[ 0.12913162 -0.44014127] [-0.14175655 0.48317296] [ 0.01663708 -0.05670698]]
更新引數
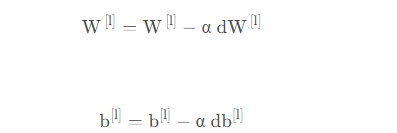
def update_parameters(parameters, grads, learning_rate): """ 使用梯度下降更新引數 引數: parameters - 包含你的引數的字典 grads - 包含梯度值的字典,是L_model_backward的輸出 回傳: parameters - 包含更新引數的字典 引數[“W”+ str(l)] = ... 引數[“b”+ str(l)] = ... """ L = len(parameters) // 2 #整除 for l in range(L): parameters["W" + str(l + 1)] = parameters["W" + str(l + 1)] - learning_rate * grads["dW" + str(l + 1)] parameters["b" + str(l + 1)] = parameters["b" + str(l + 1)] - learning_rate * grads["db" + str(l + 1)] return parameters
測驗一下:
#測驗update_parameters print("==============測驗update_parameters==============") parameters, grads = testCases.update_parameters_test_case() parameters = update_parameters(parameters, grads, 0.1) print ("W1 = "+ str(parameters["W1"])) print ("b1 = "+ str(parameters["b1"])) print ("W2 = "+ str(parameters["W2"])) print ("b2 = "+ str(parameters["b2"]))
==============測驗update_parameters============== W1 = [[-0.59562069 -0.09991781 -2.14584584 1.82662008] [-1.76569676 -0.80627147 0.51115557 -1.18258802] [-1.0535704 -0.86128581 0.68284052 2.20374577]] b1 = [[-0.04659241] [-1.28888275] [ 0.53405496]] W2 = [[-0.55569196 0.0354055 1.32964895]] b2 = [[-0.84610769]]
至此為止,我們已經實作該神經網路中所有需要的函式,接下來,我們將這些方法組合在一起,構成一個神經網路類,可以方便的使用,
建立兩層的神經網路:
我們正式開始構建兩層的神經網路:
def two_layer_model(X,Y,layers_dims,learning_rate=0.0075,num_iterations=3000,print_cost=False,isPlot=True): """ 實作一個兩層的神經網路,【LINEAR->RELU】 -> 【LINEAR->SIGMOID】 引數: X - 輸入的資料,維度為(n_x,例子數) Y - 標簽,向量,0為非貓,1為貓,維度為(1,數量) layers_dims - 層數的向量,維度為(n_y,n_h,n_y) learning_rate - 學習率 num_iterations - 迭代的次數 print_cost - 是否列印成本值,每100次列印一次 isPlot - 是否繪制出誤差值的圖譜 回傳: parameters - 一個包含W1,b1,W2,b2的字典變數 """ np.random.seed(1) grads = {} costs = [] (n_x,n_h,n_y) = layers_dims """ 初始化引數 """ parameters = initialize_parameters(n_x, n_h, n_y) W1 = parameters["W1"] b1 = parameters["b1"] W2 = parameters["W2"] b2 = parameters["b2"] """ 開始進行迭代 """ for i in range(0,num_iterations): #前向傳播 A1, cache1 = linear_activation_forward(X, W1, b1, "relu") A2, cache2 = linear_activation_forward(A1, W2, b2, "sigmoid") #計算成本 cost = compute_cost(A2,Y) #后向傳播 ##初始化后向傳播 dA2 = - (np.divide(Y, A2) - np.divide(1 - Y, 1 - A2)) ##向后傳播,輸入:“dA2,cache2,cache1”, 輸出:“dA1,dW2,db2;還有dA0(未使用),dW1,db1”, dA1, dW2, db2 = linear_activation_backward(dA2, cache2, "sigmoid") dA0, dW1, db1 = linear_activation_backward(dA1, cache1, "relu") ##向后傳播完成后的資料保存到grads grads["dW1"] = dW1 grads["db1"] = db1 grads["dW2"] = dW2 grads["db2"] = db2 #更新引數 parameters = update_parameters(parameters,grads,learning_rate) W1 = parameters["W1"] b1 = parameters["b1"] W2 = parameters["W2"] b2 = parameters["b2"] #列印成本值,如果print_cost=False則忽略 if i % 100 == 0: #記錄成本 costs.append(cost) #是否列印成本值 if print_cost: print("第", i ,"次迭代,成本值為:" ,np.squeeze(cost)) #迭代完成,根據條件繪制圖 if isPlot: plt.plot(np.squeeze(costs)) plt.ylabel('cost') plt.xlabel('iterations (per tens)') plt.title("Learning rate =" + str(learning_rate)) plt.show() #回傳parameters return parameters
train_set_x_orig , train_set_y , test_set_x_orig , test_set_y , classes = lr_utils.load_dataset() train_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).T test_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).T train_x = train_x_flatten / 255 train_y = train_set_y test_x = test_x_flatten / 255 test_y = test_set_y
資料集加載完成,開始正式訓練:
n_x = 12288 n_h = 7 n_y = 1 layers_dims = (n_x,n_h,n_y) parameters = two_layer_model(train_x, train_set_y, layers_dims = (n_x, n_h, n_y), num_iterations = 2500, print_cost=True,isPlot=True)
第 0 次迭代,成本值為: 0.6930497356599891 第 100 次迭代,成本值為: 0.6464320953428849 第 200 次迭代,成本值為: 0.6325140647912677 第 300 次迭代,成本值為: 0.6015024920354665 第 400 次迭代,成本值為: 0.5601966311605748 第 500 次迭代,成本值為: 0.515830477276473 第 600 次迭代,成本值為: 0.47549013139433266 第 700 次迭代,成本值為: 0.4339163151225749 第 800 次迭代,成本值為: 0.400797753620389 第 900 次迭代,成本值為: 0.3580705011323798 第 1000 次迭代,成本值為: 0.3394281538366412 第 1100 次迭代,成本值為: 0.30527536361962637 第 1200 次迭代,成本值為: 0.27491377282130186 第 1300 次迭代,成本值為: 0.2468176821061483 第 1400 次迭代,成本值為: 0.19850735037466102 第 1500 次迭代,成本值為: 0.1744831811255663 第 1600 次迭代,成本值為: 0.17080762978097416 第 1700 次迭代,成本值為: 0.11306524562164691 第 1800 次迭代,成本值為: 0.09629426845937152 第 1900 次迭代,成本值為: 0.08342617959726865 第 2000 次迭代,成本值為: 0.07439078704319084 第 2100 次迭代,成本值為: 0.06630748132267936 第 2200 次迭代,成本值為: 0.05919329501038171 第 2300 次迭代,成本值為: 0.05336140348560559 第 2400 次迭代,成本值為: 0.04855478562877018
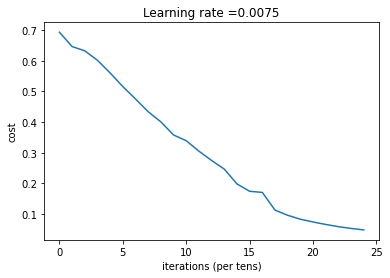
迭代完成之后我們就可以進行預測了,預測函式如下:
def predict(X, y, parameters): """ 該函式用于預測L層神經網路的結果,當然也包含兩層 引數: X - 測驗集 y - 標簽 parameters - 訓練模型的引數 回傳: p - 給定資料集X的預測 """ m = X.shape[1] n = len(parameters) // 2 # 神經網路的層數 p = np.zeros((1,m)) #根據引數前向傳播 probas, caches = L_model_forward(X, parameters) for i in range(0, probas.shape[1]): if probas[0,i] > 0.5: p[0,i] = 1 else: p[0,i] = 0 print("準確度為: " + str(float(np.sum((p == y))/m))) return p
預測函式構建好了我們就開始預測,查看訓練集和測驗集的準確性:
predictions_train = predict(train_x, train_y, parameters) #訓練集 predictions_test = predict(test_x, test_y, parameters) #測驗集
準確度為: 1.0 準確度為: 0.72
搭建多層神經網路
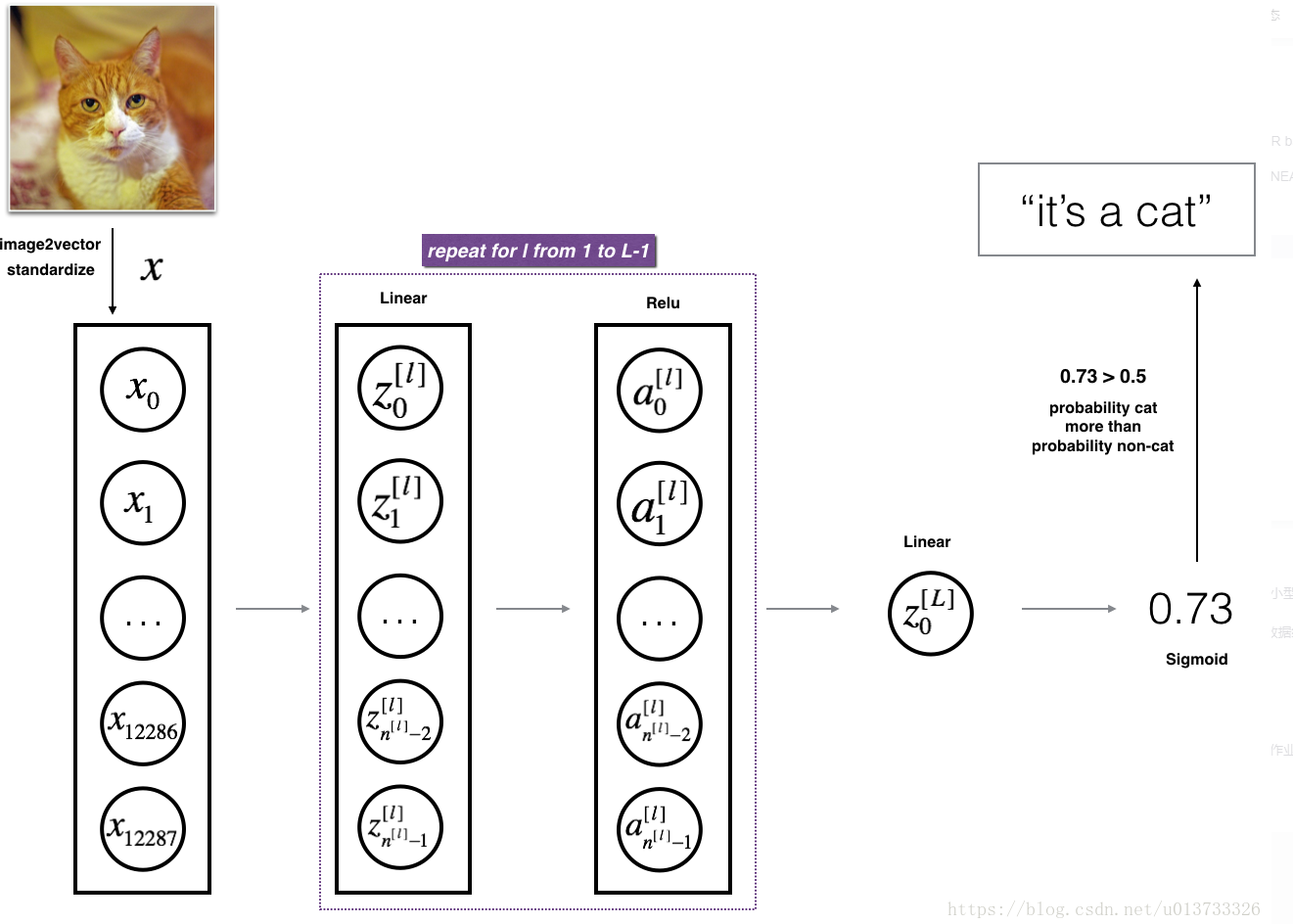
def L_layer_model(X, Y, layers_dims, learning_rate=0.0075, num_iterations=3000, print_cost=False,isPlot=True): """ 實作一個L層神經網路:[LINEAR-> RELU] *(L-1) - > LINEAR-> SIGMOID, 引數: X - 輸入的資料,維度為(n_x,例子數) Y - 標簽,向量,0為非貓,1為貓,維度為(1,數量) layers_dims - 層數的向量,維度為(n_y,n_h,···,n_h,n_y) learning_rate - 學習率 num_iterations - 迭代的次數 print_cost - 是否列印成本值,每100次列印一次 isPlot - 是否繪制出誤差值的圖譜 回傳: parameters - 模型學習的引數, 然后他們可以用來預測, """ np.random.seed(1) costs = [] parameters = initialize_parameters_deep(layers_dims) for i in range(0,num_iterations): AL , caches = L_model_forward(X,parameters) cost = compute_cost(AL,Y) grads = L_model_backward(AL,Y,caches) parameters = update_parameters(parameters,grads,learning_rate) #列印成本值,如果print_cost=False則忽略 if i % 100 == 0: #記錄成本 costs.append(cost) #是否列印成本值 if print_cost: print("第", i ,"次迭代,成本值為:" ,np.squeeze(cost)) #迭代完成,根據條件繪制圖 if isPlot: plt.plot(np.squeeze(costs)) plt.ylabel('cost') plt.xlabel('iterations (per tens)') plt.title("Learning rate =" + str(learning_rate)) plt.show() return parameters
我們現在開始加載資料集:
train_set_x_orig , train_set_y , test_set_x_orig , test_set_y , classes = lr_utils.load_dataset() train_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).T test_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).T train_x = train_x_flatten / 255 train_y = train_set_y test_x = test_x_flatten / 255 test_y = test_set_y
資料集加載完成,開始正式訓練:
layers_dims = [12288, 20, 7, 5, 1] # 5-layer model parameters = L_layer_model(train_x, train_y, layers_dims, num_iterations = 2500, print_cost = True,isPlot=True)
第 0 次迭代,成本值為: 0.715731513413713 第 100 次迭代,成本值為: 0.6747377593469114 第 200 次迭代,成本值為: 0.6603365433622127 第 300 次迭代,成本值為: 0.6462887802148751 第 400 次迭代,成本值為: 0.6298131216927773 第 500 次迭代,成本值為: 0.6060056229265339 第 600 次迭代,成本值為: 0.5690041263975134 第 700 次迭代,成本值為: 0.5197965350438059 第 800 次迭代,成本值為: 0.46415716786282285 第 900 次迭代,成本值為: 0.40842030048298916 第 1000 次迭代,成本值為: 0.37315499216069037 第 1100 次迭代,成本值為: 0.30572374573047123 第 1200 次迭代,成本值為: 0.2681015284774084 第 1300 次迭代,成本值為: 0.23872474827672574 第 1400 次迭代,成本值為: 0.20632263257914704 第 1500 次迭代,成本值為: 0.17943886927493524 第 1600 次迭代,成本值為: 0.15798735818801113 第 1700 次迭代,成本值為: 0.14240413012273798 第 1800 次迭代,成本值為: 0.1286516599788517 第 1900 次迭代,成本值為: 0.11244314998153365 第 2000 次迭代,成本值為: 0.08505631034962911 第 2100 次迭代,成本值為: 0.05758391198603161 第 2200 次迭代,成本值為: 0.04456753454692599 第 2300 次迭代,成本值為: 0.038082751665970464 第 2400 次迭代,成本值為: 0.034410749018399016
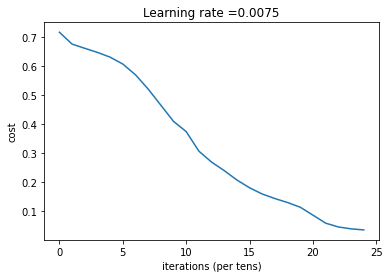
訓練完成,我們看一下預測:
pred_train = predict(train_x, train_y, parameters) #訓練集 pred_test = predict(test_x, test_y, parameters) #測驗集
準確度為: 0.9952153110047847 準確度為: 0.78
72%再到78%,可以看到的是準確度在一點點增加,當然,你也可以手動的去調整layers_dims,準確度可能又會提高一些,
分析
def print_mislabeled_images(classes, X, y, p): """ 繪制預測和實際不同的影像, X - 資料集 y - 實際的標簽 p - 預測 """ a = p + y mislabeled_indices = np.asarray(np.where(a == 1)) plt.rcParams['figure.figsize'] = (40.0, 40.0) # set default size of plots num_images = len(mislabeled_indices[0]) for i in range(num_images): index = mislabeled_indices[1][i] plt.subplot(2, num_images, i + 1) plt.imshow(X[:,index].reshape(64,64,3), interpolation='nearest') plt.axis('off') plt.title("Prediction: " + classes[int(p[0,index])].decode("utf-8") + " \n Class: " + classes[y[0,index]].decode("utf-8")) print_mislabeled_images(classes, test_x, test_y, pred_test)
 分析一下我們就可以得知原因了:
分析一下我們就可以得知原因了:
模型往往表現欠佳的幾種型別的影像包括:
- 貓身體在一個不同的位置
- 貓出現在相似顏色的背景下
- 不同的貓的顏色和品種
- 相機角度
- 圖片的亮度
- 比例變化(貓的影像非常大或很小)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/518966.html
標籤:其他
上一篇:SSH遠程登錄協議