1 引言
Redis作為基于記憶體的非關系型的K-V資料庫,因讀寫回應快速、原子操作、提供了多種資料型別String、List、Hash、Set、Sorted Set、在專案中有著廣泛的使用,今天我們來探討下下Redis的資料結構是如何實作的,
2 資料存盤
2.1 RedisDB
Redis將資料存盤在redisDb中,默認0~15共16個db,每個庫都是獨立的空間,不必擔心key沖突問題,可通過select命令切換db,集群模式使用db0
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
...
} redisDb;
- dict:資料庫鍵空間,保存著資料庫中的所有鍵值對
- expires:鍵的過期時間,字典的鍵為鍵,字典的值為過期事件UNIX時間戳
2.2 Redis哈希表實作
2.2.1 哈希字典dict
K-V存盤我們最先想到的就是map,在Redis中通過dict實作,資料結構如下:
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
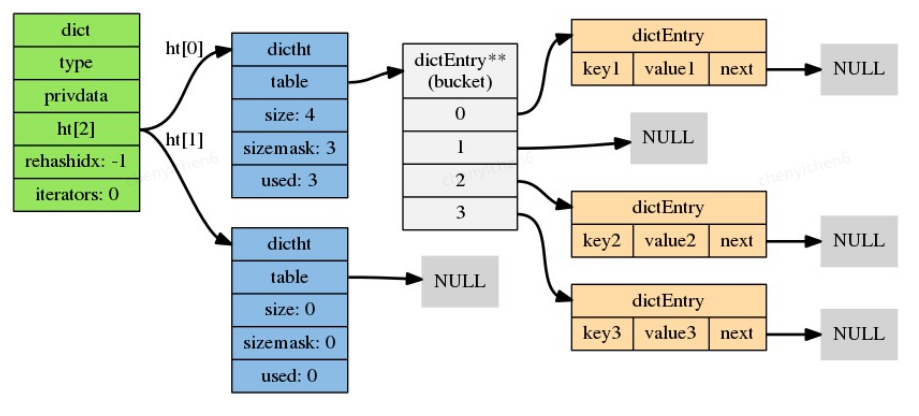
- type:型別特定函式是一個指向dictType結構的指標,每個dictType結構保存了一簇用于操作特定型別鍵值對的函式,Redis會為用途不同的字典設定不同的型別特定函式,
- privdata:私有資料保存了需要傳給那些型別特定函式的可選引數
- ht[2]:哈希表一個包含兩個項的陣列,陣列中的每個項都是一個dictht哈希表,一般情況下,字典只使用ht[0] 哈希表,ht[1]哈希表只會在對ht[0]哈希表進行rehash時使用
- rehashidx:rehash 索引,當rehash不在進行時,值為 -1
hash資料存在兩個特點:
- 任意相同的輸入一定能得到相同的資料
- 不同的輸入,有可能得到相同的輸出
針對hash資料的特點,存在hash碰撞的問題,dict通過dictType中的函式能夠解決這個問題
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
...
} dictType;
- hashFunction:用于計算key的hash值的方法
- keyCompare:key的值比較方法
2.2.2 哈希表 dictht
dict.h/dictht表示一個哈希表,具體結構如下:
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
- table:陣列指標,陣列中的每個元素都是一個指向dict.h/dictEntry結構的指標,每個dictEntry結構保存著一個鍵值對,
- size:記錄了哈希表的大小,也就是table陣列的大小,大小總是2^n
- sizemask:總是等于size - 1,這個屬性和哈希值一起決定一個鍵應該被放到table陣列的哪個索引上面,
- used:記錄了哈希表目前已有節點(鍵值對)的數量,
鍵值對dict.h/dictEntry
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
- key:保存著鍵值對中的鍵(SDS型別物件)
- val:保存著鍵值對中的值,可以是一個uint64_t整數,或者是一個int64_t整數,又或者是一個指標指向一個被redisObject包裝的值
- next:指向下個哈希表節點,形成鏈表指向另一個哈希表節點的指標,這個指標可以將多個哈希值相同的鍵值對連接在一次,以此來解決鍵沖突(collision)的問題
使用hash表就一定會存在hash碰撞的問題,hash碰撞后在當前陣列節點形成一個鏈表,在資料量超過hash表長度的情況下,就會存在大量節點稱為鏈表,極端情況下時間復雜度會從O(1)變為O(n);如果hash表的資料再不斷減少,會造成空間浪費的情況,Redis會針對這兩種情況根據負載因子做擴展與收縮操作:
- 負載因子:哈希表已保存節點數量/哈希表大小,load_factor = ht[0].used/ht[0].size
- 擴展操作:
- 服務器目前沒有在執行BGSAVE命令或者BGREWRITEAOF命令,并且哈希表的負載因子大于等于 1;
- 服務器目前正在執行BGSAVE命令或者BGREWRITEAOF命令,并且哈希表的負載因子大于等于5;
收縮操作:
- 當哈希表的負載因子小于 0.1 時, 程式自動開始對哈希表執行收縮操作,
Redis在擴容時如果全量擴容會因為資料量問題導致客戶端操作短時間內無法處理,所以采用漸進式 rehash進行擴容,步驟如下:
- 同時持有2個哈希表
- 將rehashidx的值設定為0,表示rehash作業正式開始
- 在rehash進行期間, 每次對字典執行添加、洗掉、查找或者更新操作時,程式除了執行指定的操作以外,還會順帶將ht[0]哈希表在rehashidx索引上的所有鍵值對rehash到ht[1] ,當rehash作業完成之后,程式將rehashidx屬性的值增一
- 某個時間點上,ht[0]的所有鍵值對都會被rehash至ht[1] ,這時程式將rehashidx屬性的值設為-1, 表示rehash操作已完成
在漸進式 rehash 進行期間,字典的洗掉(delete)、查找(find)、更新(update)等操作會在兩個哈希表上進行;在字典里面查找一個鍵的話, 程式會先在 ht[0] 里面進行查找,如果沒找到的話,就會繼續到ht[1]里面進行查找;新添加到字典的鍵值對一律會被保存到 ht[1] 里面,而ht[0]則不再進行任何添加操作:這一措施保證了ht[0]包含的鍵值對數量會只減不增(如果長時間不進行操作時,事件輪詢進行這種操作),并隨著rehash操作的執行而最終變成空表,
dict.h/redisObject
Typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
}
- type:4:約束客戶端操作時存盤的資料型別,已存在的資料無法修改型別,4bit
- encoding:4:值在redis底層的編碼模式,4bit
- lru:LRU_BITS:記憶體淘汰策略
- refcount:通過參考計數法管理記憶體,4byte
- ptr:指向真實存盤值的地址,8byte
完整結構圖如下:
3 String型別
3.1 String型別使用場景
String 字串存在有三種型別:字串,整數,浮點,主要有以下使用場景
1)頁面動態快取
比如生成一個動態頁面,首次可以將后臺資料生成頁面,并且存盤到redis字串中,再次訪問,不再進行資料庫請求,直接從redis中讀取該頁面,特點是:首次訪問比較慢,后續訪問快速,
2)資料快取
在前后分離式開發中,有些資料雖然存盤在資料庫,但是更改特別少,比如有個全國地區表,當前端發起請求后,后臺如果每次都從關系型資料庫讀取,會影響網站整體性能,
我們可以在第一次訪問的時候,將所有地區資訊存盤到redis字串中,再次請求,直接從資料庫中讀取地區的json字串,回傳給前端,
3)資料統計
redis整型可以用來記錄網站訪問量,某個檔案的下載量,(原子自增自減)
4)時間內限制請求次數
比如已登錄用戶請求短信驗證碼,驗證碼在5分鐘內有效的場景,當用戶首次請求了短信介面,將用戶id存盤到redis 已經發送短信的字串中,并且設定過期時間為5分鐘,當該用戶再次請求短信介面,發現已經存在該用戶發送短信記錄,則不再發送短信,
5)分布式session
當我們用nginx做負載均衡的時候,如果我們每個從服務器上都各自存盤自己的session,那么當切換了服務器后,session資訊會由于不共享而會丟失,我們不得不考慮第三應用來存盤session,通過我們用關系型資料庫或者redis等非關系型資料庫,關系型資料庫存盤和讀取性能遠遠無法跟redis等非關系型資料庫,
3.2 String型別的實作——SDS結構
Redis并沒有直接使用C字串實作String型別,在Redis3.2版本之前通過SDS實作
Typedef struct sdshdr {
int len;
int free;
char buf[];
};
- len:分配記憶體空間
- free:剩余可用分配空間
- char[]:value值實際資料
3.3 SDS與C字串之間的區別
3.3.1 查詢時間復雜度
C獲取字串長度的復雜度為O(N),而SDS通過len記錄長度,從C的O(n)變為O(1),
3.3.2 緩沖區溢位
C字串不記錄自身長度容易造成緩沖區溢位(buffer overflow),SDS的空間分配策略完全杜絕了發生緩沖區溢位的可能性,當需要對SDS進行修改時,會先檢查SDS的空間是否滿足修改所需的要求,如果不滿足的話SDS的空間擴展至執行修改所需的大小,然后才執行實際的修改操作,所以使用SDS既不需要手動修改SDS的空間大小,也不會出現緩沖區溢位問題,
在SDS中,buf陣列的長度不一定就是字符數量加一,陣列里面可以包含未使用的位元組,而這些位元組的數量就由SDS的free屬性記錄,通過未使用空間,SDS實作了空間預分配和惰性空間釋放兩種優化策略:
- 空間預分配:當對一個SDS進行修改,并且需要對SDS進行空間擴展的時候,程式不僅會為SDS分配修改所必須要的空間,還會為SDS分配額外的未使用空間,擴展SDS 空間之前,會先檢查未使用空間是否足夠, 如果足夠的話,就會直接使用未使用空間,而無須執行記憶體重分配,如果不夠根據(len + addlen(新增位元組)) * 2的方式進行擴容,大于1M時,每次只會增加1M大小,通過這種預分配策略,SDS將連續增長N次字串所需的記憶體重分配次數從必定N次降低為最多N次,
- 惰性空間釋放:惰性空間釋放用于優化SDS的字串縮短操作:當需要縮短SDS保存的字串時,程式并不立即使用記憶體重分配來回收縮短后多出來的位元組,而是使用free屬性將這些位元組的數量記錄起來,并等待將來使用,
3.3.3 二進制安全
C字串中的字符必須符合某種編碼(比如 ASCII,并且除了字串的末尾之外,字串里面不能包含空字符, 否則最先被程式讀入的空字符將被誤認為是字串結尾,
SDS的API都是二進制安全的(binary-safe):都會以處理二進制的方式來處理SDS存放在buf陣列里的資料,程式不會對其中的資料做任何限制、過濾、或者假設 —— 資料在寫入時是什么樣的,它被讀取時就是什么樣,redis不是用這個陣列來保存字符,而是用它來保存一系列二進制資料,
3.4 SDS結構優化
String型別所存盤的資料可能會幾byte存在大量這種型別資料,但len、free屬性的int型別會占用4byte共8byte存盤,3.2之后會根據字串大小使用sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64資料結構存盤,具體結構如下:
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
- unsign char flags:3bit表示型別,5bit表示未使用長度
- len:表示已使用長度
- alloc:表示分配空間大小,剩余空間大小可以使用alloc - len獲得
3.5 字符集編碼
redisObject包裝存盤的value值,通過字符集編碼對資料存盤進行優化,string型別的編碼方式有如下三種:
- embstr:
CPU每次按Cache Line 64byte讀取資料,一個redisObject物件為16byte,為填充64byte大小,會向后再讀取48 byte資料,但獲取實際資料時還需要再通過*ptr指標讀取對應記憶體地址的資料,而一個sdshdr8屬性的資訊占用4byte,其余44byte可以用來存盤資料,如果value值小于44,byte可以通過一次讀取快取行獲取資料,

- int:
如果SDS小于20位,并且能夠轉換成整型數字,redisObject的*ptr指標會直接進行存盤,

- raw:
SDS

4 總結
redis作為k-v資料存盤,因查找和操作的時間復雜度都是O(1)和豐富的資料型別及資料結構的優化,了解了這些資料型別和結構更有利于我們平時對于redis的使用,下一期將對其它常用資料型別List、Hash、Set、Sorted Set所使用的ZipList、QuickList、SkipList做進一步介紹,對于文章中不清晰不準確的地方歡迎大家一起討論交流,
作者:盛旭
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/519278.html
標籤:其他
上一篇:深度決議9種ScheduledThreadPoolExecutor的構造方法
下一篇:資料結構:線段樹基礎詳解