這是演算法與資料結構番外系列的第一篇,這個系列未來的主要內容是補充一些與演算法與資料結構相關的知識,這些知識比較零碎,同時也與正傳關系密切,往往需要閱讀了正傳的相關內容以后,才能較好的理解這部分內容,如果對番外系列不感興趣的話,是可以跳過此系列內容的,不會影響理解其他文章的內容,
閱讀本文前,需要首先了解佇列和堆的相關知識,
此文優先佇列的代碼可以在我的 github 上查看,
優先佇列
優先佇列是一種特殊的佇列,佇列具有先進先出的特性,對于普通佇列而言,首先出隊的元素是首先入隊的元素,而優先佇列中,首先出隊的元素是目前佇列中優先級最高的元素,
優先佇列分為兩類,最大優先佇列和最小優先佇列,一個最大優先佇列的嚴格定義如下:
最大優先佇列是一種用來維護由一組元素構成的集合 S 的資料結構,其中的每一個元素都有一個相關的值,稱為關鍵字(key,也就是我們上文所說的優先級),一個最大優先佇列應該支持以下操作:
INSERT(S, x):把元素 x 插入集合 S 中,
MAXIMUM(S):回傳 S 中具有最大關鍵字的元素,
EXTRACT-MAX(S):去掉并回傳 S 中的具有最大關鍵字的元素,
最大優先佇列最為著名的應用場景,是共享計算機系統的作業調度,最大優先佇列將會記錄將要執行的各個作業以及它們之間的相對優先級,當一個作業完成或者被中斷后,調度器呼叫 EXTRACT-MAX 從所有的等待作業中,選出具有最高優先級的作業來執行,在任何時候,調度器都可以呼叫 INSERT 把一個新作業加入到佇列中來,
相應的,最小優先佇列則是選擇集合中具有最小關鍵字的元素,最小優先佇列經常被用于模擬,佇列中保存要模擬的事件,每個事件都有一個發生時間作為其關鍵字,事件將會按照時間先后順序依次發生,模擬程式呼叫 EXTRACT-MIN (即與 EXTRACT-MAX 正好相反的功能:去掉并回傳 S 中的具有最小關鍵字的元素)選擇下一個要模擬的事件,當一個新事件產生時,模擬器通過呼叫 INSERT 將其插入最小優先佇列,
優先佇列可以使用堆來實作,最大優先佇列對應最大堆,最小優先佇列對應最小堆,下面我們將以最大優先佇列為例進行介紹,
優先佇列的實作
優先佇列的定義
優先佇列的定義與佇列幾乎完全一樣:
// 優先佇列定義
typedef struct PriorityQueue{
int* array;
int max_size;
}PriorityQueue;
輔助函式
這些輔助函式我們在堆排序的那一章中已經寫好,這里可以直接使用,
獲取堆中節點的父節點,左孩子和右孩子節點下標:
#define PARENT(i) (i / 2)
#define LEFT(i) (2 * i)
#define RIGHT(i) (2 * i + 1)
交換陣列兩個元素的值:
// 交換陣列 下標i 和 下標j 對應的值
int swap(int *array, int i, int j){
int temp;
temp = array[i];
array[i] = array[j];
array[j] = temp;
return 0;
}
遞回維護最大堆:
// 遞回維護最大堆
int MaintainMaxHeap(int *heap, int i){
int largest;
int left = LEFT(i);
int right = RIGHT(i);
if(left <= heap[0] && heap[left] > heap[i]){
largest = left;
} else{
largest = i;
}
if(right <= heap[0] && heap[right] > heap[largest]){
largest = right;
}
if(largest != i){
swap(heap, largest, i);
MaintainMaxHeap(heap, largest);
}
return 0;
}
這些輔助函式是直接采用的堆排序所用代碼,由于篇幅有限,故不再重復解釋,可以點此查看相關解釋,
初始化函式
// 初始化優先佇列
PriorityQueue* PriorityQueueInit(int max_size){
PriorityQueue* priority_queue = (PriorityQueue*)malloc(sizeof(PriorityQueue));
priority_queue->array = (int*)malloc(sizeof(int) * (max_size + 1));
priority_queue->array[0] = 0;
priority_queue->max_size = max_size;
return priority_queue;
}
我們在這里,依然使用堆排序中的陣列解釋方法:array[0] 用于儲存堆中的有效資料個數,故陣列的實際長度為 max_size + 1,堆頂元素是 array[1],
入隊函式
// 優先佇列入隊
int PriorityQueueEnqueue(PriorityQueue *priority_queue, int number_to_enqueue){
int i;
priority_queue->array[0] += 1;
i = priority_queue->array[0];
priority_queue->array[priority_queue->array[0]] = number_to_enqueue;
while(i > 1 && priority_queue->array[PARENT(i)] < priority_queue->array[i]){
swap(priority_queue->array, PARENT(i), i);
}
return 0;
}
整個最大優先佇列本質上是一個最大堆,當我們插入一個資料時,首先將其插入至堆的尾部,此時可能會違背最大堆的性質,故我們將此元素不斷與其父節點的值進行比較,若其小于父節點的值,說明此時整個堆已經是一個最大堆了;若其大于父節點的值,則將此節點與父節點交換,重復此步驟,直到此元素小于其父節點的值或此元素成為了堆頂節點,
顯然,入隊操作的時間復雜度是 \(O(lgn)\) ,因為整個函式中影響其時間復雜度的程序為 while 回圈,其最差情況是將此元素從葉節點一步一步交換至根節點,而樹的高度為 \(O(lgn)\) ,
整個程序如下圖所示:
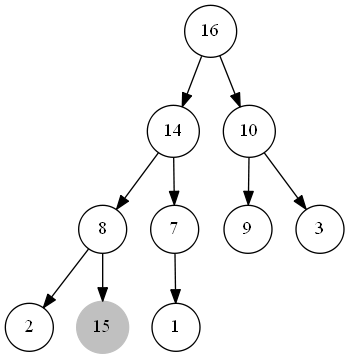
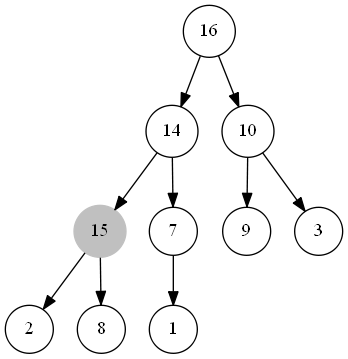
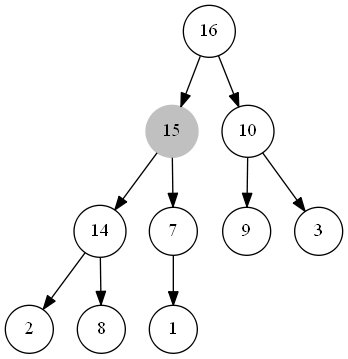
出隊函式
// 優先佇列隊首元素
int PriorityQueueHead(PriorityQueue *priority_queue){
return priority_queue->array[1];
}
// 優先佇列出隊
int PriorityQueueDequeue(PriorityQueue *priority_queue){
int return_number = priority_queue->array[1];
priority_queue->array[1] = priority_queue->array[priority_queue->array[0]];
priority_queue->array[0] -= 1;
MaintainMaxHeap(priority_queue->array, 1);
return return_number;
}
在理解了堆排序以后,優先佇列的出隊操作很簡單了,
一個最大優先佇列出隊時回傳的值為佇列中的最大值,即 array[1],那么我們只需要像堆排序時那樣,將堆中最后一個有效資料復制到堆頂(array[1]),此時新的堆頂可能會違反最大堆的性質,為此我們只需對堆頂元素呼叫一次 MaintainMaxHeap() ,即可保證出隊后,此堆依然是一個最大堆,
關于此程序的時間復雜度和正確性分析,我們已經在堆排序一章中介紹過了,在此就不贅述了,直接給出結果 \(O(lgn)\) ,
總結
在理解了堆排序以后,優先佇列就非常簡單了,幾乎連代碼都不需要太多修改,從上文的分析,我們也能得出一個結論,優先佇列最為關鍵的兩個步驟(入隊、出隊)的時間復雜度均為 \(O(lgn)\) ,
原文鏈接:albertcode.info
個人博客:albertcode.info
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/53366.html
標籤:其他