作者|Dorian Lazar
編譯|VK
來源|Towards Data Science
感知器是人工神經網路的組成部分,它是大腦中生物神經元的簡化模型,感知器是最簡單的神經網路,僅由一個神經元組成,感知器演算法由Frank Rosenblatt于1958年發明,
以下是生物神經元的圖示:
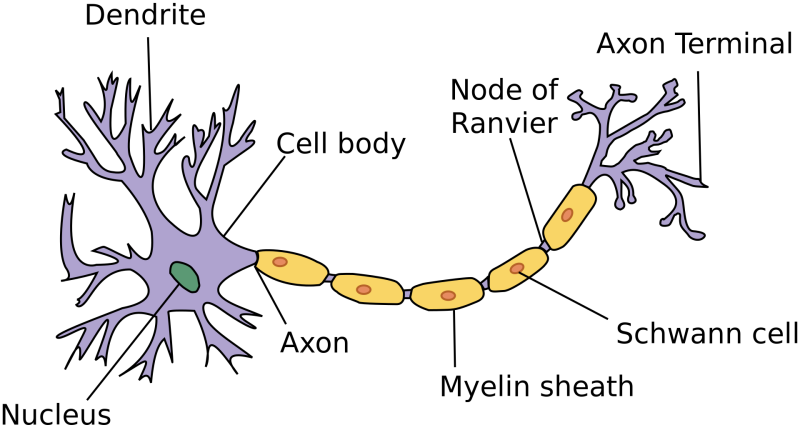
經由樹突接收到神經元的大部分輸入信號,其他神經元與這些樹突形成約1,000至10,000個連接,來自連接的信號稱為突觸,通過樹突傳播到細胞體內,細胞體內的電位增加,一旦達到閾值,神經元就會沿著軸突發出一個尖峰,該軸突通過軸突末端連接到大約100個其他神經元,
感知器是真實神經元的簡化模型,它嘗試通過以下程序來模仿它:接收輸入信號,將它們稱為x1,x2,…,xn,計算這些輸入的加權和z,然后將其傳遞閾值函式?并輸出結果,
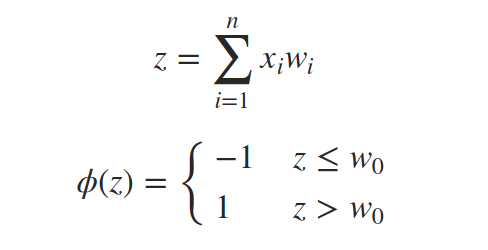
但將w0作為閾值和將w0作為偏置添加到和中并將閾值改為0是一樣的,我們考慮一個始終設定為1的附加輸入信號x0,
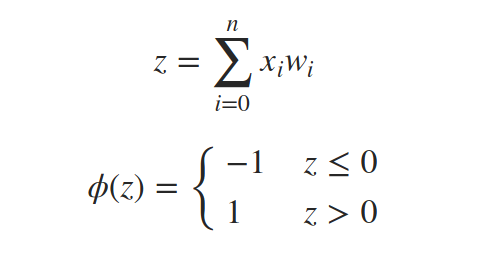
下面是一個感知器:

要使用向量表示法,我們可以將所有輸入x0、x1、…、xn和所有權重w0、w1、…、wn放入向量x和w中,當它們的點積為正時輸出1,否則輸出-1,
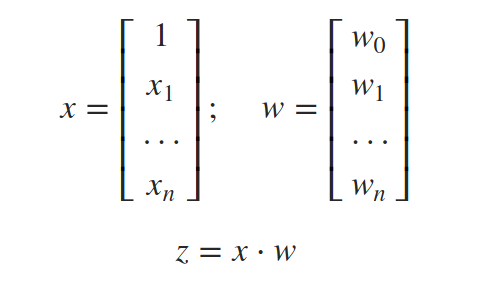
以下是僅使用2個輸入x1和x2的幾何表示,以便我們可以在2維中繪制:
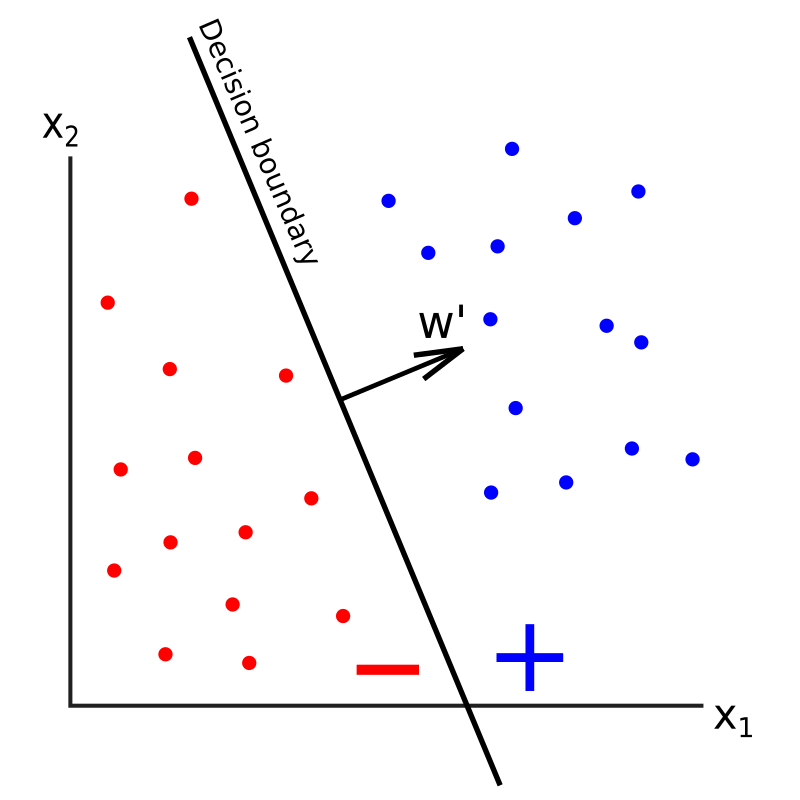
如上所示,具有2個輸入的感知器的決策邊界是一條直線,如果有3個輸入,則決策邊界為二維平面,一般來說,如果我們有n個輸入,決策邊界將是一個稱為n-1維的超平面,該超平面將我們的n維特征空間分成兩部分:一部分是將點分類為正的,另一部分是將點分類為負的(按照慣例,我們將認為恰好在決策邊界上的點是負的),因此,感知器是一個二元分類器,其權值是線性的,
在上面的影像中,w'表示沒有偏移項w0的權重向量,w'垂直于決策邊界并指向正分類點的性質,該向量決定了決策邊界的斜率,而偏移項w0決定了決策邊界沿w'軸的偏移,
到目前為止,我們討論了感知器如何根據輸入信號及其權值做出決策,但是,感知者實際上是如何學習的呢?如何找到合適的引數w0,w1,…,wn,以便進行良好的分類?
感知器演算法是基于以下簡單更新規則的迭代演算法:
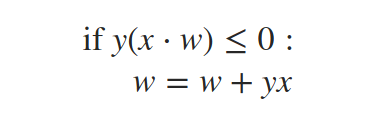
其中y是當前資料點x的標簽(要么-1要么+1),w是權重向量,
我們的更新規則怎么說?點積x?w只是感知器基于當前權重的預測(其符號與預測標簽的符號相同),運算式y(x?w)只能小于或等于0,前提是實際標簽y不同于預測標簽φ(x?w),因此,如果真標簽和預測標簽之間不匹配,那么我們更新權重:w=w+yx;否則,我們讓它們保持原樣,
那么,為什么w=w+yx更新規則有效?因為它試圖在if條件下將y(x?w)的值推向0的正邊,從而正確地對x進行分類,如果資料集是線性可分的,通過對每個點進行一定次數的迭代,權值最侄訓收斂到每個點都被正確分類的狀態,讓我們通過在更新后重新評估if條件來查看更新規則的效果:
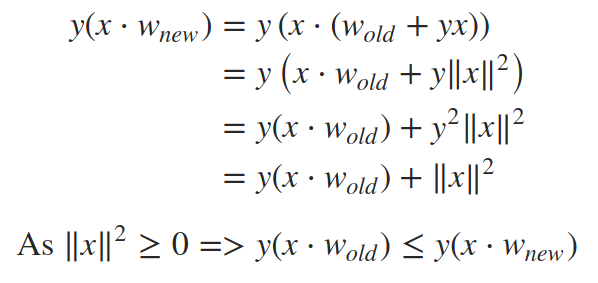
也就是說,在特定資料點的權重更新之后,if條件中的運算式應該更接近于正數,從而正確分類,
偽代碼中的完整感知器演算法如下:

Python實作

我們現在將在python中從頭開始實作感知器演算法,只使用numpy作為矩陣向量操作的外部庫,我們將把它作為一個類來實作,這個類的介面類似于Scikit-Learn這樣的通用機器學習包中的其他分類器,我們將為此類實作3個方法:.fit()、.predict()和.score(),
.fit()方法將用于訓練感知器,它期望第一個引數是2D numpy陣列X,該陣列的行是資料集的樣本,列是特征,第二個引數y應該是1D的numpy陣列,它包含X中每行資料的標簽,第三個引數n_iter是我們讓演算法運行的迭代次數,
def fit(self, X, y, n_iter=100):
n_samples = X.shape[0]
n_features = X.shape[1]
# 偏置都加1
self.weights = np.zeros((n_features+1,))
X = np.concatenate([X, np.ones((n_samples, 1))], axis=1)
for i in range(n_iter):
for j in range(n_samples):
if y[j]*np.dot(self.weights, X[j, :]) <= 0:
self.weights += y[j]*X[j, :]
.predict()方法將用于預測新資料的標簽,它首先檢查weights物件屬性是否存在,如果不存在,則表示感知器尚未訓練,然后顯示警告訊息并回傳,該方法需要一個與.fit()方法形狀相同的引數X,然后我們在X和權重之間做一個矩陣乘法,然后把它們映射到-1或+1,我們使用np.vectorize()將此映射應用于矩陣乘法結果向量中的所有元素,
def predict(self, X):
if not hasattr(self, 'weights'):
print('The model is not trained yet!')
return
n_samples = X.shape[0]
X = np.concatenate([X, np.ones((n_samples, 1))], axis=1)
y = np.matmul(X, self.weights)
y = np.vectorize(lambda val: 1 if val > 0 else -1)(y)
return y
score()方法計算并回傳預測的準確性,它期望輸入矩陣X和標簽向量y作為引數,
def score(self, X, y):
pred_y = self.predict(X)
return np.mean(y == pred_y)
幾個例子
我現在要做的是展示幾個可視化的例子,說明決策邊界是如何收斂到一個解的,
為了做到這一點,我將使用ScikitLearn的datasets.make_classification()和datasets.make_circles()函式創建幾個由200個樣本組成的2特征分類資料集,這是用于創建下兩個資料集的代碼:
X, y = make_classification(
n_features=2,
n_classes=2,
n_samples=200,
n_redundant=0,
n_clusters_per_class=1
)
還有一個資料集:
X, y = make_circles(n_samples=200, noise=0.03, factor=0.7)
對于每個示例,我將把資料分成150個用于訓練,50個用于測驗,左邊顯示訓練集,右邊顯示測驗集,當決策邊界收斂到一個解決方案時,決策邊界將在兩邊顯示,但是決策邊界將僅根據左邊的資料(訓練集)進行更新,
例1 線性可分的
我要展示的第一個資料集是線性可分的,下面是完整資料集的影像:
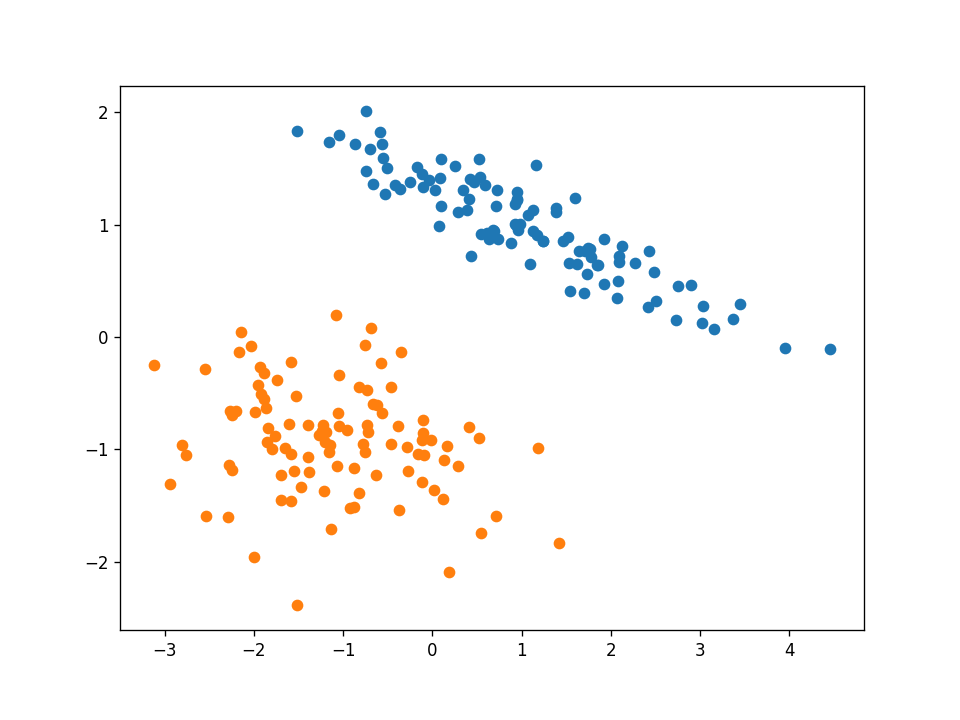
這是一個簡單的資料集,我們的感知器演算法在經過訓練集的兩次迭代后就會收斂到一個解,因此,每個資料點的影片幀都會改變,綠點是目前在演算法中測驗的那個,

在該資料集上,演算法對訓練樣本和測驗樣本進行了正確分類,
例2 噪聲資料集
如果資料集不是線性可分的呢?如果正反兩個例子像下圖一樣混淆在一起呢?
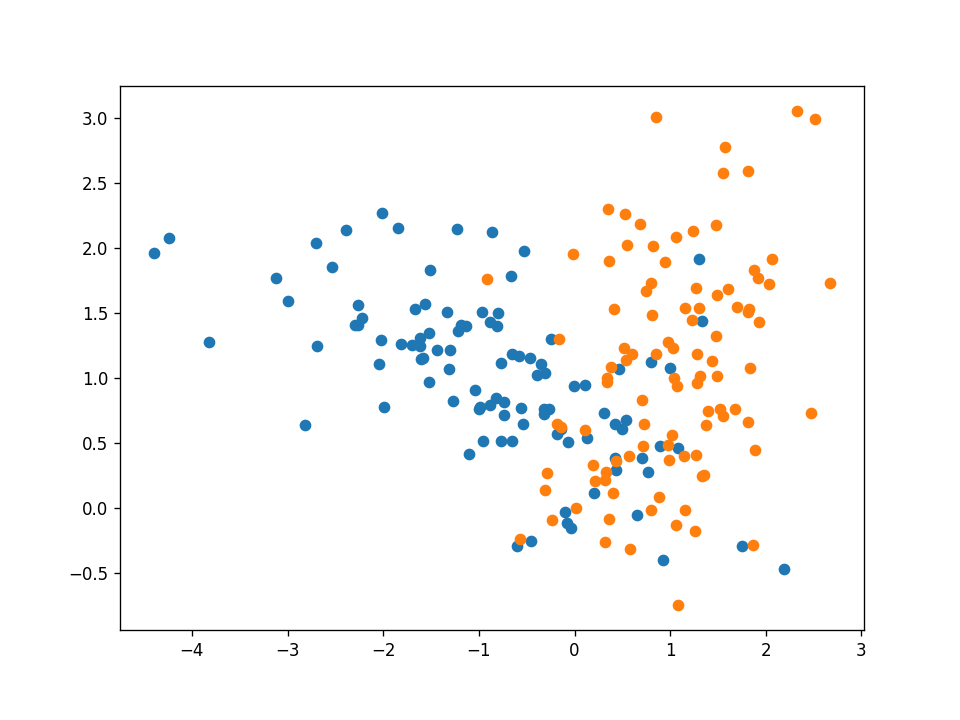
好吧,感知器演算法將不能正確分類所有的例子,但它將試圖找到一條線,最好的分開他們,在這個例子中,我們的感知器得到了88%的測驗精度,下面的影片幀在每次迭代后都會通過所有訓練示例進行更新,

例3 非線性資料集
下面的資料集如何呢?
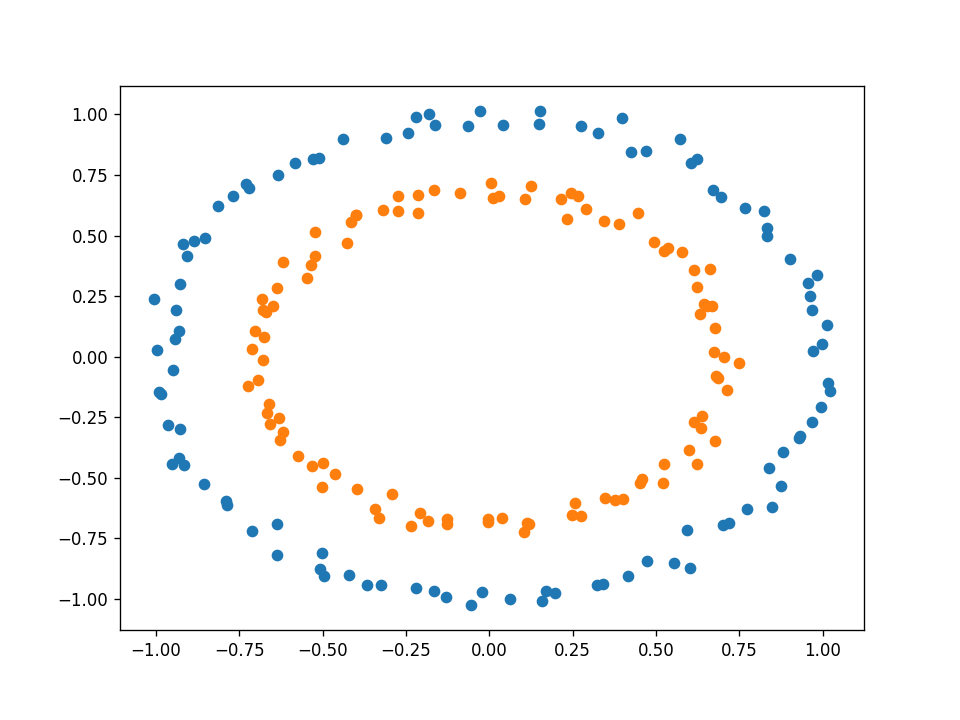
它是可分離的,但顯然不是線性的,所以你可能會認為一個感知器不適合這個任務,但感知器的問題是,它的決策邊界是線性的,就權重而言,不一定就輸入而言,我們可以擴充輸入向量x,使其包含原始輸入的非線性函式,例如,除了原始輸入x1和x2之外,我們還可以將項x1平方、x1乘以x2和x2平方相加,
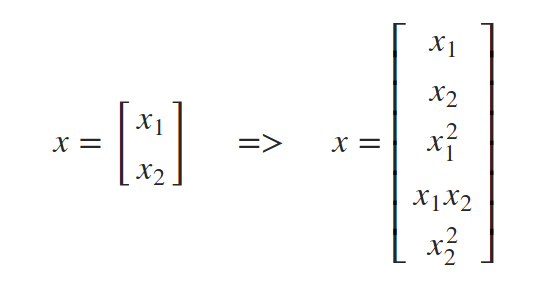
下面的 polynomial_features(X, p)(X,p)函式能夠將輸入矩陣X轉換成一個矩陣,該矩陣包含p次多項式的所有項作為特征,它使用polynom()函式計算表示要相乘列的索引串列,以獲得p階項,
def polynom(indices_list, indices, a, b, p):
indices = [*indices]
if p == 0:
indices_list.append(indices)
return
for i in range(a, b):
indices.append(i)
polynom(indices_list, indices, i, b, p-1)
indices = indices[0:-1]
def polynomial_features(X, p):
n, d = X.shape
features = []
for i in range(1, p+1):
l = []
polynom(l, [], 0, d, i)
for indices in l:
x = np.ones((n,))
for idx in indices:
x = x * X[:, idx]
features.append(x)
return np.stack(features, axis=1)
在我們的例子中,我們將在X矩陣中添加2級項作為新特征,
X = polynomial_features(X, 2)
現在,讓我們看看使用這個轉換后的資料集進行訓練時會發生什么:
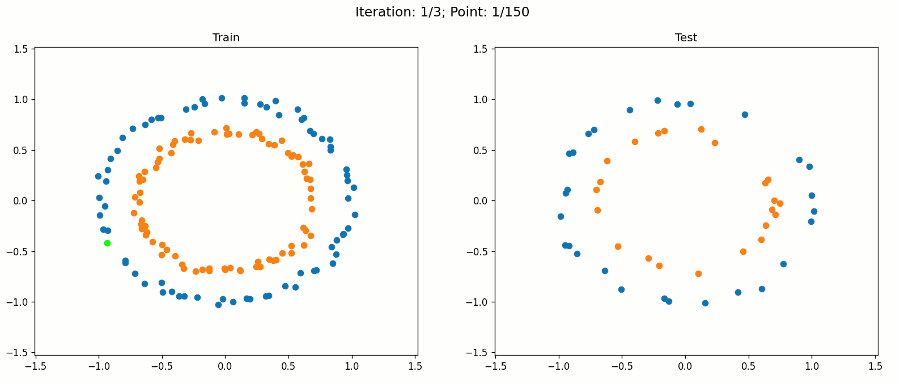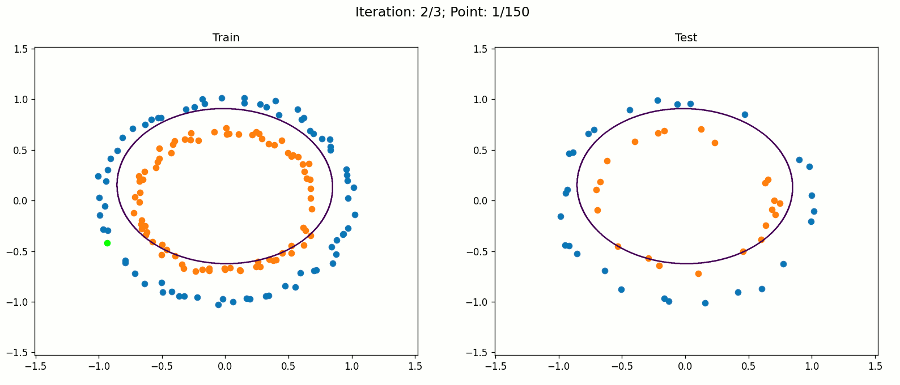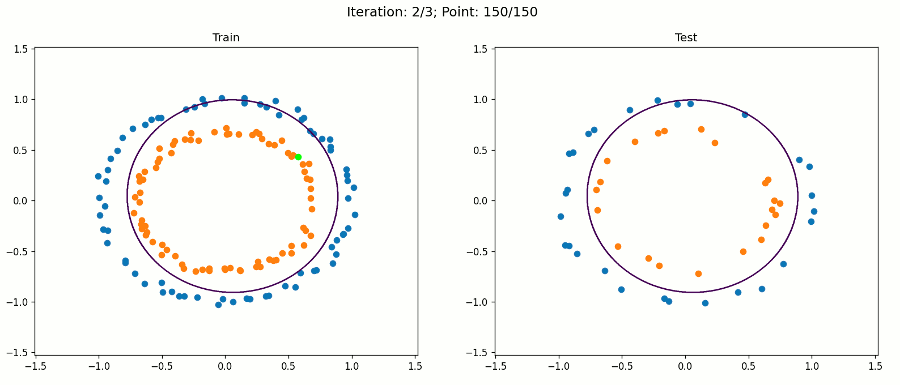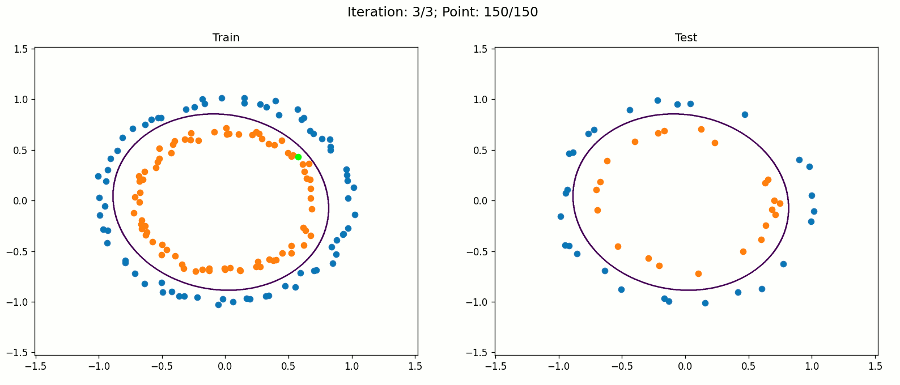
注意,對于繪圖,我們只使用原始輸入來保持它的二維性,決策邊界在擴展特征空間中仍然是線性的,現在是5D,但是,當我們繪制投影到原始特征空間的決策邊界時,它具有非線性形狀,
通過這種方法,我們的感知器演算法能夠在不修改演算法本身的情況下正確地分類訓練和測驗實體,我們只改變了資料集,
通過這種特征增強方法,我們可以使用線性演算法在資料中建模非常復雜的模式,
但是,這種方法不是很有效,想象一下,如果我們有1000個輸入特征,并且我們想用最多10次多項式項來擴充它,會發生什么,幸運的是,這個問題可以通過使用核函式來避免,但這是另一篇文章的主題,我不想把這篇文章寫得太長,
原文鏈接:https://towardsdatascience.com/perceptron-explanation-implementation-and-a-visual-example-3c8e76b4e2d1
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/5334.html
標籤:其他
上一篇:Creating and deleting branches within your repository
下一篇:5個強大的Excel儀表板