前言
想象一下這個場景:多個系統運行在同一套 K8s 集群上,有重要系統,也有不太重要的系統,但是某一天,某個不重要的系統突然占用了該 K8s 集群的所有資源,導致該集群上的其他系統的正常運行受到影響,本文介紹了 Kubernetes 平臺如何管理容量,以及作者對管理員的注意事項和建議,
Kubernetes 資源限制概述
我們壽險了解 Kubernetes 平臺如何在容器和節點級別應用資源約束, 為了討論合理規模,我們將專門關注 CPU 和記憶體,盡管還有其他因素需要考慮,
可以為每個容器和 Pod 指定 resource requests 和 limits, Requests 是為 pod 預留的有保證的資源,而 limits 則是旨在保護集群整體架構的安全措施, 在 Kubernetes 中,pod 的 requests 和 limits 之間的關系被配置為服務質量(QoS), 在節點上,kubelet(可以監控資源的代理)將此資訊傳遞給容器運行時,容器運行時使用內核 cgroups 來應用資源約束,
要調度新的 pod,Kubernetes 調度程式將確定可用節點上的有效位置,并考慮現有 pod 資源限制, Kubernetes 會預配置一些系統預留,以留出資源供作業系統和 Kubernetes 系統組件使用(具體如下圖), 剩余量被定義為可分配的,調度程式將其視為節點的容量, 調度器可以基于所有單元的合計資源請求來調度單元到節點的容量, 請注意,所有單元的聚合資源限制可以大于節點容量,這種做法稱為超額使用(超配 or 超賣),
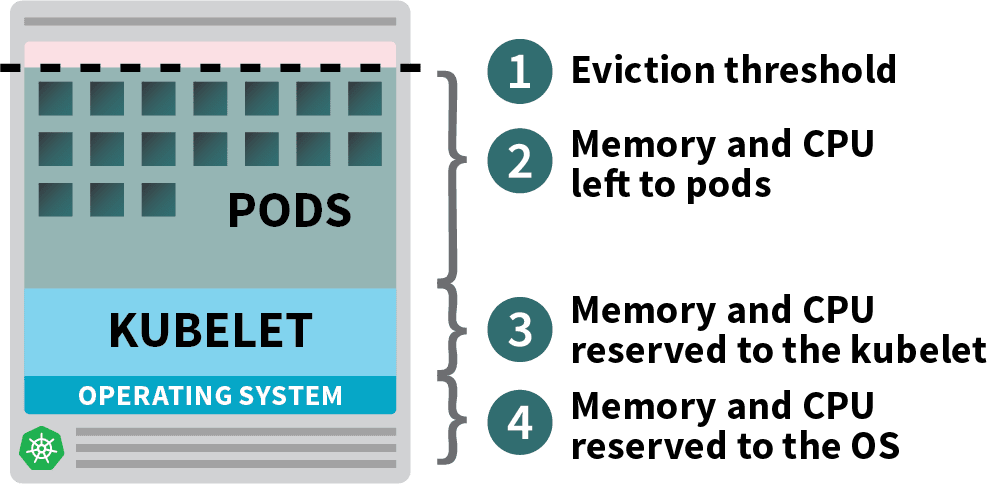
在管理節點容量時,我們要盡量避免兩種情況, 在第一種情況下,實際記憶體利用率達到容量,并且 kubelet 基于驅逐信號觸發節點壓力驅逐, 如果節點在 kubelet 可以回收記憶體之前用完記憶體,則節點 oom-killer 將做出回應,根據從每個 pod 的 QoS 計算的 oom_score_adj 值選擇要洗掉的 pod, 因此,構成這些 pod 的應用程式會受到影響,
在 CPU 上過量使用的底層機制與記憶體的行為不同,因為它將 CPU 時間分配給各個容器, 高 CPU 利用率會導致 CPU 節流 (CPU throttling),但不會觸發節點壓力驅逐,也不會自動導致 Kubernetes 終止 Pod, 但是也請注意,CPU 耗盡仍可能導致應用程式 pod 降級、活動探測失敗并重新啟動,
我們還希望避免另一種情況, 在節點級別,requests 是有保證的資源,并且必須小于容量,因為 Kubernetes 調度程式不會超額預訂, 如果 requests 明顯且始終大于實際使用的資源,則多余的容量基本上未被使用, 雖然可能需要為高峰處理時間保留資源,但管理員應在這一點與運行可能不需要的過剩容量的重復成本之間進行平衡, 根據實際使用情況配置請求是一種平衡行為,應考慮應用程式的風險管理(平衡可用性和成本).
Kubernetes 管理員能做啥
Kubernetes 管理員的一個主要關注點是管理和合理調整集群容量,我們可以在 Web 上利用 Prometheus + Grafana 儀表盤和命令列捕獲集群利用率指標,供管理員使用,
但是 Kubernetes 管理員還面臨一個棘手的大問題:正在運行的應用程式(的資源管理), 解決特定問題的應用程式可以由不同的開發人員以不同的方式撰寫,從而導致不同的性能(比如 java 撰寫的可能消耗記憶體較多,golang 消耗記憶體相對較少), 每個應用程式都是獨特的,沒有一種適合所有應用程式的方法, 管理員對開發人員的應用程式的控制能力較弱,在大型企業中,單個管理團隊可能很難接觸到眾多的開發團隊, 因此,管理員的重點應該是設定護欄,以允許開發人員(在護欄內)調整自己的應用程式,
配置 LimitRange
繞了這么久,終于進入正題了,
為此,管理員可以為每個 NameSpace 配置不同的 LimitRanges,為開發人員提供針對各個容器和 pod 的建議大小限制, 以下是 LimitRange 的示例, 由于每個集群和應用程式都有不同的業務和風險要求,因此各位讀者實際應用時數字會有所不同,
apiVersion: v1
kind: LimitRange
metadata:
name: "resource-limits"
spec:
limits:
- max:
cpu: "2"
memory: 4Gi
min:
cpu: 125m
memory: 128Mi
type: Pod
- default:
cpu: "0.5"
memory: 1Gi
defaultRequest:
cpu: 250m
memory: 256Mi
max:
cpu: "2"
memory: 4Gi
maxLimitRequestRatio:
cpu: "25"
memory: "4"
min:
cpu: 125m
memory: 128Mi
type: Container
在 Kubernetes 中進行開發的良好實踐是創建微服務應用程式,而不是大型的巨石應用程式, 為了鼓勵微服務的開發,應該應用 limits 來約束 pod 的最大大小, 節點的物理容量可能會決定此最大大小,因為它應該可以輕松地容納幾個最大的 pod, 還是類似這個圖:
讓我們繼續上面的 LimitRange 示例, 最小 pod 和容器大小可能由正在運行的應用程式的需求確定,管理員不必強制執行, 為了簡單起見,我們還鼓勵開發人員在每個 pod 上運行一個容器(一個典型的例外是使用 sidecar 容器,如 Istio 的 sidecar), 因此,上面的示例對 pod 和 container 使用相同的資源值,
默認 requests 和 limits 作為開發人員的建議值, 未顯式宣告容器大小的作業負載資源(即 pod)將繼承默認值, 作為一種好的做法,開發人員應明確定義作業負載資源中的資源請求和限制,而不采用默認值,
CPU 和記憶體的 maxLimitRequestRatio 是開發人員的突發準則, 在開發環境中,當原型應用程式經常空閑運行,但在使用時需要合理的按需資源時,高 CPU maxLimitRequestRatio 會很好地作業, 開發人員可能只在作業時間作業,在自己的 IDE 中離線編碼,偶爾測驗單個微服務,或者測驗 CI/CD 管道的不同階段, 相比之下,如果許多最終用戶在一天中同時訪問應用程式,您將看到更高的基準利用率, 這可能更接近您的生產環境,并可能降低 maxLimitRequestRatio(可能是事件 1:1 的請求限制), 由于管道各階段的不同利用率模式將導致不同的請求和限制,因此在生產之前使用模擬作業負載進行測驗以確定適當的單元大小非常重要,
開發人員將使用 maxLimitRequestRatio 作為適當調整大小的準則, Kubernetes 調度程式基于資源請求做出調度決策,因此開發人員應配置資源 requests 以反映實際使用情況, 然后,基于應用程式的風險狀況,開發人員將配置 limits 以遵守 maxLimitRequestRatio, 將 maxLimitRequestRatio 設定為 1 的管理員強制開發人員將 requests 配置為等于限制,這在生產中可能是理想的,以降低風險并優先考慮穩定性,
在本文前面,我們比較了記憶體和 CPU,并描述了這兩種資源在負載下的不同行為,高記憶體可能導致 pod 逐出或從記憶體不足的情況重新啟動, 因此,最好是謹慎行事,并為不同環境的記憶體配置較低的 maxLimitRequestRatio,以防止應用程式 pod 重新啟動, 為 OpenJDK pod 配置記憶體時還應注意其他事項, (如果沒配置相應動態調整的引數), 容器和 pod 內部的 JVM heap 對容器的請求和限制一無所知,但應用于前者的資源約束將影響后者,
配置 ResourceQuota
管理員還可以配置 ResourceQuotas,它為 NameSpace 提供基于容量的限制,以指導開發人員根據預測的估計值來調整應用程式的規模, 下面是一個 ResourceQuota 示例,
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
limits.memory: 20Gi
requests.cpu: "4"
requests.memory: 20Gi
在應用程式 NameSpace 的初始創建程序中,開發團隊應與管理員一起預測其應用程式大小并應用適當的配額, 管理員應根據服務、副本的數量和 pod 的估計大小來預測應用程式大小, 為了簡化對眾多 NameSpace 的管理,管理員可考慮類似 AWS 的方法作為起始準則,其中 small、medium、large、xlarge 應用程式被給予對應的預定配額,
應用程式跨 CI/CD 管道的各個階段進行運行,每個階段都位于不同的集群或 NameSpace 中,并具有自己的配置配額, 在不考慮性能和高可用性的開發和測驗 NameSpace 中,應用程式應配置最小的 pod,并為每個服務配置 1 個 pod 副本,以減少資源使用, 另一方面,在生產集群或 NameSpace 中,應使用更大的 pod 和每個服務至少 2 個單元副本,以處理更高的業務量并提供高可用性, 通過使用 CI/CD 管道中的模擬作業負載進行壓力和性能測驗,開發人員可以在生產發布之前確定適當的生產 pod 大小、副本數量和配額,
管理員應針對未來的擴展制定配額預算,并考慮應用程式的使用模式、峰值容量和已配置的 pod 或節點的 autoscaler(如果有), 例如,可在快速添加新微服務的開發 NameSpace、用于確定適當生產 pod 大小的性能測驗 NameSpace、或使用 HPA 來調整峰值容量的生產 NameSpace 中分配附加配額, 管理員應針對上述各種情況和其他情況提供足夠的配額開銷,同時平衡基礎架構容量的風險并保護架構容量,
管理員和開發人員都應該預期會隨著時間的推移調整配額, 開發人員無需管理員的幫助即可識訓配額,方法是查看每項服務并減少 Pod requests 或 limits 以匹配實際使用量, 如果開發人員已經采取了這些步驟,但仍然需要額外的配額,那么他們應該聯系管理員, 管理員應將開發人員的定期配額請求作為一個機會,根據以前預測的估計值分析實際消耗量,并相應地確認或調整配額大小和新的預測估計值,
另外再介紹在調整配額大小時的一些次要注意事項, 在確定 CPU 和記憶體的配額比率時,應考慮節點容量,以便有效地利用兩者, 例如,m5.2xlarge 型別的 AWS EC2 實體為 8 個 vCPU、32 GiB RAM, 由 m5.2xlarge 節點組成的集群可以按照每 4 GB RAM 對應 1 個 vCPU 的比例分配應用配額(不考慮節點的系統保留空間),從而高效地使用 CPU 和記憶體, 如果應用程式作業負載(即 CPU 或記憶體密集型)與節點大小不匹配,則可以考慮使用不同的節點大小,
管理員對何時應用和不應用配額的 CPU limits 一直存在爭議,這里我們將提供一些考慮事項,而不是正式的指導, 正如我們前面所討論的,pod 的 CPU 不足會導致節流,但不一定會導致 pod 終止, 如果管理員傾向于過量使用并利用節點上的所有可用 CPU,則不應設定配額的 CPU limits, 相反,應設定配額 (resource quota) 的 CPU limits,以減少過度使用和應用程式性能風險,這可能是一個業務和成本決策,而不是技術決策, 與生產環境相比,開發環境可以容忍更高的風險和不可預測的性能,因此管理員可以考慮將 CPU limits 應用于生產而不是開發,
最后,在某些特殊情況下,不建議應用配額, 應用配額的目的是讓管理員能夠對自定義開發的應用程式的容量規劃進行一定程度的控制, 配額不應應用于 Kubernetes 自身的組件,因為這些專案需要預先配置的資源量, 出于類似的原因,配額也不應適用于第三方供應商提供的企業版應用程式,
總結
在本文中,我們介紹了 Kubernetes 平臺如何通過資源約束保護架構,包括:
- Pod 的 requests 和 limits
- Node 的資源分配
- NameSpace 級別的針對 Pod 和容器的 LimitRange
- NameSpace 級別的 ResourceQuota
并提供了在應用程式 NameSpace 中應用 limits 和 quota 的保護措施時的合理調整注意事項, 每個應用的風險偏好和 Kubernetes 集群的容量各不相同,需要綜合考量再實施,
參考檔案
- Kubernetes instance calculator (learnk8s.io)
- 限制范圍 | Kubernetes
- 資源配額 | Kubernetes
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/531928.html
標籤:其他
上一篇:寶塔面板發布vue頁面