引言
最近在學編譯原理,一門理論與實踐結合的課程,我把作業發到博客里,希望能與大家交流分享,
詞法分析一章有一道比較復雜的作業題如下:
本題是一個編程問題,在本題目中,你將完整的實作Thompson演算法、子集構造演算法和Hopcroft演算法,為了幫助你開始,請下載如下鏈接中的代碼并根據代碼運行時的提示將缺少的代碼補充完整,(注意,我們給出了正則運算式和NFA的資料結構和Thompson演算法的框架,其它的資料結構和演算法需要你自行補充完整,)
代碼鏈接:http://staff.ustc.edu.cn/~bjhua/mooc/thompson.rar
由于我寫起C來就跟Cfront一樣,我還是寫C++吧,為了增加一點難度,我把原題的3步擴展為5步:構造正則運算式、Thompson構造法、子集構造演算法、Hopcroft演算法、生成C++代碼,
雖然屬于詞法分析部分,這道題的目標是實作詞法分析器生成器,已經有點語法分析的意味,不過背景關系無關文法換成了正則運算式,
完整代碼
構造正則運算式
設\(\Sigma\)為所有可能字符構成的集合,正則運算式(Regular Expression/regex/RE)是一串定義搜索樣式的字符,用于匹配由取自\(\Sigma\)中的字符組成的字串,RE的定義是遞回的:
-
空串\(\varepsilon\)是RE;
-
\(\forall c \in \Sigma\),\(c\)是RE;
-
如果\(M\)和\(N\)都是RE,則以下都是RE:
-
\(MN\),表示\(M\)后跟\(N\);
-
\(M|N\),表示\(M\)或\(N\);
-
\(M*\),表示\(\varepsilon\)或若干個\(M\),稱為\(M\)的Kleene閉包;
-
這是最基本的RE,諸如[0-9]和e+之類都屬于語法糖,我的實作中不涉及,
首先定義正則運算式型別:
class Regex
{
public:
Regex();
Regex(const Regex&) = delete;
virtual ~Regex() = 0;
};
class Regexvarepsilon : public Regex
{
public:
virtual ~Regexvarepsilon() override;
Regexvarepsilon();
};
class RegexChar : public Regex
{
public:
virtual ~RegexChar() override;
RegexChar(char);
char c;
};
class RegexConcat : public Regex
{
public:
virtual ~RegexConcat() override;
RegexConcat(Regex*, Regex*);
Regex* re0;
Regex* re1;
};
class RegexAlter : public Regex
{
public:
virtual ~RegexAlter() override;
RegexAlter(Regex*, Regex*);
Regex* re0;
Regex* re1;
};
class RegexClosure : public Regex
{
public:
virtual ~RegexClosure() override;
RegexClosure(Regex* re);
Regex* re;
};
Regex::Regex() = default;
Regex::~Regex() = default;
Regexvarepsilon::~Regexvarepsilon() = default;
Regexvarepsilon::Regexvarepsilon() = default;
RegexChar::~RegexChar() = default;
RegexChar::RegexChar(char c)
: c(c)
{
;
}
RegexConcat::~RegexConcat()
{
delete re0;
delete re1;
}
RegexConcat::RegexConcat(Regex* re0, Regex* re1)
: re0(re0), re1(re1)
{
;
}
RegexAlter::~RegexAlter()
{
delete re0;
delete re1;
}
RegexAlter::RegexAlter(Regex* re0, Regex* re1)
: re0(re0), re1(re1)
{
}
RegexClosure::~RegexClosure()
{
delete re;
}
RegexClosure::RegexClosure(Regex* re)
: re(re)
{
;
}
Regex和它的子類們把new的任務交給客戶,解構式負責delete,如果Regex要拷貝的話需要遞回深拷貝,很容易實作,但我不需要,所以寫= delete,
stringToRegex函式用于把字串轉換為Regex*,實作思路如下:
-
如果輸入是
(...)但不是(...)...(...)樣式的字串,去掉兩邊的圓括號,因為它們沒有用; -
如果
|存在于最外層(即...(...|...)...不算),對|分割的每一個子RE遞回呼叫該函式,然后用RegexAlter連接起來; -
否則,對于每一個帶括號的子RE遞回呼叫,對于字符直接構造
RegexChar,把空格當做\(\varepsilon\)(這兩個是遞回出口),都放到堆疊中(實作中用std::vector),遇到*時彈出堆疊頂,套上RegexClosure并放回,
static Regex* stringToRegex(std::string::const_iterator begin, decltype(begin) end)
{
return stringToRegex(std::string{ begin, end });
}
Regex* stringToRegex(const std::string& string)
{
auto begin = string.begin();
auto end = string.end();
while (1)
{
if (begin == end)
return makeRegex<Regexvarepsilon>();
if (*begin != '(')
break;
int level = 0;
bool bk = false;
for (auto iter = begin, e = end - 1; iter != e; ++iter)
if (*iter == '(')
++level;
else if (*iter == ')' && --level == 0)
bk = true;
if (bk)
break;
++begin;
--end;
}
std::vector<std::string::const_iterator> alts;
int level = 0;
for (auto iter = begin; iter != end; ++iter)
switch (*iter)
{
case '(':
++level;
break;
case ')':
--level;
break;
case '|':
if (level == 0)
alts.push_back(iter);
break;
}
if (alts.empty())
{
std::vector<Regex*> cons;
for (auto iter = begin; iter != end; ++iter)
{
switch (*iter)
{
case ' ':
cons.push_back(makeRegex<Regexvarepsilon>());
break;
case '*':
{
auto back = cons.back();
cons.pop_back();
cons.push_back(makeRegex<RegexClosure>(back));
break;
}
case '(':
{
int level = 0;
auto begin = iter;
for (; ; ++iter)
if (*iter == '(')
++level;
else if (*iter == ')' && --level == 0)
break;
cons.push_back(stringToRegex(begin, iter + 1));
break;
}
default:
cons.push_back(makeRegex<RegexChar>(*iter));
break;
}
}
auto regex = cons.front();
for (auto iter = cons.begin() + 1; iter != cons.end(); ++iter)
regex = makeRegex<RegexConcat>(regex, *iter);
return regex;
}
else
{
auto size = alts.size();
alts.push_back(end);
auto regex = stringToRegex(begin, alts.front());
for (decltype(size) i = 0; i != size; ++i)
regex = makeRegex<RegexAlter>(regex, stringToRegex(alts[i] + 1, alts[i + 1]));
return regex;
}
}
以(a|b)(c|d)*為例,構造出的Regex樹如圖:
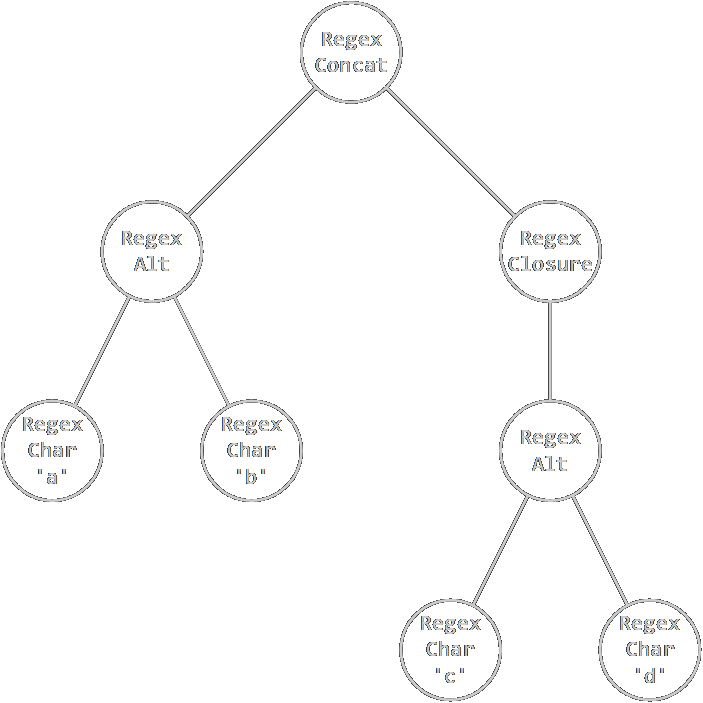
BTW,可否寫個RE來匹配所有RE?
Thompson構造法
Thompson構造法可以把正則運算式轉換為非確定性有限自動機(nondeterministic finite automaton,NFA),“非確定性”指的是狀態和狀態之間可以用\(\varepsilon\)來轉移,
首先給出Nfa的定義:
class NfaNode
{
public:
std::vector<NfaNode*> eps;
std::map<char, NfaNode*> map;
bool accept = false;
};
class Nfa
{
public:
explicit Nfa(const Regex*);
Nfa(const Nfa&) = delete;
Nfa& operator=(const Nfa&) = delete;
Nfa(Nfa&&) noexcept;
Nfa& operator=(Nfa&&) noexcept;
~Nfa();
NfaNode* begin = nullptr;
NfaNode* end = nullptr;
private:
std::vector<NfaNode*> nodes;
NfaNode* makeNode();
Nfa makeSubNfa(const Regex*);
};
Nfa::Nfa(Nfa&&) noexcept = default;
Nfa& Nfa::operator=(Nfa&& other) noexcept
{
begin = other.begin;
end = other.end;
nodes.swap(other.nodes);
return *this;
}
Nfa::~Nfa()
{
for (auto&& p : nodes)
delete p;
}
NfaNode* Nfa::makeNode()
{
auto ptr = new NfaNode;
nodes.push_back(ptr);
return ptr;
}
Nfa Nfa::makeSubNfa(const Regex* regex)
{
auto temp = regexToNfa(regex);
nodes.insert(nodes.end(), temp.nodes.begin(), temp.nodes.end());
temp.nodes.clear();
return temp;
}
NfaNode表示NFA中的狀態:eps為該狀態可以通過\(\varepsilon\)轉移到的狀態的集合;map為\(\Sigma\)中字符到對應目標狀態的映射;accept指示該狀態是否為接受狀態,
Nfa表示NFA:用nodes保存由makeNode創建的Nfa指標,在解構式中統一銷毀;begin和end表示起始和接受狀態,NFA是圖,拷貝要復雜得多,由于不需要(其實是我懶),故= delete之,Nfa要作為引數傳遞,移動構造還是需要的,
C++新手小課堂:
問:
std::vector中元素的迭代器和指標不是會失效嗎?為什么可以讓NfaNode保存NfaNode*呢?答:因為
std::vector的模板引數是NfaNode*而非NfaNode,NfaNode*是存盤的值,不會失效,
RE是遞回的,Thompson構造法亦是,為了方便遞回,需要對產生的NFA作一些規約:
-
NFA有唯一的起始狀態;
-
NFA有唯一的接收狀態,該狀態沒有向其他狀態的轉移;
然后就可以遞回地構造了:
-
空串\(\varepsilon\)構造為:
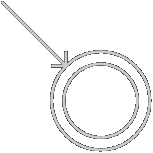
-
字符\(c\)構造為:
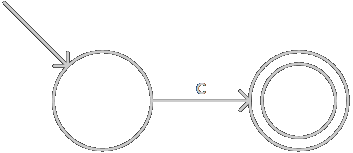
-
\(MN\)構造為:

-
\(M|N\)構造為:
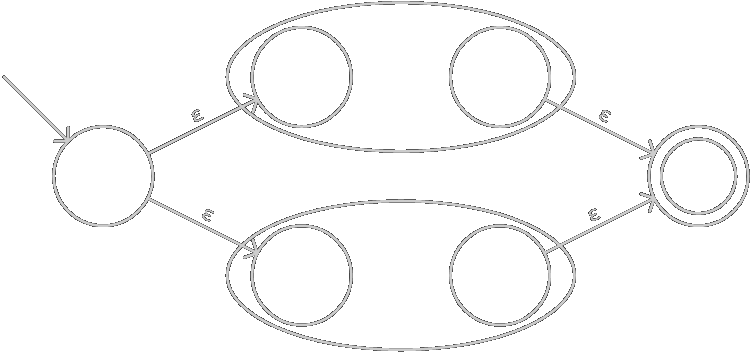
-
\(M*\)構造為:
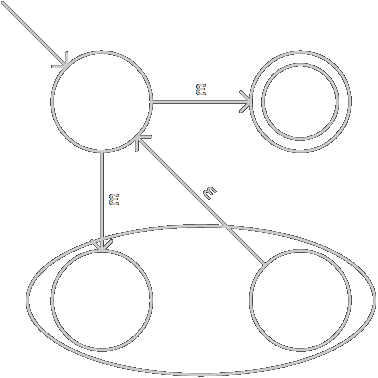
我對Thompson構造法的定義與標準的略有不同:我去掉了NFA起始狀態不能作為轉移目標狀態的要求,于是對閉包的構造減少了一個節點;同時對連接的構造增加了一個節點,不過這也有以上資料結構不方便洗掉一個節點的考慮,
Nfa::Nfa(const Regex* regex)
{
if (dynamic_cast<const Regexvarepsilon*>(regex))
{
begin = makeNode();
end = begin;
end->accept = true;
}
else if (dynamic_cast<const RegexChar*>(regex))
{
auto r = static_cast<const RegexChar*>(regex);
begin = makeNode();
end = makeNode();
end->accept = true;
begin->map[r->c] = end;
}
else if (dynamic_cast<const RegexConcat*>(regex))
{
auto r = static_cast<const RegexConcat*>(regex);
begin = makeNode();
auto nfa0 = makeSubNfa(r->re0);
auto nfa1 = makeSubNfa(r->re1);
begin->eps.push_back(nfa0.begin);
nfa0.end->eps.push_back(nfa1.begin);
nfa0.end->accept = false;
end = nfa1.end;
}
else if (dynamic_cast<const RegexAlter*>(regex))
{
auto r = static_cast<const RegexAlter*>(regex);
begin = makeNode();
end = makeNode();
auto nfa0 = makeSubNfa(r->re0);
auto nfa1 = makeSubNfa(r->re1);
begin->eps.push_back(nfa0.begin);
nfa0.end->eps.push_back(end);
nfa0.end->accept = false;
begin->eps.push_back(nfa1.begin);
nfa1.end->eps.push_back(end);
nfa1.end->accept = false;
end->accept = true;
}
else if (dynamic_cast<const RegexClosure*>(regex))
{
auto r = static_cast<const RegexClosure*>(regex);
begin = makeNode();
end = makeNode();
auto nfa = makeSubNfa(r->re);
begin->eps.push_back(end);
begin->eps.push_back(nfa.begin);
nfa.end->accept = false;
nfa.end->eps.push_back(begin);
end->accept = true;
}
}
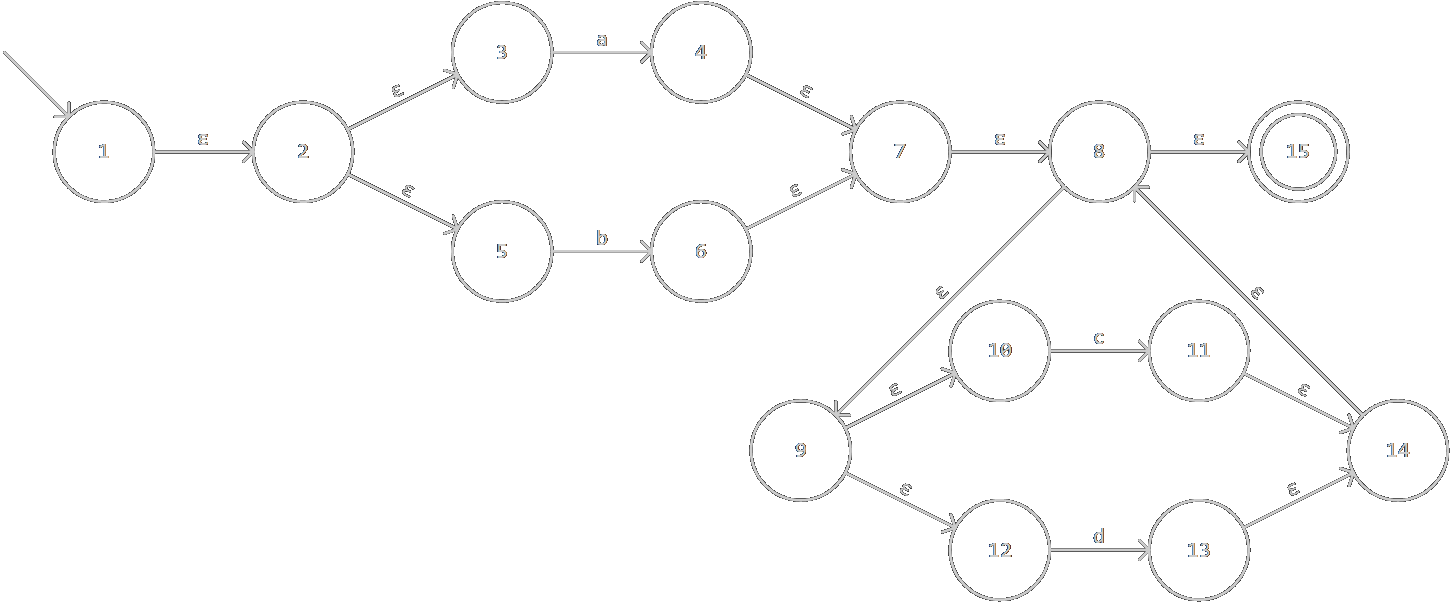
仍以(a|b)(c|d)*為例,構造出的NFA如圖:
子集構造演算法
NFA是不確定的,盡管有演算法可以用NFA來匹配字串,但是DFA(deterministic finite automaton,確定性有限自動機)更加簡單、直觀,因為它沒有\(\varepsilon\)轉移,并且每個狀態每個字符有唯一的轉移目標(用Thompson構造法構造出的NFA也符合這一點),
子集構造演算法可以從NFA構造DFA,先給出DFA的定義:
class SimpDfa;
class DfaNode
{
public:
std::map<char, std::size_t> map;
bool accept = false;
};
class Dfa
{
public:
Dfa();
Dfa(const Dfa&) = delete;
Dfa& operator=(const Dfa&) = delete;
Dfa(Dfa&&) noexcept;
Dfa& operator=(Dfa&&) noexcept;
~Dfa();
DfaNode* getNode(std::size_t);
private:
std::vector<DfaNode*> nodes;
using SubsetMap = std::map<std::set<NfaNode*>, std::size_t>;
SubsetMap subsetMap;
std::pair<SubsetMap::iterator, bool> makeNode(const std::set<NfaNode*>&, bool);
friend Dfa nfaToDfa(const Nfa& nfa);
friend SimpDfa simplifyDfa(const Dfa& dfa);
};
Dfa::Dfa() = default;
Dfa::Dfa(Dfa&& other) noexcept
: nodes(std::move(other.nodes))
{
;
}
Dfa& Dfa::operator=(Dfa&& other) noexcept
{
nodes.swap(other.nodes);
return *this;
}
Dfa::~Dfa()
{
for (auto&& p : nodes)
delete p;
}
DfaNode* Dfa::getNode(std::size_t index)
{
return nodes[index];
}
這回DfaNode不再維護DfaNode指標而是std::size_t陣列下標,其中陣列指的是Dfa中的nodes,這使Dfa的拷貝變得十分平凡,但還是改變不了我的懶惰——拷貝依然是= delete,makeNode功能上還是創建DfaNode,但是引數非常詭異,后面再講,
子集是冪集的元素,極端情況下子集構造演算法的復雜度為\(O(2^n)\),因此子集(subset)構造演算法又稱冪集(powerset)構造演算法,
之前提到,NFA中狀態之間可以用\(\varepsilon\)轉移,它們看起來像是相同的狀態,這就是子集構造演算法的核心想法,
在詳述演算法之前,先下個定義:一個狀態的\(\varepsilon\)閉包為能從該狀態通過\(\varepsilon\)轉移到的所有狀態的集合,
static void epsClosure(NfaNode* node, std::set<NfaNode*>& set, bool& accept)
{
if (set.find(node) != set.end())
return;
set.insert(node);
if (node->accept)
accept = true;
for (auto&& n : node->eps)
epsClosure(n, set, accept);
}
static std::pair<std::set<NfaNode*>, bool> epsClosure(NfaNode* node)
{
std::set<NfaNode*> set;
bool accept = false;
epsClosure(node, set, accept);
return { set, accept };
}
makeNode的第一個引數,正是\(\varepsilon\)閉包這樣的狀態集合;subsetMap為狀態集合到DfaNode指標的映射;makeNode的回傳值為std::map::insert的回傳值,其中的bool表示是否有新鍵插入,這個值后面有用,
std::pair<Dfa::SubsetMap::iterator, bool> Dfa::makeNode(const std::set<NfaNode*>& set, bool accept)
{
auto found = subsetMap.find(set);
if (found != subsetMap.end())
return { found, false };
auto ptr = new DfaNode;
auto index = nodes.size();
nodes.push_back(ptr);
ptr->accept = accept;
return subsetMap.insert({ set, index });
}
子集構造演算法的程序為:
-
求出起始狀態的\(\varepsilon\)閉包,該NFA狀態集合對應一個DFA狀態,接受屬性取決于閉包中是否有接受狀態,入隊;
-
取出佇列首元素,是一個狀態集合,對于\(\Sigma\)中的每一個字符,求出 集合中每一個狀態 通過該字母轉移到的狀態 的\(\varepsilon\)閉包 的并集,對應一個DFA狀態,接受屬性取決于并集中是否有接受狀態(思考:為什么是
||的關系?),如果該集合未被處理過,則入隊; -
如果佇列非空,回到2,否則結束,
Dfa nfaToDfa(const Nfa& nfa)
{
Dfa dfa;
auto ret = epsClosure(nfa.begin);
dfa.makeNode(ret.first, ret.second);
auto start = dfa.subsetMap.begin();
std::queue<decltype(start)> queue;
queue.push(start);
while (!queue.empty())
{
auto iter = queue.front();
queue.pop();
std::set<char> sigma;
for (auto&& node : iter->first)
for (auto&& kv : node->map)
sigma.insert(kv.first);
for (auto&& c : sigma)
{
std::set<NfaNode*> set;
bool accept = false;
for (auto&& node : iter->first)
{
auto found = node->map.find(c);
if (found == node->map.end())
continue;
auto ret = epsClosure(found->second);
set.insert(ret.first.begin(), ret.first.end());
accept = accept || ret.second;
}
auto pair = dfa.makeNode(set, accept);
dfa.nodes[iter->second]->map[c] = pair.first->second;
if (pair.second)
queue.push(pair.first);
}
}
return dfa;
}
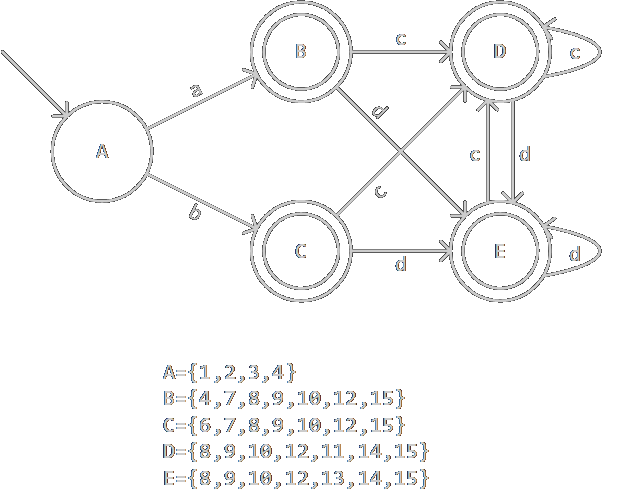
上一個NFA構造出的DFA如圖:
已經很復雜了,不是嗎?不要慌,后面還有更復雜的,
Hopcroft演算法
通過子集構造演算法獲得的DFA不是最簡的,化簡一個DFA的手段有刪掉不可到達的狀態和合并不可區分的狀態,上面這個子集構造演算法的實作不會產生不可到達的狀態,因此只需用Hopcroft演算法化簡即可(呵,說得輕巧),
Hopcroft演算法的輸入與輸出都是DFA,輸出用Dfa即可表示,但我定義了一個類似的新的資料結構,方便后續優化:
class SimpNode
{
public:
std::map<char, std::size_t> map;
bool accept = false;
};
class SimpDfa
{
public:
SimpDfa();
SimpDfa(const SimpDfa&) = delete;
SimpDfa& operator=(const SimpDfa&) = delete;
SimpDfa(SimpDfa&&) noexcept;
SimpDfa& operator=(SimpDfa&&) noexcept;
~SimpDfa();
std::size_t begin = 0;
SimpNode* getNode(std::size_t);
private:
std::vector<SimpNode*> nodes;
std::size_t makeNode();
friend SimpDfa simplifyDfa(const Dfa& dfa);
friend void generateCode(std::ostream&, const std::string&, const SimpDfa&);
};
SimpDfa::SimpDfa() = default;
SimpDfa::SimpDfa(SimpDfa&& other) noexcept
: nodes(std::move(other.nodes)), begin(other.begin)
{
;
}
SimpDfa& SimpDfa::operator=(SimpDfa&& other) noexcept
{
nodes.swap(other.nodes);
begin = other.begin;
return *this;
}
SimpDfa::~SimpDfa()
{
for (auto&& p : nodes)
delete p;
}
SimpNode* SimpDfa::getNode(std::size_t index)
{
return nodes[index];
}
std::size_t SimpDfa::makeNode()
{
auto ptr = new SimpNode;
auto index = nodes.size();
nodes.push_back(ptr);
return index;
}
Hopcroft演算法的核心是集合劃分:
-
初始狀態為兩個集合,接受狀態組成的集合與非接受狀態組成的集合;
-
對于每一個集合,我們要考察其中的各個狀態是否是不可區分的:對集合中的每一個狀態,求出其轉移到的狀態所在的集合,集合中的所有狀態的這一資訊必須完全相同——字符與字符對應的集合都相同——才能認為該集合不可劃分;否則就根據這一資訊來劃分,相同的劃分為一個新的集合;
-
如果這一步中集合被劃分,那么先前被認為是不可劃分的集合可能會變得可以劃分,需要重新遍歷集合的集合,直到一次遍歷中沒有劃分操作;
-
最后,每個集合對應一個化簡后DFA的狀態,接受屬性只需任取集合中一個元素看——很容易證明集合中各狀態的接受屬性相同;然后根據原DFA的轉移計算出新DFA的轉移,
這個演算法的實作非常猥瑣,我們知道并查集(可并集),初始時每個元素都是獨立的集合,然后可以把兩個集合并起來,時間復雜度接近\(O(n)\),那么有沒有所謂“可分集”呢?
我用的是笨辦法,用std::list保存各個集合,包括原DFA與新DFA中的狀態,在原DFA中維護指向std::list中元素的迭代器,這樣原DFA中的狀態與集合可以互相知曉,原DFA中的狀態是只讀的(為什么不去掉const或者加mutable呢?因為不優雅),無法在其中維護迭代器,因此新開一個std::vector,與nodes中的元素一一對應,這也是DfaNode中用陣列下標而不像NfaNode那樣用指標的原因(顯然,最初的實作是用指標的,后來才改成陣列下標),
struct ListItem
{
ListItem() = default;
ListItem(std::set<std::size_t>&& set)
: indices(std::move(set)) { }
std::set<std::size_t> indices;
std::size_t node = 0;
};
struct ItemRef
{
std::list<ListItem>::iterator iterator;
};
SimpDfa simplifyDfa(const Dfa& dfa)
{
auto size = dfa.nodes.size();
std::vector<ItemRef> helper(size);
std::list<ListItem> list;
{
list.emplace_back();
list.emplace_back();
auto yes = list.begin();
auto no = ++list.begin();
for (decltype(size) i = 0; i != dfa.nodes.size(); ++i)
if (dfa.nodes[i]->accept)
{
yes->indices.insert(i);
helper[i].iterator = yes;
}
else
{
no->indices.insert(i);
helper[i].iterator = no;
}
if (no->indices.empty())
list.erase(no);
}
while (1)
{
bool ok = true;
for (auto iter = list.begin(); iter != list.end(); )
{
std::map<std::map<char, ListItem*>, std::set<std::size_t>> map;
for (auto&& i : iter->indices)
{
std::map<char, ListItem*> key;
for (auto&& kv : dfa.nodes[i]->map)
key.insert({ kv.first, &*helper[kv.second].iterator });
map[key].insert(i);
}
if (map.size() == 1)
{
++iter;
continue;
}
ok = false;
for (auto&& pair : map)
{
auto& set = pair.second;
list.emplace_back(std::move(set));
auto iter = --list.end();
for (auto&& i : iter->indices)
helper[i].iterator = iter;
}
iter = list.erase(iter);
}
if (ok)
break;
}
SimpDfa result;
for (auto&& item : list)
{
item.node = result.makeNode();
result.nodes[item.node]->accept = dfa.nodes[*item.indices.begin()]->accept;
}
for (decltype(size) i = 0; i != size; ++i)
{
auto& map = result.nodes[helper[i].iterator->node]->map;
for (auto&& kv : dfa.nodes[i]->map)
map.insert({ kv.first, helper[kv.second].iterator->node });
}
result.begin = helper[0].iterator->node;
return result;
}
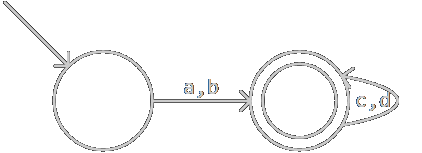
上一個DFA化簡得DFA如圖:
這個例子沒有涉及到集合劃分的程序,我們換一個wikipedia上的例子:(0|(1(01*(00)*0)*1)*)*,匹配所有能被3整除的二進制數,這里不探討它的正確性,我更不知道該如何寫出這樣的正則運算式,只管拿來用就是了,該RE被轉換為:
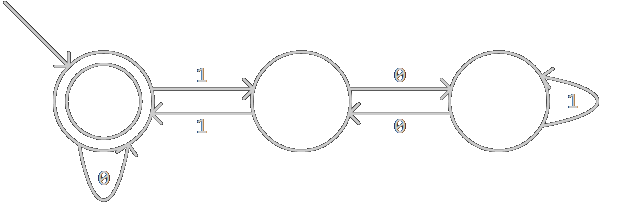
生成C++代碼
既然是用C++寫的,那就生成C++的代碼吧!想起曾經讀過的《設計模式》,State模式完全就是為自動狀態機而生,趁機實踐一下:
#include <iostream>
class Automaton
{
public:
~Automaton()
{
for (auto&& p : states)
delete p;
}
bool operator()(const std::string& s)
{
index = 0;
for (auto&& c : s)
(*states[index])(c);
return states[index]->accept();
}
private:
struct State
{
Automaton* ptr;
State(Automaton* ptr)
: ptr(ptr) { }
virtual ~State() = default;
virtual bool accept() = 0;
virtual void operator()(char) = 0;
};
struct StateAccept : State
{
using State::State;
virtual ~StateAccept() override = default;
virtual bool accept() override final
{
return true;
}
virtual void operator()(char) override = 0;
};
struct StateReject : State
{
using State::State;
virtual ~StateReject() override = default;
virtual bool accept() override final
{
return false;
}
virtual void operator()(char) override = 0;
};
struct StateError : StateReject
{
using StateReject::StateReject;
virtual ~StateError() override = default;
virtual void operator()(char c) override final
{
;
}
};
struct State0 : StateAccept
{
using StateAccept::StateAccept;
virtual ~State0() override = default;
virtual void operator()(char c) override final
{
switch (c)
{
case '0':
ptr->index = 0;
break;
case '1':
ptr->index = 1;
break;
default:
ptr->index = 3;
break;
}
}
};
struct State1 : StateReject
{
using StateReject::StateReject;
virtual ~State1() override = default;
virtual void operator()(char c) override final
{
switch (c)
{
case '0':
ptr->index = 2;
break;
case '1':
ptr->index = 0;
break;
default:
ptr->index = 3;
break;
}
}
};
struct State2 : StateReject
{
using StateReject::StateReject;
virtual ~State2() override = default;
virtual void operator()(char c) override final
{
switch (c)
{
case '0':
ptr->index = 1;
break;
case '1':
ptr->index = 2;
break;
default:
ptr->index = 3;
break;
}
}
};
State* states[4] = {
new State0{this},
new State1{this},
new State2{this},
new StateError{this},
};
std::size_t index;
};
int main()
{
std::cout << std::boolalpha;
Automaton a;
std::string input;
while (std::getline(std::cin, input))
std::cout << a(input) << std::endl;
}
這是上面最后一張圖的代碼實作,用作生成代碼的模板,State及其子類的關系如圖:
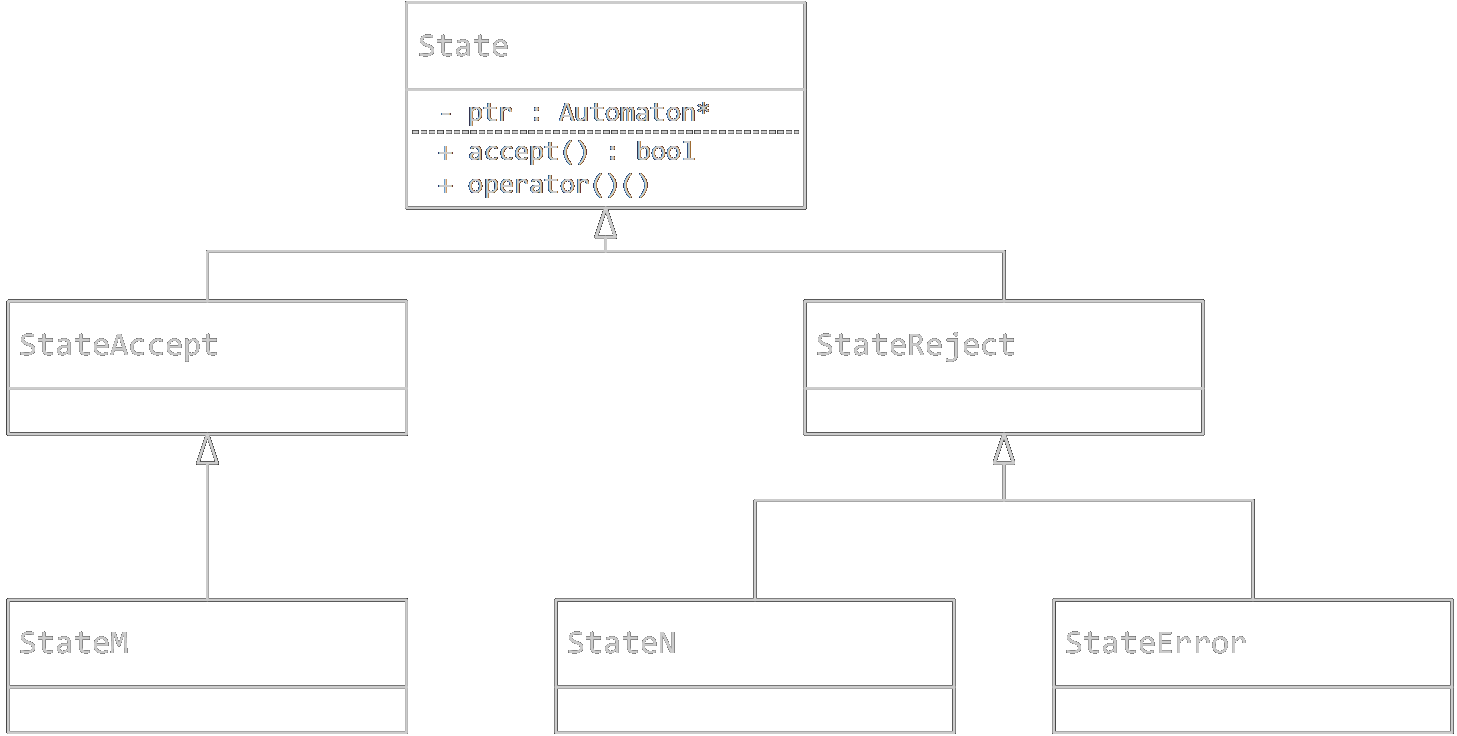
void generateCode(std::ostream& os, const std::string& name, const SimpDfa& dfa)
{
const char* indent = " ";
os << "#include <iostream>\n"
<< "\n"
<< "class " << name << "\n"
<< "{\n"
<< "public:\n"
<< indent << "~" << name << "()\n"
<< indent << "{\n"
<< indent << indent << "for (auto&& p : states)\n"
<< indent << indent << indent << "delete p;\n"
<< indent << "}\n"
<< indent << "bool operator()(const std::string& s)\n"
<< indent << "{\n"
<< indent << indent << "index = " << dfa.begin << ";\n"
<< indent << indent << "for (auto&& c : s)\n"
<< indent << indent << indent << "(*states[index])(c);\n"
<< indent << indent << "return states[index]->accept();\n"
<< indent << "}\n"
<< "private:\n"
<< indent << "struct State\n"
<< indent << "{\n"
<< indent << indent << name << "* ptr;\n"
<< indent << indent << "State(" << name << "* ptr)\n"
<< indent << indent << indent << ": ptr(ptr) { }\n"
<< indent << indent << "virtual ~State() = default;\n"
<< indent << indent << "virtual bool accept() = 0;\n"
<< indent << indent << "virtual void operator()(char) = 0;\n"
<< indent << "};\n"
<< indent << "struct StateAccept : State\n"
<< indent << "{\n"
<< indent << indent << "using State::State;\n"
<< indent << indent << "virtual ~StateAccept() override = default;\n"
<< indent << indent << "virtual bool accept() override final\n"
<< indent << indent << "{\n"
<< indent << indent << indent << "return true;\n"
<< indent << indent << "}\n"
<< indent << indent << "virtual void operator()(char) override = 0;\n"
<< indent << "};\n"
<< indent << "struct StateReject : State\n"
<< indent << "{\n"
<< indent << indent << "using State::State;\n"
<< indent << indent << "virtual ~StateReject() override = default;\n"
<< indent << indent << "virtual bool accept() override final\n"
<< indent << indent << "{\n"
<< indent << indent << indent << "return false;\n"
<< indent << indent << "}\n"
<< indent << indent << "virtual void operator()(char) override = 0;\n"
<< indent << "};\n"
<< indent << "struct StateError : StateReject\n"
<< indent << "{\n"
<< indent << indent << "using StateReject::StateReject;\n"
<< indent << indent << "virtual ~StateError() override = default;\n"
<< indent << indent << "virtual void operator()(char c) override final\n"
<< indent << indent << "{\n"
<< indent << indent << indent << ";\n"
<< indent << indent << "}\n"
<< indent << "};\n";
auto size = dfa.nodes.size();
for (decltype(size) i = 0; i != size; ++i)
{
using namespace std::string_literals;
auto& node = *dfa.nodes[i];
auto className = "State" + std::to_string(i);
auto baseName = "State"s + (node.accept ? "Accept" : "Reject");
os << indent << "struct " << className << " : " << baseName << " \n"
<< indent << "{\n"
<< indent << indent << "using " << baseName << "::" << baseName << ";\n"
<< indent << indent << "virtual ~" << className << "() override = default;\n"
<< indent << indent << "virtual void operator()(char c) override final\n"
<< indent << indent << "{\n"
<< indent << indent << indent << "switch (c)\n"
<< indent << indent << indent << "{\n";
for (auto&& kv : node.map)
os << indent << indent << indent << "case '" << kv.first << "':\n"
<< indent << indent << indent << indent << "ptr->index = " << kv.second << ";\n"
<< indent << indent << indent << indent << "break;\n";
os << indent << indent << indent << "default:\n"
<< indent << indent << indent << indent << "ptr->index = " << size << ";\n"
<< indent << indent << indent << indent << "break;\n"
<< indent << indent << indent << "}\n"
<< indent << indent << "}\n"
<< indent << "};\n";
}
os << indent << "State* states[" << size + 1 << "] = {\n";
for (decltype(size) i = 0; i != size; ++i)
os << indent << indent << "new State" << std::to_string(i) << "{this},\n";
os << indent << indent << "new StateError{this},\n"
<< indent << "};\n"
<< indent << "std::size_t index;\n"
<< "};\n"
<< "\n"
<< "int main()\n"
<< "{\n"
<< indent << "std::cout << std::boolalpha;\n"
<< indent << "Automaton a;\n"
<< indent << "std::string input;\n"
<< indent << "while (std::getline(std::cin, input))\n"
<< indent << indent << "std::cout << a(input) << std::endl;\n"
<< "}\n";
}
代碼當然不是手敲的,先在編輯器中替換,再把要更改的部分換成變數即可,
至此,從正則運算式到C++代碼的轉換終于實作了,
后記
本文介紹的演算法大多涉及比較復雜的資料結構,復雜程度重繪了我的記錄,以致于我一直在思考是不是我的想法太復雜了?其實有時想得簡單也會導致問題變得復雜,比如我一開始把子集構造演算法中狀態集合的轉移誤認為對每一個轉移求閉包而不取并集(網課沒有講清楚是一方面),然后std::map的值型別就從T變為std::vector<T>或std::set<T>,實作更加復雜,而且出現了錯誤!如果一個狀態對一個字符有多條轉移,DFA的“D”體現在哪了呢——寫一個演算法發現不對勁的時候,也許是對前導演算法的理解有誤,
最好的辦法是對每一個演算法加以嚴謹的證明,順便求出最壞和平均復雜度,然而與演算法有關的數學我都不太懂,本文也沒有那么遠大的目標,如果想了解詳情,還請參考專業資料,
以上實作還有很多改進空間,比如,NfaNode中的accept是不必要的,可以以陣列下標的形式放入Nfa中,為每個NfaNode物件節省4位元組空間,Thompson構造法的實作也可以優化,減少NFA狀態與\(\varepsilon\)轉移的數量有助于減少epsClosure的遞回深度,增加一些代碼來換取運行時性能還是值得的,只不過我又一次犯懶了,
這一套演算法的正則運算式輸入部分,或許可以稱為“前端”,可以增加對RE語法糖的支持,使演算法能處理通用的、友好的RE,這是可擴展性的體現;然而局限也十分明顯,生成代碼只能對輸入字串回答是否接受,而不能給出匹配的具體資訊,從而無法作為通用的編程工具,C++11引入了regex庫,有機會去學習學習,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/53380.html
標籤:其他