3.1基本概念
路徑和路徑長度:樹中一個結點到另一個結點之間的分支構成這兩個結點之間的路徑;路徑上的分枝數目稱作路徑長度,它等于路徑上的結點數減1.
結點的權和帶權路徑長度:在許多應用中,常常將樹中的結點賦予一個有著某種意義的實數,我們稱此實數為該結點的權;結點的帶權路徑長度規定為從樹根結點到該結點之間的路徑長度與該結點上權的乘積.
樹的帶權路徑長度:為樹中所有葉子結點的帶權路徑長度之和,公式為:WPL = $$ \sum_{i=1}^{n} w_il_i $$
其中,n表示葉子結點的數目,wi和li分別表示葉子結點ki的權值和樹根結點到ki之間的路徑長度,
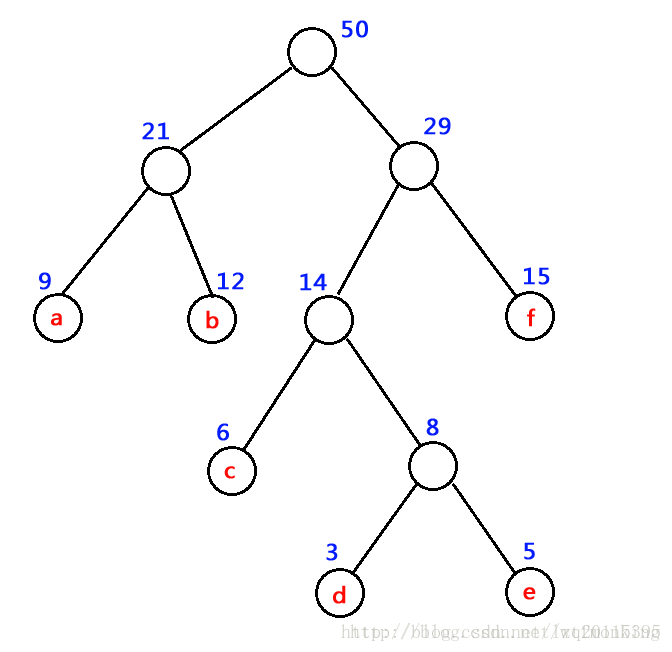
如下圖中樹的帶權路徑長度 WPL = 9 x 2 + 12 x 2 + 15 x 2 + 6 x 3 + 3 x 4 + 5 x 4 = 122
哈夫曼樹:哈夫曼樹又稱最優二叉樹,它是 n 個帶權葉子結點構成的所有二叉樹中,帶權路徑長度 WPL 最小的二叉樹,如下圖為一哈夫曼樹示意圖,
3.2 構建哈夫曼樹
假設有n個權值,則構造出的哈夫曼樹有n個葉子結點, n個權值分別設為 w1、w2、…、wn,則哈夫曼樹的構造規則為:
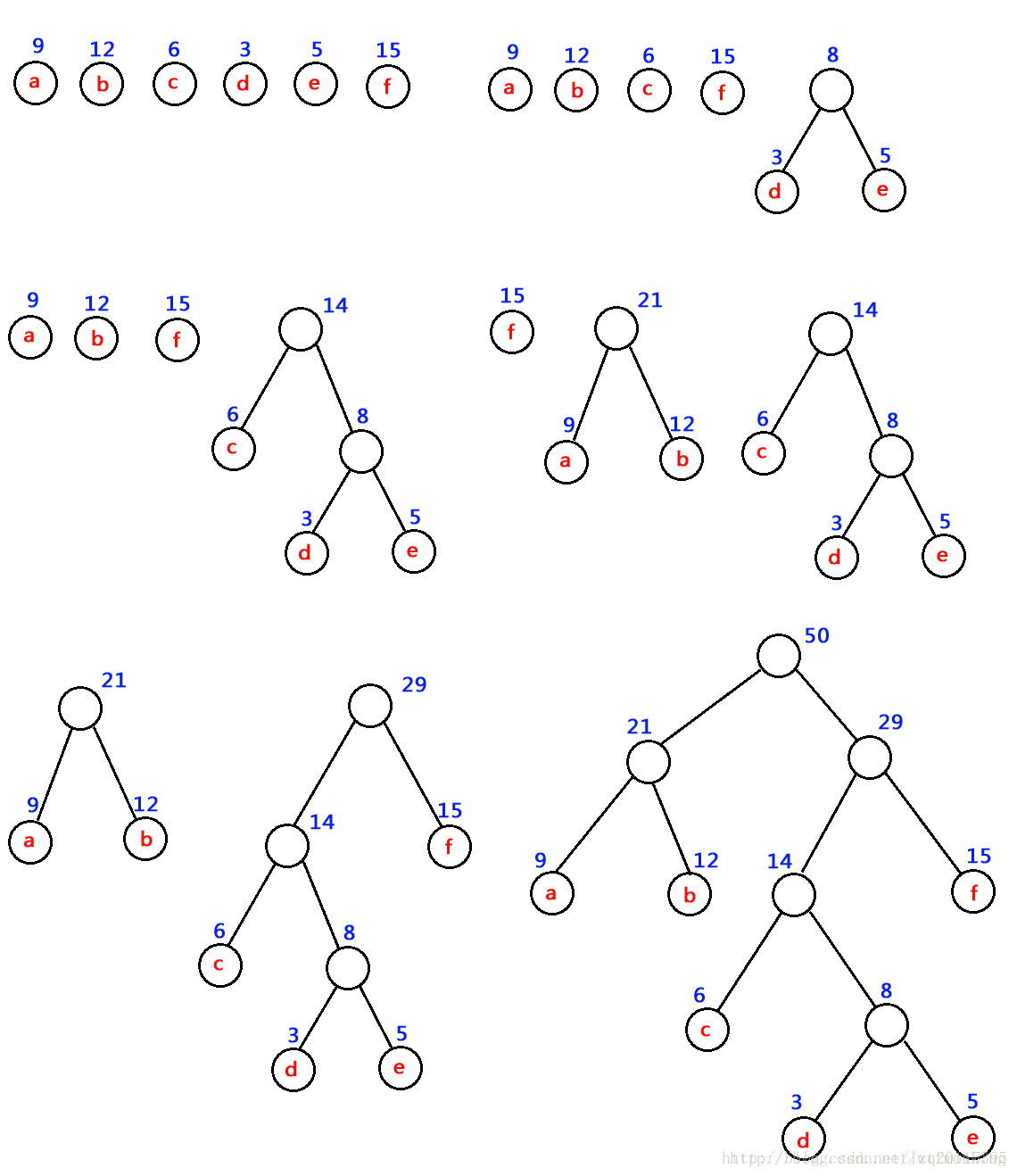
- 將w1、w2、…,wn看成是有n 棵樹的森林(每棵樹僅有一個結點);
- 在森林中選出兩個根結點的權值最小的樹合并,作為一棵新樹的左、右子樹,且新樹的根結點權值為其左、右子樹根結點權值之和;
- 從森林中洗掉選取的兩棵樹,并將新樹加入森林;
- 重復(2)、(3)步,直到森林中只剩一棵樹為止,該樹即為所求得的哈夫曼樹,
如:對 下圖中的六個帶權葉子結點來構造一棵哈夫曼樹,步驟如下:
注意:為了使得到的哈夫曼樹的結構盡量唯一,通常規定生成的哈夫曼樹中每個結點的左子樹根結點的權小于等于右子樹根結點的權,如果還是不清楚程序,可以參考https://jingyan.baidu.com/article/a501d80c16dfa0ec620f5e70.html,程序介紹的更清晰,
3.3 哈夫曼編碼
- 等長編碼:這種編碼方式的特點是每個字符的編碼長度相同(編碼長度就是每個編碼所含的二進制位數),假設字符集只含有4個字符A,B,C,D,用二進制兩位表示的編碼分別為00,01,10,11,若現在有一段電文為:ABACCDA,則應發送二進制序列:00010010101100,總長度為14位,當接收方接收到這段電文后,將按兩位一段進行譯碼,這種編碼的特點是譯碼簡單且具有唯一性,但編碼長度并不是最短的,
- 不等長編碼:在傳送電文時,為了使其二進制位數盡可能地少,可以將每個字符的編碼設計為不等長的,使用頻度較高的字符分配一個相對比較短的編碼,使用頻度較低的字符分配一個比較長的編碼,例如,可以為A,B,C,D四個字符分別分配0,00,1,01,并可將上述電文用二進制序列:000011010發送,其長度只有9個二進制位,但隨之帶來了一個問題,接收方接到這段電文后無法進行譯碼,因為無法斷定前面4個0是4個A,1個B、2個A,還是2個B,即譯碼不唯一,因此這種編碼方法不可使用,
因此,為了設計長短不等的編碼,以便減少電文的總長,還必須考慮編碼的唯一性,即在建立不等長編碼時必須使任何一個字符的編碼都不是另一個字符的前綴,這宗編碼稱為前綴編碼(prefix code),
- 利用字符集中每個字符的使用頻率作為權值構造一個哈夫曼樹;
- 從根結點開始,為到每個葉子結點路徑上的左分支賦予0,右分支賦予1,并從根到葉子方向形成該葉子結點的編碼.
假設一個文本檔案TFile中只包含7個字符{a,b,c,d,e,f},這7個字符在文本中出現的次數為{9,12,6,3,5,15}
通過哈夫曼樹來構造的編碼稱為哈弗曼編碼(huffman code)
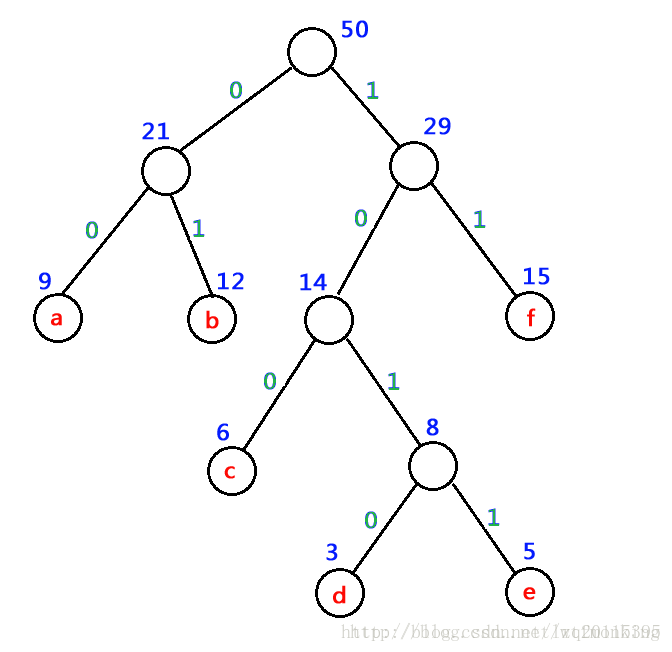
- a 的編碼為:00
- b 的編碼為:01
- c 的編碼為:100
- d 的編碼為:1010
- e 的編碼為:1011
- f 的編碼為:11
3.4 Python實作
- 若帶編碼字符的個數,即樹中葉結點的最大個數為n時,哈夫曼樹的總節點數為2n-1
# 節點類
class Node(object):
def __init__(self, name=None, value=https://www.cnblogs.com/minqiliang/archive/2022/10/26/None):
self._name = name
self._value = value
self._left = None
self._right = None
# 哈夫曼樹類
class HuffmanTree(object):
# 根據Huffman樹的思想:以葉子節點為基礎,反向建立Huffman樹
def __init__(self, char_weights):
self.a = [Node(part[0], part[1]) for part in char_weights] # 根據輸入的字符及其頻數生成葉子節點
while len(self.a) != 1:
self.a.sort(key=lambda node: node._value, reverse=True)
c = Node(value=(self.a[-1]._value + self.a[-2]._value))
c._left = self.a.pop(-1)
c._right = self.a.pop(-1)
self.a.append(c)
self.root = self.a[0]
self.b = list(range(10)) # self.b用于保存每個葉子節點的Haffuman編碼,range的值只需要不小于樹的深度就行
# 用遞回的思想生成編碼
def pre(self, tree, length):
node = tree
if not node:
return
elif node._name:
print(node._name +'的編碼為:',end=" ")
for i in range(length):
print(self.b[i],end="")
print()
return
self.b[length] = 0
self.pre(node._left, length + 1)
self.b[length] = 1
self.pre(node._right, length + 1)
# 生成哈夫曼編碼
def get_code(self):
self.pre(self.root, 0)
if __name__ == '__main__':
# 輸入的是字符及其頻數
char_weights = [('A', 27), ('B', 8), ('C', 15), ('D', 6), ('E', 30), ('F', 5)]
tree = HuffmanTree(char_weights)
tree.get_code()
輸出結果為:
C的編碼為: 00
B的編碼為: 010
F的編碼為: 0110
D的編碼為: 0111
A的編碼為: 10
E的編碼為: 11
原文鏈接:https://blog.csdn.net/lzq20115395/article/details/78906863
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/520654.html
標籤:其他
上一篇:用昇騰AI護航“井下安全”