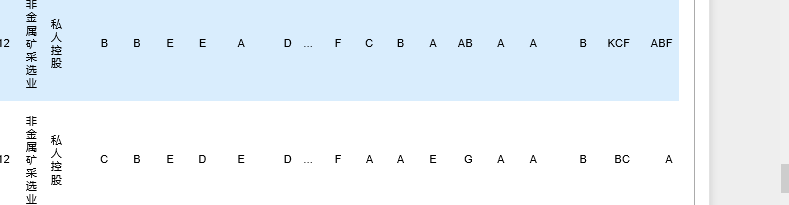
這個每一行有各種 abd acf bf 多選題 怎么分類統計呢?
每一個行業這一題有多少個a 多少個d
每個控股方式這一題有幾個a
試了各種 就是回傳 多少個 abd 多少個acf 這樣子。。
求大神幫助。。。

uj5u.com熱心網友回復:
沒搞懂你要做什么uj5u.com熱心網友回復:
資料是很多家公司的問卷調查資料。。。
第一列是行業 第二列是控股方式 abcd那些是每個題目他們的回答
想統計不同行業 每個題目的 a有多少個。。b有多少個。。。
uj5u.com熱心網友回復:
lista=['c','b','c','b','abc','abd','acd','abd','acd']
dictb={}
for lista1 in lista:
if dictb.get(lista1,"fff")=="ffff":
dictb[lista1]=1
else:
dictb[lista1]+=1
print(dictb)
uj5u.com熱心網友回復:
.
lista = ['c', 'b', 'c', 'b', 'abc', 'abd', 'acd', 'abd', 'acd']
dictb = {}
for lista1 in lista:
if dictb.get(lista1, "fff") == "fff":
dictb[lista1] = 1
else:
dictb[lista1] += 1
print(dictb)
print(lista)
uj5u.com熱心網友回復:
lista = ['c', 'b', 'c', 'b', 'abc', 'abd', 'acd', 'abd', 'acd']
dictb = {}
for lista1 in lista:
for _,lista2 in enumerate(list(lista1)):
if dictb.get(lista2, "fff") == "fff":
dictb[lista2] = 1
else:
dictb[lista2] += 1
print(dictb)
print(lista)
全分解為單選
uj5u.com熱心網友回復:
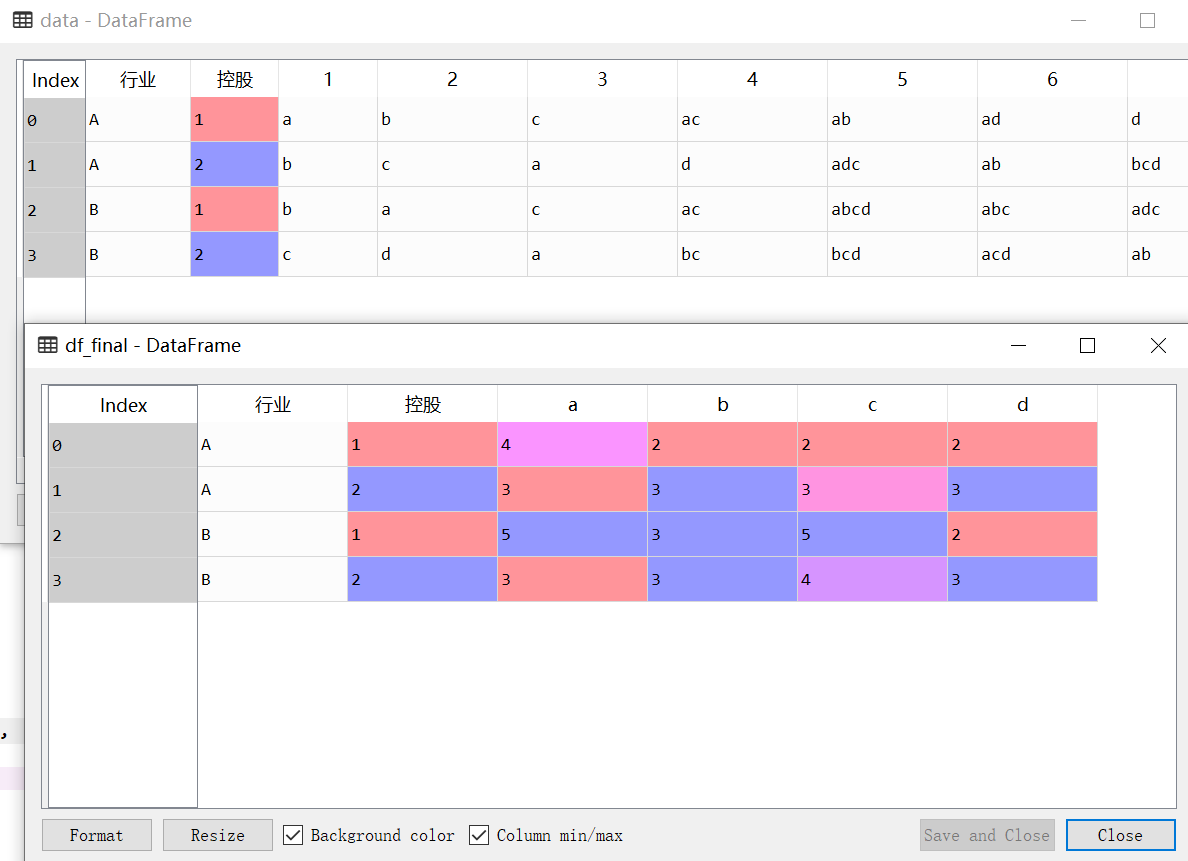
我自定義了一些資料,做了測驗。以下是代碼,你結合自己的資料試試看from collections import Counter
#讀入資料
data=https://bbs.csdn.net/topics/pd.read_excel(r'C:\Users\Desktop\ttt.xlsx')
#每一行所有題目的答案拼接在一起
data['匯總']=data.apply(lambda x: np.sum(x[2:9]), axis=1)
#僅選取需要的列
data1=data[['行業','控股','匯總']]
#自定義函式,對字母進行計數
def f(x):
ll= [c.lower() for c in x if c.isalpha()]
return Counter(ll)
counter = data1['匯總'].map(f)
#把字母計數 字典轉換為DataFrame
counterdf = pd.DataFrame()
counterdf=counter.map(lambda x: dict(x))
counterdf1=pd.DataFrame(list(counterdf.values))
#字母計數部分與源資料拼接在一起
df_final=pd.concat([data1,counterdf1],axis=1)[['行業', '控股', 'a', 'b', 'c', 'd']]
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/52670.html
上一篇:萌新求問,飛機大戰中key.getpressed()如何實作兩個按鍵同時作用?
下一篇:關于Pld預取的問題