摘要:不少大公司的一個桶里都是幾億幾十億的物件,那他們都是怎么檢索的呢?
本文分享自華為云社區《物件存盤只能按檔案名搜索? 用 DWR + ElasticSearch 實作檔案名、檔案內容、圖片文字的模糊搜索!》,作者:云存盤開發者支持團隊 ,
眾所周知,由于物件存盤的架構限制,要想檢索物件存盤里的檔案,只能使用前綴的方式過濾,然后一頁一頁的列舉,限制多,效率低,要是桶內物件實在太多,可能光列舉就要列舉一兩天,你可能會問,不少大公司的一個桶里都是幾億幾十億的物件,那他們都是怎么檢索的呢?很簡單但很有效的方案——在上傳物件時候把物件資訊存到其他資料庫里,如 Elasticsearch、MongoDB、MySOL 等,然后在資料庫里檢索,
這種方案雖然見到有效,但修改成本極高,如果在業務設計初期沒有考慮到,或系統運行程序中想要添加些新的欄位,那就只能修改業務代碼并重新部署,要是再碰上有已分發客戶端的情況下還要推動客戶端升級才能解決,
有沒有升級簡單,不用改動業務代碼的方案呢?還真有,把存資料庫的程序轉移到物件存盤來做就好了,每次上傳物件之后,讓物件存盤幫你把物件資訊存一份到你指定的位置,本文我們嘗試通過 DWR 平臺來進行解決,DWR 是華為云推出的一個近資料計算平臺,簡單來說,通過 DWR 平臺,我們可以在不改動業務系統的情況下實作對物件的處理,如圖片上傳時把圖片轉成 JPG 格式并存盤在另一個桶里、在獲取圖片時給圖片加上水印等,DWR 將這一個個的能力都封裝成了“算子”,除了官方和第三方伙伴提供的算子外,我們也可以撰寫自定義算子來實作我們的其他定制類要求,
一、架構總覽
1.1 資料庫選型
物件存盤中一個物件(Object)由物件名(Key)、元資料(Metadata)、物件內容(Data)三部分組成,從原始需求出發,為了實作物件的模糊搜索,我們首先要把物件名存起來,進一步的,元資料中也包含了許多可以進行過略、排序用的資訊,如物件大小、最后修改時間、上傳時間、物件 Content-Type、自定義元資料等,其中自定義元資料中包含的 Key 的數目、value 型別都是可變的,為了方便存盤和檢索自定義元資料,不在每次想增加一個欄位時都去修改資料庫,我們首先就排除了傳統的關系型資料庫,
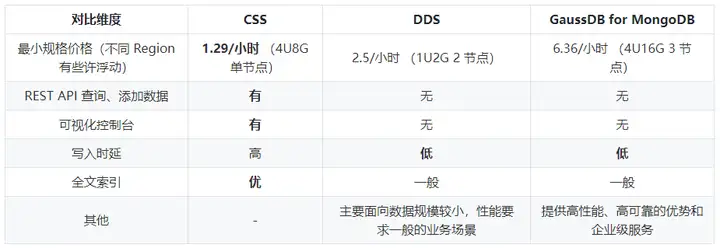
非關系型資料庫(NoSQL)中,比較符合我們要求的是兩款檔案型資料庫——MongoDB 與 Elasticsearch,從定位上來說,MongoDB 更偏向于資料庫,可以用作資料管理和資料搜索; CSS 則偏向于資料搜索服務,具體到我們這個場景,從訪問便捷度、最小規格價格幾個維度對比,最終選擇了選擇 CSS 服務,下表為華為云上的 DDS、CSS、GaussDB for NoSQL 的對比,大家也可以根據自己具體場景選擇合適的服務,
1.2 存盤物件資訊的整體流程
總的流程分 3 步:
1. 上傳檔案到物件存盤
2. DWR 自動觸發,保存需要的資訊到 CSS
3. 通過 API、kibana 等方式檢索 CSS 中存盤的資料
其中第二步還可以進行些進階的操作,例如上傳圖片時,檢測圖片中的文字資訊,一并存入資料庫;上傳視頻時,檢測把視頻大小、碼率、清晰度等資訊抽取出來存入資料庫…
二、購買與配置 CSS
2.1 購買 CSS
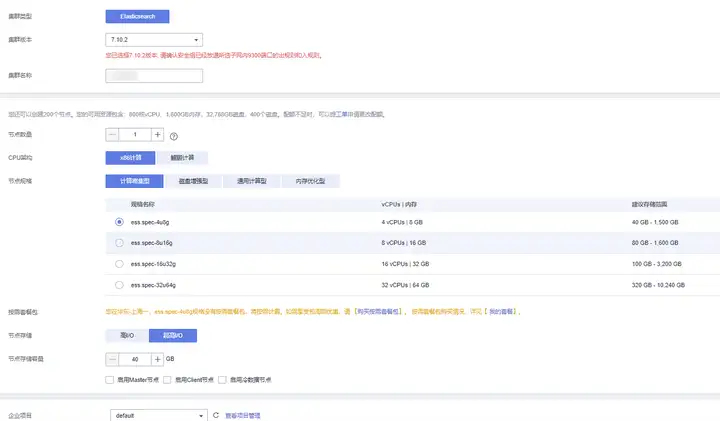
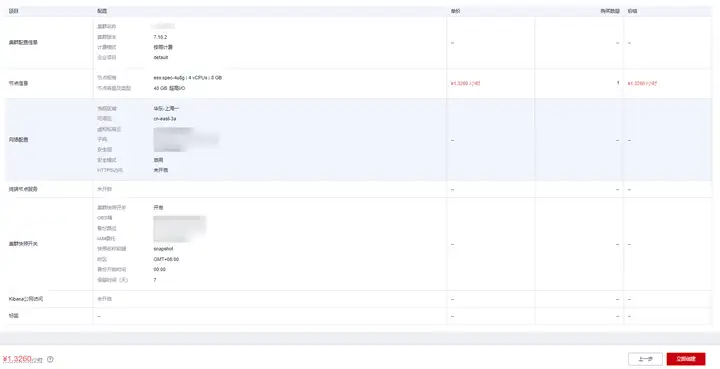
1.配置集群 控制臺找到 CSS 服務,點擊創建集群,集群版本選擇了 7.10.2,在此我們先選擇最低配的單節點,存盤選了超高 IO,
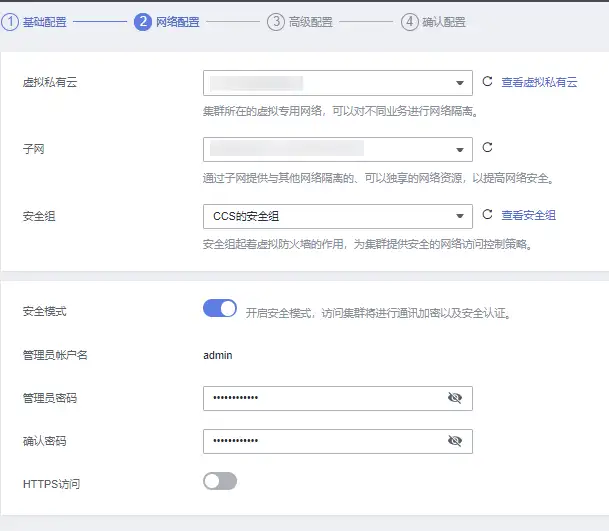
2.配置網路 需要注意,安全組一定要允許 9200 埠,集群在創建后不支持修改安全組,只能洗掉重新創建,如果只是在 VPC 內網訪問可以不開安全模式,要是想開放給公網訪問就必須開啟完全模式,
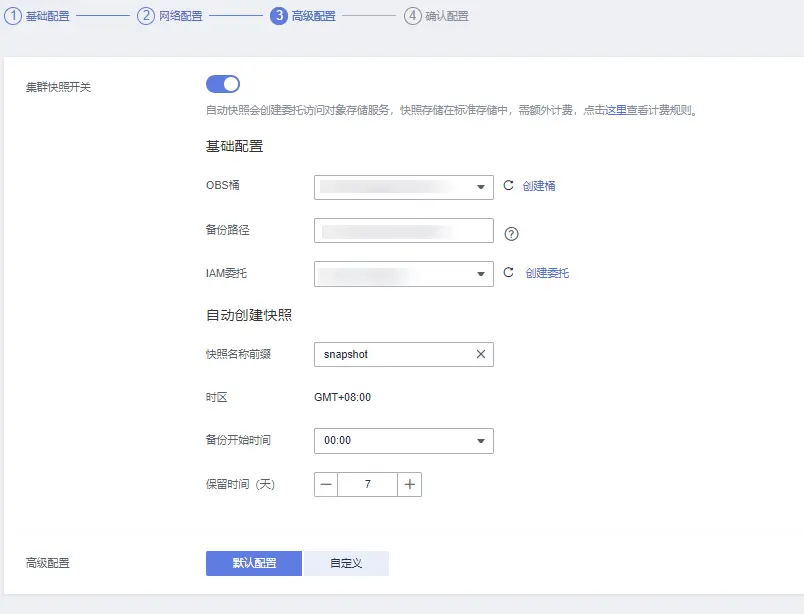
3.配置備份 建議開啟下資料備份,OBS 本身價格也不貴,還可以通過轉冷存盤進一步降低成本,資料多一份保護,萬一哪天誤刪了不用從頭挨個列舉,
4.完成配置 至此就完成了初始的配置,點擊立即申請即開始創建集群,
2.2 初始化 Mapping
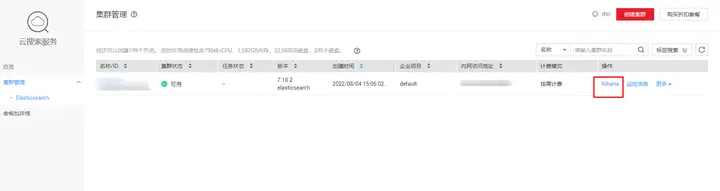
ES 中的 Mapping 大致可以類比為資料庫中的表結構,通過定義 mapping,可以指定欄位的存盤型別,我們目前需要的欄位如下,可以使用 CSS 自帶的 kibana 控制臺創建 Mapping,
在 CSS 控制臺找到 kibana,點擊跳轉后登錄,側邊欄找到 Dev Tools
把下面的代碼插入進去,點擊運行,記得把 your-bucket-name 替換成你實際要用的桶名,需要自己在 OBS 手動創建桶
PUT your-bucket-name { "mappings": { "dynamic": true, "properties": { "etag": { "type": "text" }, "expiration": { "type": "text" }, "content-type": { "type": "text" }, "date": { "type": "text" }, "content-length": { "type": "integer" }, "bucket_name": { "type": "text" }, "object_name": { "type": "text" }, "create_time": { "type": "integer" } } } }
三、配置 DWR
資料工坊(Data Workroom,DWR)是一款近資料處理服務,下層呼叫了函式服務 FunctionGraph 的能力,自定義算子本質上就是 FunctionGraph 的一個函式,為了開發自定義算子,我們首先要在 FunctionGraph 上創建一個自定義函式并測驗通過,
3.1 創建 FunctionGraph 函式
創建函式包含上傳依賴包、創建函式、創建委托、測驗函式幾個步驟,都不復雜,
3.1.1 上傳依賴包
本地 Python 操作 Elasticsearch 需要通過 pip 安裝 Elasticsearch Python 依賴,相應的,我們在函式作業流中呼叫也需要添加對應的依賴包,我們需要安裝7.10.1 版本的 elasticsearch ,
首先需要使用你對應 python 版本創建個新的虛擬環境,如果沒有新建,而你本地已經有了部分依賴,會導致依賴包裝不出來,
建議使用 Linux 環境打包依賴包,在 windows 環境下打包出的部分包可能不兼容 functionGraph 環境
# 安裝虛擬環境包,有的話可以跳過 pip install virtualenv # 創建 python 3.9 的虛擬環境 virtualenv fgpackage --python=3.9 # Linux 激活虛擬環境 source ./fgpackage/bin/activate # Windows 激活虛擬環境 # .\fgpackage\Scripts\activate # 安裝指定包到臨時目錄 pip install elasticsearch==7.10.1 --root \tmp\fgpackage
經過上面的操作,把就elasticsearch 和它們需要的依賴安裝到了 \tmp\fgpackage 下了,一層一層進入 \tmp\es_package,一直到 site-packages 一層,全選后添加到一個壓縮包內,
在函式串列頁點擊函式-依賴包管理-添加依賴包
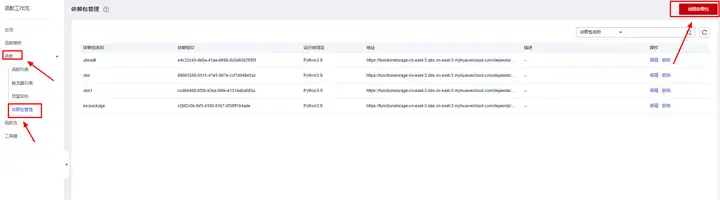
運行語言選 Python3.9,上傳剛剛打包的壓縮檔案點擊確定即可,
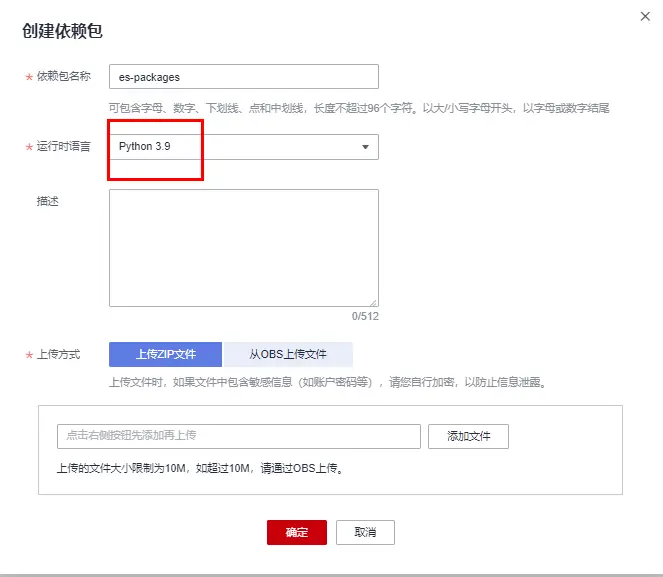
更多可參考 官方添加依賴說明
3.1.2 創建函式
控制臺找到 FuntionGraph 服務,點擊創建函式,
選擇空白函式,運行時選擇為 Python 3.9 (話說把 Runtime 翻譯成運行時好奇怪,這種專有詞是不是最好別強行翻譯?);委托需要具有 VPC Administrator 與 Tenant Administrator 兩個權限,用以訪問其他云服務和 VPC 內網資源,如果有現成的可以直接選擇,沒有的話點擊創建委托進入創建頁,參考下一節進行創建,然后重繪下選擇即可,
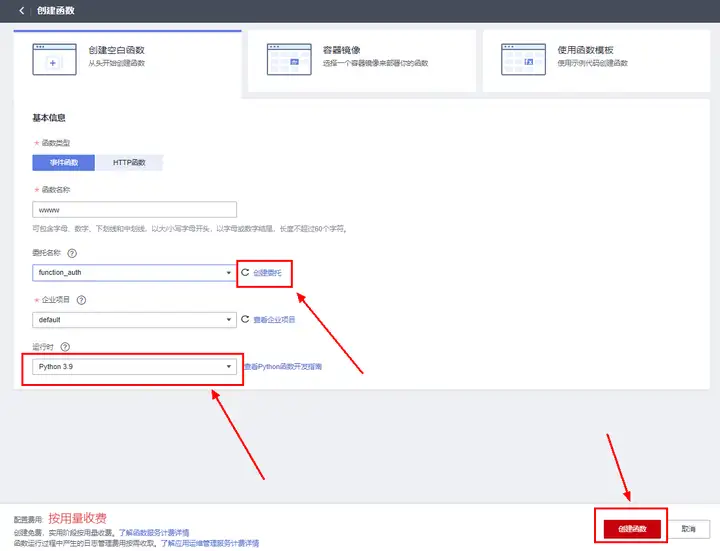
點擊完成創建,
3.1.3 創建委托
委托需要有 VPC Administrator 與 Tenant Administrator 兩個權限,如果已有可以直接跳過,上一節中的創建函式位置點擊 創建委托 跳轉到委托創建頁,點擊創建委托,
委托型別選擇云服務
權限選擇 VPC Administrator 與 Tenant Administrator 兩個權限

授權范圍選擇所有資源,或跟你需要自己配置
點擊完成即可,
3.1.4 填寫代碼
創建過函式后,會進入函式編輯頁面,將下面的代碼寫到編輯器里,點擊下部署,或鍵盤按 Ctrl + S 進行部署
# -*- coding:utf-8 -*- import time from urllib.parse import unquote_plus from elasticsearch import Elasticsearch from obs import ObsClient def handler(event, context): # 獲取桶名與物件名 region_id, bucket_name, object_name = get_obs_obj_info(event.get("Records", None)[0]) context.getLogger().info(f"bucket name: {bucket_name}, object key: {object_name}") ak = context.getAccessKey() sk = context.getSecretKey() server = 'obs.' + region_id + '.myhuaweicloud.com' context.getLogger().info("before token") context.getLogger().info(context.getToken()) context.getLogger().info("finish token") obs_client = ObsClient(access_key_id=ak, secret_access_key=sk, server=server) # 獲取物件元資料 object_metadata = obs_client.getObjectMetadata(bucket_name, object_name) # 將頭域轉為字典 info_dict = {i[0]: i[1] for i in object_metadata["header"]} info_dict["bucket_name"] = bucket_name info_dict["object_name"] = object_name # 為了不同系統下時區轉換導致時間不統一,這里不使用 OBS 里的 last-modified 的 GMT 時間,改用時間戳 info_dict["create_time"] = int(time.time()) # 把物件大小轉為數字格式 info_dict["content-length"] = int(info_dict["content-length"]) # 去除部分無用的 header for i in ["id-2", "request-id", "connection", "last-modified", "uploadid"]: if i in info_dict: info_dict.pop(i) # 把其他算子里包含的資訊也一起保存下來 if "other_info" in event["dynamic_source"]: info_dict.update(event["dynamic_source"]["other_info"]) context.getLogger().info(f"metadata to save: {info_dict}") es_user = event["dynamic_source"]["es_user"] es_password = event["dynamic_source"]["es_password"] es_server_ip = event["dynamic_source"]["es_server"] es_port = event["dynamic_source"]["es_port"] context.getLogger().info(es_port) if es_user != "" and es_password != "": es_server = f"https://{es_user}:{es_password}@{es_server_ip}:{es_port}" context.getLogger().info(es_server.replace(es_password, "xxxxxxx")) else: es_server = f"http://{es_server_ip}:{es_port}" context.getLogger().info(es_server) es = Elasticsearch([es_server], ca_certs=False, verify_certs=False) response = es.index(index=bucket_name, body=info_dict) context.getLogger().info(response) return { "statusCode": 200, "isBase64Encoded": False, "body": response, "headers": { "Content-Type": "application/json" } } def get_obs_obj_info(record): if 's3' in record: s3 = record['s3'] return record["eventRegion"], s3['bucket']['name'], unquote_plus(s3['object']['key']) else: obs_info = record['obs'] return record["eventRegion"], obs_info['bucket']['name'], \ unquote_plus(obs_info['object']['key'])
3.1.5 配置函式
1.配置依賴 在代碼配置頁最下找到添加依賴包按鈕,分別添加公共依賴中的OBS 3.21.8 與 私有依賴中的fgpackage
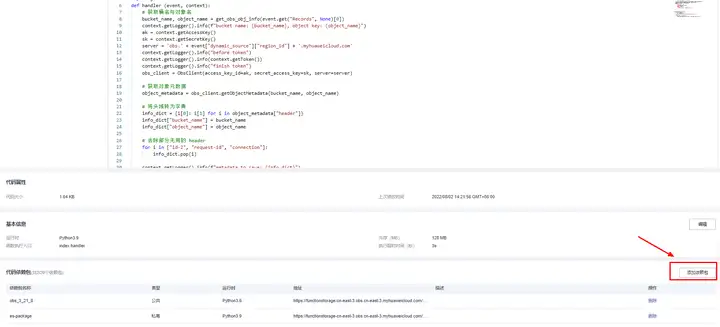
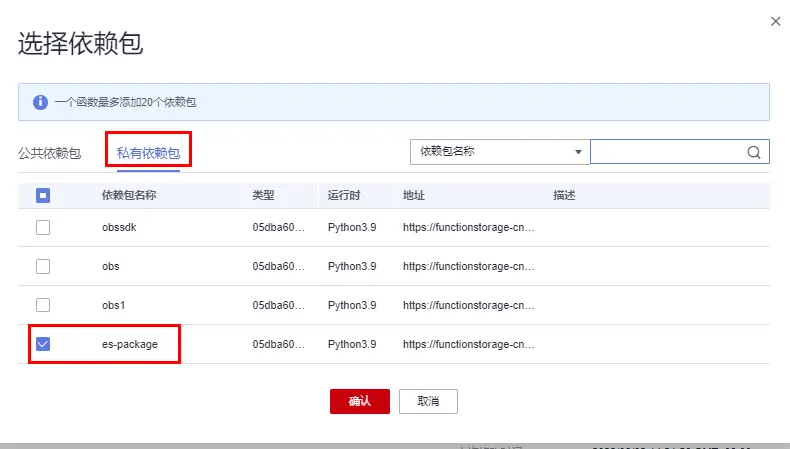

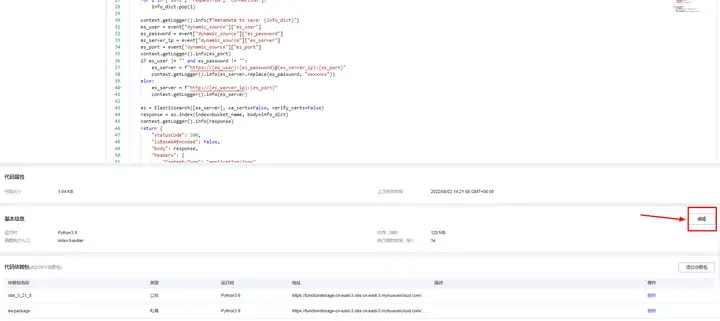
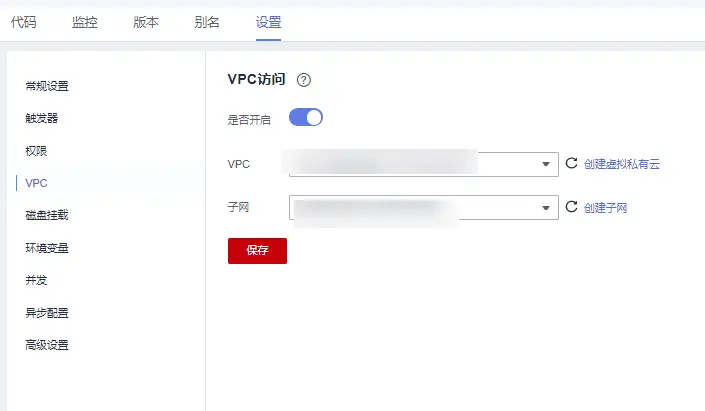
2.配置 VPC 還是代碼配置頁,點擊基本資訊的編輯按鈕,這里要記得與 2.1 節中的 CSS 選擇同一個 VPC,
3.1.6 測驗函式
在 OBS 里創建一個桶,最好和 CSS、FunctionGraph 都在同一個 Region,我用的上海一節點,region id 為 cn-east-3 桶內隨便上傳一個物件做備用,然后點擊函式代碼頁中配置測驗事件,把下面這段 Json 添加進去,并修改下面的配置為你的配置,其中 es_server 的值為 CSS 集群 IP,
{ "Records": [ { "eventRegion": "cn-east-3", "obs": { "bucket": { "name": "your-bucket-name" }, "object": { "key": "your-object-name" } } } ], "dynamic_source": { "es_server": "your-CSS-endpoint", "es_user": "admin", "es_password": "your-CSS-password", "es_port": 9200 } }
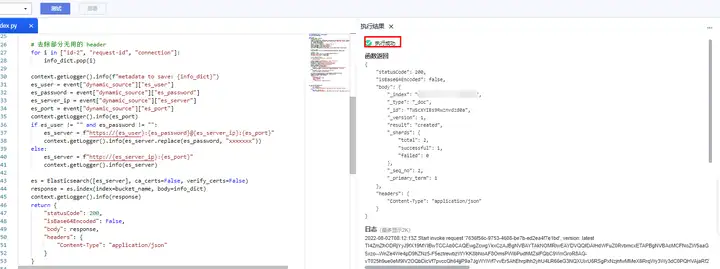
保存后點擊測驗,如果一切配置正確,右邊會出現這樣的結果,如果提示執行失敗,就看下下面報錯,再找找前面幾步哪個寫錯了,
3.2 配置 DWR 作業流
DWR 現在還在公測中,需要點擊申請公測,資訊隨便填就可以,目測是自動審核的,點完申請就通知申請成功了,
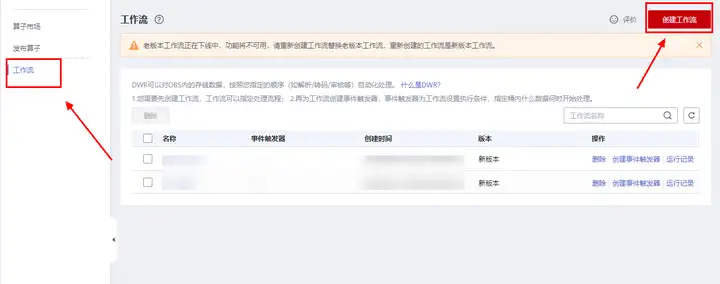
進入頁面,點擊作業流選項-創建作業流
左側把自定義算子拖到中間,和 Start、End 連上線,函式選擇剛剛創建的函式,再填寫下引數,這里的引數就是上一節 Json 檔案里 dynamic_source 欄位的引數即可,
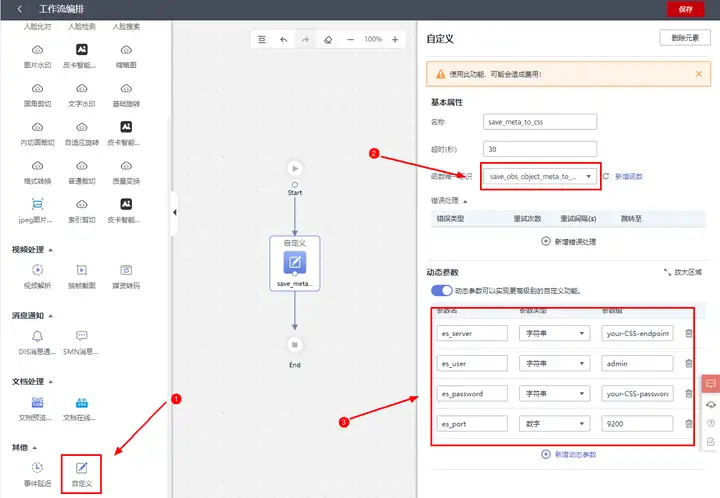
點擊保存,寫上名字,會自動跳轉出來,創建個觸發器再
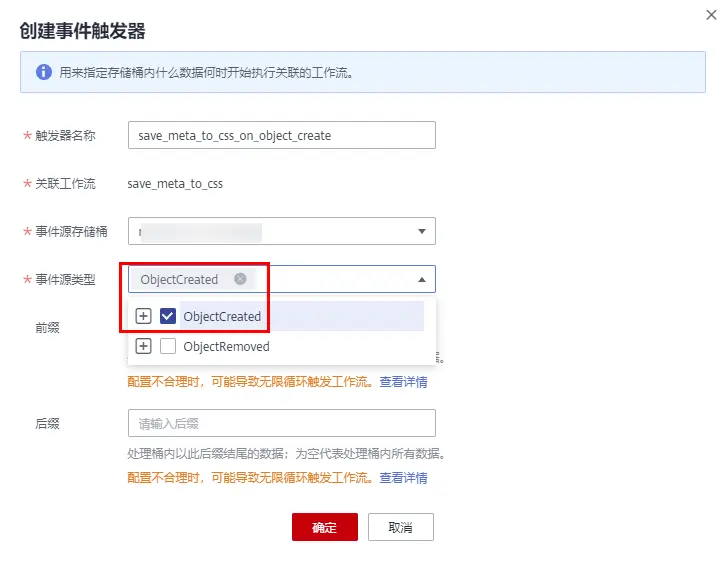
這里我沒有寫前綴和后綴,對桶內所有物件生效,如果填了前綴后綴,則會只匹配指定事件,
四、檢索
到現在所有配置都完成了,使用 OBS Browser+ 向桶里上傳幾個測驗檔案,然后用自己熟悉 Elasticsearch 呼叫方法嘗試下檢索,我這里使用 CSS 自帶的 kibana 控制臺,
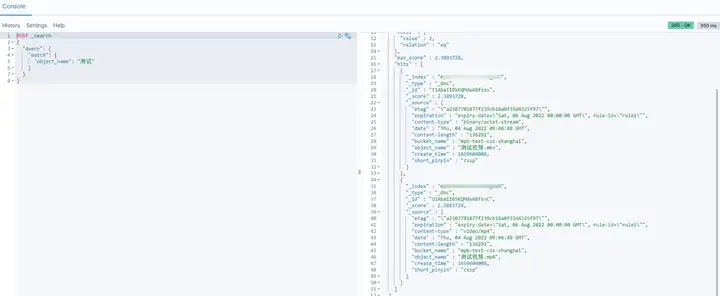
4.1 檢索名字里包含測驗 兩個字的物件
測驗代碼:
POST _search { "query": { "match": { "object_name": "測驗" } } }
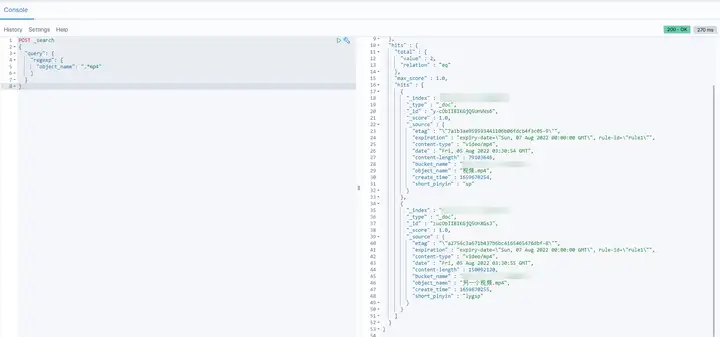
4.2 檢索為 .mp4 結尾的物件
POST _search { "query": { "regexp": { "object_name": ".*mp4" } } }
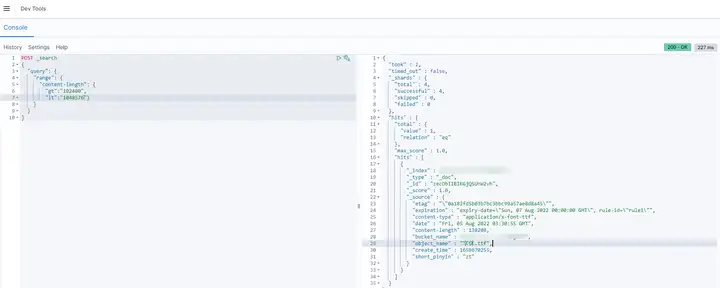
4.3 檢索大小介于 100k 到 1M 的物件
POST _search { "query": { "range": { "content-length": { "gt":"102400", "lt":"1048576"} } } }
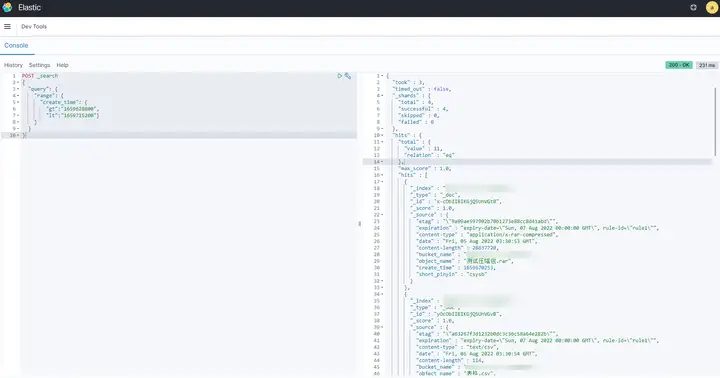
4.4 檢索創建時間在 2022 年 8 月 5 日與 2022 年 8 月 6 日之間的物件(時間戳)
POST _search { "query": { "range": { "create_time": { "gt":"1659628800", "lt":"1659715200"} } } }
五、再進一步
有的同學可能注意到了,流程介紹時我提到可以進行進階的操作,存入 CSS 的算子上頭可以拼接很多其他算子,算子的代碼包里也留了一個小擴展,可以從上一個算子中讀取 other_info 并一起保存,這個能干點啥嘞,咱們舉幾個場景:
- 把物件名縮寫存起來,如一個檔案叫我的檔案.txt,只用輸入 wdwj 就能找到該檔案的全稱
- 圖片檔案上傳后,呼叫 AI 給圖片打個標簽,把標簽存到資料庫,可以通過風景、美食、貓咪 等關鍵詞檢索到圖片,現在華為鴻蒙、蘋果 iOS 都有這樣的功能
- 圖片包含文字的話,把文字識別出來存入資料庫,可以通過文字搜索圖片,在某些業務系統里還可以用專用的算子,如發票識別、身份證識別等,
…
這里先把最簡單的物件名縮寫給個示例,拋磚引玉,大家可以自行嘗試更多功能,
用了xpinyin 這個庫,上傳依賴包步驟參考前面的介紹,代碼很簡單:
# coding:utf-8 from urllib.parse import unquote_plus from xpinyin import Pinyin def handler(event, context): # 獲取桶名與物件名 _, _, object_name = get_obs_obj_info(event.get("Records", None)[0]) context.getLogger().info(f"Object name is {object_name}") pinyin = Pinyin() pinyin = pinyin.get_pinyin(object_name, '-') short_pinyin = "".join([i[0] for i in pinyin.split("-") if i[0].isalpha()]) if "other_info" in event["dynamic_source"]: event["dynamic_source"]["other_info"]["short_pinyin"] = short_pinyin else: event["dynamic_source"]["other_info"] = {"short_pinyin": short_pinyin} context.getLogger().info(f"Object short name is {short_pinyin}") context.getLogger().info(event) return event def get_obs_obj_info(record): if 's3' in record: s3 = record['s3'] return record["eventRegion"], s3['bucket']['name'], unquote_plus(s3['object']['key']) else: obs_info = record['obs'] return record["eventRegion"], obs_info['bucket']['name'], \ unquote_plus(obs_info['object']['key'])
這就配置完了,只用去 DWR 作業流頁面創建個作業流,把這個函式加載前面:

給作業流配置個觸發器,然后把之前創建的作業流先洗掉掉,以免重復觸發,再上傳幾個檔案,
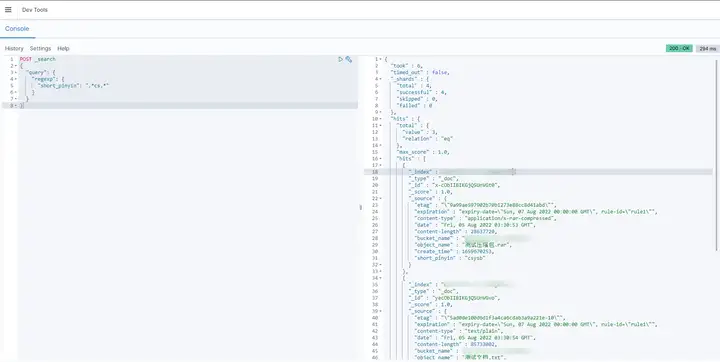
搜索下包含 cs 的物件
POST _search { "query": { "regexp": { "short_pinyin": ".*cs.*" } } }
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/519296.html
標籤:其他
上一篇:【遠程訪問與設備重定向】上海道寧為您助您遠程共享USB設備與USB設備重定向到遠程會話
下一篇:NFS共享檔案服務