宣告
本文參考【中文】【吳恩達課后編程作業】Course 2 - 改善深層神經網路 - 第一周作業(1&2&3)_何寬的博客-CSDN博客,加上自己的理解,方便自己以后的學習,我覺得這次理解起來還是蠻簡單的,就是知識點比較多
讓我們跟著這篇博客對比著來學習吧!
資料下載
本文所使用的資料已上傳到百度網盤【點擊下載】,提取碼:imgq ,請在開始之前下載好所需資料,或者在本文底部copy資料代碼,
開始之前
我們在開始之前說一下我們要干什么,在這篇文章中,我們要干三件事:
1. 初始化引數: 1.1:使用0來初始化引數, 1.2:使用亂數來初始化引數, 1.3:使用抑梯度例外初始化引數(參見視頻中的梯度消失和梯度爆炸), 2. 正則化模型: 2.1:使用二范數對二分類模型正則化,嘗試避免過擬合, 2.2:使用隨機洗掉節點的方法精簡模型,同樣是為了嘗試避免過擬合, 3. 梯度校驗 :對模型使用梯度校驗,檢測它是否在梯度下降的程序中出現誤差過大的情況,
我們就開始匯入相關的庫:
import numpy as np import matplotlib.pyplot as plt import sklearn import sklearn.datasets import init_utils #第一部分,初始化 import reg_utils #第二部分,正則化 import gc_utils #第三部分,梯度校驗 import testCase #第四部分,梯度檢查 plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots plt.rcParams['image.interpolation'] = 'nearest' plt.rcParams['image.cmap'] = 'gray'
初始化引數
我們在初始化之前,我們來看看我們的資料集是怎樣的:
讀取并繪制資料
train_X, train_Y, test_X, test_Y = init_utils.load_dataset(is_plot=True)
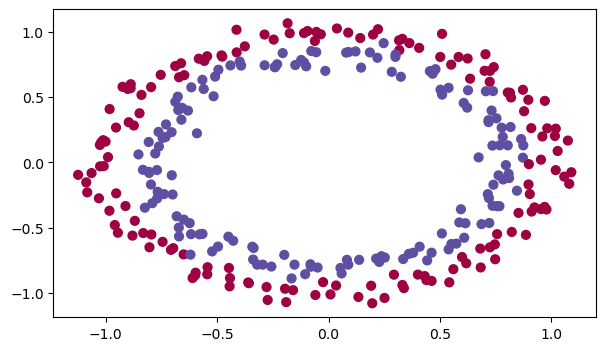
我們將要建立一個分類器把藍點和紅點分開,在之前我們已經實作過一個3層的神經網路,我們將對它進行初始化:
我們將會嘗試下面三種初始化方法:
- 初始化為0:在輸入引數中全部初始化為0,引數名為initialization = “zeros”,核心代碼:
parameters['W' + str(l)] = np.zeros((layers_dims[l], layers_dims[l - 1]))
- 初始化為亂數:把輸入引數設定為隨機值,權重初始化為大的隨機值,引數名為initialization = “random”,核心代碼:
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * 10
- 抑梯度例外初始化:參見梯度消失和梯度爆炸的那一個視頻,引數名為initialization = “he”,核心代碼:
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * np.sqrt(2 / layers_dims[l - 1])
首先我們來看看我們的模型是怎樣的:
def model(X,Y,learning_rate=0.01,num_iterations=15000,print_cost=True,initialization="he",is_polt=True): """ 實作一個三層的神經網路:LINEAR ->RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID 引數: X - 輸入的資料,維度為(2, 要訓練/測驗的數量) Y - 標簽,【0 | 1】,維度為(1,對應的是輸入的資料的標簽) learning_rate - 學習速率 num_iterations - 迭代的次數 print_cost - 是否列印成本值,每迭代1000次列印一次 initialization - 字串型別,初始化的型別【"zeros" | "random" | "he"】 is_polt - 是否繪制梯度下降的曲線圖 回傳 parameters - 學習后的引數 """ grads = {} costs = [] m = X.shape[1] layers_dims = [X.shape[0],10,5,1] #選擇初始化引數的型別 if initialization == "zeros": parameters = initialize_parameters_zeros(layers_dims) elif initialization == "random": parameters = initialize_parameters_random(layers_dims) elif initialization == "he": parameters = initialize_parameters_he(layers_dims) else : print("錯誤的初始化引數!程式退出") #開始學習 for i in range(0,num_iterations): #前向傳播 a3 , cache = init_utils.forward_propagation(X,parameters) #計算成本 cost = init_utils.compute_loss(a3,Y) #反向傳播 grads = init_utils.backward_propagation(X,Y,cache) #更新引數 parameters = init_utils.update_parameters(parameters,grads,learning_rate) #記錄成本 if i % 1000 == 0: costs.append(cost) #列印成本 if print_cost: print("第" + str(i) + "次迭代,成本值為:" + str(cost)) #學習完畢,繪制成本曲線 if is_polt: plt.plot(costs) plt.ylabel('cost') plt.xlabel('iterations (per hundreds)') plt.title("Learning rate =" + str(learning_rate)) plt.show() #回傳學習完畢后的引數 return parameters
模型我們可以簡單地看一下,我們這就開始嘗試一下這三種初始化,
初始化為零
def initialize_parameters_zeros(layers_dims): """ 將模型的引數全部設定為0 引數: layers_dims - 串列,模型的層數和對應每一層的節點的數量 回傳 parameters - 包含了所有W和b的字典 W1 - 權重矩陣,維度為(layers_dims[1], layers_dims[0]) b1 - 偏置向量,維度為(layers_dims[1],1) ··· WL - 權重矩陣,維度為(layers_dims[L], layers_dims[L -1]) bL - 偏置向量,維度為(layers_dims[L],1) """ parameters = {} L = len(layers_dims) #網路層數 for l in range(1,L): parameters["W" + str(l)] = np.zeros((layers_dims[l],layers_dims[l-1])) parameters["b" + str(l)] = np.zeros((layers_dims[l],1)) #使用斷言確保我的資料格式是正確的 assert(parameters["W" + str(l)].shape == (layers_dims[l],layers_dims[l-1])) assert(parameters["b" + str(l)].shape == (layers_dims[l],1)) return parameters
我們這就來測驗一下:
parameters = initialize_parameters_zeros([3,2,1]) print("W1 = " + str(parameters["W1"])) print("b1 = " + str(parameters["b1"])) print("W2 = " + str(parameters["W2"])) print("b2 = " + str(parameters["b2"]))
W1 = [[0. 0. 0.] [0. 0. 0.]] b1 = [[0.] [0.]] W2 = [[0. 0.]] b2 = [[0.]]
我們可以看到W和b全部被初始化為0了,那么我們使用這些引數來訓練模型,結果會怎樣呢?
parameters = model(train_X, train_Y, initialization = "zeros",is_polt=True)
第0次迭代,成本值為:0.6931471805599453 第1000次迭代,成本值為:0.6931471805599453 第2000次迭代,成本值為:0.6931471805599453 第3000次迭代,成本值為:0.6931471805599453 第4000次迭代,成本值為:0.6931471805599453 第5000次迭代,成本值為:0.6931471805599453 第6000次迭代,成本值為:0.6931471805599453 第7000次迭代,成本值為:0.6931471805599453 第8000次迭代,成本值為:0.6931471805599453 第9000次迭代,成本值為:0.6931471805599453 第10000次迭代,成本值為:0.6931471805599455 第11000次迭代,成本值為:0.6931471805599453 第12000次迭代,成本值為:0.6931471805599453 第13000次迭代,成本值為:0.6931471805599453 第14000次迭代,成本值為:0.6931471805599453
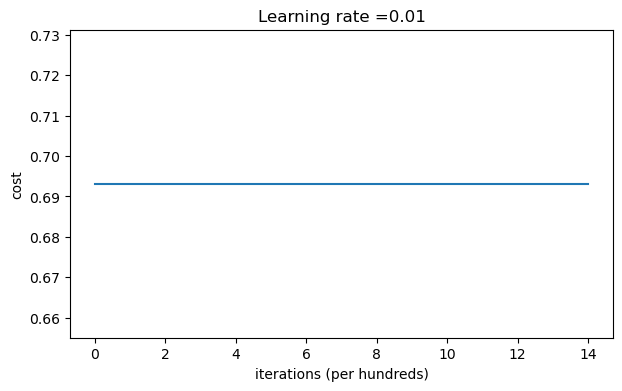
從上圖中我們可以看到學習率一直沒有變化,也就是說這個模型根本沒有學習,我們來看看預測的結果怎么樣:
print ("訓練集:") predictions_train = init_utils.predict(train_X, train_Y, parameters) print ("測驗集:") predictions_test = init_utils.predict(test_X, test_Y, parameters)
訓練集: Accuracy: 0.5 測驗集: Accuracy: 0.5
性能確實很差,而且成本并沒有真正降低,演算法的性能也比隨機猜測要好,為什么?讓我們看看預測和決策邊界的細節:
print("predictions_train = " + str(predictions_train)) print("predictions_test = " + str(predictions_test)) plt.title("Model with Zeros initialization") axes = plt.gca() axes.set_xlim([-1.5, 1.5]) axes.set_ylim([-1.5, 1.5]) init_utils.plot_decision_boundary(lambda x: init_utils.predict_dec(parameters, x.T), train_X, train_Y)
predictions_train = [[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]] predictions_test = [[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
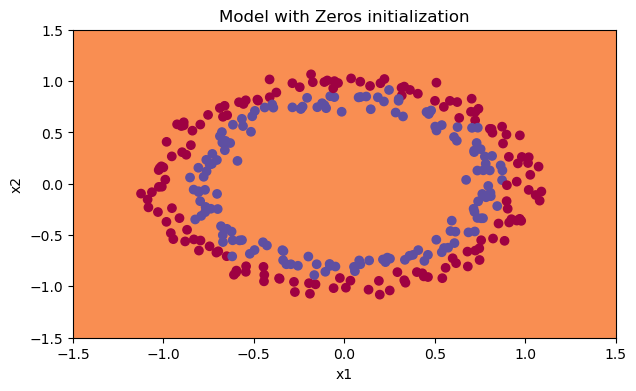
分類失敗,
隨機初始化
為了打破對稱性,我們可以隨機地把引數賦值,在隨機初始化之后,每個神經元可以開始學習其輸入的不同功能,我們還會設定比較大的引數值,看看會發生什么,
def initialize_parameters_random(layers_dims): """ 引數: layers_dims - 串列,模型的層數和對應每一層的節點的數量 回傳 parameters - 包含了所有W和b的字典 W1 - 權重矩陣,維度為(layers_dims[1], layers_dims[0]) b1 - 偏置向量,維度為(layers_dims[1],1) ··· WL - 權重矩陣,維度為(layers_dims[L], layers_dims[L -1]) b1 - 偏置向量,維度為(layers_dims[L],1) """ np.random.seed(3) # 指定隨機種子 parameters = {} L = len(layers_dims) # 層數 for l in range(1, L): parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1])*10 #使用10倍縮放 parameters['b' + str(l)] = np.zeros((layers_dims[l], 1)) #使用斷言確保我的資料格式是正確的 assert(parameters["W" + str(l)].shape == (layers_dims[l],layers_dims[l-1])) assert(parameters["b" + str(l)].shape == (layers_dims[l],1)) return parameters
我們可以來測驗一下:
parameters = initialize_parameters_random([3, 2, 1]) print("W1 = " + str(parameters["W1"])) print("b1 = " + str(parameters["b1"])) print("W2 = " + str(parameters["W2"])) print("b2 = " + str(parameters["b2"]))
W1 = [[ 17.88628473 4.36509851 0.96497468] [-18.63492703 -2.77388203 -3.54758979]] b1 = [[0.] [0.]] W2 = [[-0.82741481 -6.27000677]] b2 = [[0.]]
看起來這些引數都是比較大的,我們來看看實際運行會怎么樣:
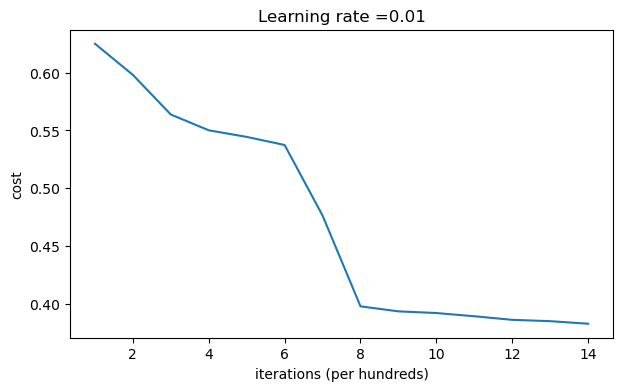
parameters = model(train_X, train_Y, initialization = "random",is_polt=True) print("訓練集:") predictions_train = init_utils.predict(train_X, train_Y, parameters) print("測驗集:") predictions_test = init_utils.predict(test_X, test_Y, parameters) print(predictions_train) print(predictions_test)
第0次迭代,成本值為:inf 第1000次迭代,成本值為:0.6250982793959966 第2000次迭代,成本值為:0.5981216596703697 第3000次迭代,成本值為:0.5638417572298645 第4000次迭代,成本值為:0.5501703049199763 第5000次迭代,成本值為:0.5444632909664456 第6000次迭代,成本值為:0.5374513807000807 第7000次迭代,成本值為:0.4764042074074983 第8000次迭代,成本值為:0.39781492295092263 第9000次迭代,成本值為:0.3934764028765484 第10000次迭代,成本值為:0.3920295461882659 第11000次迭代,成本值為:0.38924598135108 第12000次迭代,成本值為:0.3861547485712325 第13000次迭代,成本值為:0.384984728909703 第14000次迭代,成本值為:0.3827828308349524
訓練集: Accuracy: 0.83 測驗集: Accuracy: 0.86 [[1 0 1 1 0 0 1 1 1 1 1 0 1 0 0 1 0 1 1 0 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 0 1 0 1 1 1 1 0 0 1 1 1 1 0 1 1 0 1 0 1 1 1 1 0 0 0 0 0 1 0 1 0 1 1 1 0 0 1 1 1 1 1 1 0 0 1 1 1 0 1 1 0 1 0 1 1 0 1 1 0 1 0 1 1 0 0 1 0 0 1 1 0 1 1 1 0 1 0 0 1 0 1 1 1 1 1 1 1 0 1 1 0 0 1 1 0 0 0 1 0 1 0 1 0 1 1 1 0 0 1 1 1 1 0 1 1 0 1 0 1 1 0 1 0 1 1 1 1 0 1 1 1 1 0 1 0 1 0 1 1 1 1 0 1 1 0 1 1 0 1 1 0 1 0 1 1 1 0 1 1 1 0 1 0 1 0 0 1 0 1 1 0 1 1 0 1 1 0 1 1 1 0 1 1 1 1 0 1 0 0 1 1 0 1 1 1 0 0 0 1 1 0 1 1 1 1 0 1 1 0 1 1 1 0 0 1 0 0 0 1 0 0 0 1 1 1 1 0 0 0 0 1 1 1 1 0 0 1 1 1 1 1 1 1 0 0 0 1 1 1 1 0]] [[1 1 1 1 0 1 0 1 1 0 1 1 1 0 0 0 0 1 0 1 0 0 1 0 1 0 1 1 1 1 1 0 0 0 0 1 0 1 1 0 0 1 1 1 1 1 0 1 1 1 0 1 0 1 1 0 1 0 1 0 1 1 1 1 1 1 1 1 1 0 1 0 1 1 1 1 1 0 1 0 0 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 0]]
我們來把圖繪制出來,看看分類的結果是怎樣的,
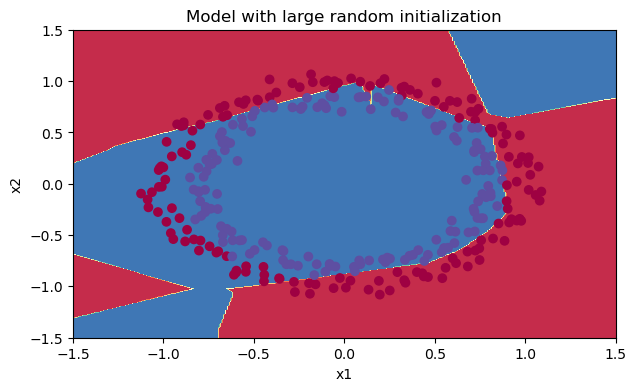
?我們可以看到誤差開始很高,這是因為由于具有較大的隨機權重,最后一個激活(sigmoid)輸出的結果非常接近于0或1,而當它出現錯誤時,它會導致非常高的損失,初始化引數如果沒有很好地話會導致梯度消失、爆炸,這也會減慢優化演算法,如果我們對這個網路進行更長時間的訓練,我們將看到更好的結果,但是使用過大的亂數初始化會減慢優化的速度,
當然也可以試一試不?10那樣得到的分類情況也還不錯,
抑梯度例外初始化
我們會使用到sqrt(2/上一層的維度)這個公式來初始化引數,
def initialize_parameters_he(layers_dims): """ 引數: layers_dims - 串列,模型的層數和對應每一層的節點的數量 回傳 parameters - 包含了所有W和b的字典 W1 - 權重矩陣,維度為(layers_dims[1], layers_dims[0]) b1 - 偏置向量,維度為(layers_dims[1],1) ··· WL - 權重矩陣,維度為(layers_dims[L], layers_dims[L -1]) b1 - 偏置向量,維度為(layers_dims[L],1) """ np.random.seed(3) # 指定隨機種子 parameters = {} L = len(layers_dims) # 層數 for l in range(1, L): parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * np.sqrt(2 / layers_dims[l - 1]) parameters['b' + str(l)] = np.zeros((layers_dims[l], 1)) #使用斷言確保我的資料格式是正確的 assert(parameters["W" + str(l)].shape == (layers_dims[l],layers_dims[l-1])) assert(parameters["b" + str(l)].shape == (layers_dims[l],1)) return parameters
我們來測驗一下這個函式:
parameters = initialize_parameters_he([2, 4, 1]) print("W1 = " + str(parameters["W1"])) print("b1 = " + str(parameters["b1"])) print("W2 = " + str(parameters["W2"])) print("b2 = " + str(parameters["b2"]))
W1 = [[ 1.78862847 0.43650985] [ 0.09649747 -1.8634927 ] [-0.2773882 -0.35475898] [-0.08274148 -0.62700068]] b1 = [[0.] [0.] [0.] [0.]] W2 = [[-0.03098412 -0.33744411 -0.92904268 0.62552248]] b2 = [[0.]]
這樣我們就基本把引數W初始化到了1附近,我們來實際運行一下看看:
parameters = model(train_X, train_Y, initialization = "he",is_polt=True) print("訓練集:") predictions_train = init_utils.predict(train_X, train_Y, parameters) print("測驗集:") init_utils.predictions_test = init_utils.predict(test_X, test_Y, parameters)
第0次迭代,成本值為:0.8830537463419761 第1000次迭代,成本值為:0.6879825919728063 第2000次迭代,成本值為:0.6751286264523371 第3000次迭代,成本值為:0.6526117768893807 第4000次迭代,成本值為:0.6082958970572937 第5000次迭代,成本值為:0.5304944491717495 第6000次迭代,成本值為:0.4138645817071793 第7000次迭代,成本值為:0.3117803464844441 第8000次迭代,成本值為:0.23696215330322556 第9000次迭代,成本值為:0.18597287209206828 第10000次迭代,成本值為:0.15015556280371808 第11000次迭代,成本值為:0.12325079292273548 第12000次迭代,成本值為:0.09917746546525937 第13000次迭代,成本值為:0.08457055954024274 第14000次迭代,成本值為:0.07357895962677366
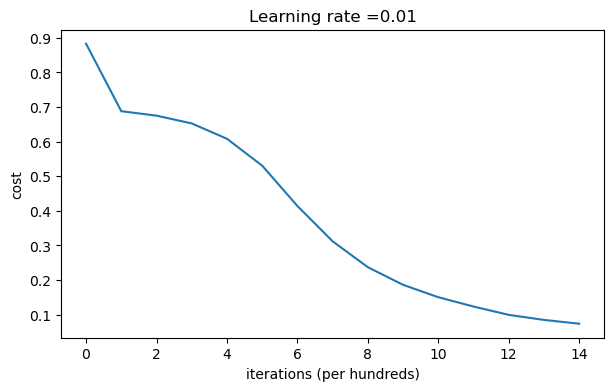
訓練集: Accuracy: 0.9933333333333333 測驗集: Accuracy: 0.96
我們可以看到誤差越來越小,我們來繪制一下預測的情況:
plt.title("Model with He initialization") axes = plt.gca() axes.set_xlim([-1.5, 1.5]) axes.set_ylim([-1.5, 1.5]) init_utils.plot_decision_boundary(lambda x: init_utils.predict_dec(parameters, x.T), train_X, train_Y)
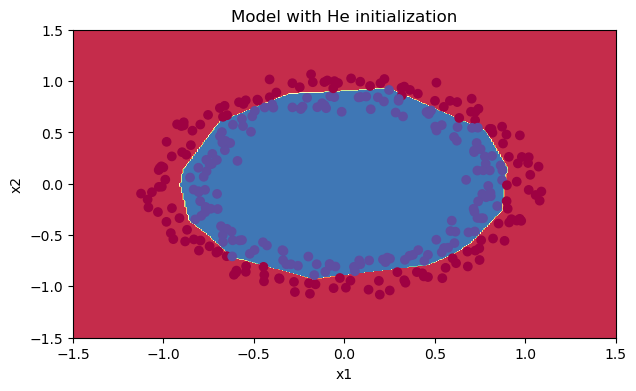
初始化的模型將藍色和紅色的點在少量的迭代中很好地分離出來
總結一下:
-
不同的初始化方法可能導致性能最終不同
-
隨機初始化有助于打破對稱,使得不同隱藏層的單元可以學習到不同的引數,
-
初始化時,初始值不宜過大,
-
He初始化搭配ReLU激活函式常常可以得到不錯的效果,
接下來,我們介紹減少過擬合的方法:正則化
正則化模型
問題描述:假設你現在是一個AI專家,你需要設計一個模型,可以用于推薦在足球場中守門員將球發至哪個位置可以讓本隊的球員搶到球的可能性更大,
說白了,實際上就是一個二分類,一半是己方搶到球,一半就是對方搶到球,我們來看一下這個圖:
讀取并繪制資料集
train_X, train_Y, test_X, test_Y = reg_utils.load_2D_dataset(is_plot=True)
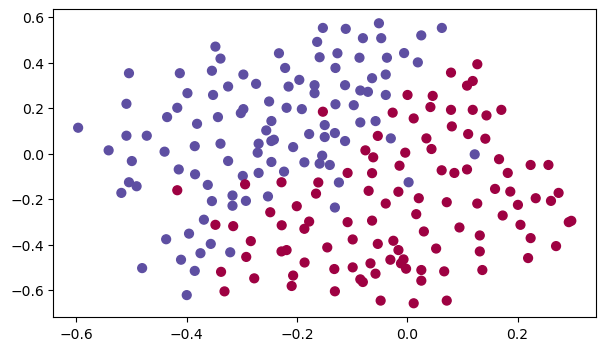
每一個點代表球落下的可能的位置,藍色代表己方的球員會搶到球,紅色代表對手的球員會搶到球,我們要做的就是使用模型來畫出一條線,來找到適合我方球員能搶到球的位置,
我們要做以下三件事,來對比出不同的模型的優劣:
- 不使用正則化
- 使用正則化
2.1 使用L2正則化
2.2 使用隨機節點洗掉
我們來看一下我們的模型:
- 正則化模式 - 將lambd輸入設定為非零值, 我們使用“lambd”而不是“lambda”,因為“lambda”是Python中的保留關鍵字,
- 隨機洗掉節點 - 將keep_prob設定為小于1的值
def model(X,Y,learning_rate=0.3,num_iterations=30000,print_cost=True,is_plot=True,lambd=0,keep_prob=1): """ 實作一個三層的神經網路:LINEAR ->RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID 引數: X - 輸入的資料,維度為(2, 要訓練/測驗的數量) Y - 標簽,【0(藍色) | 1(紅色)】,維度為(1,對應的是輸入的資料的標簽) learning_rate - 學習速率 num_iterations - 迭代的次數 print_cost - 是否列印成本值,每迭代10000次列印一次,但是每1000次記錄一個成本值 is_polt - 是否繪制梯度下降的曲線圖 lambd - 正則化的超引數,實數 keep_prob - 隨機洗掉節點的概率 回傳 parameters - 學習后的引數 """ grads = {} costs = [] m = X.shape[1] layers_dims = [X.shape[0],20,3,1] #初始化引數 parameters = reg_utils.initialize_parameters(layers_dims) #開始學習 for i in range(0,num_iterations): #前向傳播 ##是否隨機洗掉節點 if keep_prob == 1: ###不隨機洗掉節點 a3 , cache = reg_utils.forward_propagation(X,parameters) elif keep_prob < 1: ###隨機洗掉節點 a3 , cache = forward_propagation_with_dropout(X,parameters,keep_prob) else: print("keep_prob引數錯誤!程式退出,") #計算成本 ## 是否使用二范數 if lambd == 0: ###不使用L2正則化 cost = reg_utils.compute_cost(a3,Y) else: ###使用L2正則化 cost = compute_cost_with_regularization(a3,Y,parameters,lambd) #反向傳播 ##可以同時使用L2正則化和隨機洗掉節點,但是本次實驗不同時使用, assert(lambd == 0 or keep_prob ==1) ##兩個引數的使用情況 if (lambd == 0 and keep_prob == 1): ### 不使用L2正則化和不使用隨機洗掉節點 grads = reg_utils.backward_propagation(X,Y,cache) elif (lambd != 0 and keep_prob ==1): ### 使用L2正則化,不使用隨機洗掉節點 grads = backward_propagation_with_regularization(X, Y, cache, lambd) elif (keep_prob < 1 and lambd ==0): ### 使用隨機洗掉節點,不使用L2正則化 grads = backward_propagation_with_dropout(X, Y, cache, keep_prob) #更新引數 parameters = reg_utils.update_parameters(parameters, grads, learning_rate) #記錄并列印成本 if i % 1000 == 0: ## 記錄成本 costs.append(cost) if (print_cost and i % 10000 == 0): #列印成本 print("第" + str(i) + "次迭代,成本值為:" + str(cost)) #是否繪制成本曲線圖 if is_plot: plt.plot(costs) plt.ylabel('cost') plt.xlabel('iterations (x1,000)') plt.title("Learning rate =" + str(learning_rate)) plt.show() #回傳學習后的引數 return parameters
我們來先看一下不使用正則化下模型的效果:
不使用正則化
parameters = model(train_X, train_Y,is_plot=True) print("訓練集:") predictions_train = reg_utils.predict(train_X, train_Y, parameters) print("測驗集:") predictions_test = reg_utils.predict(test_X, test_Y, parameters)
第0次迭代,成本值為:0.6557412523481002 第10000次迭代,成本值為:0.16329987525724196 第20000次迭代,成本值為:0.13851642423253843
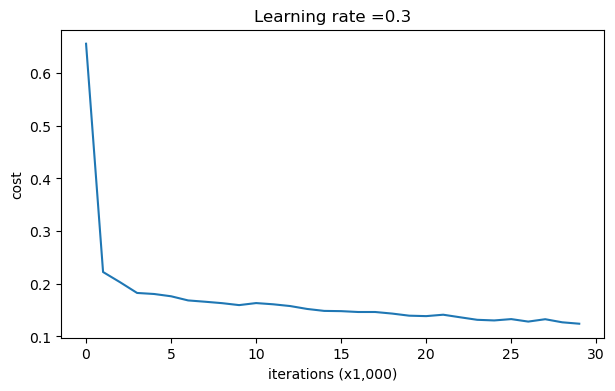
訓練集: Accuracy: 0.9478672985781991 測驗集: Accuracy: 0.915
我們可以看到,對于訓練集,精確度為94%;而對于測驗集,精確度為91.5%,接下來,我們將分割曲線畫出來:
plt.title("Model without regularization") axes = plt.gca() axes.set_xlim([-0.75,0.40]) axes.set_ylim([-0.75,0.65]) reg_utils.plot_decision_boundary(lambda x: reg_utils.predict_dec(parameters, x.T), train_X, train_Y)
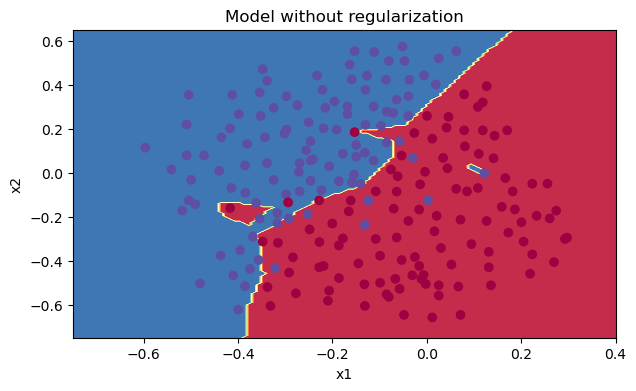
從圖中可以看出,在無正則化時,分割曲線有了明顯的過擬合特性,接下來,我們使用L2正則化:
使用正則化
L2正則化
避免過度擬合的標準方法稱為L2正則化,它包括適當修改你的成本函式,我們從原來的成本函式(1)到現在的函式(2):
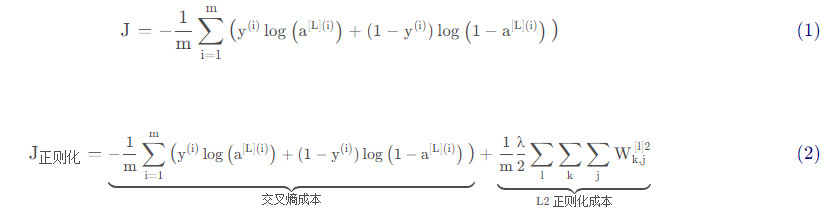
我們下面就開始寫相關的函式:
def compute_cost_with_regularization(A3,Y,parameters,lambd): """ 實作公式2的L2正則化計算成本 引數: A3 - 正向傳播的輸出結果,維度為(輸出節點數量,訓練/測驗的數量) Y - 標簽向量,與資料一一對應,維度為(輸出節點數量,訓練/測驗的數量) parameters - 包含模型學習后的引數的字典 回傳: cost - 使用公式2計算出來的正則化損失的值 """ m = Y.shape[1] W1 = parameters["W1"] W2 = parameters["W2"] W3 = parameters["W3"] cross_entropy_cost = reg_utils.compute_cost(A3,Y) L2_regularization_cost = lambd * (np.sum(np.square(W1)) + np.sum(np.square(W2)) + np.sum(np.square(W3))) / (2 * m) cost = cross_entropy_cost + L2_regularization_cost return cost #當然,因為改變了成本函式,我們也必須改變向后傳播的函式, 所有的梯度都必須根據這個新的成本值來計算, def backward_propagation_with_regularization(X, Y, cache, lambd): """ 實作我們添加了L2正則化的模型的后向傳播, 引數: X - 輸入資料集,維度為(輸入節點數量,資料集里面的數量) Y - 標簽,維度為(輸出節點數量,資料集里面的數量) cache - 來自forward_propagation()的cache輸出 lambda - regularization超引數,實數 回傳: gradients - 一個包含了每個引數、激活值和預激活值變數的梯度的字典 """ m = X.shape[1] (Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache dZ3 = A3 - Y dW3 = (1 / m) * np.dot(dZ3,A2.T) + ((lambd * W3) / m ) db3 = (1 / m) * np.sum(dZ3,axis=1,keepdims=True) dA2 = np.dot(W3.T,dZ3) dZ2 = np.multiply(dA2,np.int64(A2 > 0)) # 應該是生成一個A2同緯度的矩陣,但是這個矩陣是A2中大于 0 的數保持不變,其余的數為 0 dW2 = (1 / m) * np.dot(dZ2,A1.T) + ((lambd * W2) / m) db2 = (1 / m) * np.sum(dZ2,axis=1,keepdims=True) dA1 = np.dot(W2.T,dZ2) dZ1 = np.multiply(dA1,np.int64(A1 > 0)) dW1 = (1 / m) * np.dot(dZ1,X.T) + ((lambd * W1) / m) db1 = (1 / m) * np.sum(dZ1,axis=1,keepdims=True) gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3, "dA2": dA2, "dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1, "dZ1": dZ1, "dW1": dW1, "db1": db1} return gradients
我們來直接放到模型中跑一下:
parameters = model(train_X, train_Y, lambd=0.7,is_plot=True) print("使用正則化,訓練集:") predictions_train = reg_utils.predict(train_X, train_Y, parameters) print("使用正則化,測驗集:") predictions_test = reg_utils.predict(test_X, test_Y, parameters)
第0次迭代,成本值為:0.6974484493131264 第10000次迭代,成本值為:0.2684918873282239 第20000次迭代,成本值為:0.2680916337127301
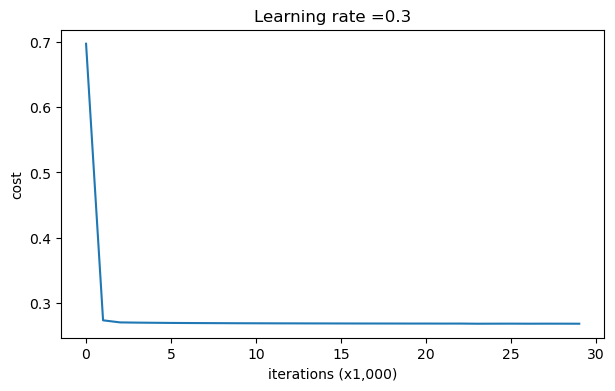
使用正則化,訓練集: Accuracy: 0.9383886255924171 使用正則化,測驗集: Accuracy: 0.93
我們來看一下分類的結果吧~
plt.title("Model with L2-regularization") axes = plt.gca() axes.set_xlim([-0.75,0.40]) axes.set_ylim([-0.75,0.65]) reg_utils.plot_decision_boundary(lambda x: reg_utils.predict_dec(parameters, x.T), train_X, train_Y)
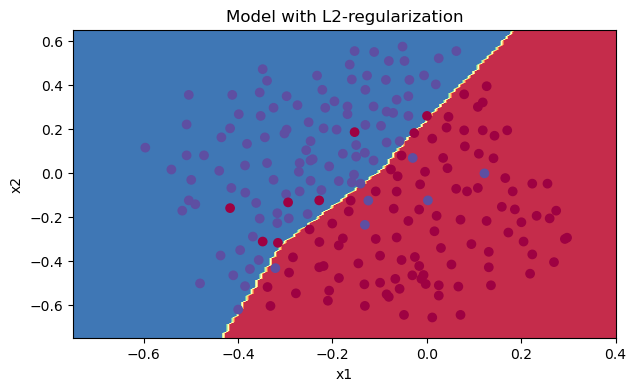
L2通過削減成本函式中權重的平方值,可以將所有權重值逐漸改變到到較小的值,權值數值高的話會有更平滑的模型,其中輸入變化時輸出變化更慢,但是你需要花費更多的時間,
盡管L2的速度會降低,但是它仍舊是我們減少過擬合的不二選則,
隨機洗掉節
- 最后,我們使用Dropout來進行正則化,就是我們隨機留下一部分的節點,在節點多的層,將keep_prob設定的小一點,在節點少的層,將keep_prob設定的大一點,甚至是1,
- 在視頻中,吳恩達老師講解了使用np.random.rand() 來初始化和a[1]具有相同維度的 d[1],
- 如果d[1]大于keep_prob就是true,小于就是false,將a[1] = a[1] * d[1],我們就相當于關閉了一些節點
- 最后用a[1]除以 keep_prob,這樣做的話我們通過縮放就在計算成本的時候仍然具有相同的期望值,這叫做反向dropout,
def forward_propagation_with_dropout(X,parameters,keep_prob=0.5): """ 實作具有隨機舍棄節點的前向傳播, LINEAR -> RELU + DROPOUT -> LINEAR -> RELU + DROPOUT -> LINEAR -> SIGMOID. 引數: X - 輸入資料集,維度為(2,示例數) parameters - 包含引數“W1”,“b1”,“W2”,“b2”,“W3”,“b3”的python字典: W1 - 權重矩陣,維度為(20,2) b1 - 偏向量,維度為(20,1) W2 - 權重矩陣,維度為(3,20) b2 - 偏向量,維度為(3,1) W3 - 權重矩陣,維度為(1,3) b3 - 偏向量,維度為(1,1) keep_prob - 隨機洗掉的概率,實數 回傳: A3 - 最后的激活值,維度為(1,1),正向傳播的輸出 cache - 存盤了一些用于計算反向傳播的數值的元組 """ np.random.seed(1) W1 = parameters["W1"] b1 = parameters["b1"] W2 = parameters["W2"] b2 = parameters["b2"] W3 = parameters["W3"] b3 = parameters["b3"] #LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID Z1 = np.dot(W1,X) + b1 A1 = reg_utils.relu(Z1) #下面的步驟1-4對應于上述的步驟1-4, D1 = np.random.rand(A1.shape[0],A1.shape[1]) #步驟1:初始化矩陣D1 = np.random.rand(..., ...) D1 = D1 < keep_prob #步驟2:將D1的值轉換為0或1(使??用keep_prob作為閾值) A1 = A1 * D1 #步驟3:舍棄A1的一些節點(將它的值變為0或False) A1 = A1 / keep_prob #步驟4:縮放未舍棄的節點(不為0)的值 Z2 = np.dot(W2,A1) + b2 A2 = reg_utils.relu(Z2) #下面的步驟1-4對應于上述的步驟1-4, D2 = np.random.rand(A2.shape[0],A2.shape[1]) #步驟1:初始化矩陣D2 = np.random.rand(..., ...) D2 = D2 < keep_prob #步驟2:將D2的值轉換為0或1(使??用keep_prob作為閾值) A2 = A2 * D2 #步驟3:舍棄A1的一些節點(將它的值變為0或False) A2 = A2 / keep_prob #步驟4:縮放未舍棄的節點(不為0)的值 Z3 = np.dot(W3, A2) + b3 A3 = reg_utils.sigmoid(Z3) cache = (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3) return A3, cache
改變了前向傳播的演算法,我們也需要改變后向傳播的演算法
def backward_propagation_with_dropout(X,Y,cache,keep_prob): """ 實作我們隨機洗掉的模型的后向傳播, 引數: X - 輸入資料集,維度為(2,示例數) Y - 標簽,維度為(輸出節點數量,示例數量) cache - 來自forward_propagation_with_dropout()的cache輸出 keep_prob - 隨機洗掉的概率,實數 回傳: gradients - 一個關于每個引數、激活值和預激活變數的梯度值的字典 """ m = X.shape[1] (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3) = cache dZ3 = A3 - Y dW3 = (1 / m) * np.dot(dZ3,A2.T) db3 = 1. / m * np.sum(dZ3, axis=1, keepdims=True) dA2 = np.dot(W3.T, dZ3) dA2 = dA2 * D2 # 步驟1:使用正向傳播期間相同的節點,舍棄那些關閉的節點(因為任何數乘以0或者False都為0或者False) dA2 = dA2 / keep_prob # 步驟2:縮放未舍棄的節點(不為0)的值 dZ2 = np.multiply(dA2, np.int64(A2 > 0)) dW2 = 1. / m * np.dot(dZ2, A1.T) db2 = 1. / m * np.sum(dZ2, axis=1, keepdims=True) dA1 = np.dot(W2.T, dZ2) dA1 = dA1 * D1 # 步驟1:使用正向傳播期間相同的節點,舍棄那些關閉的節點(因為任何數乘以0或者False都為0或者False) dA1 = dA1 / keep_prob # 步驟2:縮放未舍棄的節點(不為0)的值 dZ1 = np.multiply(dA1, np.int64(A1 > 0)) dW1 = 1. / m * np.dot(dZ1, X.T) db1 = 1. / m * np.sum(dZ1, axis=1, keepdims=True) gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,"dA2": dA2, "dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1, "dZ1": dZ1, "dW1": dW1, "db1": db1} return gradients
我們前向和后向傳播的函式都寫好了,現在用dropout運行模型(keep_prob = 0.86)跑一波,這意味著在每次迭代中,程式都可以24%的概率關閉第1層和第2層的每個神經元,呼叫的時候:
- 使用forward_propagation_with_dropout而不是forward_propagation,
- 使用backward_propagation_with_dropout而不是backward_propagation,
parameters = model(train_X, train_Y, keep_prob=0.86, learning_rate=0.3,is_plot=True) print("使用隨機洗掉節點,訓練集:") predictions_train = reg_utils.predict(train_X, train_Y, parameters) print("使用隨機洗掉節點,測驗集:") reg_utils.predictions_test = reg_utils.predict(test_X, test_Y, parameters)
第0次迭代,成本值為:0.6543912405149825
第10000次迭代,成本值為:0.061016986574905605 第20000次迭代,成本值為:0.060582435798513114
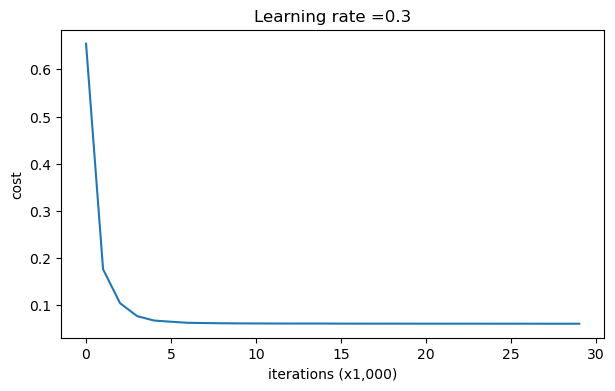
使用隨機洗掉節點,訓練集: Accuracy: 0.9289099526066351 使用隨機洗掉節點,測驗集: Accuracy: 0.95
我們來看看它的分類情況:
plt.title("Model with dropout") axes = plt.gca() axes.set_xlim([-0.75, 0.40]) axes.set_ylim([-0.75, 0.65]) reg_utils.plot_decision_boundary(lambda x: reg_utils.predict_dec(parameters, x.T), train_X, train_Y)
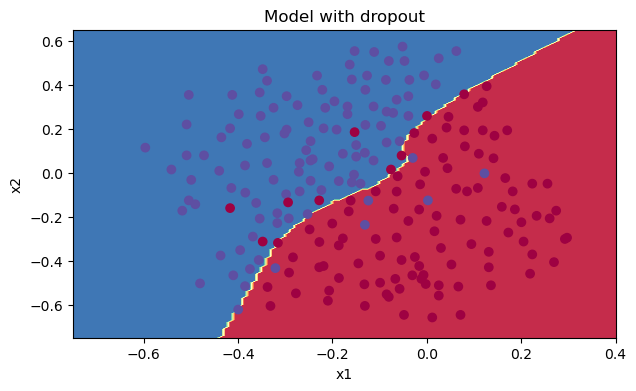
我們可以看到,正則化會把訓練集的準確度降低,但是測驗集的準確度提高了,所以,我們這個還是成功了,
梯度校驗
假設你現在是一個全球移動支付團隊中的一員,現在需要建立一個深度學習模型去判斷用戶賬戶在進行付款的時候是否是被黑客入侵的,
但是,在我們執行反向傳播的計算程序中,反向傳播函式的計算程序是比較復雜的,為了驗證我們得到的反向傳播函式是否正確,現在你需要撰寫一些代碼來驗證反向傳播函式的正確性,
讓我們回頭看一下導數(或梯度)的定義:

我們先來看一下一維線性模型的梯度檢查計算程序: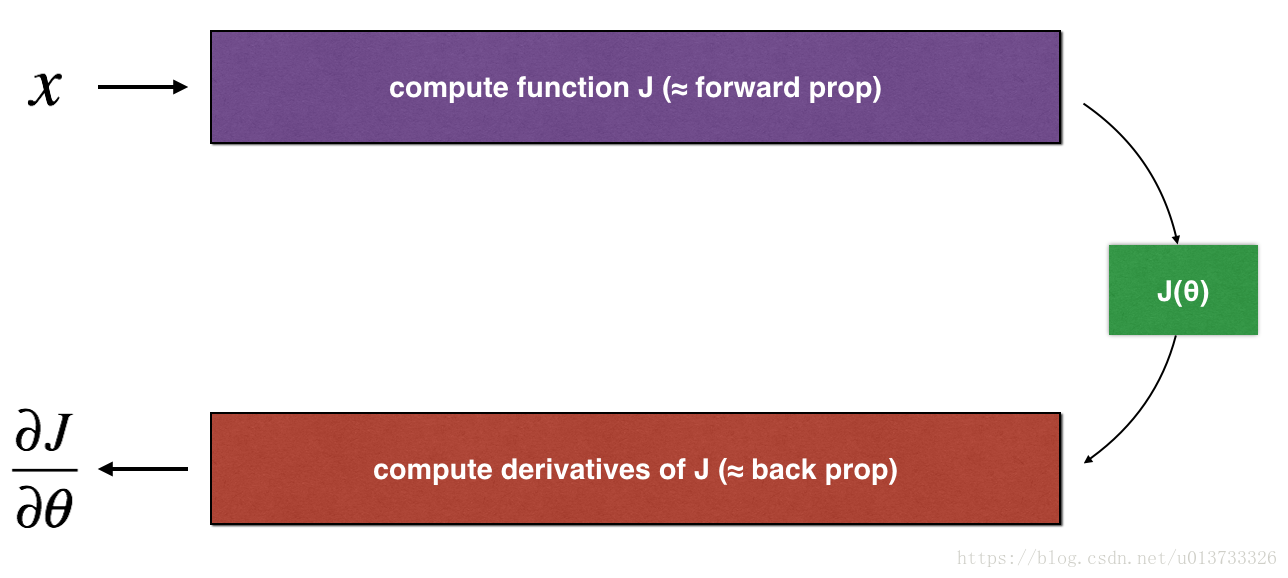
一維線性
def forward_propagation(x,theta): """ 實作圖中呈現的線性前向傳播(計算J)(J(theta)= theta * x) 引數: x - 一個實值輸入 theta - 引數,也是一個實數 回傳: J - 函式J的值,用公式J(theta)= theta * x計算 """ J = np.dot(theta,x) return J
測驗一下:
#測驗forward_propagation print("-----------------測驗forward_propagation-----------------") x, theta = 2, 4 J = forward_propagation(x, theta) print ("J = " + str(J))
-----------------測驗forward_propagation----------------- J = 8
前向傳播有了,我們來看一下反向傳播:
def backward_propagation(x,theta): """ 計算J相對于θ的導數, 引數: x - 一個實值輸入 theta - 引數,也是一個實數 回傳: dtheta - 相對于θ的成本梯度 """ dtheta = x return dtheta
測驗一下:
#測驗backward_propagation print("-----------------測驗backward_propagation-----------------") x, theta = 2, 4 dtheta = backward_propagation(x, theta) print ("dtheta = " + str(dtheta))
-----------------測驗backward_propagation----------------- dtheta = 2
梯度檢查的步驟如下:
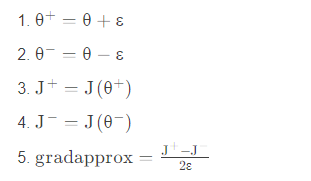
接下來,計算梯度的反向傳播值,最后計算誤差:
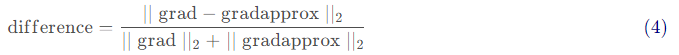
當difference小于10-7時,我們通常認為我們計算的結果是正確的,
def gradient_check(x,theta,epsilon=1e-7): """ 實作圖中的反向傳播, 引數: x - 一個實值輸入 theta - 引數,也是一個實數 epsilon - 使用公式(3)計算輸入的微小偏移以計算近似梯度 回傳: 近似梯度和后向傳播梯度之間的差異 """ #使用公式(3)的左側計算gradapprox, thetaplus = theta + epsilon # Step 1 thetaminus = theta - epsilon # Step 2 J_plus = forward_propagation(x, thetaplus) # Step 3 J_minus = forward_propagation(x, thetaminus) # Step 4 gradapprox = (J_plus - J_minus) / (2 * epsilon) # Step 5 #檢查gradapprox是否足夠接近backward_propagation()的輸出 grad = backward_propagation(x, theta) numerator = np.linalg.norm(grad - gradapprox) # Step 1' denominator = np.linalg.norm(grad) + np.linalg.norm(gradapprox) # Step 2' difference = numerator / denominator # Step 3' if difference < 1e-7: print("梯度檢查:梯度正常!") else: print("梯度檢查:梯度超出閾值!") return difference
測驗一下:
#測驗gradient_check print("-----------------測驗gradient_check-----------------") x, theta = 2, 4 difference = gradient_check(x, theta) print("difference = " + str(difference))
-----------------測驗gradient_check----------------- 梯度檢查:梯度正常! difference = 2.919335883291695e-10
高維引數是怎樣計算的呢?我們看一下下圖:

高維
def forward_propagation_n(X,Y,parameters): """ 實作圖中的前向傳播(并計算成本), 引數: X - 訓練集為m個例子 Y - m個示例的標簽 parameters - 包含引數“W1”,“b1”,“W2”,“b2”,“W3”,“b3”的python字典: W1 - 權重矩陣,維度為(5,4) b1 - 偏向量,維度為(5,1) W2 - 權重矩陣,維度為(3,5) b2 - 偏向量,維度為(3,1) W3 - 權重矩陣,維度為(1,3) b3 - 偏向量,維度為(1,1) 回傳: cost - 成本函式(logistic) """ m = X.shape[1] W1 = parameters["W1"] b1 = parameters["b1"] W2 = parameters["W2"] b2 = parameters["b2"] W3 = parameters["W3"] b3 = parameters["b3"] # LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID Z1 = np.dot(W1,X) + b1 A1 = gc_utils.relu(Z1) Z2 = np.dot(W2,A1) + b2 A2 = gc_utils.relu(Z2) Z3 = np.dot(W3,A2) + b3 A3 = gc_utils.sigmoid(Z3) #計算成本 logprobs = np.multiply(-np.log(A3), Y) + np.multiply(-np.log(1 - A3), 1 - Y) cost = (1 / m) * np.sum(logprobs) cache = (Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) return cost, cache def backward_propagation_n(X,Y,cache): """ 實作圖中所示的反向傳播, 引數: X - 輸入資料點(輸入節點數量,1) Y - 標簽 cache - 來自forward_propagation_n()的cache輸出 回傳: gradients - 一個字典,其中包含與每個引數、激活和激活前變數相關的成本梯度, """ m = X.shape[1] (Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache dZ3 = A3 - Y dW3 = (1. / m) * np.dot(dZ3,A2.T) dW3 = 1. / m * np.dot(dZ3, A2.T) db3 = 1. / m * np.sum(dZ3, axis=1, keepdims=True) dA2 = np.dot(W3.T, dZ3) dZ2 = np.multiply(dA2, np.int64(A2 > 0)) #dW2 = 1. / m * np.dot(dZ2, A1.T) * 2 # Should not multiply by 2 dW2 = 1. / m * np.dot(dZ2, A1.T) db2 = 1. / m * np.sum(dZ2, axis=1, keepdims=True) dA1 = np.dot(W2.T, dZ2) dZ1 = np.multiply(dA1, np.int64(A1 > 0)) dW1 = 1. / m * np.dot(dZ1, X.T) #db1 = 4. / m * np.sum(dZ1, axis=1, keepdims=True) # Should not multiply by 4 db1 = 1. / m * np.sum(dZ1, axis=1, keepdims=True) gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3, "dA2": dA2, "dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1, "dZ1": dZ1, "dW1": dW1, "db1": db1} return gradients
然而,θ 不再是標量, 這是一個名為“parameters”的字典, 我們為你實作了一個函式“dictionary_to_vector()”, 它將“parameters”字典轉換為一個稱為“values”的向量,通過將所有引數(W1,b1,W2,b2,W3,b3)整形為向量并將它們連接起來而獲得,
反函式是“vector_to_dictionary”,它回傳“parameters”字典,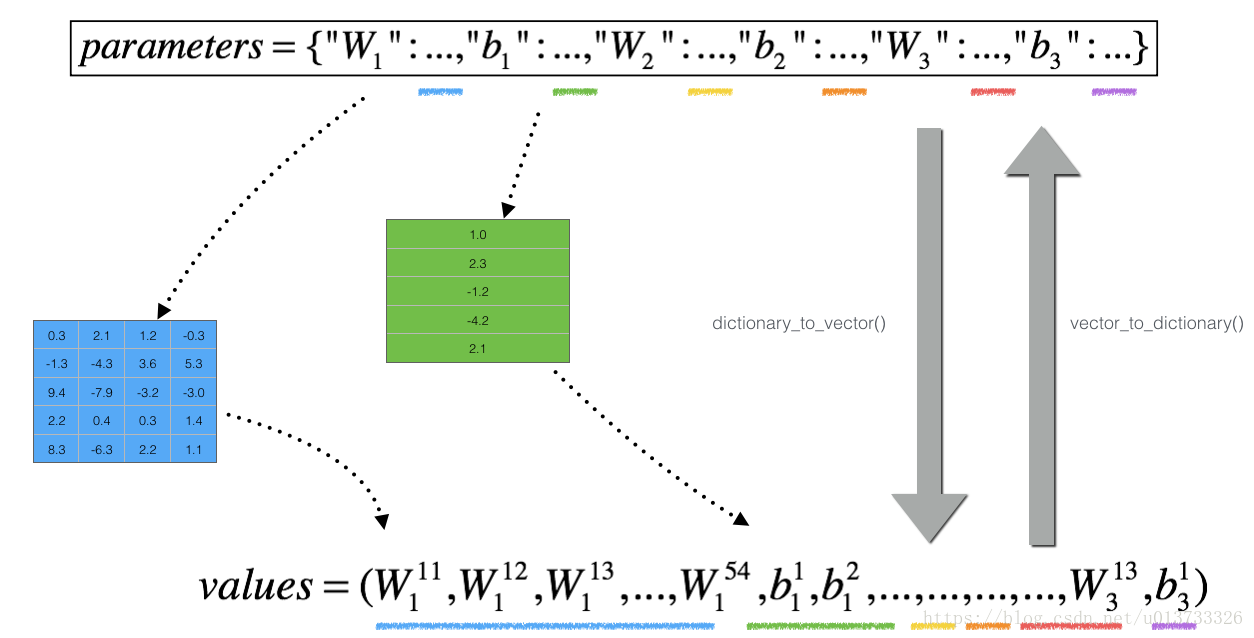
這里是偽代碼,可以幫助你實作梯度檢查:

def gradient_check_n(parameters,gradients,X,Y,epsilon=1e-7): """ 檢查backward_propagation_n是否正確計算forward_propagation_n輸出的成本梯度 引數: parameters - 包含引數“W1”,“b1”,“W2”,“b2”,“W3”,“b3”的python字典: grad_output_propagation_n的輸出包含與引數相關的成本梯度, x - 輸入資料點,維度為(輸入節點數量,1) y - 標簽 epsilon - 計算輸入的微小偏移以計算近似梯度 回傳: difference - 近似梯度和后向傳播梯度之間的差異 """ #初始化引數 parameters_values , keys = gc_utils.dictionary_to_vector(parameters) #keys用不到 grad = gc_utils.gradients_to_vector(gradients) num_parameters = parameters_values.shape[0] J_plus = np.zeros((num_parameters,1)) J_minus = np.zeros((num_parameters,1)) gradapprox = np.zeros((num_parameters,1)) #計算gradapprox for i in range(num_parameters): #計算J_plus [i],輸入:“parameters_values,epsilon”,輸出=“J_plus [i]” thetaplus = np.copy(parameters_values) # Step 1 thetaplus[i][0] = thetaplus[i][0] + epsilon # Step 2 J_plus[i], cache = forward_propagation_n(X,Y,gc_utils.vector_to_dictionary(thetaplus)) # Step 3 ,cache用不到 #計算J_minus [i],輸入:“parameters_values,epsilon”,輸出=“J_minus [i]”, thetaminus = np.copy(parameters_values) # Step 1 thetaminus[i][0] = thetaminus[i][0] - epsilon # Step 2 J_minus[i], cache = forward_propagation_n(X,Y,gc_utils.vector_to_dictionary(thetaminus))# Step 3 ,cache用不到 #計算gradapprox[i] gradapprox[i] = (J_plus[i] - J_minus[i]) / (2 * epsilon) #通過計算差異比較gradapprox和后向傳播梯度, numerator = np.linalg.norm(grad - gradapprox) # Step 1' denominator = np.linalg.norm(grad) + np.linalg.norm(gradapprox) # Step 2' difference = numerator / denominator # Step 3' if difference < 1e-7: print("梯度檢查:梯度正常!") else: print("梯度檢查:梯度超出閾值!") return difference
檢測一下:
print('=============測驗梯度===============') x,y,parameters = testCase.gradient_check_n_test_case() cost, cache = forward_propagation_n(x,y,parameters) gradients = backward_propagation_n(x,y,cache) difference = gradient_check_n(parameters,gradients,x,y) print("difference = " + str(difference))
=============測驗梯度=============== 梯度檢查:梯度超出閾值! difference = 1.1885552035482147e-07
到此本次課就結束了,下面是所需庫的代碼
init_utils.py
# -*- coding: utf-8 -*- #init_utils.py import numpy as np import matplotlib.pyplot as plt import sklearn import sklearn.datasets def sigmoid(x): """ Compute the sigmoid of x Arguments: x -- A scalar or numpy array of any size. Return: s -- sigmoid(x) """ s = 1/(1+np.exp(-x)) return s def relu(x): """ Compute the relu of x Arguments: x -- A scalar or numpy array of any size. Return: s -- relu(x) """ s = np.maximum(0,x) return s def compute_loss(a3, Y): """ Implement the loss function Arguments: a3 -- post-activation, output of forward propagation Y -- "true" labels vector, same shape as a3 Returns: loss - value of the loss function """ m = Y.shape[1] logprobs = np.multiply(-np.log(a3),Y) + np.multiply(-np.log(1 - a3), 1 - Y) loss = 1./m * np.nansum(logprobs) return loss def forward_propagation(X, parameters): """ Implements the forward propagation (and computes the loss) presented in Figure 2. Arguments: X -- input dataset, of shape (input size, number of examples) Y -- true "label" vector (containing 0 if cat, 1 if non-cat) parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3": W1 -- weight matrix of shape () b1 -- bias vector of shape () W2 -- weight matrix of shape () b2 -- bias vector of shape () W3 -- weight matrix of shape () b3 -- bias vector of shape () Returns: loss -- the loss function (vanilla logistic loss) """ # retrieve parameters W1 = parameters["W1"] b1 = parameters["b1"] W2 = parameters["W2"] b2 = parameters["b2"] W3 = parameters["W3"] b3 = parameters["b3"] # LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID z1 = np.dot(W1, X) + b1 a1 = relu(z1) z2 = np.dot(W2, a1) + b2 a2 = relu(z2) z3 = np.dot(W3, a2) + b3 a3 = sigmoid(z3) cache = (z1, a1, W1, b1, z2, a2, W2, b2, z3, a3, W3, b3) return a3, cache def backward_propagation(X, Y, cache): """ Implement the backward propagation presented in figure 2. Arguments: X -- input dataset, of shape (input size, number of examples) Y -- true "label" vector (containing 0 if cat, 1 if non-cat) cache -- cache output from forward_propagation() Returns: gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables """ m = X.shape[1] (z1, a1, W1, b1, z2, a2, W2, b2, z3, a3, W3, b3) = cache dz3 = 1./m * (a3 - Y) dW3 = np.dot(dz3, a2.T) db3 = np.sum(dz3, axis=1, keepdims = True) da2 = np.dot(W3.T, dz3) dz2 = np.multiply(da2, np.int64(a2 > 0)) dW2 = np.dot(dz2, a1.T) db2 = np.sum(dz2, axis=1, keepdims = True) da1 = np.dot(W2.T, dz2) dz1 = np.multiply(da1, np.int64(a1 > 0)) dW1 = np.dot(dz1, X.T) db1 = np.sum(dz1, axis=1, keepdims = True) gradients = {"dz3": dz3, "dW3": dW3, "db3": db3, "da2": da2, "dz2": dz2, "dW2": dW2, "db2": db2, "da1": da1, "dz1": dz1, "dW1": dW1, "db1": db1} return gradients def update_parameters(parameters, grads, learning_rate): """ Update parameters using gradient descent Arguments: parameters -- python dictionary containing your parameters grads -- python dictionary containing your gradients, output of n_model_backward Returns: parameters -- python dictionary containing your updated parameters parameters['W' + str(i)] = ... parameters['b' + str(i)] = ... """ L = len(parameters) // 2 # number of layers in the neural networks # Update rule for each parameter for k in range(L): parameters["W" + str(k+1)] = parameters["W" + str(k+1)] - learning_rate * grads["dW" + str(k+1)] parameters["b" + str(k+1)] = parameters["b" + str(k+1)] - learning_rate * grads["db" + str(k+1)] return parameters def predict(X, y, parameters): """ This function is used to predict the results of a n-layer neural network. Arguments: X -- data set of examples you would like to label parameters -- parameters of the trained model Returns: p -- predictions for the given dataset X """ m = X.shape[1] p = np.zeros((1,m), dtype = np.int) # Forward propagation a3, caches = forward_propagation(X, parameters) # convert probas to 0/1 predictions for i in range(0, a3.shape[1]): if a3[0,i] > 0.5: p[0,i] = 1 else: p[0,i] = 0 # print results print("Accuracy: " + str(np.mean((p[0,:] == y[0,:])))) return p def load_dataset(is_plot=True): np.random.seed(1) train_X, train_Y = sklearn.datasets.make_circles(n_samples=300, noise=.05) np.random.seed(2) test_X, test_Y = sklearn.datasets.make_circles(n_samples=100, noise=.05) # Visualize the data if is_plot: plt.scatter(train_X[:, 0], train_X[:, 1], c=train_Y, s=40, cmap=plt.cm.Spectral); train_X = train_X.T train_Y = train_Y.reshape((1, train_Y.shape[0])) test_X = test_X.T test_Y = test_Y.reshape((1, test_Y.shape[0])) return train_X, train_Y, test_X, test_Y def plot_decision_boundary(model, X, y): # Set min and max values and give it some padding x_min, x_max = X[0, :].min() - 1, X[0, :].max() + 1 y_min, y_max = X[1, :].min() - 1, X[1, :].max() + 1 h = 0.01 # Generate a grid of points with distance h between them xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # Predict the function value for the whole grid Z = model(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) # Plot the contour and training examples plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral) plt.ylabel('x2') plt.xlabel('x1') plt.scatter(X[0, :], X[1, :], c=y, cmap=plt.cm.Spectral) plt.show() def predict_dec(parameters, X): """ Used for plotting decision boundary. Arguments: parameters -- python dictionary containing your parameters X -- input data of size (m, K) Returns predictions -- vector of predictions of our model (red: 0 / blue: 1) """ # Predict using forward propagation and a classification threshold of 0.5 a3, cache = forward_propagation(X, parameters) predictions = (a3>0.5) return predictions
gc_utils.py
# -*- coding: utf-8 -*- #gc_utils.py import numpy as np import matplotlib.pyplot as plt def sigmoid(x): """ Compute the sigmoid of x Arguments: x -- A scalar or numpy array of any size. Return: s -- sigmoid(x) """ s = 1/(1+np.exp(-x)) return s def relu(x): """ Compute the relu of x Arguments: x -- A scalar or numpy array of any size. Return: s -- relu(x) """ s = np.maximum(0,x) return s def dictionary_to_vector(parameters): """ Roll all our parameters dictionary into a single vector satisfying our specific required shape. """ keys = [] count = 0 for key in ["W1", "b1", "W2", "b2", "W3", "b3"]: # flatten parameter new_vector = np.reshape(parameters[key], (-1,1)) keys = keys + [key]*new_vector.shape[0] if count == 0: theta = new_vector else: theta = np.concatenate((theta, new_vector), axis=0) count = count + 1 return theta, keys def vector_to_dictionary(theta): """ Unroll all our parameters dictionary from a single vector satisfying our specific required shape. """ parameters = {} parameters["W1"] = theta[:20].reshape((5,4)) parameters["b1"] = theta[20:25].reshape((5,1)) parameters["W2"] = theta[25:40].reshape((3,5)) parameters["b2"] = theta[40:43].reshape((3,1)) parameters["W3"] = theta[43:46].reshape((1,3)) parameters["b3"] = theta[46:47].reshape((1,1)) return parameters def gradients_to_vector(gradients): """ Roll all our gradients dictionary into a single vector satisfying our specific required shape. """ count = 0 for key in ["dW1", "db1", "dW2", "db2", "dW3", "db3"]: # flatten parameter new_vector = np.reshape(gradients[key], (-1,1)) if count == 0: theta = new_vector else: theta = np.concatenate((theta, new_vector), axis=0) count = count + 1 return theta
testCase.py
import numpy as np def compute_cost_with_regularization_test_case(): np.random.seed(1) Y_assess = np.array([[1, 1, 0, 1, 0]]) W1 = np.random.randn(2, 3) b1 = np.random.randn(2, 1) W2 = np.random.randn(3, 2) b2 = np.random.randn(3, 1) W3 = np.random.randn(1, 3) b3 = np.random.randn(1, 1) parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2, "W3": W3, "b3": b3} a3 = np.array([[ 0.40682402, 0.01629284, 0.16722898, 0.10118111, 0.40682402]]) return a3, Y_assess, parameters def backward_propagation_with_regularization_test_case(): np.random.seed(1) X_assess = np.random.randn(3, 5) Y_assess = np.array([[1, 1, 0, 1, 0]]) cache = (np.array([[-1.52855314, 3.32524635, 2.13994541, 2.60700654, -0.75942115], [-1.98043538, 4.1600994 , 0.79051021, 1.46493512, -0.45506242]]), np.array([[ 0. , 3.32524635, 2.13994541, 2.60700654, 0. ], [ 0. , 4.1600994 , 0.79051021, 1.46493512, 0. ]]), np.array([[-1.09989127, -0.17242821, -0.87785842], [ 0.04221375, 0.58281521, -1.10061918]]), np.array([[ 1.14472371], [ 0.90159072]]), np.array([[ 0.53035547, 5.94892323, 2.31780174, 3.16005701, 0.53035547], [-0.69166075, -3.47645987, -2.25194702, -2.65416996, -0.69166075], [-0.39675353, -4.62285846, -2.61101729, -3.22874921, -0.39675353]]), np.array([[ 0.53035547, 5.94892323, 2.31780174, 3.16005701, 0.53035547], [ 0. , 0. , 0. , 0. , 0. ], [ 0. , 0. , 0. , 0. , 0. ]]), np.array([[ 0.50249434, 0.90085595], [-0.68372786, -0.12289023], [-0.93576943, -0.26788808]]), np.array([[ 0.53035547], [-0.69166075], [-0.39675353]]), np.array([[-0.3771104 , -4.10060224, -1.60539468, -2.18416951, -0.3771104 ]]), np.array([[ 0.40682402, 0.01629284, 0.16722898, 0.10118111, 0.40682402]]), np.array([[-0.6871727 , -0.84520564, -0.67124613]]), np.array([[-0.0126646]])) return X_assess, Y_assess, cache def forward_propagation_with_dropout_test_case(): np.random.seed(1) X_assess = np.random.randn(3, 5) W1 = np.random.randn(2, 3) b1 = np.random.randn(2, 1) W2 = np.random.randn(3, 2) b2 = np.random.randn(3, 1) W3 = np.random.randn(1, 3) b3 = np.random.randn(1, 1) parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2, "W3": W3, "b3": b3} return X_assess, parameters def backward_propagation_with_dropout_test_case(): np.random.seed(1) X_assess = np.random.randn(3, 5) Y_assess = np.array([[1, 1, 0, 1, 0]]) cache = (np.array([[-1.52855314, 3.32524635, 2.13994541, 2.60700654, -0.75942115], [-1.98043538, 4.1600994 , 0.79051021, 1.46493512, -0.45506242]]), np.array([[ True, False, True, True, True], [ True, True, True, True, False]], dtype=bool), np.array([[ 0. , 0. , 4.27989081, 5.21401307, 0. ], [ 0. , 8.32019881, 1.58102041, 2.92987024, 0. ]]), np.array([[-1.09989127, -0.17242821, -0.87785842], [ 0.04221375, 0.58281521, -1.10061918]]), np.array([[ 1.14472371], [ 0.90159072]]), np.array([[ 0.53035547, 8.02565606, 4.10524802, 5.78975856, 0.53035547], [-0.69166075, -1.71413186, -3.81223329, -4.61667916, -0.69166075], [-0.39675353, -2.62563561, -4.82528105, -6.0607449 , -0.39675353]]), np.array([[ True, False, True, False, True], [False, True, False, True, True], [False, False, True, False, False]], dtype=bool), np.array([[ 1.06071093, 0. , 8.21049603, 0. , 1.06071093], [ 0. , 0. , 0. , 0. , 0. ], [ 0. , 0. , 0. , 0. , 0. ]]), np.array([[ 0.50249434, 0.90085595], [-0.68372786, -0.12289023], [-0.93576943, -0.26788808]]), np.array([[ 0.53035547], [-0.69166075], [-0.39675353]]), np.array([[-0.7415562 , -0.0126646 , -5.65469333, -0.0126646 , -0.7415562 ]]), np.array([[ 0.32266394, 0.49683389, 0.00348883, 0.49683389, 0.32266394]]), np.array([[-0.6871727 , -0.84520564, -0.67124613]]), np.array([[-0.0126646]])) return X_assess, Y_assess, cache def gradient_check_n_test_case(): np.random.seed(1) x = np.random.randn(4,3) y = np.array([1, 1, 0]) W1 = np.random.randn(5,4) b1 = np.random.randn(5,1) W2 = np.random.randn(3,5) b2 = np.random.randn(3,1) W3 = np.random.randn(1,3) b3 = np.random.randn(1,1) parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2, "W3": W3, "b3": b3} return x, y, parameters
?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/523184.html
標籤:其他
上一篇:Shell腳本2