摘要:openGemini是一個開源的分布式時序資料庫系統,可廣泛應用于物聯網、車聯網、運維監控、工業互聯網等業務場景,具備卓越的讀寫性能和高效的資料分析能力,
本文分享自華為云社區《華為云面向全球正式開放openGemini內核原始碼》,作者: 云資料庫創新Lab,
一、背景介紹
物聯網時代已經來臨,物聯網設備走進我們的日常生活,例如智能冰箱、電動汽車、智能手表等等,公開報告顯示,預計到2025年,中國的物聯網連接數會占到全球的30%,這些聯網的設備每時每刻都在產生大量的資料,每天的資料增長量可以達到GB級甚至TB級,給資料庫帶來非常大的挑戰,例如:高并發寫入大量資料導致資料入庫太慢,海量資料引起過高的存盤成本和查詢時延等等,時序場景作為物聯網領域的典型場景,與傳統關系型資料庫場景有很大區別,時序資料庫專為時序場景設計和優化,近年來開始受到越來越多的關注,
華為云整合產業和技術優勢,打造了業界領先的企業級時序資料庫GaussDB for Influx,并經過外部公有云業務服務化的錘煉以及內部DevOps等業務的長時間打磨,在大規模集群、高性能查詢、分級壓縮存盤等方面都有明顯優勢,今年6月,華為云宣布將GaussDB for Influx內核正式對外開源,開源品牌命名為openGemini,
openGemini是一個開源的分布式時序資料庫系統,可廣泛應用于物聯網、車聯網、運維監控、工業互聯網等業務場景,具備卓越的讀寫性能和高效的資料分析能力,
二、openGemini軟體架構
2.1架構設計
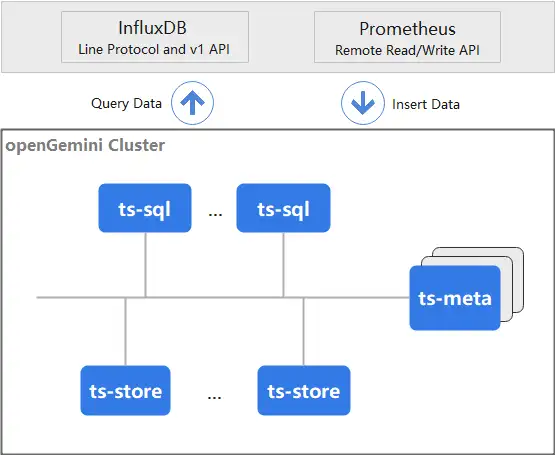
openGemini采用MPP 大規模并行處理分層架構,由ts-sql(計算引擎)、ts-store(存盤引擎)、ts-meta(元資料引擎)三大部分組成,openGemini既支持集群部署,也可以單機部署,
ts-sql:統一處理客戶端請求
- 提供RESTful介面
- 兼容InfluxDB Line Protocol和v1 API,同時也支持Prometheus的遠程資料讀寫
- 查詢陳述句執行期間,從ts-store獲取資料并匯總,并回傳客戶端
- 支持橫向擴展
ts-store:資料管理
- 將原始資料按優化設計的資料格式進行統一組織和存盤
- 按時間范圍和時間線ID查詢資料
- 支持橫向擴展
ts-meta:元資料管理
- 資料庫集群元資料管理,如節點資訊等
- 資料庫元資料管理,如資料保留時間、資料磁區資訊、表資訊等
2.2關鍵特性
高性能讀寫
- 每秒千萬級指標資料并發寫入,毫秒級查詢回應支持時序資料分析
- 內置AI資料分析演算法,支持實時例外檢測和預測
兼容時序生態
- 完全兼容InfluxDB Line Protocol 和 InfluxQL
- 無縫集成現有InfluxDB工具鏈
- 支持Prometheus遠程資料存盤
分布式
- 提供了水平擴展能力,支持數百節點集群規模
海量時序資料高效管理
- 支持億級時間線管理
- 內置高效資料壓縮演算法,存盤成本只有傳統關系資料庫的1/20
部署靈活
- 部署只需運行編譯生成的可執行檔案,無需外部依賴
- 所有資料庫配置引數均有合理的默認值,無需手動設定
- 支持單機和集群部署
三、openGemini有什么優勢
3.1性能優勢
針對物聯網、運維監控等領域海量資料管理和分析的需求,openGemini對計算引擎和存盤引擎做了大量的優化設計,
- 查詢引擎,實作了向量化、分布式計算、算子下推、預聚合等多種查詢優化和執行技術,提升了資料查詢效率,在工業物聯網、運維監控等場景中實作互動級的查詢時延,并且在超大資料基數(萬億級)的情況下,也能夠達到很低的查詢時延,
- 存盤引擎,設計列式資料存盤格式,將多元時間序列資料按時間對齊,減少時間戳的重復存盤,并開發了一套高效的存盤引擎,實作了資料有序存盤、資料磁區分級、資料預取、稀疏索引等豐富功能,
資料吞吐量和查詢時延是評價一個時序資料庫性能的關鍵指標,openGemini經過大量優化后,整體性能表現出色,下方的測驗結果顯示了openGemini 從4U擴展到32U的性能表現,可以看出:
- 從4U到32U,openGemini寫入性能可以線性擴展(擴展比為0.8)
- 從4U的155萬Metrics/s平穩增長到32U的560萬Metrics/s

在業界流行的時序資料庫Benchmark測驗工具TSBS的15個標準測驗場景中,openGemini性能表現優異,15個標準測驗場景可分為簡單查詢、中等查詢和復雜查詢三大型別:
- 簡單查詢:少量或者沒有使用函式或運算式,查詢時間范圍在24小時以內,查詢時延數毫秒,
- 中等查詢:使用多個函式或運算式,查詢時間范圍在幾周內,并且使用了GROUP BY分組,查詢時延在數十毫秒到數百毫秒,
- 復雜查詢:使用了多個聚合函式或運算式,按月或者按年為時間范圍查詢,查詢時延通常可能會達分鐘級,
openGemini相比開源InfluxDB,簡單查詢場景提升2倍多,中等查詢場景提升4倍多;復雜查詢場景下,openGemini依然可以快速回應,然而InfluxDB則出現OOM無法作業,

3.2豐富的資料分析能力
時序資料采集的最終目的是讓資料被理解和使用,資料分析是其中關鍵的一環,時序資料庫具有廣泛的應用場景,使得時序應用日益多樣化,資料分析需求在不斷變化和增加,這要求時序資料庫能快速應對不同資料分析需求,不斷豐富內部的分析算子,
與此同時,傳統的大資料分析工具(比如Spark、Flink等)過于厚重,部署成本高;搭配時序資料庫進行分析時,離資料較遠,資料分析實時性無法滿足要求,隨著物聯網、傳感器技術、5G的快速發展,迫切需要一種更有效的方法來處理海量、高速的時序資料,而用戶真正需要的是一個能夠以最低時延和最高吞吐量處理、檢測和預測資訊的系統,這樣的系統在業界開源的資料庫中少之又少,
相對應的,openGemini具有豐富的聚合分析算子(COUNT、SUM、MAX、MIN等共計60余種)、統計分析算子(PERCENTILE分位數、HISTOGRAM直方圖等)、例外檢測和預測算子(內置13種例外檢測器,可覆寫常見的離群點、數值變化、閾值、持續上升下降等時序例外場景),其中基于AI的例外檢測的實作程序中,充分考慮了資料分布,提供近資料計算能力,能提升端到端資料分析和計算效率,
3.3降低成本,增加效益
openGemini 源于華為云GaussDB for Influx,GaussDB for Influx已經在華為云許多內部重要業務上使用,通過技術的升級,替代了Cassandra、InfluxDB、HBase、OpenTSDB等多套系統部署,實作了降本增效,

openGemini在承載相同業務場景下,較原系統端到端時延減低50%,CPU資源上可以節省68%,記憶體資源可以節省50%,硬碟資源可以節省90%以上,
四、為什么開源
開源是開放創新的有效手段,是數字時代的事實標準和專利,DB-Engines的統計資料表明,從 2021 年開始,開源資料庫的流行指數已經超過商用資料庫,開源時序資料庫占比更是高達80%,openGemini時序資料庫作為基礎軟體,也需要擁抱開源,


源于開源,回饋開源
openGemini時序資料庫經歷了幾個發展階段,從最扯訓于開源InfluxDB的架構改造,到應對內部數十億海量時間線挑戰,再到自研資料庫引擎,一路打磨,經受住了華為云內、外部100余家用戶的生產檢驗,openGemini現在以及將來取得的成績,都離不開開源社區肥沃的土壤,openGemini的開源,希望可以倡導開源文化,以實際行動回饋開源,

開放合作,共建共享
我們深知獨木難成林,百川聚江海的道理,但開源生態建設并非朝夕之功,也并非一個企業自身就能完成,而是一個聚沙成塔、集腋成裘的程序,唯有攜手伙伴共建、共享,方能打造出健康繁榮的開源生態,我們希望把openGemini社區作為一個支點、一個開放創新平臺,通過釋放華為云內部多年積累的時序資料庫技術研發和應用的實踐經驗,吸引更多的伙伴與開發者參與貢獻,不斷改善openGemini生態和競爭力,持續打造開放的技術產品和應用生態,使能物聯網、工業互聯網等行業數字化轉型,促進產業協同,以應對生存環境愈發復雜,行業競爭愈發激烈,業務發展愈發多樣的數字化時代,
版本說明
本次發布的v0.1.0是具有完整時序資料庫功能的版本,詳細資訊請點擊查看用戶指南,
v0.1.0版本主要特性:
- 支持單機和分布式集群部署,高性能和可擴展
- 支持證書驗證和用戶鑒權
- 完全兼容InfluxDB Line Protocol v1、InfluxQL
- 支持Prometheus遠程資料讀寫
- 支持Linux作業系統
- 豐富的內核運行指標(60余項),提供指標監測的工具ts-monitor
詳細版本路標已發布,請前往社區查閱,
加入社區
為方便了解和參與社區貢獻,我們為您準備了貢獻指南,
其他
社區合作、尋求社區幫助、相關問題咨詢渠道:
- 推薦在GitHub上給社區提交Issue和Discussion
- 發送郵件到openGemini社區郵箱([email protected]),1-2個作業日內給與回復
- 加入openGemini社區微信交流群(微信添加 xiangyu5632,備注openGemini)
- 加入Slack,
openGemini官網主頁: http://www.openGemini.org/
openGemini開源地址: https://github.com/openGemini
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/519138.html
標籤:其他
下一篇:面試HTML CSS基礎