一、Kubernetes的整體架構
學習k8s,最終目的是為了部署應用,部署一個完整的k8s, 就要知道k8s的組成,k8s主要包含兩大部分: 中間包含三個綠色包的是master服務器. 下面是node節點.
在這里提前說一下etcd,etcd是k8s集群的一個資料庫存盤服務器,它采用了RAFT演算法來選舉主節點, 所以, 要求我們的master節點個數必須是3,5, 7, 9這樣的奇數,也就是大于1的奇數個,3個節點可以保證1次高可用, 5個節點可以保證兩次高可用,7個節點可以保證3次高可用, 以此類推,也就是3個節點最多可以死一次,5個節點最多可以死2次,node節點的個數不限制,
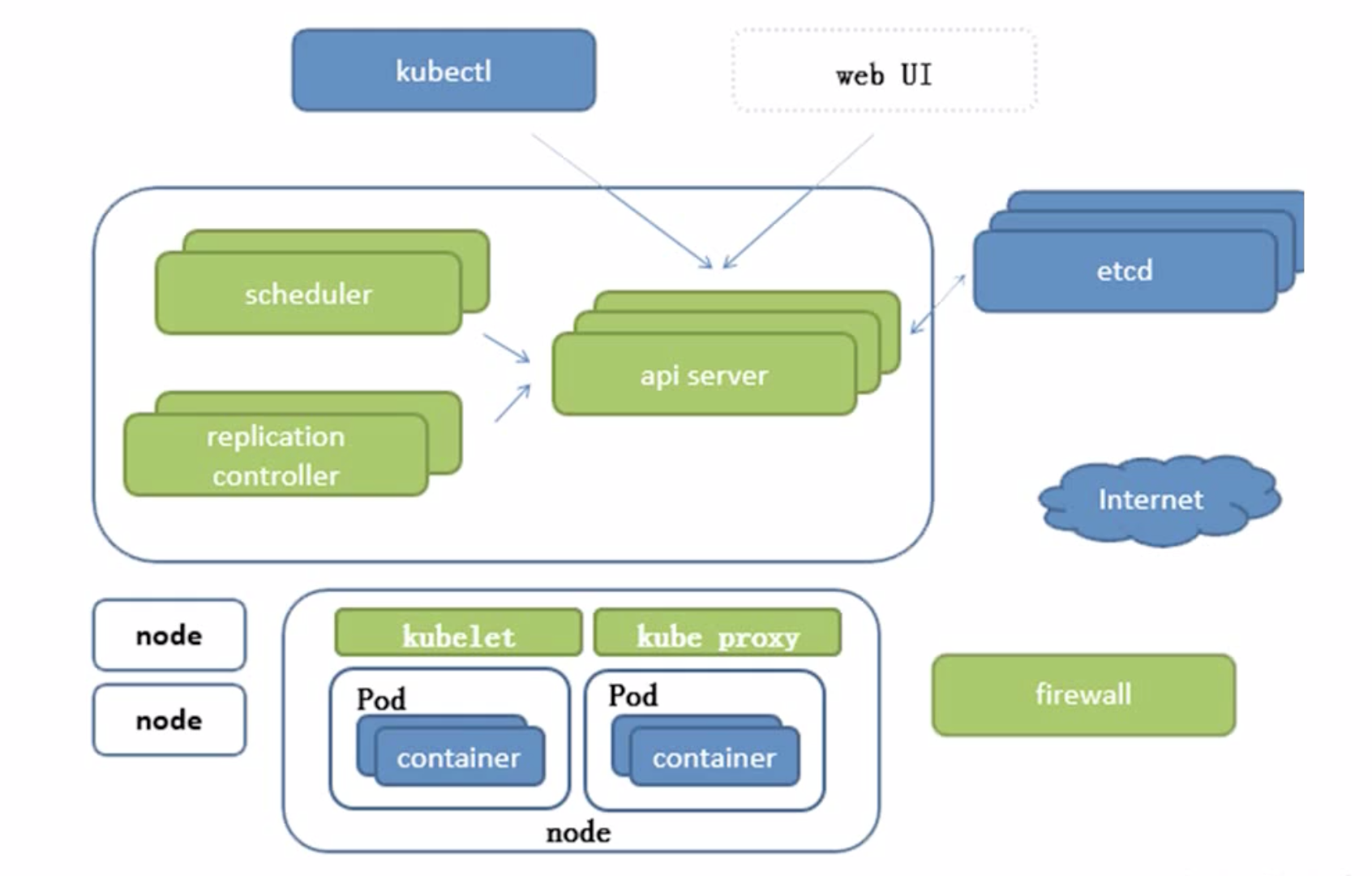
上圖是k8s的簡單架構圖,可以看到有如下幾個部分:
- master節點:左上角的最大快區域,是我們整個k8s的核心,上面說的大于1的奇數個節點,說的就是這里,
- node節點:
- etcd存盤端:用來存盤k8s中的資料的,主要采用Raft演算法,
- internet網路層:
- firewall防火墻:
- web UI:
- kubectl:
二、Master節點
master節點在整個服務中起著至關重要的作用
master中主要有三個部分的內容:scheduler,控制器,api server,
1、Api Server
api server是所有服務請求訪問統一的入口(所有請求的統一的入口),如果想要給k8s下達命令,不管是什么型別的命令,都需要發送給api servier,
Api Server 本身是一個HTTP Server,也就是一個web服務器,它是無狀態的,它的所有資料都會寫入到Etcd, 如果你想要管Api Server要資料,它本身是沒有的,他會去Etcd里面查詢,然后回傳給你,
從上圖可以看出. Master中scheduler需要和api server互動, rc要和api server互動, kubectl(客戶端)也要和api sever互動, web UI也要和api server互動, etcd也要和api server互動. apiserver是非常繁忙的.
api server采用的是無狀態http請求,所以,他不會記錄任何資料,所有資料都存盤在etcd上,
Kubernetes API 服務器的主要實作是 kube-apiserver, kube-apiserver 設計上考慮了水平伸縮,也就是說,我們可以通過部署多個實體進行伸縮, 你可以運行 kube-apiserver 的多個實體,并在這些實體之間平衡流量,
2、Scheduler 任務調度器
scheduler是k8s本身的一個調度器,這個調度器可以存在多個組成高可用,
scheduler是任務調度器, 負責調度任務, 選擇合適的節點來執行任務. 當用戶下達資源請求的時候,任務調度器會把任務分配給后端的多個node節點上,要基于一定的原則,公平的,快速的分發,也就是說,保證每個節點都有事做,不要浪費資源,做到資源利用最大化,所以,scheduler調度區非常關鍵,他是保證整個集群資源利用高不高的核心組件,
舉個例子,一個任務來了, 要部署一個應用,到底應該部署在哪個節點上呢? 這個程序就是通過scheduler進行任務調度的,有的機器繁忙,有的機器空閑,scheduler會找一臺空閑的機器進行部署,通過scheduler進行任務調度分發至不同的node.
scheduler會將任務交給api server, 由api server將任務寫入到etcd, 也就是說scheduler不會直接和etcd互動,
3、controller-manager 控制器管理器
controller-manager: 控制器, 處理集群中常規后臺任務,一個資源對應一個控制器,假如集群中有的pod已經死了,控制管理器就會處理將其洗掉或者救活,集群中的擴容,維穩都是有控制管理器來實作的,相當于是集群的管家,
舉例來說,有一個訂單服務,我們要部署這個服務,首先是交給任務調度器,任務調度器呼叫api server,將資訊保存到etcd,etcd會創建一個controller-manager來專門管理這個訂單服務,通常來說,一個資源對應一個控制器,
4、kubectl
命令列管理工具,這個工具我們可以安裝在任何節點上,通常,我們將其安裝在master節點上, 可以安裝在安卓手機上,蘋果手機上,windows電腦上,只要能夠通過網路連接到api server,就能下發請求,
5、Web UI
Web UI是一套可操作的界面,Dashboard是 Kubernetes 集群的通用的、基于 Web 的用戶界面, 它使用戶可以管理集群中運行的應用程式以及集群本身并進行故障排除,
這個儀表盤不是給開發者使用的,開發者通常還是使用命令列,命令列是最全的,
三、etcd資料存盤
? 先來說說etcd資料庫的背景,我們熟悉的docker是docker公司開發的,其實在docker公司吧docker做大之前,還有一個公司也在默默的付出,就是Core OS公司,知道這家公司的人不多,但這個公司的技術背景是非常強悍的,docker公司和Core OS公司關系非常好,可以說技術是半共享狀態,docker里面很多技術也是core OS公司貢獻的,但是最終的結果是docker公司走紅,一飛升天了,但是core OS公司沒有幾個人知道,但是core OS公司也獲得了強大的技術背景的實體,core OS公司也想崛起,還開發了一款容器,但很顯然,沒法和docker比,于是core OS公司ua拿了一個策略,加入到了k8s的生態構建,core OS為k8s構建了很多組件,etcd就是core OS公司開發并且維護的,采用golang語言撰寫, etcd是k8s的總存盤,由core OS公司負責,由此可見技術能力是很強的,
etcd是鍵值對資料庫, 存盤K8s集群的所有重要資訊(持久化). 在Kubernetes集群中起到的了持久化的作用.
1.etcd概念
etcd官方將其定位為一個可信賴的分布式****鍵值存盤服務, 它能夠為整個分布式集群存盤一些關鍵資料, 協助分布式集群的正常運轉.
可信賴的:官方已經提供了一個高可用方案,也就是說本省自帶高可用
分布式:將資料分散到不同節點,以此來保證資料的強壯性
鍵值存盤:就是簡單的K-V對,etcd所有的資料型別只有一種存盤結構,就是k-v結構,
2. Raft演算法
- Raft是etcd采用的演算法,叫做共識演算法,或最終一致演算法,
? 舉個例子,什么是共識演算法, 比如有一個村子,村子里有幾百個村民, 然后有一個人考上了***大學,可厲害,旁邊的鄰居知道了,然后就開始一傳十,十傳百, 最后整個村子的人都知道了, 這就是共識演算法
? 那最終一致是怎么回事呢?整個村子的人可能有的人先知道這個事,有的人晚點知道,但最終大家都知道,程序不一定一致,但結果是一致的,
? 剛剛說了Raft的節點為什么是3,5,7,9個呢,因為要投票選舉,如果資料在某個節點,比如我的資料值是2017,另外兩個事2018,已投票我就輸了,那就是以你倆的資料為準,你倆成為leader了,來管理我,你們來提供服務,我要聽你們的話,你們把資料給我,
-
每一個Raft集群中都包含多個服務器,在任意時刻,每一臺服務器只能處于Leader、Follower以及Candidate三種狀態;在處于正常的狀態時,集群中只會存在一個Leader,其余都是Follower,
- Leader:領導者
- Follower:跟隨者
- Candidate:競選者
注意:一個能被外部正常訪問的集群只有Leader和Follower兩種狀態,并且通常只有一個leader,其余都是follower
讀寫的資訊, 所有的讀寫資訊都被存在Raft里面, 而且, 為了防止這些資訊出現損壞, 他還有一個WAL預寫日志
2. Raft演算法
-
etcd的版本
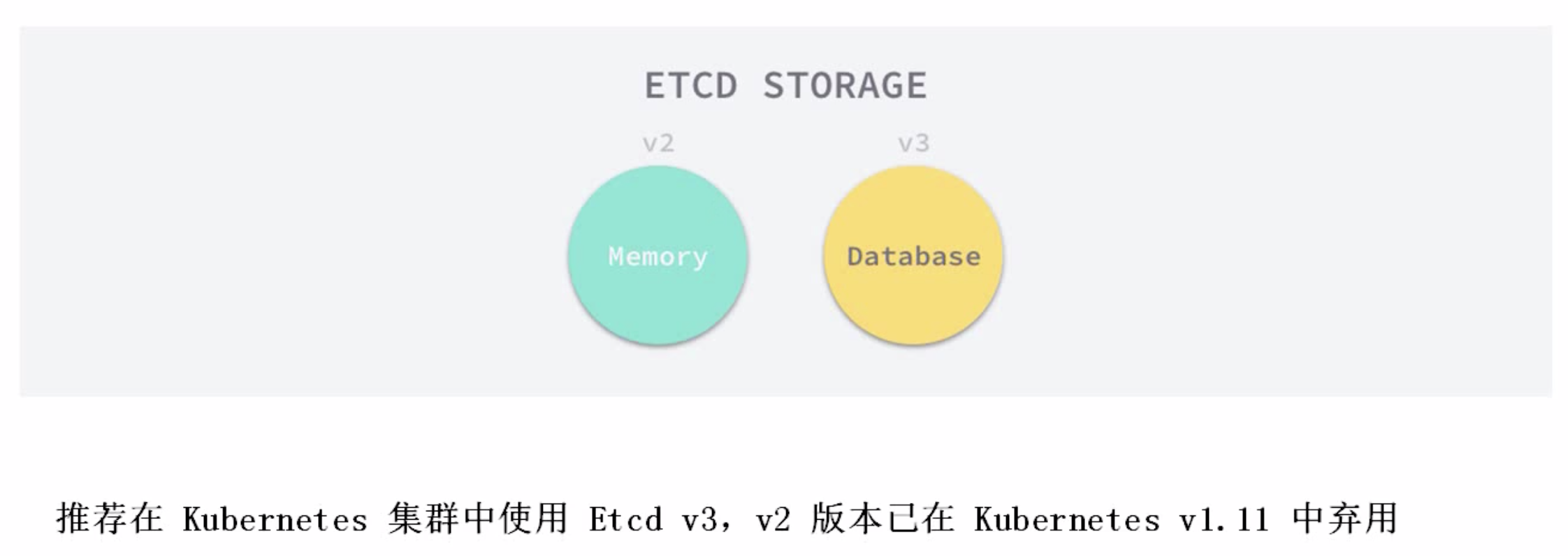
etcd現在有兩個版本, v2和v3版本,
-
V2:v2版本將資料保存到記憶體, 這樣很可能會不穩定,一宕機,資料全沒了,
-
V3: v3版本將資料保 存到磁盤. 然后進行快取加速,并且,如果使用了V3版本,官方建議采用SSD進行存盤和讀取
-
如何選擇版本呢?不用我們自己選擇,k8s已經集成了etcd,正常我們都選擇使用v3版本, 但Kubernetes v1.11版本之前使用的是v2版本.
3、Raft內部結構
Raft內部結構如下圖,主要包含幾個方面:Http Server, Raft,Wal,Store,下面來詳細介紹
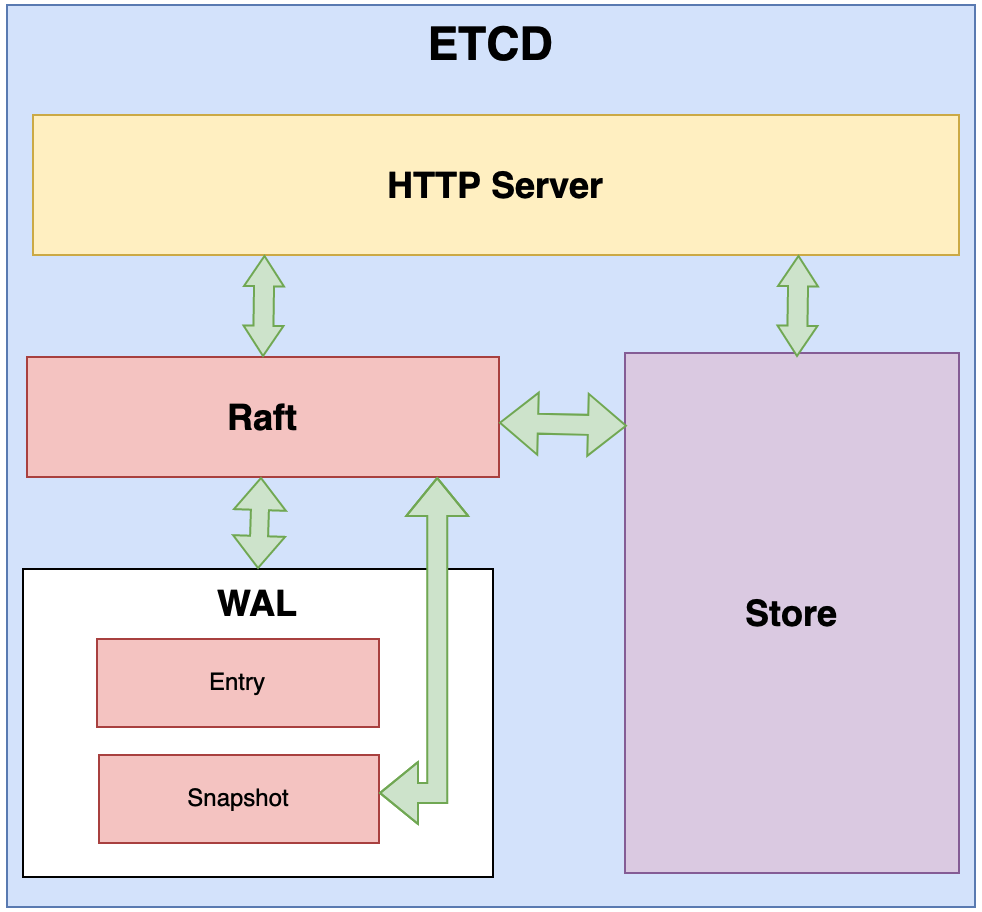
1> HTTP Server
這里采用的是使用http進行構建的c/s服務, k8s也是采用的http協議進行c/s服務的開發. 為什么要這么做呢? 因為http天生支持一系列的操作. 例如: get ,post, put, delete, 授權認證等. 所以, 沒有必要再去采用標準的tcp協議. 開發一系列的認證流程, 所以, 直接采用http協議即可. http協議主要解決的是資料傳輸問題,
2> Raft
共識演算法,上面說過了,這里不再贅述
3> WAL 預寫日志
什么叫預寫日志呢?在寫入修改底層資料之前,把所有的操作先保存在日志里,
-
Raft:共識演算法,從一開始就被設計成一個易于理解和實作的共識演算法,每一個Raft集群中都包含多個服務器,在任意時刻,每一臺服務器只能處于Leader、Follower以及Candidate三種狀態;在處于正常的狀態時,集群中只會存在一個Leader,其余都是Follower,
共識演算法,或者叫最終一致演算法,比如:有3臺etcd機器在運行的程序中,突然停了,那么3臺etcd中的配置可能是不一樣的,但是,一旦運行起來,經過一段時間,最侄訓達到一致,每一個Raft集群都包含多個服務器,在任意時刻,每一臺服務器只可能處于Leader(主節點)、Follower(跟隨者)、Candidater(競選者)三種狀態中的一種,在處于正常狀態(可訪問)時,集群中只會存在一個Leader,其余的服務器都是Follower,
-
WAL: 預寫日志, 吸入到資料庫之前,先保存到日志里,如果要對資料進行更改, 那么先寫入一條日志, 然后定時的對日志進行完整的備份. 也就是完整+臨時. 比如: 我先備份一個大版本, 備份以后, 還會有1個子版本, 兩個子版本....., 然后將這些版本再次進行一個完整備份,把它變成一個大版本. 這樣做的好處, 我們不能始終進行完整備份, 因為消耗的資料量太大. 為什么還要在一定時間內進行完整的備份呢?防止增量備份太多, 還原的時候太費事. 并且, Raft還會實時的把這些資料和日志存入到本地磁盤進行持久化.
-
Store: 把WAL中的日志和資料, 寫入磁盤進行持久化.
四、Node節點
從圖中可以看出, Node節點包含三個組件 ,kubelet, kube proxy, 以及container. 也就是說我們在node節點需要安裝三個軟體: kebelet, kebu proxy, docker
1)kubelet的作用
master端收到多個任務,調度器會把任務發送給node節點,在node節點上,任務都是以容器化的方式運行的,容器是被誰初始化的?容器的運行時,比如docker,docker會幫我們啟動容器,一邊是kuberates 的Api Server, 另一邊是docker,他倆能夠對話么?不能,舉個例子: 一個是外國人,只會說英語,一個是中國人,只會說漢語,那如何讓外國人和中國人交流呢?翻譯唄,kubelet的作用就是連接k8s和docker的,kubelet監聽api server,api server下發命令以后,kubelet要去呼叫docker,去執行指令,比如容器的創建,
kubelet的直接跟容器互動, 實作容器的生命周期管理.他會和CRI, C是容器, R是runtime, I是interface. CRI就是docker的操作形式. kubelet會和docker互動, 創建需要的容器. kubelet會維持Pod的生命周期.
也就是說,kubelet起到承上啟下的作用,
2)kube proxy的作用:
下面呼叫linux的內核介面,叫做net link介面,當監聽到api server發送的請求以后
kube proxy 上面監聽api server,api server發出請求以后,會呼叫linux的內核介面,叫做net link介面,這個介面允許我們通過命令的方式,庫呼叫的方式去實作IPVS的創建,實作netfire的管控,就是IPVS和防火墻的管控,負載均衡和資料的轉發都是基于kube proxy組件實作的,
負責寫入規則至IPTABLES, IPVS實作服務映射訪問. 之前說過svc, 可以進行負載操作, 負責的操作就是通過kube proxy完成的. 怎么實作Pod與Pod之間的訪問, 以及負載均衡. 默認操作是操作防火墻, 去實作Pod的映射. 新版本還支持IPVS.
由此可見,kubelet和kube proxy這兩個功能各有各的用途,
3、其他重要的插件
1)Web UI
Web UI是一套可操作的界面,Dashboard是 Kubernetes 集群的通用的、基于 Web 的用戶界面, 它使用戶可以管理集群中運行的應用程式以及集群本身并進行故障排除,
2) COREDNS
可以為集群中的SVC創建一個域名IP對應的關系決議. 也就是說,我們在集群中訪問其他Pod的時候, 完全不需要通過Pod的ip地址, 通過CoreDns給他生成的域名去實作訪問. 他是集群中的重要重要組件, 也是實作負載均衡的其中一項功能.
3)DASHBOARD
給K8S集群提供一個 B/S結構訪問體系.
4)Ingress Controller
官方只為我們實作了四層代理. Ingress可以實作七層代理, 也就是可以根據組件名和域名進行負載均衡.
5)Federation
提供一個可以跨集群中心多K8s統一集群管理功能.
6)Prometheus(普羅米修斯)
提供K8S集群的監控能力.
7)ELK
提供k8s集群日志統一接入平臺
二、K8S和docker的關系
為什么會說k8s和docker的關系呢?這還要源于k8s發布的一則訊息,在后續版本將不再增加墊片這個組件,導致很多人覺得docker不行了,很可能會被k8s遺棄,為什么這個墊片會有這么大的影響呢?這就要從CRI和O-CRI說起了,
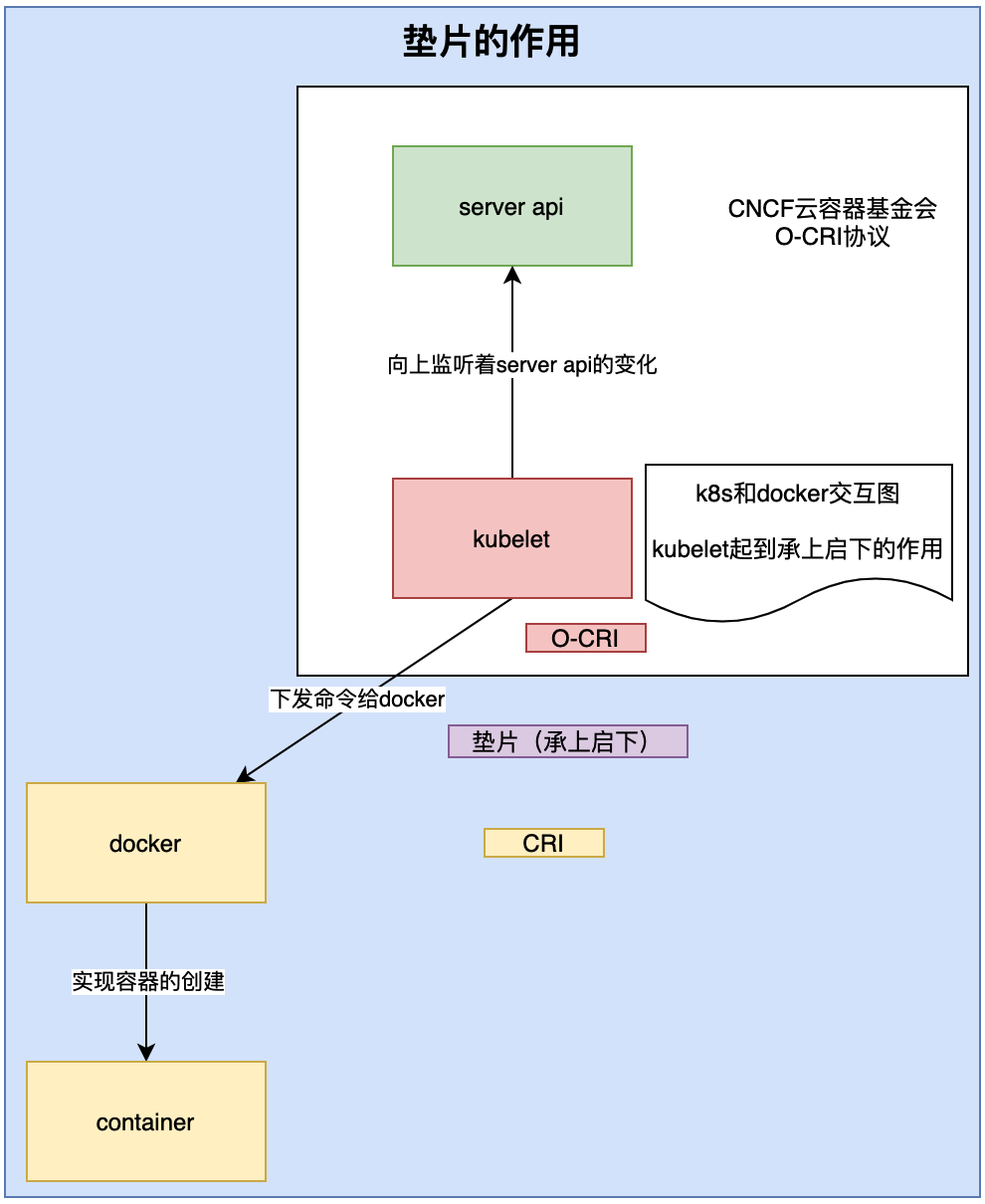
先來看看容器是如何創建的?
kubelet監聽了server api,有任何的變化都會下發命令給docker,然后docker操作容器,那么,kubelet呼叫docker的時候,是使用命令還是呼叫介面呢?
肯定是直接呼叫介面,因為呼叫命令最終也是去執行介面,中間還轉一步,效率太低了,
但是,kubelet能直接呼叫docker介面么?
我們知道docker采用的是CRI容器運行時介面,
而k8s是google的產品,現在是CNCF云容器基金會的產品,這是一個開源鏡像,k8s會直接對接到CRI這樣一個私有協議么?我是公共使用的,所以肯定不會對接到私有協議介面,那么,我會對接到O-CRI介面,這時一個共有協議介面,問題來了,docker是CRI私有協議介面,k8s是O-CRI共有協議介面,對接不過去啊,所以,怎么辦?再加一層轉換,這層轉換的作用是承上啟下,上面承的是O-CRI,下面承的是CRI,這個轉換是在kubectl實作的,這一層被叫做墊片,承上啟下用的,
最開始,Docker的名氣要比k8s大的多得多,所以,k8s就承接了墊片的任務,而如今,k8s的名氣已經很大了,它不再需要依賴于docker,于是他要去掉墊片,并且發了公告,
那么docker是不是就完蛋了,k8s沒有墊片做轉換了,就不能呼叫docker介面了,docker也很機智,隨即發布訊息,他會增加墊片功能,這樣k8s依然可以呼叫docker容器,但是,我們要知道,docker就重了,k8s減負了,k8s可以兼容任何容器,現在市面上有好幾款容器,他不是飛docker不可的了,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/531493.html
標籤:其他