二分查找是一種高效的查找演算法,一般普通的回圈遍歷查找需要O(n)的時間復雜度,而二分查找時間復雜度則為O(logN),因為每一次都將查找范圍減半,
看看百度百科以及LeetCode官方給出的二分查找演算法的解釋:
(百度百科)
二分查找也稱折半查找(Binary Search),它是一種效率較高的查找方法,但是,折半查找要求線性表必須采用順序存盤結構,而且表中元素按關鍵字有序排
列,
(LeetCode)
二分查找也稱折半查找(Binary Search),它是一種效率較高的查找方法,前提是資料結構必須先排好序,可以在資料規模的對數時間復雜度內完成查找,但
是,二分查找要求線性表具有有隨機訪問的特點(例如陣列),也要求線性表能夠根據中間元素的特點推測它兩側元素的性質,以達到縮減問題規模的效果,
二分查找問題也是面試中經常考到的問題,雖然它的思想很簡單,但寫好二分查找演算法并不是一件容易的事情,
能夠使用二分查找有兩個前提:一是要求資料結構必須先排好序或者說是有序的(這樣可以推斷出一個元素左邊以及右邊的性質) 二是還可以隨機訪問(順序存
儲結構),
為什么需要者兩個前提呢?我們通過一個案例來看看
二分查找最經典的案例 就是給出一個升序的無重復元素的陣列,再給出一個目標值,回傳陣列中與目標值相等的
元素的索引(下標)找不到則回傳-1;看下方核心代碼:
int left = 0,right = array.length;
while(left<right){ //left 為左邊界 //right 為右邊界
mid = (left+right)/2;
if(array[mid]==target)
return mid; //找到目標索引 直接回傳
else if(array[mid]>target)
{
right = mid; //大于目標值 則搜索區間改為左半區間
}else if(array[mid]<target)
{
left = mid+1; 0 //小于目標值 則搜索區間改為右半區間
}
return -1;
}
可能很多小伙伴看到left<right會疑惑因為還見過left<=right的,這個我們留待后面討論,
這題其實就是在查找索引,假定陣列為【1,2,3,4,5,6,7】 target值為6 我們看看是如何查找的,
其實二分查找的核心就是一步一步的把查找(搜索)范圍減半,
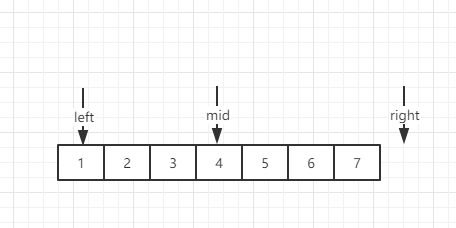
left = 0 ,right = array.length為初始化邊界,即將查找范圍鎖定為[0,array.length)注意是左閉右開;
接著我們將陣列分為兩部分,準確的說是3部分,一是 該查找范圍的中間值mid 二是mid左邊部分(姑且叫左半區間) 三是mid右邊部分(姑且叫右半區間)
然后我們來看看 mid 這個索引 對于的陣列元素與目標值的大小比較,如果相等則代表mid 就是需要查找的索引直接回傳,如果mid對應元素比目標值大,值大了
就應該縮小,所以我們將查找范圍改為mid 的左邊部分
即right = mid,如果mid對應元素比目標值小,值小了就應該放大,所以我們將查找范圍改為mid右邊部分即left = mid +1.可能有人好奇為什么left = mid+1,而right 卻直接變為mid,這個我們也留在后面討論,
一開始我們left = 0 ,right = 7.那么第一步一開始查找的值便是(0+7)/2=3,即是4 比6要小,說明目標值更大所以將查找范圍減半至更大的一部分(右邊部分),我們通過將左邊界右移至mid+1的位置來改變
邊界,此時left = 4,right是7,接著我們查找(4+7)/2 = 5 索引5 對應的是6 正好是目標值所以直接回傳了5,
為什么我們通過mid與目標值關系就可以知道查找范圍應該落在哪里呢?
就是因為陣列是已經排好序的(滿足了一個條件),那為什么我們可以知道左右區間又或者說知道了范圍可以直接訪問中間的元素呢?因為陣列是順序存盤結構可
以隨機訪問(通過下標),所以必須是
順序存盤結構,如果是鏈表沒有下標訪問是無法直接判斷中間元素與目標值關系的,這就是為什么想要二分查找必須滿足這兩個條件了,
接著我們來討論下 什么時候回圈條件是left<=right,而什么時候又是left<right,
這一個其實取決與我們定義查找范圍區間時是如何定義的,由于我們初始化left = 0,right = array.length,所以我們可以確定初始狀態的左邊界是0而右邊界是陣列長度,由于是查找索引,所以一開始的查找區間是[left,right),為左閉右開的,此時我們的回圈執行條件是left<right,回圈的終止條件是left = right ,此時
對應的區間是[left,left),該區間內已經無法再查詢了所以該回圈條件是可行的,
但當我們將right 初始化為array.length-1時,此時的查找范圍區間便是[left,right],左閉右閉,此時如果我們的回圈條件仍然是left<right,那么代表終止時left=right,對應的搜索區間是【left,left】,此時我們帶入一個具體數字如是2,則區間則為[2,2],此時區間內還有一個數2沒有查詢而回圈卻終止了(漏查,所
以是不可取的,故回圈條件的中的這個=號取決于查找區間的定義是左閉右開還是左閉右閉,
還有一個問題是當減半查找范圍時,left = mid +1,為什么right = mid又或者right = mid-1,這其實也跟查找區間有關,上面講到其實二分查找時將陣列分為三
部分,mid,mid左半區間,mid右半區間,
如果我們定義的right 為array.length,那么搜索區間是左閉右開的,我們每查找一次mid 的值后,就要對范圍做改變,因為mid已經查找過了所以我們的選擇要么左邊要么右邊,如果我們去右邊,則left 指標右移, 即left = mid +1,而要去左邊時,需要的是right指標左移,由于區間是左閉右開的,所以右邊界直接等于mid,我們也可以將三部分兩個區間直接用區間表示出來[left,mid) , [mid+1,right)這就是為什么right 直接等于mid了,
當然我們也可以將right 初始化為array.length-1,那么查找區間就是左閉右閉的 ,那三部分中里的兩個區間分別為[left,mid-1],[mid+1,right],這時我們改變查
找范圍時left = mid+1,而right = mid-1,
所以回圈條件的等號和left,right的相應變化都取決于左右邊界時的定義(取決于是左閉右倍訓是左閉右開),
另外,對于 mid = (left+right)/2, 這一式子我們可以變形優化, mid = left + (right-left)/2 防止溢位,也可以將整除2換成位運算右移一位即 mid = left = ((right-left)>>1),
這是二分查找的一種經典題型——精確查找,找到某值就直接回傳,關于精確查找的例題可以直接在leetcode里找到——704.二分查找
二分查找的應用除了精確查找還有查找左右邊界
關于查找左右邊界的定義個人見解為:
(查找左邊界)從后往前有一部分滿足條件,則前面必有一個臨界點屬于邊界,比邊界大則滿足,比邊界小則不符合,
(查找右邊界)從前往后有一部分滿足條件,則后面必有一個臨界點屬于邊界,比邊界小則滿足,比邊界大則不符合,
對于查找兩個邊界我也找了兩個題目來幫助理解
先看看查找左邊界(原題 leetcode278.第一個錯誤的版本):
剛看題目,首先暴力肯定可以,直接從頭到尾掃一次,發現是錯誤的版本直接return出來就好,
雖然不是考精確查值,但是其實這個是考二分查找的,而且極其明顯的查值左邊界的特征:從后往前有一部分滿足條件,則前面必有一個臨界點屬于邊界,比邊界大則滿足,比邊界小
則不符合,從最后往前到第一個錯誤的版本都是滿足條件的都是錯誤的版本,但是第一個錯誤的版本就是臨界點就是邊界,邊界前的版本都是正確的版本,
首先我們想想
我們想想如果第k個版本是錯誤的版本 那么很自然 它后面的所有版本 (k+1~n) 也都是錯誤的版本,但是第一個錯誤的版本卻是落在k的左邊的或者就是k,
那如果第k個版本并非錯誤的版本,那錯誤的版本會落在哪里呢?很明顯肯定是落在k的右手邊,并且第一個錯誤的版本也是在右邊,
直接看代碼更便于理解:
1 /* The isBadVersion API is defined in the parent class VersionControl. 2 boolean isBadVersion(int version); */ 3 public class Solution extends VersionControl { 4 public int firstBadVersion(int n) { 5 int left = 1; 6 int right = n; 7 //【left,right】 左閉右閉搜索區間 8 while (left <= right) { 9 int mid = left + ((right-left)>>1); 10 if (isBadVersion(mid)) { //當前版本是錯誤的版本 要找第一個錯誤的版本 搜索區間改為左半部分 11 right = mid-1; 12 } else { 13 left = mid + 1; //不是錯誤版本直接去右方找 14 } 15 } 16 return right+1; //why? 17 } 18 }
對于區間的減半方向我們已經了解了,那這題的回傳值該是什么呢?我們這樣回圈結束后,第一個錯誤的版本號是什么呢?
我們可以根據回圈內部的代碼得出我們想要的答案,因為是要第一個錯誤的版本,那么版本首先肯定是錯誤的那我們直接就將目光鎖定在

我們看到 ,mid 版本是肯定錯誤的,那我們回圈最后終止時的mid 應該就是我們要找的第一個錯誤版本號,可是我們定義的變數只有left,right兩個指標,
那我們該如何回傳mid呢?我們看到滿足條件執行的陳述句是 right = mid -1;那mid 等于什么呢?很明顯 mid = right +1; 所以我們可以直接回傳right+1;
很多人可能會疑惑,不是查詢左邊界嘛,怎么回傳是指標是right 再+1?想回傳左指標便于理解怎么辦?其實也可以,我們知道正確的回傳值是right+1,那回圈
條件是什么?是left<=right,那回圈終止時left 的值就是right+1.所以可以回傳right+1,也可直接回傳left,
看完左邊界我們繼續看看查找右邊界(特殊原因不放鏈接直接上圖):

首先單看題目,其實就是問你,給你n塊巧克力讓你切成k份并且要保證切出來的是正方形,讓我們求滿足條件下最大這個切出來的正方形的邊長是多少,
可能會有些小伙伴看不出這是個二分查找的題目,讓我們分析一下, 我們求的是滿足條件下切出來的正方形最大的邊長為多少,我們滿足的條件是什么?要切出
k塊,那其實我們想象,如果切出來的正方形的邊長越小,那是不是得到的塊數就越多呢?假設一下, 如果最大邊長是 x 那,邊長為1的正方形去切也肯定滿足吧?
那就是說我們需要查的最大邊長,其實就是滿足條件下邊長是右邊界,確定了是二分查找的題目,那我們怎么確定初始的搜索區間呢?對于左邊,題目提示了最小
可以為1,那我們就
為1,對于右邊沒有規定,那我們就直接初始化為所給出的巧克力的最大邊長就好,那現在問題就轉變到了,對于如何確定邊長x是否滿足條件我們可以通過計算最
終切出來的塊數而判
斷出來,那對于一塊巧克力,如果按照x的邊長是正方形去切,我們能得到幾塊巧克力呢?假設為6*5的巧克力去切邊長為2的正方形,正方形是特殊的長方形,他
們的面積其實都是長*寬,那我們其實可以直接通過巧克力的長寬分別除于邊長再乘起來就可以了,注意是整出,如這個例子,能切出來的巧克力塊數就是(6/2)*(5/2)=6塊,
所有的問題都解決了我們就直接上代碼吧
1 import java.util.Scanner; 2 3 public class Main { 4 5 public static void main(String[] args) { 6 Scanner in = new Scanner(System.in); 7 int left = 1; 8 int right = -1; 9 int n = in.nextInt(); 10 int k = in.nextInt(); 11 int[] h = new int[n]; 12 int[] w = new int[n]; 13 for (int i = 0; i < n; i++) { 14 h[i] = in.nextInt(); 15 w[i] = in.nextInt(); 16 right = Math.max(Math.max(h[i], w[i]), right); 17 } 18 while (left <= right) { 19 int mid = left + ((right - left) >> 1); 20 if (check(mid, h, w, k)) { 21 left = mid + 1; 22 } else 23 right = mid - 1; 24 } 25 System.out.println(right); 26 } 27 28 public static boolean check(int mid, int[] h, int[] w, int k) { 29 int cnt = 0; 30 for (int i = 0; i < h.length; i++) { 31 cnt += ((h[i] / mid) * (w[i] / mid)); 32 if (cnt >= k) 33 return true; 34 } 35 return false; 36 } 37 }
好了本篇文章到此結束了,可能并不能真的讓你攻克二分查找,但肯定會讓你更好的理解二分查找,感謝瀏覽!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/53395.html
標籤:其他