作者|LAKSHAY ARORA
編譯|VK
來源|Analytics Vidhya
概述
-
部署機器學習模型是每個ML專案的一個關鍵
-
學習如何使用Flask將機器學習模型部署到生產中
-
模型部署是資料科學家訪談中的一個核心話題
介紹
我記得我早期在機器學習領域的日子,我喜歡處理多個問題,對機器學習專案的各個階段都很感興趣,和我之前的許多人一樣,我被模型整個生命周期的構建所吸引,
我和領域專家談過,專案經理和所有相關人員確保他們的投入被包括在模型中,但后來我遇到了一個障礙——我到底該如何把我的模型交給我的客戶呢?我不能給他們一個Jupyter notebook!
我所學的一切都集中在模型構建組件上,沒有多少人會談論如何部署你的機器學習模型,把你的模型投入生產意味著什么?它需要什么?

這些都是每個資料科學家需要回答的關鍵的職業定義問題,這就是為什么我決定寫下這個教程來演示如何使用Flask來部署機器學習模型,
我們將首先了解模型部署的概念,然后討論Flask是什么,如何安裝它,最后,我們將深入到一個問題陳述中,學習如何使用Flask部署機器學習模型,
目錄
-
什么是模型部署?
-
什么是Flask?
-
在機器上安裝Flask
-
理解問題陳述
-
建立我們的機器學習模型
-
設定Twitter API
-
創建網頁
-
將網頁與模型連接
-
查看部署模型
什么是模型部署?
在典型的機器學習和深度學習專案中,我們通常從定義問題陳述開始,然后是資料收集和準備、資料理解和模型構建,對吧?
但是,最后,我們希望我們的模型能夠提供給最終用戶,以便他們能夠利用它,模型部署是任何機器學習專案的最后階段之一,可能有點棘手,如何將機器學習模型傳遞給客戶/利益相關者?當你的模型投入生產時,你需要注意哪些不同的事情?你怎么能開始部署一個模型呢?
Flask的作用來了,
什么是Flask?
Flask是一個用Python撰寫的web應用程式框架,它有多個模塊,使web開發人員更容易撰寫應用程式,而不必擔心協議管理、執行緒管理等細節,
Flask是開發web應用程式的選擇之一,它為我們提供了構建web應用程式所必需的工具和庫,

在本教程中,我們將利用Flask的資源來幫助我們部署自己的機器學習模型,你會喜歡用Flask作業的!
在機器上安裝Flask
安裝Flask簡單明了,在這里,我假設你已經安裝了Python 3和pip,要安裝Flask,需要運行以下命令:
sudo apt-get install python3-flask
就這樣!準備好深入到問題陳述中去,離部署機器學習模型更近一步,
理解問題陳述
在本節中,我們將使用Twitter資料集,我們的目標是在推特上發現仇恨言論,為了簡單起見,如果推特帶有種族主義或性別歧視情緒,我們說它包含仇恨言論,
我們將創建一個包含如下文本框的網頁(用戶可以搜索任何文本):

對于任何搜索查詢,我們將實時抓取與該文本相關的tweet,對于所有這些被抓取的tweet,我們將使用仇恨言語檢測模型對種族主義和性別歧視tweet進行分類,
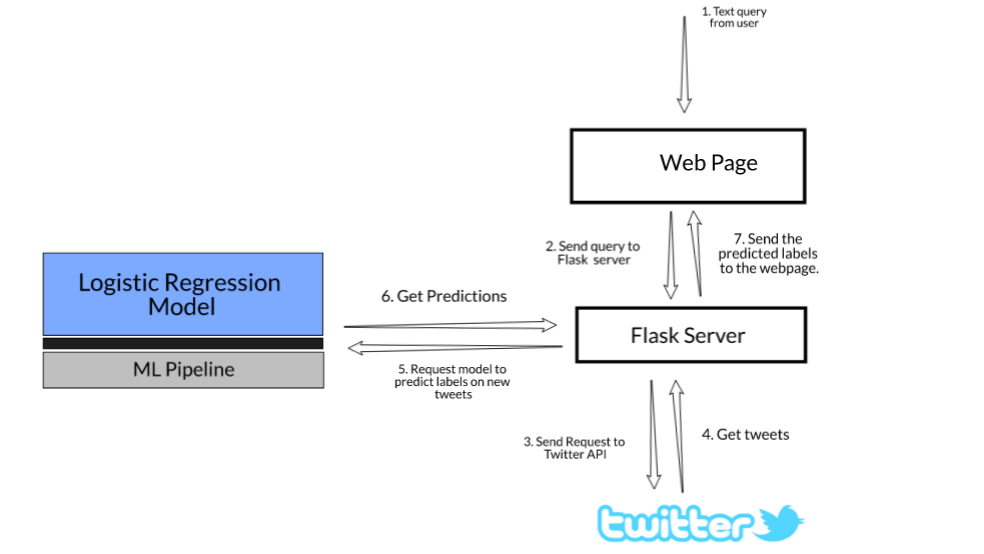
設定專案作業流
- 模型構建:我們將建立一個邏輯回歸模型管道來分類tweet是否包含仇恨言論,在這里,我們的重點不是如何建立一個非常精確的分類模型,而是看看如何使用Flask部署這個模型
- 安裝Twitter應用程式:我們將在Twitter開發人員的網站上創建一個Twitter應用程式,并獲取身份驗證密鑰,我們將撰寫一個Python腳本來抓取與特定文本查詢相關的tweet
- 網頁模板:在這里,我們將設計一個用戶界面,用戶可以提交他的查詢
- 獲取Tweets:從用戶處獲取查詢后,我們將使用twitter API獲取與所搜索查詢相關的Tweets
- 預測類并發送結果:接下來,使用保存的模型預測tweets的類并將結果發送回網頁
下面是我們剛才看到的步驟的示意圖:
建立我們的機器學習模型
我們在映射到標簽的CSV檔案中有關于Tweets的資料,我們將使用logistic回歸模型來預測tweet是否包含仇恨言論,
你可以在這里下載完整的代碼和資料集,
https://github.com/lakshay-arora/Hate-Speech-Classification-deployed-using-Flask/tree/master
首先匯入一些必需的庫:
# 匯入必需的庫
import pandas as pd
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS, TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
接下來,我們將讀取資料集并查看頂行:
# 讀取資料集
data = https://www.cnblogs.com/panchuangai/p/pd.read_csv('dataset/twitter_sentiments.csv')
# 查看頂行
data.head()

資料集有31962行和3列:
- id:每行的唯一編號
- label:對于正常的tweet,它是0;對于種族主義或性別歧視的tweet,它將是1,有29720個0和2242個1
- tweet:在Twitter上發布的tweet
現在,我們將使用scikit learn的train_test_split函式將資料分為訓練和測驗,我們只將20%的資料用于測驗,我們將對標簽列上的資料進行分層抽樣,以便目標標簽在訓練和測驗資料中的分布相同:
# 分為訓練集和測驗集
train, test = train_test_split(data, test_size = 0.2, stratify = data['label'], random_state=21)
# 獲取大小
train.shape, test.shape
## >> ((25569, 3), (6393, 3))
現在,我們將使用TfidfVectorizer 創建tweet列的TF-IDF向量,并將引數lowercase設為True,以便它首先將文本轉換為小寫,我們還將保持max features為1000,并傳遞scikit learn 庫中預定義的停用詞串列,
首先,創建TFidfVectorizer的物件,構建模型并將模型與訓練資料tweets匹配:
# 創建TfidfVectorizer物件
tfidf_vectorizer = TfidfVectorizer(lowercase= True, max_features=1000, stop_words=ENGLISH_STOP_WORDS)
# 擬合模型
tfidf_vectorizer.fit(train.tweet)
利用模型對訓練和測驗資料的推文進行變換:
# #轉換訓練和測驗資料
train_idf = tfidf_vectorizer.transform(train.tweet)
test_idf = tfidf_vectorizer.transform(test.tweet)
現在,我們將創建一個Logistic回歸模型的物件,
請記住,我們的重點不是建立一個非常精確的分類模型,而是看我們如何部署這個預測模型來獲得結果,
# 創建線性回歸模型的物件
model_LR = LogisticRegression()
# 用訓練資料擬合模型
model_LR.fit(train_idf, train.label)
# 預測訓練資料的標簽
predict_train = model_LR.predict(train_idf)
# 在測驗資料預測模型
predict_test = model_LR.predict(test_idf)
# f1得分
f1_score(y_true= train.label, y_pred= predict_train)
## >> 0.4888178913738019
f1_score(y_true= test.label, y_pred= predict_test)
## >> 0.45751633986928114
讓我們定義管道的步驟:
-
步驟1:創建一個tweet文本的TF-IDF向量,其中包含上面定義的1000個特征
-
步驟2:使用邏輯回歸模型預測目標標簽
當我們對管道物件使用fit()函式時,這兩個步驟都會執行,在模型訓練程序之后,我們使用predict())函式來生成預測,
# 定義管道的階段
pipeline = Pipeline(steps= [('tfidf', TfidfVectorizer(lowercase=True,
max_features=1000,
stop_words= ENGLISH_STOP_WORDS)),
('model', LogisticRegression())])
# 用訓練資料擬合管道模型
pipeline.fit(train.tweet, train.label)
現在,我們將使用一個示例tweet測驗管道:
# 示例tweet
text = ["Virat Kohli, AB de Villiers set to auction their 'Green Day' kits from 2016 IPL match to raise funds"]
# 使用管道預測標簽
pipeline.predict(text)
## >> array([0])
我們已經成功地構建了機器學習管道,我們將使用joblib庫中的dump函式保存這個管道物件,只需傳遞管道物件和檔案名:
# 匯入joblib
from joblib import dump
# 保存管道模型
dump(pipeline, filename="text_classification.joblib")
它將創建一個檔案“text_classification.joblib“. 現在,我們將打開另一個Python檔案,并使用joblib庫的load函式來加載管道模型,
讓我們看看如何使用保存的模型:
# 匯入joblib
from joblib import load
# tweet文本示例
text = ["Virat Kohli, AB de Villiers set to auction their 'Green Day' kits from 2016 IPL match to raise funds"]
# 加載保存的pipleine模型
pipeline = load("text_classification.joblib")
# 對tweet文本樣本的預測
pipeline.predict(text)
## >> array([0])
設定Twitter API
我們需要做的第一件事是從Twitter開發人員網站獲取API key, API secret key, access token,access token secret,這些密鑰將幫助API進行身份驗證,首先,轉到這一頁并填寫表格,
https://developer.twitter.com/en/apps/create
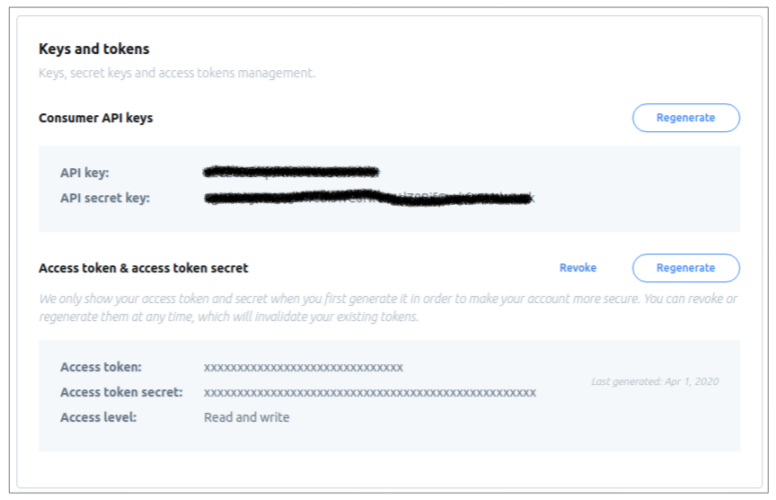
一旦你填好表格,你就會拿到key,
安裝tweepy
現在,我們將安裝tweepy,它是一個Python庫,允許我們訪問Twitter API,
!pip3 install tweepy
匯入所需的庫并添加從Twitter接收到的身份驗證密鑰,Tweepy試圖使身份驗證對你來說盡可能無痛,
要開始這個程序,需要創建OAuthHandler實體并傳遞API key和API secret key,然后使用access token和access token secret對實體進行身份驗證,
# 匯入所需庫
import tweepy
import time
import pandas as pd
pd.set_option('display.max_colwidth', 1000)
# api key
api_key = "Enter API Key Here"
# api secret key
api_secret_key = "Enter API Secret Key Here."
# access token
access_token = "Enter Access Token Here"
# access token secret
access_token_secret = "Enter Access Token Secret Here."
# 授權API Key
authentication = tweepy.OAuthHandler(api_key, api_secret_key)
#對用戶access token和access token secret授權
authentication.set_access_token(access_token, access_token_secret)
# 呼叫api
api = tweepy.API(authentication, wait_on_rate_limit=True)
接下來,我們將定義一個函式“get_related_tweets”,它將接受引數text_query并回傳與該特定文本查詢相關的50條tweets,我們將使用搜索API從Twitter獲取結果,
搜索API的一些引數是:
- q–最多500個字符的搜索查詢字串
- geocode–回傳位于給定緯度/經度的給定半徑內的用戶的tweets
- lang–將tweets限制為給定的語言,由ISO 639-1代碼給出
- result_type–指定希望接收的搜索結果型別,當前默認值為“mixed”,有效值包括:
- mixed:回傳包含流行和實時結果
- recent:僅回傳最近的結果
- popular:只回傳最流行的結果
- count–每頁嘗試檢索的結果數,一次最多可以請求100條tweets
- max_id–僅回傳id小于(即早于)或等于指定id的狀態,使用此選項,可以自動獲取大量唯一的tweets
我們將為給定的文本查詢請求50條tweet以及tweet創建時間、tweet id和tweet文本,函式將回傳所有tweet的資料幀:
def get_related_tweets(text_query):
# 存盤推文的串列
tweets_list = []
# 推特數量
count = 50
try:
# 從查詢中提取單個tweets
for tweet in api.search(q=text_query, count=count):
print(tweet.text)
# 添加到包含所有tweets的串列
tweets_list.append({'created_at': tweet.created_at,
'tweet_id': tweet.id,
'tweet_text': tweet.text})
return pd.DataFrame.from_dict(tweets_list)
except BaseException as e:
print('failed on_status,', str(e))
time.sleep(3)
創建網頁
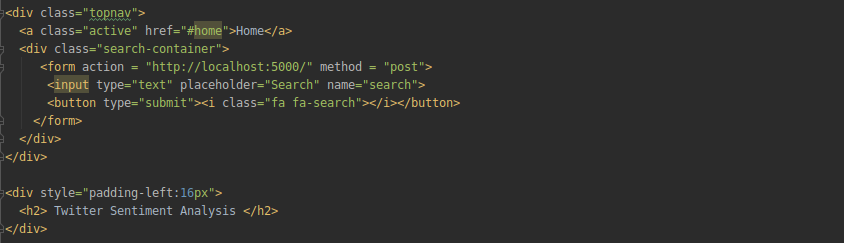
在這里,我們將創建一個類似于以下內容的網頁:
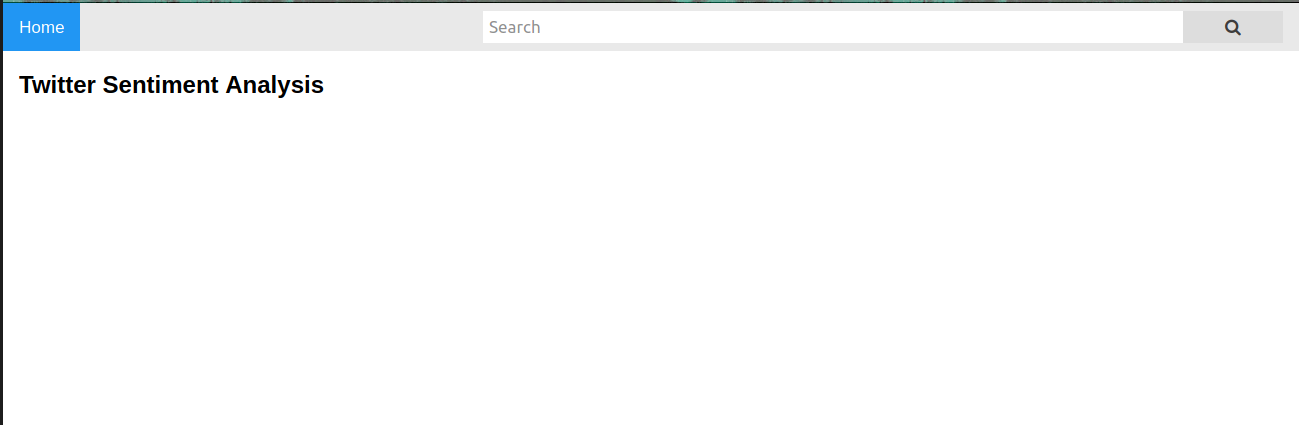
它將有一個文本框,用戶可以在其中鍵入文本查詢,然后單擊“搜索”按鈕以獲取搜索文本查詢的結果,
我們需要添加表單標記來收集搜索容器中的資料,在表單標記中,我們將方法post和name作為“search”傳遞,通過提供這個方法,我們的后端代碼將能夠知道我們已經收到了一些名為“search”的資料,在后端,我們需要處理這些資料并發送一些資料,
這只是HTML檔案的一部分,你可以在此處下載完整的代碼和與此專案相關的其他檔案,
https://github.com/lakshay-arora/Hate-Speech-Classification-deployed-using-Flask/tree/master
將網頁與模型連接
我們已經完成了前端部分,現在我們連接模型和網頁,第一步是加載保存的管道模型,我們將定義一個函式requestResults,該函式將獲取所請求查詢的tweets,并使用管道獲取標簽并回傳要發送的最終結果,
# 匯入所需庫
from flask import Flask, render_template, request, redirect, url_for
from joblib import load
from get_tweets import get_related_tweets
# 加載管道物件
pipeline = load("text_classification.joblib")
# 獲取特定文本查詢的結果
def requestResults(name):
# 獲取推特文本
tweets = get_related_tweets(name)
# 獲取預測
tweets['prediction'] = pipeline.predict(tweets['tweet_text'])
# 獲取預測的不同標簽的值計數
data = https://www.cnblogs.com/panchuangai/p/str(tweets.prediction.value_counts()) +'\n\n'
return data + str(tweets)
現在,首先,創建Flask類的一個物件,該物件將以當前模塊名作為引數,route函式將告訴Flask應用程式下一步要在網頁上呈現哪個URL,
當Flask服務器運行時,Flask應用程式將路由到默認URL路徑并呼叫home函式,它將呈現home.html檔案,
現在,每當有人發送文本查詢時,Flask將檢測post方法并呼叫get_data函式,在這里我們將使用名稱搜索獲取表單資料,然后重定向到success函式,
最后,success函式將使用requestResults函式獲取資料并將其發送回網頁,
# 啟動flask
app = Flask(__name__)
# 渲染網頁
@app.route('/')
def home():
return render_template('home.html')
# 當post方法檢測到時,則重定向到success函式
@app.route('/', methods=['POST', 'GET'])
def get_data():
if request.method == 'POST':
user = request.form['search']
return redirect(url_for('success', name=user))
# 獲取請求查詢的資料
@app.route('/success/<name>')
def success(name):
return "<xmp>" + str(requestResults(name)) + " </xmp> "
現在,呼叫run函式啟動Flask服務器:
app.run(debug=True)
查看部署模型
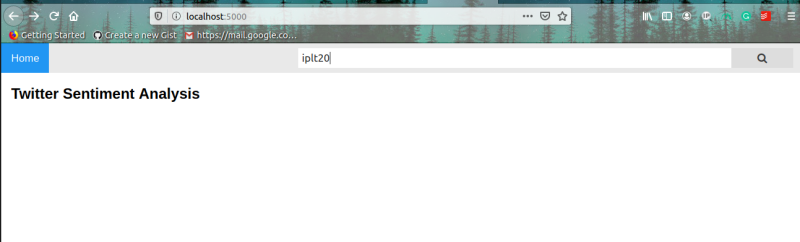
我們已成功啟動Flask服務器!打開瀏覽器并轉到此地址-http://127.0.0.1:5000/,你將看到Flask服務器已呈現默認模板,現在搜索任何查詢,如iplt20:
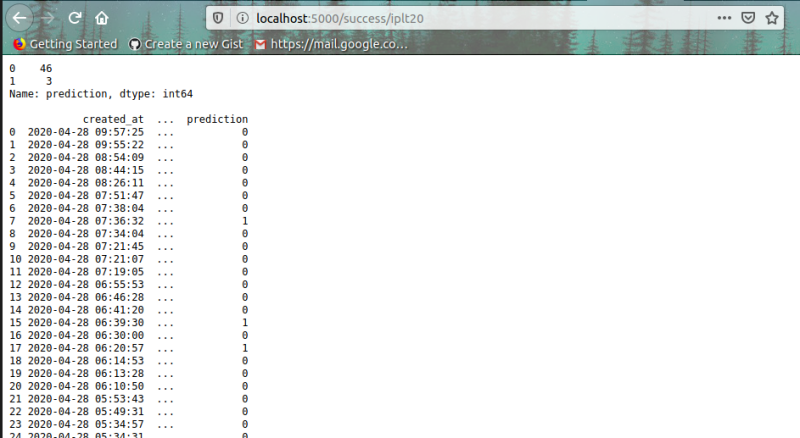
Flask服務器將接收與iplt20相關的資料和新tweets請求,并使用該模型預測標簽并回傳結果,
令人驚嘆!在這里,在50條推文中,我們的模型預測了3條包含仇恨言論的推文,我們可以添加更多的功能,比如請求來自某個國家的推文,
結尾
這就是使用Flask執行模型部署的方法!部署機器學習模型聽起來可能是一項復雜而繁重的任務,但是一旦你了解了它是什么以及它是如何作業的,你就已經完成了一半,
原文鏈接:https://www.analyticsvidhya.com/blog/2020/04/how-to-deploy-machine-learning-model-flask/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/5336.html
標籤:其他
上一篇:5個強大的Excel儀表板
下一篇:光學時鐘“升天”助力衛星精準導航