字符儲存在1~length的位置上
簡單模式匹配
? 思路:從主串的第一個位置起和模式串的第一個字符開始比較,如果相等,則繼續逐一比較后續字符;否則從主串的第二個字符開始,再重新用上一步的方法與模式串中的字符做比較,以此類推,直到比較完模式串中的所有字符,若匹配成功,則回傳模式串在主串中的位置;若匹配不成功,則回傳一個可區別于主串所有位置的標記,如“0”,
int index(Str str,Str substr)
{
int i = 1,j = 1,k = 1;//串從陣列下標1位置開始存盤,初值為1
while(i <= str.length && j <= substr.length)
{
if(str.ch[i] == substr[j])
{
i++;
j++;
}
else
{
j = 1;
i = ++k;//匹配失敗,i從主串的下一個位置開始匹配,k儲存了主串上一次的起始位置
}
}
if(j > substr.length)
return k;
else ruturn 0;
}
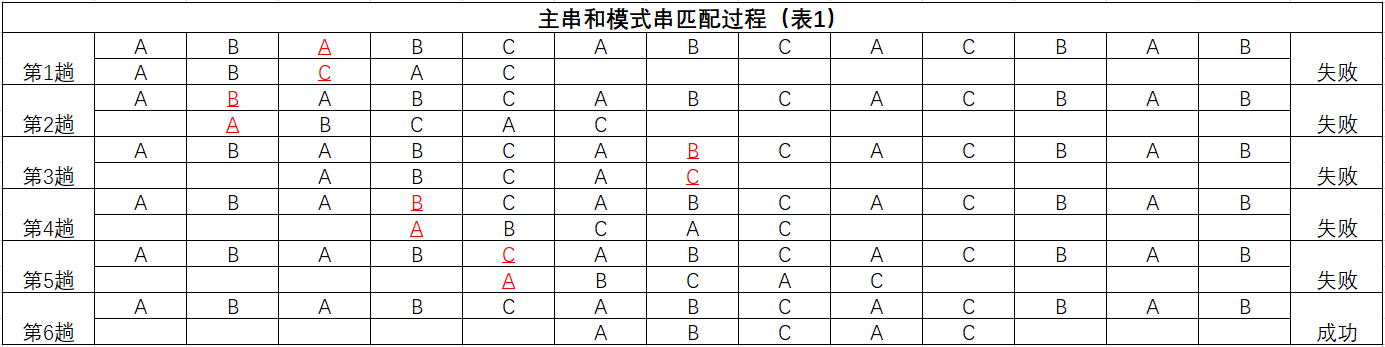
主串(ABABCABCACBAB)和模式串(ABCAC)匹配程序
KMP演算法
? 設主串為s1s2...sn,模式串為p1p2...pm,在上面的匹配程序中,經常出現一個關鍵狀態(表2),其中i和j分別為主串和模式串中當前參與比較的兩個字符的下標,

? 模式串的前部某子串P1P2...Pj-1與主串中的一個子串Si-j+1Si-j+2...Si-1匹配,而Pj與Si不匹配,每當出現這種狀態時,簡單模式匹配演算法的做法是:一律將i賦值為i-j+2,j賦值為1,重新開始比較,這個程序反映到表2中可以形象地表示為模式串先向后移動一個位置,然后從第一個字符P1開始逐個和當前主串中對應的字符做比較;當再次發現不匹配時,重復上述程序,這樣做的目的是試圖消除Si處的不匹配,進而開始Si+1及其以后字符的比較,使得整個程序得以推進下去,
? 如果在模式串后移的程序中又出現了其前部某子串P1P2…與主串中某子串…Si-2Si-1相匹配的狀態,則認為這是一個進步的狀態,因為通過模式串后移排除了一些不可能匹配的狀態,來到了一個新的區域匹配狀態,并且此時Si有了和模式串中對應字符匹配的可能性,為了方便表述,記表中描述的狀態為Sk,此處的新狀態為Sk+1,此時可以將簡單模式匹配程序看成一個由Sk向Sk+1推進的程序,當由Sk來到Sk+1時有兩種情況可能發生:其一,S處的不匹配被解決,從si+1繼續往下比較,若來到新的不匹配字符位置,則模式串后移尋找狀態Sk+2;其二,Si處的不匹配仍然存在,則模式串繼續后移尋找狀態Sk+2如此進行下去,直到得到最終結果,
? 說明:為了使上邊其一與其二的表述看起來清晰工整且抓住重點,此處省略了對匹配成功與失敗這兩種容易理解的情況的描述,
? 說明:模式串后移使P1移動到Si+1,即模式串整個移過Si的情況也認為是Si處的不匹配被解決,試想,如果在匹配程序中可以省略掉模式串逐漸后移的程序,而從Sk直接跳到Sk+1,則可以大大提高匹配效率,帶著這個想法,我們把Sk+1狀態添加到表2中得到表3,

? 觀察發現,P1P2...Pj-1和Si-j+1Si-j+2...Si-1是完全相同的,且我們研究的是從Sk跳到Sk+1,因此,洗掉表3關于主串的一行,得到表4,

? 由表4可知,P1P2...Pt-1和Pj-t+1Pj-t+2...Pj-1匹配,記P1P2..Pj-1為F,記P1P2...Pt-1為FL,記Pj-t+1Pj-t+2...Pj-1為FR,所以,只需將F后移到使得FL和FR重合的位置(上表有色部位),即可實作Sk直接跳到Sk+1,
? 總結一般情況:每當發生不匹配的時候,找出模式串當中的不匹配的那個字符Pj,取其之前的子串F=P1P2...Pj-1,將模式串后移,使F最先發生前部(FL)與后部(FR)相重合的位置(見表中有色區域所示),即為模式串應后移的目標位置,
? 為了使問題表述得更形象,采用了模式串后移這種分析方式,事實上,在計算機中模式串是不會移動的,因此需要把模式串后移轉化為j的變化,模式串后移到某個位置可等效于j重新指向某位置,容易看出,j處發生不匹配時,j重新指向的位置恰好是F串中前后相重合子串的長度+1(串F或F長度+1),通常我們定義一個next]陣列,其中j取1~m,m為模式串長度,表示模式串中第j個字符發生不匹配時,應從next]處的字符開始重新與主串比較,
特殊情況:
? 1)模式串中的第一個字符與主串i位置不匹配,應從下一個位置和模式串第一個字符繼續比較,反映在從si+1與p1開始比較,
? 2)當串F中不存在前后重合的部分時(不可將F自身視為和自身重合),則從主串中發生不匹配的字符與模式串第一個字符開始比較,反映在表4-2中即從s1與p1開始比較,
下邊以下表中的模式串為例,介紹求陣列next的方法,

? 1)當j等于1時發生不匹配,屬于特殊情況1,此時將next[1]賦值成0來表示這個特殊情況,
? 2)當j等于2時發生不匹配,此時F為“”,屬于特殊情況2),即next[2]賦值為1,
? 3)當j等于3時發生不匹配,此時F為“AB”,屬于特殊情況2),即next[3]賦值為1,
? 4)當j等于4時發生不匹配,此時F為“ABA”,前部子串A與后部子串A重合,長度為1,因此next[4]賦值為2(F或FR長度+1),
? 5)當j等于5時發生不匹配,此時F為“ABAB”,前部子串AB與后部子串AB重合,長度為2,因此next[5]賦值為3,
? 6)當j等于6時發生不匹配,此時F為“ABAB”,前部子串ABA與后部子串ABA最先發生重合,長度為3,因此next[6]賦值為4,
? 7)當j等于7時發生不匹配,此時F為“ABABAB”,前部子串ABAB與后部子串ABAB最先發生
重合,長度為4,因此next[7]賦值為5,
? 注意:6)和7)中出現了“最先"字眼,以7)為例,F向后移動,會發生兩次前部與后部的重合,第一次是ABAB,第二次是AB,顯然最先發生重合的是ABAB.之所以選擇最先的ABAB,而不是第二次的AB,是因為模式串是不停后移的,選擇AB則丟掉了一次解決不匹配的可能性,而選擇ABAB,即使當前解決不了,則下一個狀態就是AB,不會丟掉任何解決問題的可能,這里也解釋了一些參考書中提到的取最長相等前后的原因,7)中的ABAB或AB在一些參考書中稱為F的相等前后綴(即FL和FR為F的相等前后綴),ABAB是最長相等前后綴,并且很顯然的是,越先發生重合的相等前后綴長度越長,
next陣列

? 上述方法為手工求next陣列的方法,介紹一下適用于轉換成代碼的高效的求next陣列的方法,
? 假設next[j]的值已知,則next[j+1]的求值可以分兩種情況分析,
? 1)若Pj等于Pt,顯然next[j+1]=t+1,因為t為當前F最長相等前后綴長度(t為FL和FR長度),
? 2)若Pj不等于Pt,將Pj-t+1Pj-t+2...Pj當作主串,P1P2...Pt當作子串,則又回到了由狀態Sk找Sk+1的程序,所以只需將t賦值為next[t],繼續進行Pj與Pt的比較,如果滿足1)則求得next[j+1],不滿足則重復t賦值為next[t],并比較Pj與Pt的程序,如果在這個程序中t出現等于0的情況,則應將next[J+1]賦值為1,此處類似于上邊講到的特殊情況2),
? 說明:Sk直接跳到Sk+1,也就是通常所說的簡單模式匹配演算法中i不需要回溯,
注意:MP演算法中的i不需要回溯這里隱藏著一個考點,i不需要回溯意味著對于規模較大的外存中字串的匹配操作可以分段進行,讀入記憶體一部分進行匹配,完成之后即可寫回外存確保在發生不匹配時不需要將之前寫回外存的部分再次讀入,減少了IO操作,提高了效率,在回答KMP演算法較之于簡單模式匹配演算法的優勢時,不要忘掉這一點,
演算法如下
void getnext(Str substr,int next[])
{
int i = 1,j = 0;//串從下標為1的位置開始存盤,i初值為1
next[1] = 0;
while(i < substr.length)
{
if(j == 0 || substr.ch[i] == sbustr[j])
{
++i;
++j;
next[i] = j;
}
else
j = next[j]//理解這一點,回溯
}
}
? 得到next陣列后,將簡單模式匹配演算法稍作修改就可以由狀態Sk直接跳到Sk+1的改進演算法,這就是知名的KMP演算法,代碼如下:
int KMP(Str str,Str substr,int next[])
{
int i = 1,j = 1;//串從陣列下標1處開始
while(i <= str.length && j <= substr.length)
{
if(j == 0 || str.ch[i] == substr.ch[j])
{
++i;
++j;
}
else
j = next[j];
}
if(j > substr.length)
return i - substr.length;
else
return 0;
}
KMP演算法的改進
? 先看一種特殊情況,見表7,當j等于,發生不匹配時,因next[5]=4,則需將j回溯到4進行比較;又因next[4]=3,則應將j回溯到3進行比較…由此可見,j需要依次在5、4、3、2、1的位置上進行比較,而模式串在1到5的位置上的字符完全相等,因此較為聰明的做法應該是在j等于5處發生不匹配時,直接跳過位置1到4的多余比較,這就是KMP演算法改進的切入點,

? 將上述程序推廣到一般情況為:
? 若Pj等于Pk1(k1=next[j]),則繼續比較Pj與Pk2(k2=next[next[j]]),若仍相等則繼續比較下去,直到Pj與Pkn不等(kn=next[next[next[j]…]],嵌套n個next)或kn等于0時,則next[j]重置為kn,一般保持next陣列不變,而用名為 nextval的陣列來保存更新后的next陣列,即當Pj與Pkn不等時, nextval[j]賦值為kn,
? 下面通過一個例題來看一下 nextval的推導程序,
? 【例】求模 ABABAAB式串的next陣列和 nextval陣列,
? 首先求出next陣列,見表8,

? 1)當j為1時,nextval[1]賦值為0,特殊情況標記,
? 2)當j為2時,P2為B,Pk1(k1=next[2],值為1)為A,兩者不等,因此 nextval[2]賦值為1,
? 3)當j為3時,P3為A,Pk1(k1=next[3],值為1)為A,兩者相等,因此應先判斷k2是否為0,而k2等于next[next[3]],值為0,所以 nextval[3]賦值為k2,值為0,
? 注意:步驟3)中P3與Pk1(k1=next[3])比較相等后,按照之前的分析應先判斷k2是否為0,再讓P3繼續與Pk2比較,注意到此時 nextval[next[3]]即 nextval[1]的值已經存在,故只需直接將 nextval[3]直接賦值為 nextval[1]即可,即 nextval[3]=nextval[3]=0,
? 推廣到一般情況為:當Pj等于Pk1(k1=next[j])時,只需讓 nextval[j]賦值為 nextval[next[j]]即可,原因有兩點:
? ① nextval陣列是從下標1開始逐漸往后求得的,所以在求 nextval[j]時, nextval[next[j]]必已求得,
? ② nextval[next[j]]為Pj與Pk2到Pkn比較結果的記錄,因此無須再重復比較,
? 4)當j為4時,P4為B,Pk(k=next[4])為B,兩者相等,因此 nextval[4]賦值為 nextval[next[4]]值為1,
? 5)當j為5時,P5為A,Pk(k=next[5])為A,兩者相等,因此nextval[5]賦值為nextval[next[5]],值為0,
? 6)當j為6時,P6為A,Pk(k=next[6])為B,兩者不等,因此nextval[6]賦值為next[6],值為4,
? 7)當j為7時,P7為B,Pk(k=next[7])為B,兩者相等,因此nextval[7]賦值為nextval[next[7]],值為1,
? 由此求得nextval陣列見表9

? 總結求nextval的一般步驟:
? 1)當j等于1時,nextval[j]賦值為0,作特殊標記,
? 2)當Pj不等于Pk時(k=next[j]),nextval[j]賦值為k,
? 3)當Pj等于Pk時(k=next[j]),nextval[j]賦值為nextval[k],
? 求next陣列的函式getnext()的核心代碼段:
if(j == 0 || substr.ch[i] == substr.ch[j])
{
++i;
++j;
next[i] = j;//1
}
else
j = next[j];//2
? 在注釋1處next[i]已求出,且next[0...i-1]皆已求出,則結合上邊的總結,要求nextval,可以在1處添加以下代碼
next[i] = j;//1:i處不匹配,應跳回j處
if(substr.ch[i] != substr.ch[next[i]])
nextval[i] = next[i];
else
nextval[i] = nextval[next[i]];
? 顯然,在注釋2處用next陣列來回溯j的代碼可以用已求得的nextval陣列代替(注意,j往前跳,之前的nextval值已經求得),修改后的代碼如下:
j = nextval[j];//2
? 通過以上的分析,可以將函式的getnext()中的next陣列用nextval陣列代替掉,最終得到求nextval的代碼:
void getnextval(Str substr,int nextval[])
{
int i = 1,j = 0;//串從陣列下標1位置開始儲存,因此初值為1
nextval[1] = 0;
while(i < substr.length)
{
if(j == 0 || substr.ch[i] == substr.ch[j])
{
++i;
++j;
if(substr.ch[i] != substr.ch[j])
nextval[i] = j;
else
nextval[i] = nextval[j];
}
else
j = nextval[j];
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/5289.html
標籤:其他
上一篇:leetcode刷題筆記-3. 無重復字符的最長子串(java實作)
下一篇:UVa439(騎士的移動)