摘要:在本文中,我們將介紹用于測驗的相關指標,如何進行大規模測驗,以及我們如何實作大規模的集群接入,
本文分享自華為云社區《突破100倍集群規模!Karmada大規模測驗報告發布》,作者:華為云云原生團隊,
摘要
隨著云原生技術在越來越多的企業和組織中的大規模落地,如何高效、可靠地管理大規模資源池以應對不斷增長的業務挑戰成為了當下云原生技術的關鍵挑戰,在過去的很長一段時間內,不同廠商嘗試通過定制Kubernetes原生組件的方式擴展單集群的規模,這在提高規模的同時也引入了復雜的單集群運維、不清晰的集群升級路徑等問題,而多集群技術能在不侵入修改Kubernetes單集群的基礎上橫向擴展資源池的規模,在擴展資源池的同時降低了企業的運維管理等成本,
在Karmada的大規模落地行程中,Karmada的可擴展性和大規模逐漸成為社區用戶的新關注點,因此,我們對Karmada開展了大規模環境下的測驗作業,以獲取Karmada管理多個Kubernetes集群的性能基線指標,對于以Karmada為代表的多集群系統而言,單集群的規模不是制約它的資源池規模的限制因素,因此,我們參考了Kubernetes的大規模集群的標準配置和用戶的生產落地實踐,測驗了Karmada同時管理100個5k節點和2wPod的Kubernetes集群的用戶場景,受限于測驗環境和測驗工具,本次測驗并未追求測驗到Karmada多集群系統的上限,而是希望能覆寫到在生產中大規模使用多集群技術的典型場景,根據測驗結果分析,以Karmada為核心的集群聯邦可以穩定支持100個大規模集群,管理超過50萬個節點和200萬個Pod,可以滿足用戶在大規模生產落地的需要,
在本文中,我們將介紹用于測驗的相關指標,如何進行大規模測驗,以及我們如何實作大規模的集群接入,
背景
隨著云原生技術的不斷發展和使用場景的不斷豐富,多云、分布式云逐漸成為引領云計算發展的趨勢,著名分析公司 Flexera 在 2021 的調查報告顯示,超過 93%的企業正同時使用多個云廠商的服務,一方面受限于 Kubernetes 單集群的業務承載能力和故障恢復能力,單一的集群無法適應現有的企業業務,另一方面,在全球化的當下,企業出于避免被單家廠商壟斷的目的,或是出于成本等因素考慮,更傾向于選擇混合云或者多公有云的架構,與此同時,Karmada 社區的用戶在落地的行程中也提出了多集群下大規模節點和應用管理的訴求,
Karmada 介紹
Karmada(Kubernetes Armada)是一個 Kubernetes 管理系統,它能夠使你在無需修改應用的情況下跨集群和跨云運行你的云原生應用,通過使用 Kubernetes 原生 API 并在其上提供高級調度功能,Karmada 實作了真正開放的多云 Kubernetes,
Karmada 旨在為多云和混合云場景中的多集群應用管理提供完全的自動化,它具備集中式多云管理、高可用性、故障恢復和流量調度等關鍵特性,
Karmada 控制面包括以下組件:
- Karmada API Server
- Karmada Controller Manager
- Karmada Scheduler
ETCD 存盤了 Karmada 的 API 物件, karmada-apiserver 提供了與所有其他組件通信的 REST 埠, 之后由 karmada-controller-manager 對你向 karmada-apiserver 提交的 API 物件進行對應的調和操作,
karmada-controller-manager 運行著各種控制器,這些控制器 watch 著 Karmada 的物件,然后發送請求至成員集群的 apiserver 來創建常規的 Kubernetes 資源,
多集群系統資源池規模的維度和閾值
一個多集群系統的資源池規模不單指集群數量,即Scalability!=#Num of Clusters, 實際上多集群資源池規模包含很多維度的測量,在不考慮其他維度的情況下只考慮集群數量是毫無意義的,
我們將一個多集群的資源池規模按優先級描述為以下所示的三個維度:
- Num of Clusters: 集群數量是衡量一個多集群系統資源池規模和承載能力最直接且最重要的維度,在其余維度不變的情況下系統能接入的集群數量越多,說明系統的資源池規模越大,承載能力越強,
- Num of Resources(API Objects): 對于一個多集群系統的控制面來說,存盤并不是無限制的,而在控制面創建的資源物件的數量和總體大小受限于系統控制面的存盤,也是制約多集群系統資源池規模的重要維度,這里的資源物件不僅指下發到成員集群的資源模板,而且還包括集群的調度策略、多集群服務等資源,
- Cluster Size: 集群規模是衡量一個多集群系統資源池規模不可忽視的維度,一方面,集群數量相等的情況下,單個集群的規模越大,整個多集群系統的資源池越大,另一方面,多集群系統的上層能力依賴系統對集群的資源畫像,例如在多集群應用的調度程序中,集群資源是不可或缺的一個因素,綜上所述,單集群的規模與整個多集群系統息息相關,但單集群的規模同樣不是制約多集群系統的限制因素,用戶可以通過優化原生的Kubernetes組件的方式來提升單集群的集群規模,達到擴大整個多集群系統的資源池的目的,但這不是衡量多集群系統性能的關注點,本次測驗中,社區參考了kubernetes的大規模集群的標準配置以及測驗工具的性能,制定了測驗集群的規模,以貼切實際生產環境中的單集群配置,在集群的標準配置中,Node與Pod毫無疑問是其中最重要的兩個資源,Node是計算、存盤等資源的最小載體,而Pod數量則代表著一個集群的應用承載能力,事實上,單集群的資源物件也包括像service,configmap,secret這樣的常見資源,這些變數的引入會使得測驗程序變得更復雜,所以這次測驗不會過多關注這些變數,
- Num of Nodes
- Num of Pods
對于多集群系統而言想要無限制地擴展各個維度而且又滿足 SLIs/SLOs 各項指標顯然是不可能實作的,各個維度不是完全獨立的,某個維度被拉伸相應的其他維度就要被壓縮,可以根據使用場景進行調整,以 Clusters 和 Nodes 兩個維度舉例,在 100 集群下將單集群的 5k 節點拉伸到 10k node 的場景或者在單集群規格不變的同時擴展集群數量到 200 集群,其他維度的規格勢必會受到影響,如果各種場景都進行測驗分析作業量是非常巨大的,在本次測驗中,我們會重點選取典型場景配置進行測驗分析,在滿足 SLIs/SLOs 的基礎上,實作單集群支持 5k 節點,20k pod規模的100數量的集群接入和管理,
SLIs/SLOs
可擴展性和性能是多集群聯邦的重要特性,作為多集群聯邦的用戶,我們期望在以上兩方面有服務質量的保證,在進行大規模性能測驗之前,我們需要定義測量指標,在參考了 Kubernetes 社區的 SLI(Service Level Indicator)/SLO(Service Level Objectives)和多集群的典型應用,Karmada 社區定義了以下 SLI/SLO 來衡量多集群聯邦的服務質量,
- API Call Latency

- Resource Distribution Latency

- Cluster Registration Latency

- Resource usage

Note:
- 上述指標不考慮控制面和成員集群的網路波動,同時,單集群內的 SLO 不會考慮在內,
- 資源使用量是一個對于多集群系統非常重要的指標,但是不同多集群系統提供的上層服務不同,所以對各個系統來順澩的要求也會不同,我們不對這個指標進行強制的限制,
- 集群注冊時延是從集群注冊到控制面到集群在聯邦側可用的時延,它在某種程度上取決于控制面如何收集成員集群的狀態,
測驗工具
ClusterLoader2
ClusterLoader2 是一款開源 Kubernetes 集群負載測驗工具,該工具能夠針對 Kubernetes 定義的 SLIs/SLOs 指標進行測驗,檢驗集群是否符合各項服務質量標準,此外 ClusterLoader2 為集群問題定位和集群性能優化提供可視化資料,ClusterLoader2 最侄訓輸出一份 Kubernetes 集群性能報告,展示一系列性能指標測驗結果,然而,在 Karmada 性能測驗的程序中,由于 ClusterLoader2 是一個為 Kubernetes 單集群定制的測驗工具,且在多集群場景下它不能獲取到所有集群的資源, 因此我們只用 ClusterLoader2 來分發被 Karmada 管理的資源,
Prometheus
Prometheus 是一個開源的用于監控和告警的工具, 它包含資料收集、資料報告、資料可視化等功能,在分析了 Clusterloader2 對各種監控指標的處理后,我們使用 Prometheus 根據具體的查詢陳述句對控制面的指標進行監控,
Kind
Kind 是一個是用容器來運行 Kubernetes 本地集群的工具,為了測驗 Karmada 的應用分發能力,我們需要一個真實的單集群控制面來管理被聯邦控制面分發的應用,Kind 能夠在節約資源的同時模擬一個真實的集群,
Fake-kubelet
Fake-kubelet 是一個能模擬節點且能維護虛擬節點上的 Pod 的工具,與 Kubemark 相比,fake-kubelet 只做維護節點和 Pod 的必要作業,它非常適合模擬大規模的節點和 Pod 來測驗控制面的在大規模環境下的性能,
測驗集群部署方案
Kubernetes 控制面部署在單 master 的節點上,etcd,kube-apiserver,kube-scheduler 和 kube-controller 以單實體的形式部署,Karmada 的控制面組件部署在這個 master 節點上,他們同樣以單實體的形式部署,所有的 Kubernetes 組件和 Karmada 組件運行在高性能的節點上,且我們不對他們限制資源,我們通過 kind 來模擬單 master 節點的集群,通過 fake-kubelet 來模擬集群中的作業節點,
測驗環境資訊
控制面作業系統版本
Ubuntu 18.04.6 LTS (Bionic Beaver)
Kubernetes 版本
Kubernetes v1.23.10
Karmada 版本
Karmada v1.3.0-4-g1f13ad97
Karmada 控制面所在的節點配置
- CPU
Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 64 On-line CPU(s) list: 0-63 Thread(s) per core: 2 Core(s) per socket: 16 Socket(s): 2 NUMA node(s): 2 Vendor ID: GenuineIntel CPU family: 6 Model: 85 Model name: Intel(R) Xeon(R) Gold 6266C CPU @ 3.00GHz Stepping: 7 CPU MHz: 3000.000 BogoMIPS: 6000.00 Hypervisor vendor: KVM Virtualization type: full L1d cache: 32K L1i cache: 32K L2 cache: 1024K L3 cache: 30976K NUMA node0 CPU(s): 0-31 NUMA node1 CPU(s): 32-63
- 記憶體
Maximum Capacity: 512 GB
- 磁盤
Disk /dev/vda: 200 GiB, 214748364800 bytes, 419430400 sectors
組件引數配置
- karmada-apiserver
--max-requests-inflight=2000 --max-mutating-requests-inflight=1000
- karmada-aggregated-server
--kube-api-qps=200 --kube-api-burst=400
- karmada-scheduler
--kube-api-qps=200 --kube-api-burst=400
- karmada-controller-manager
--kube-api-qps=200 --kube-api-burst=400
- karmada-agent
--kube-api-qps=40 --kube-api-burst=60
- karmada-etcd
--quota-backend-bytes=8G
測驗執行
在使用 Clusterloader2 進行性能測驗之前,我們需要自己通過組態檔定義性能測驗策略,我們使用的組態檔如下:
unfold me to see the yaml
name: test namespace: number: 10 tuningSets: - name: Uniformtinyqps qpsLoad: qps: 0.1 - name: Uniform1qps qpsLoad: qps: 1 steps: - name: Create deployment phases: - namespaceRange: min: 1 max: 10 replicasPerNamespace: 20 tuningSet: Uniformtinyqps objectBundle: - basename: test-deployment objectTemplatePath: "deployment.yaml" templateFillMap: Replicas: 1000 - namespaceRange: min: 1 max: 10 replicasPerNamespace: 1 tuningSet: Uniform1qps objectBundle: - basename: test-policy objectTemplatePath: "policy.yaml" # deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: {{.Name}} labels: group: test-deployment spec: replicas: {{.Replicas}} selector: matchLabels: app: fake-pod template: metadata: labels: app: fake-pod spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: type operator: In values: - fake-kubelet tolerations: - key: "fake-kubelet/provider" operator: "Exists" effect: "NoSchedule" containers: - image: fake-pod name: {{.Name}} # policy.yaml apiVersion: policy.karmada.io/v1alpha1 kind: PropagationPolicy metadata: name: test spec: resourceSelectors: - apiVersion: apps/v1 kind: Deployment placement: replicaScheduling: replicaDivisionPreference: Weighted replicaSchedulingType: Divided
Kubernetes 資源詳細的配置如下表所示:
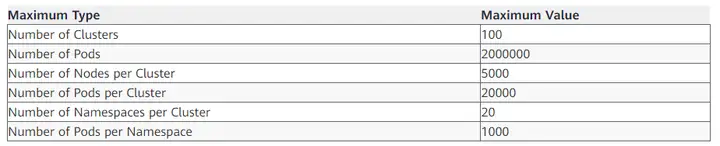
詳細的測驗方法和程序,可以參考
https://github.com/kubernetes/perf-tests/blob/master/clusterloader2/docs/GETTING_STARTED.md[1]
測驗結果
APIResponsivenessPrometheus:
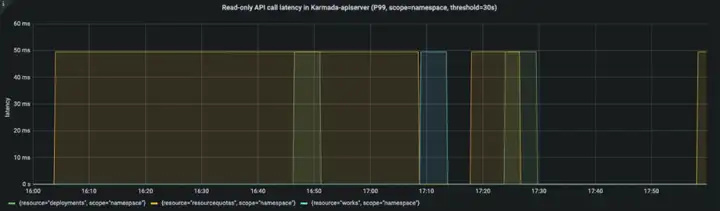
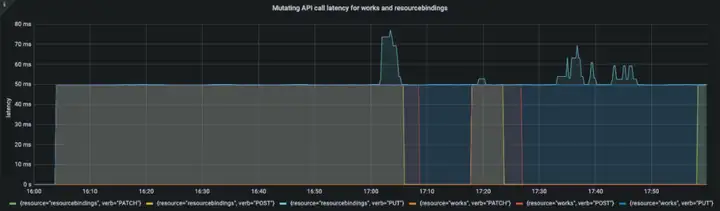

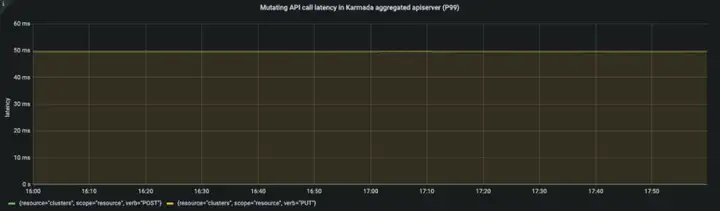
Cluster Registration Latency:

Note: Karmada 的 Pull 模式適合用于私有云的場景,與 Push 模式相比,成員集群會運行一個名為 karmada-agent 的組件,它會從控制面拉取用戶提交的應用,并運行在成員集群中,在 Pull 模式集群注冊的程序中,它會包含安裝 karmada-agent 的時間,如果 karmada-agent 的鏡像已經準備完畢的話,它很大程度上取決于單集群內 Pod 啟動的時延,這里不過多討論 Pull 模式的注冊時延,
Resource Distribution Latency:

Push Mode
Etcd latency:
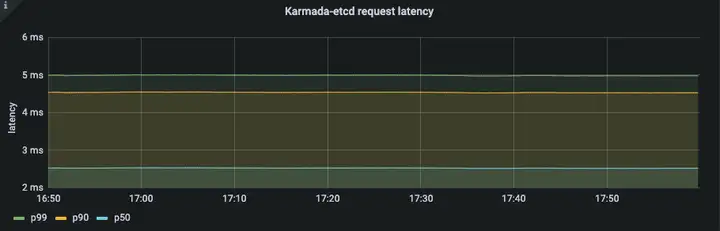
Resource Usage:



Pull Mode
Etcd latency:
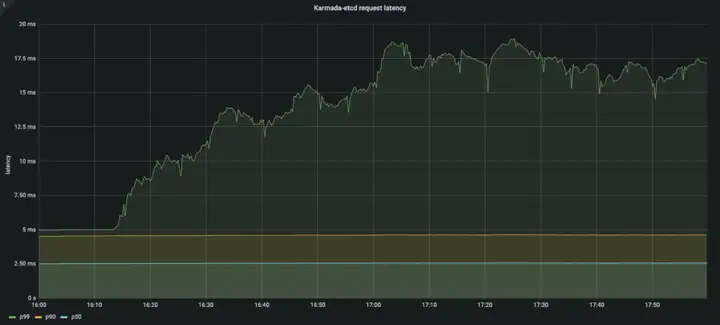
Resource Usage:



成員集群中的 karmada-agent 消耗了 40m CPU(cores)和 266Mi Memory(bytes),
結論與分析
在以上的測驗結果中,API呼叫時延和資源分發時延均符合上述定義的SLIs/SLOs,在整個程序中,系統消耗的資源在一個可控制的范圍,因此,Karmada能穩定支撐100個大規模集群,并且管理超過500,000個節點和2,000,000個的pods,在生產中,Karmada能有效支持數以百計的大規模的集群,接下來,我們會具體分析每個測驗指標的資料,
關注點分離:資源模板和策略
Karmada 使用 Kubernetes 原生 API 來表達集群聯邦資源模板,使用可復用的策略 API 來表達集群的調度策略,它不僅可以讓 Karmada 能夠輕松集成 Kubernetes 的生態, 同時也大大減少了控制面的資源數量,基于此,控制面的資源數量不取決于整個多集群系統集群的數量,而是取決于多集群應用的數量,
Karmada 的架構集成了 Kubernetes 架構的簡潔性和擴展性,Karmada-apiserver 作為控制面的入口與 Kubernetes 的 kube-apiserver 類似,你可以使用單集群配置中所需的引數優化這些組件,
在整個資源分發程序中,API 呼叫時延在一個合理的范圍,
集群注冊與資源分發
在 Karmada 1.3 版本中,我們提供了基于 Bootstrap tokens 注冊 Pull 模式集群的能力,這種方式不僅可以簡化集群注冊的流程,也增強了集群注冊的安全性,現在無論是 Pull 模式還是 Push 模式,我們都可以使用 karmadactl 工具來完成集群注冊,與 Push 模式相比,Pull 模式會在成員集群運行一個名為 karmada-agent 的組件,
集群注冊時延包含了控制面收集成員集群狀態所需的時間,在集群生命周期管理的程序中,Karmada 會收集成員集群的版本,支持的 API 串列以及集群是否健康的狀態資訊,此外,Karmada 會收集成員集群的資源使用量,并基于此對成員集群進行建模,這樣調度器可以更好地為應用選擇目標集群,在這種情況下,集群注冊時延與集群的規模息息相關,上述指標展示了加入一個 5,000 節點的集群直至它可用所需的時延,你可以通過關閉集群資源建模[2]來使集群注冊時延與集群的大小無關,在這種情況下,集群注冊時延這個指標將小于 2s,
不論是 Push 模式還是 Pull 模式,Karmada 都以一個很快的速度來下發資源到成員集群中,唯一的區別在于 karmada-controller-manager 負責所有 Push 模式集群的資源分發,而 karmada-agent 只負責它所在那一個 Pull 模式集群,因此, 在高并發條件下發資源的程序中,Pull 在相同配置條件下會比 Push 模式更快,你也可以通過調整 karmada-controller-manager 的--concurrent-work-syncs的引數來調整同一時間段內并發 work 的數量來提升性能,
Push 模式和 Pull 模式的資源使用量對比
在 Karmada 1.3 版本中,我們做了許多作業來減少 Karmada 管理大型集群的資源使用量,現在我們很高興宣布,相比于 1.2 版本,Karmada 1.3 在大規模場景下減少了 85% 的記憶體消耗和 32% 的 CPU 消耗,總的來說, Pull 模式在記憶體使用上有明顯的優勢,而在其他資源上相差的不大,
在 Push 模式中,控制面的資源消耗主要集中在 karmada-controller-manager,而 karmada-apiserver 的壓力不大,
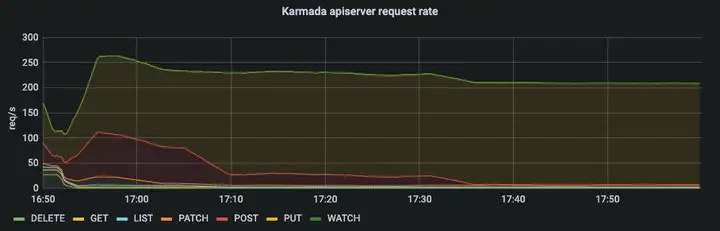
從 karmada-apiserver 的 qps 以及 karmada-etcd 的請求時延我們可以看出 karmada-apiserver 的請求量保持在一個較低的水平,在 Push 模式中,絕大多數的請求來自 karmada-controller-manager,你可以配置--kube-api-qps and --kube-api-burst這兩個引數來控制請求數在一個確定的范圍內,
在 Pull 模式中,控制面的資源消耗主要集中在 karmada-apiserver,而不是 karmada-controller-manager,
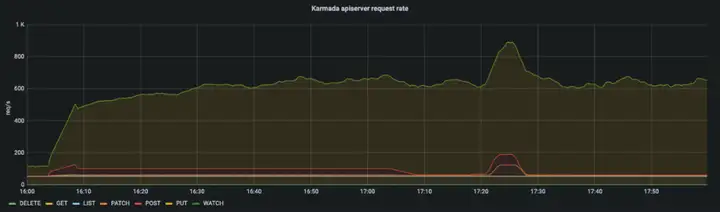
從 karmada-apiserver 的 qps 以及 karmada-etcd 的請求時延我們可以看出 karmada-apiserver 的請求量保持在一個較高的水平,在 Pull 模式中,每個成員集群的 karmada-agent 需要維持一個與 karmada-apiserver 通信的長連接,我們很容易得出:在下發應用至所有集群的程序中 karmada-apiserver 的請求總量是是 karmada-agent 中配置的 N 倍(N=#Num of clusters),因此,在大規模 Pull 模式集群的場景下,我們建議增加 karmada-apiserver 的--max-requests-inflight以及--max-mutating-requests-inflight引數的值,和 karmada-etcd 的--quota-backend-bytes引數的值來提升控制面的吞吐量,
現在 Karmada 提供了集群資源模型[3]的能力來基于集群空閑資源做調度決策,在資源建模的程序中,它會收集所有集群的節點與 Pod 的資訊,這在大規模場景下會有一定的記憶體消耗,如果你不使用這個能力,你可以關閉集群資源建模[4]來進一步減少資源消耗,
總結與展望
根據測驗結果分析,Karmada可以穩定支持100個大規模集群,管理超過50萬個節點和200萬個Pod,
在使用場景方面,Push模式適用于管理公有云上的Kubernetes集群,而Pull模式相對于Push模式涵蓋了私有云和邊緣相關的場景,在性能和安全性方面,Pull模式的整體性能要優于Push模式,每個集群由集群中的karmada-agent組件管理,且完全隔離,但是,Pull模式在提升性能的同時,也需要相應提升karmada-apiserver和karmada-etcd的性能,以應對大流量、高并發場景下的挑戰,具體方法請參考kubernetes對大規模集群的優化,一般來說,用戶可以根據使用場景選擇不同的部署模式,通過引數調優等手段來提升整個多集群系統的性能,
由于測驗環境和測驗工具的限制,本次測驗尚未測驗到Karmada多集群系統的上限,同時多集群系統的性能測驗仍處于方興未艾的階段,下一步我們將繼續優化多集群系統的測驗工具,系統性地整理測驗方法,以覆寫更大的規模和更多的場景,
參考資料
[1]https://github.com/kubernetes/perf-tests/blob/master/clusterloader2/docs/GETTING_STARTED.md: https://github.com/kubernetes/perf-tests/blob/master/clusterloader2/docs/GETTING_STARTED.md
[2]關閉集群資源建模: https://karmada.io/docs/next/userguide/scheduling/cluster-resources#disable-cluster-resource-modeling
[3]集群資源模型: https://karmada.io/docs/next/userguide/scheduling/cluster-resources
[4]關閉集群資源建模: https://karmada.io/docs/next/userguide/scheduling/cluster-resources#disable-cluster-resource-modeling
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/531490.html
標籤:其他