基于深度學習對運維時序指標進行例外檢測,快速發現線上業務問題
時間序列的例外檢測是實際應用中的一個關鍵問題,尤其是在 IT 行業,我們沒有采用傳統的基于閾值的方法來實作例外檢測,而是通過深度學習提出了一種無閾值方法:基于 LSTM 網路的基線(一個 LSTM 框架輔助幾個優化步驟)和無監督檢測(神經網路和多種機器學習演算法的組合)協同綜合分析時間序列,當時間序列顯示出清晰的周期性形態的情況下基線表現良好,而無監督檢測在效率要求高且周期性不太清晰的情況下表現出色,通過兩個并行模塊的互補設計,可以在不依賴閾值設定和調整的情況下實作無閾值例外檢測,京東云內部實踐證明,我們所提出的無閾值方法獲得了準確的預測和可靠的檢測,
在過去的幾年中,aiops業界提出了各種解決例外檢測問題的方法,機器學習 (ML) 和深度學習 (DL) 頗受歡迎,在傳統的 ML 中,通常采用 K-means、基于密度的空間聚類和隔離森林 (IForest)等聚類方法,除了 ML,由于其強大的逼近能力,使用深度神經網路 (DNN) 進行時間序列預測和例外檢測被越來越多的演算法同學使用,多層感知器 (MLP) 是一種基本的 DNN 架構,用于評估時間序列上例外檢測的性能,此外,回圈神經網路 (RNN) 及其變體,如長短期記憶 (LSTM) 網路和門控回圈單元 (GRU) 是解決與時間序列相關的問題的常用方法,
對于大多數上述用于解決例外檢測的方法,一般是時間序列是否超出預定義的上限和下限,然而,固定閾值無法表征具有內在動態趨勢變化的時間序列,從而導致例外分析不準確,此外,由于單個閾值無法涵蓋所有?例外情況,因此該方法也容易遺漏例外,此外,設定上限和下限的程序是一項復雜且重要的任務,總是需要為各種情況定義新的閾值,耗時長且遷移性差,
為了解決上述問題,我們介紹一種新方法,即通過 DL 進行無閾值例外檢測,
我們的方法不需要預定義上限和下限,而是通過抽取一些易于調整的引數,在小范圍內自動搜索適配不同場景的監控資料,進而實作無閾值例外檢測:基于 LSTM 網路的基線模塊(LnB)和無監督檢測模塊(UnD),具體來說,LnB 生成基線,該基線能夠以自適應和自動的方式表征時間序列的動態特征, LnB 的框架是用 LSTM 網路構建的,長短周期識別方法是此框架的貢獻之一,它引入了一種糾正機制,可以實作更準確的擬合,生成的基線描述了檢測到的時間序列的主要特征,提供了替代傳統閾值的限制, UnD是一種DL和多種ML演算法的合并模型,基于投票機制從各個角度檢測到的時間序列是否正常,兩個模塊中的任何一個檢測到例外表明發生了例外,兩個模塊的融合使我們所提出的方法能夠以互補和全面的方式有效地分析具有不確定性或各種周期性的時間序列,
時間序列X=(x1, x2, ..., xt),我們的目標是確定下一步 xt+1 的值是否例外,歷史值有助于模型學習指標當前和未來的狀態,但與預測值距離越近的點對模型預測的影響越大,因此,我們選擇使用時間序列 Xt-T:t 的序列,而不是取時間序列的單個步長或整個歷史序列來進行例外檢測, T 是選擇作為模型訓練輸入的序列長度,下圖1為無閾值例外檢測的總體框架包括兩個階段,即訓練程序和在線檢測,
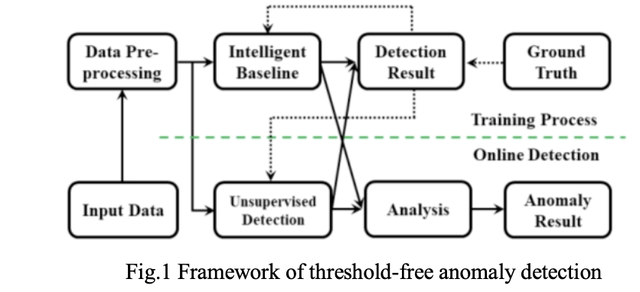
LnB 和 UnD兩個模塊都可以單獨完成例外檢測,但是兩個模塊有不同的擅長方面,每個模塊的結構差異為檢測到的時間序列提供了不同維度的檢測結果,其中,LnB將更長時期的歷史資料輸入到模塊中,它可以很好地說明特定時間序列的長期行為,但是 LnB 對那些周期性不明確的指標的例外檢測能力較弱,相反,UnD 從一個 DL 模型和多個 ML 模型中獲得投票結果,對具有不確定性或各種周期性的時間序列具有更強的魯棒性,此外,UnD 在輸入的檢測指標的歷史資料不足的情況下提供了更合理的檢測,
圖 1 中的實線箭頭表示前向流,而虛線箭頭表示反向傳播訓練,在得到每個模塊的檢測結果后,根據為每個模塊設定的損失函式分別對LnB和UnD進行反向傳播訓練,LnB和UnD都進行更新,即模型訓練,在模型訓練之后,LnB 學習生成一個自適應基線,同時,LnB為UnD賦予 基于無監督學習預測未來例外狀態的能力,
在線檢測不需要訓練步驟,所以按入參格式輸入時間序列,可直接得到檢測結果,這訓練和在線檢測兩個模塊的詳細介紹如下:

其中 f 表示模型學習所采用的網路,Ti 表示第 i 天的資料, 在訓練階段,a 和 b 會及時隨著傳入的指標資料自動更新,形成可適應的基線,在測驗狀態下,y ' final 是我們的最終預測,長短周期識別的重點是引入校正項,為歷史上最有價值的“記憶”賦予更多的權重,
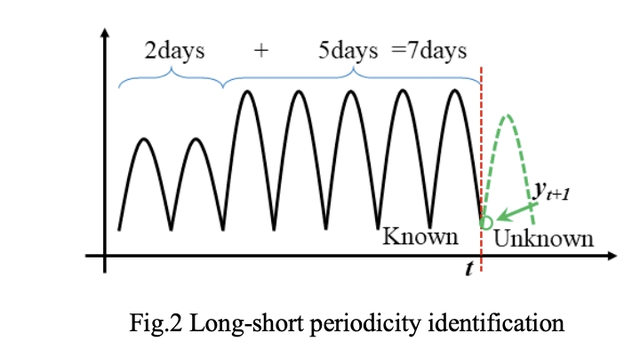
如上所述,有兩種方法用于識別長短周期,即峰值檢測和 SBD距離計算,每天的峰值數量、每天的峰值最大值以及每天第一和第二個最大值的殘差是用于識別長短周期,除了這種峰值檢查,SBD 是識別長短周期的替代方法,假設我們有兩個輸入序列 X 和 Y(在我們的例子中,14 天的資料被平均分成兩部分),兩個序列的SBD結果可以根據以下等式計算,
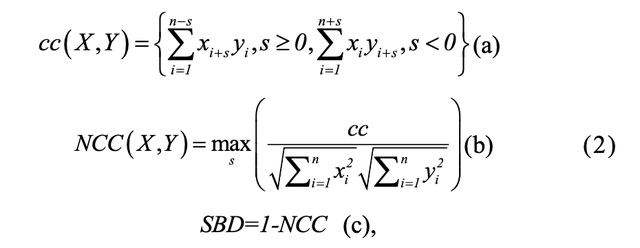
其中 SBD 的范圍從 0 到 2,在我們的案例中 s=0, SBD 越小,說明兩個序列屬于同一周期的相似度越高,
最佳開始時間通過尋找不同時間粒度(如10s 和 1min)下的最佳開始時間來關注擬合精度,待檢測的時間序列總是遵循一定的周期性,但根據我們的實驗驗證,在不同位置選擇的開始時間可能會導致擬合精度不同,我們選取均方根誤差 (RMSE) 用作優化搜索程序的目標函式:
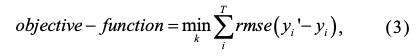
其中 y' 代表預測結果,而 y 代表基本事實, k 表示檢測到的序列中的第 k 個起始位置,采用L-BFGS通過最小化目標函式實作自動搜索,
基線生成 LnB 的核心程序是基線生成,與RNN相比,LSTM包含了三個門,即遺忘門、輸入門和輸出門,這種門設計在識別歷史中的重要資訊方面表現出更好的性能,減輕了對遠程歷史的依賴和梯度消失,輸入資料經 LSTM,輸出理論上暗示了正常資料的期望,因此,我們將損失函式訓練為:

通過減少實際值和預測值之間的誤差,網路可以學習預測時間序列的正常行為,
我們選擇 95% 置信區間,計算基線的上限和下限:
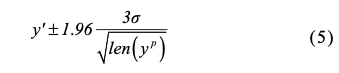
LnB 的最后一步是自適應調整,這是實作“自適應”的關鍵步驟,通過 LSTM 獲得的上限和下限是初始基線,然后通過極值點平滑和插值修改初始基線,即初始基線中的所有峰點和谷點都形成了初始上限和下限,然后采用拉格朗日插值進行細粒度資料填充以形成平滑的基線,
DL (GRU) 和 ML(IForest、基于角度的例外值檢測-ABOD 和基于集群的區域例外值因子-CBLOF)從多個級別檢測例外,不需要標簽資訊或閾值定義,作為回歸任務,GRU 學習給定時間序列的正態分布并輸出對未來的預測,與 LSTM 從長期歷史中捕捉內在特征的能力相比,GRU 在資料量不足且需要效率的情況下理論上表現良好,與 LnB 不同,UnD 將較短的序列作為輸入,因此,UnD 中的 GRU 單元是 LnB 的補充,另一方面,IForest、ABOD 和 CBLOF 是用于例外檢測的三種基于 ML 的聚類演算法, UnD的最終檢測是GRU、IForest、ABOD和CBLOF通過投票方案的合并結果,
對于 GRU,我們采用與 LnB 相同的損失函式,區別在于輸入長度(在下一節中解釋),訓練有素的 GRU 會給出預測的準確值 y',在這里,定義例外權重 (AW) 以確定預測是否例外,

AW 是例外識別的關鍵決定因素,并且根據經驗知識自動學習以滿足在我們的案例中檢測到的例外百分比應在 1%-3% 以內的條件,當涉及到不同的領域或資料集時,也可以根據經驗知識確定 AW, IForest、ABOD和CBLOF是常用的例外值檢測方法,它們的輸出結果可以看作是一個描述例外概率的分數,然后將所有 GRU、IForest、ABOD 和 CBLOF 的檢測結果編碼并拼接成一個 one-hot 矩陣,其中 0 表示正常,1 表示例外,如圖 3 所示的示例,接下來,我們得到每個時間步對應的“1”的總數,通過與投票數 n (在我們的例子中 n = 2)的比較,如果“1”的總數不小于 n ,則合并結果被檢測為例外,反之亦然, n 是一個引數,需要通過幾個簡單的試驗來確定,例如逐漸增加值或縮小范圍,
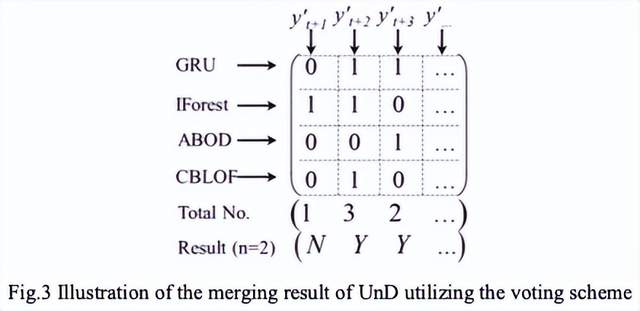
通過投票方案的合并結果可以從不同方面揭示內在特征,因為 GRU 的回歸結果包含顯示增加或減少趨勢的精確值,而 ML 結果呈現 0 或 1 僅表示例外與否,但具有更準確的決策,因為這些模型可以利用從附加維度或測量中捕獲的資訊(例如,基于角度視角的 ABOD 和基于概率視角的 CBLOF),因此,多個高級演算法的合并結果可以充分利用給定的資料進行全面的預測,
我們的模型主要有三個步驟,詳細介紹如下:
第一步:資料預處理
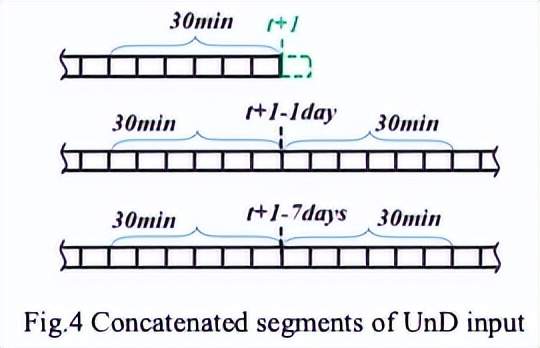
LnB和UnD對資料拆分和連接有不同的要求,兩個模塊的輸入資料是不同的,例如,當前時間為 t,時間序列的周期性為 T(如 7 天),我們的目標是檢測 t+1 時刻的值是否例外,在這種情況下,LnB 的輸入是過去 2*T 周期(即 14 天)收集的歷史資料,選擇 2*T 周期的原因是 14 天之前的歷史資料重要性較低,如果只收集一個周期的資料,可能會受到例外事件的影響,相反,UnD采用最相關的資訊而不是使用長歷史,并且選擇三個滑動視窗覆寫的序列作為輸入資料,三個視窗的長度分別為 30 分鐘、60 分鐘和 60 分鐘,
從圖4可以看出,UnD輸入中有3個段串聯,即[Xt-30min:t, Xt+1-1day-30min:t+1- 1day+30min, Xt+1-7days-30min: t+1-7 天+30 分鐘],這種連接提供了一種新的輸入結構設計,為特征學習和未來預測提供了最相關的資訊,總之,LnB 將過去 14 天的序列作為輸入,而 UnD 將過去 30 分鐘、1 天前的 60 分鐘和 7 天前的 60 分鐘作為輸入,
資料填充采用 K-NN 作為資料填充方法,以確保所有輸入樣本的長度相同且可讀,資料過濾為保證輸入資料的有效性,對輸入資料進行平滑過濾,以消除因噪聲引起的毛刺,資料轉換對訓練結果和快速收斂非常重要,在輸入訓練程序之前,原始資料還需要一個轉換程序,包括歸一化和對數轉換,如(7)所示,
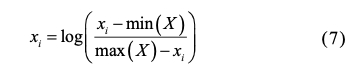
歸一化避免了不同維度的副作用,有利于模型快速收斂,此外,它還確保輸出不會超過輸入的最小值和最大值,因為在輸出上實施了指數變換,同時,對數變換可以在不改變資料特征和資料相關性的情況下,減輕方差,平滑變化,
第二步:模型訓練
如圖 1 中的流程圖所示,LnB 和 UnD 都是根據訓練資料分別訓練的,但是,如上所述,兩個模塊的輸入是不同的, LnB 將較長的歷史資料作為輸入,并嘗試捕獲檢測到的時間序列的豐富資訊,而 UnD 將最相關但較短的序列部署為訓練資料, UnD 中的GRU和 LnB通過減少第二部分中介紹的損失函式來學習檢測到的序列的正常行為,同時,IForest、ABOD 和 CBLOF 學習了無監督聚類模型,上述單元的所有輸出都是一步超前的例外檢測,
第三步:在線例外檢測
在運行時,傳入的資料首先進入預處理模塊,然后同時進入LnB和UnD,輸入資料的格式應與訓練階段一致,如果兩個模塊的任一結果例外,則提示待檢測資料例外,LnB和UnD的融合機制對時間序列進行了全面的檢測,降低了潛在例外遺漏的概率,另一方面,LnB 中較長的歷史輸入和 UnD 中的多模型投票方案有效地避免了將正常的誤認為是例外的,
經過京東內部多場景多組資料驗證,模型在線上運行的效果評估如下表所示:
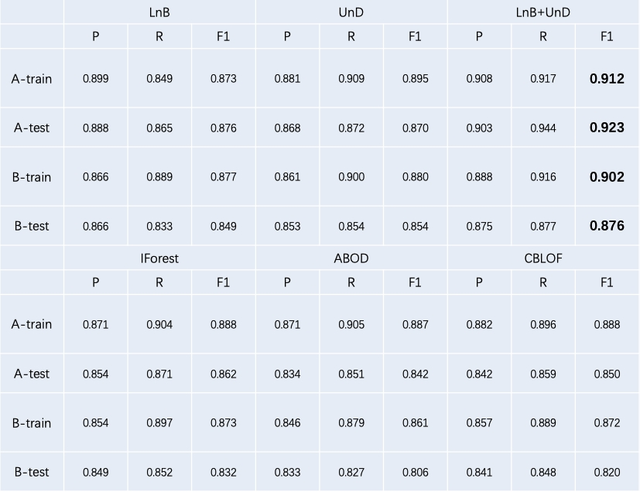
此外,可以靈活選擇“and”或“or”來整合LnB和UnD的結果,沒有統一的規則,要看實際場景的需求,在我們的落地實踐場景中,這兩個資料集都需要保證召回率,因此我們采取“或”操作,這意味著無論哪個檢測到例外都會報警,如果需要較低的警告級別,我們可以選擇“和”作為積分運算,選擇三個流行的基線 IForest、ABOD 和 CBLOF 進行比較,此外,我們還比較了我們的方法和單獨使用 LnB 或 UnD 的方法的結果,如上表所示,從定量比較中,很明顯,所提出的方法,即 LnB+UnD 在兩者中都獲得了最高的 F1 分數資料集, LnB+UnD 的組合比單獨采用 LnB 或 UnD 效果更好,而且我們的模型優于其他三個基線,這也證明了我們并行機制的有效性和必要性,
我們提出的一種用于時間序列分析的無閾值例外檢測方法,即 LSTM 構建的 LnB和DL、ML 模型融合機制構建的 UnD,以互補和智能的方式實作例外檢測,在具有不同長短周期和變化趨勢的真實實踐場景的兩個資料集上進行了實驗,比較結果證明了我們方法的有效性和準確性,
-
Threshold-free Anomaly Detection for Streaming Time Series through Deep Learning. ICMLA.
-
**ieeexplore檢索:**https://ieeexplore.ieee.org/abstract/document/9680175
作者:張靜
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/527866.html
標籤:其他