機器學習使我們能夠訓練一個可以將資料轉換為標簽的模型,從而把相似的資料映射到相似或相同的標簽,
例如,我們正在為電子郵件構建一個垃圾郵件過濾器,我們有很多電子郵件,其中一些標記為垃圾郵件,另一些標記為正常郵件(INBOX),我們可以構建一個模型,該模型學習識別垃圾郵件,被標記為垃圾郵件的郵件在某種程度上類似于已經標記為垃圾郵件的郵件,
相似性的概念對于機器學習至關重要,在現實世界中,相似性的概念與某個主題相關,它取決于我們的知識,
另一方面,數學模型定義了相似性的概念,通常,我們將資料表示為多維向量,并測量向量之間的距離,
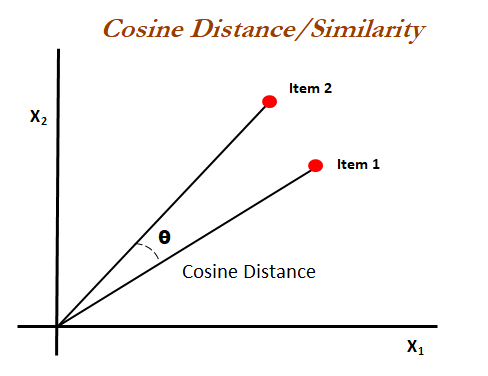
https://www.quora.com/Why-do-we-use-cosine-similarity-on-Word2Vec-instead-of-Euclidean-distance
特征工程是將我們對現實世界中的某個物件的知識轉換為數字表示的程序,我們認為相似的物件轉化為數字后的向量也會很靠近,
例如,我們正在估算房價,我們的經驗告訴我們,房屋是由臥室的數量,浴室的數量,房齡,房屋面積,位置等來定義的,位于同一社區,具有相同大小和房齡的房屋的價格應該大致相同,我們將對房屋市場的了解轉化為表征房屋的數字,并用它來估算房屋的價格,
不幸的是,如上所述,手動特征工程在將我們的知識轉換為描述性特征的能力方面存在局限性,
有時,知識的使用僅限于相似性原理,而不是物件的確切相似特征,通常,我們對現實世界的了解要比簡單的表格所代表的要復雜得多,它通常是相互聯系的概念和圖形,
嵌入模型使我們能夠獲取原始資料,并根據我們的知識自動將其轉換為特征,
Word2Vec
Word2Vec可能是最著名的嵌入模型,它為單詞建立相似度向量,在這種情況下,我們對世界的了解用文字來進行表示,即文字序列,
雖然數十年來,人們嘗試使用手動定義的特征來刻畫單詞,但收效甚微,這些解決方案通常無法擴展到全部知識,也無法在有限的情況下起作用,
托馬斯·米科洛夫(Tomas Mikolov)和他在Google的團隊決定建立模型時,一切都改變了,該模型基于眾所周知的相似性原理進行作業,在相似背景關系中使用的詞通常相似,在這種情況下,背景關系由附近的單詞來定義,
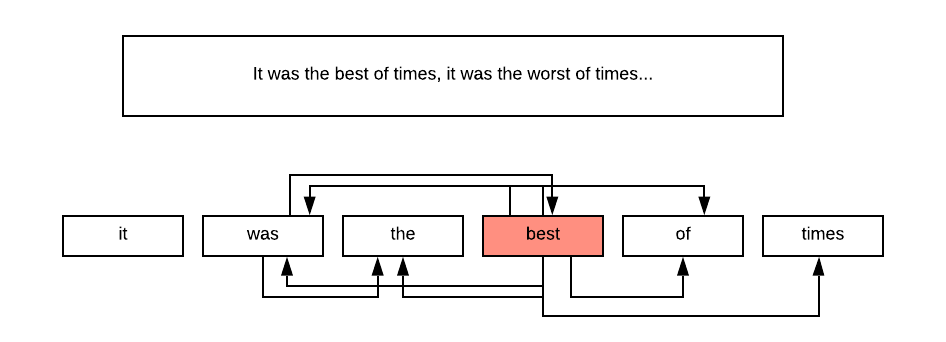
單詞序列的圖形表示,
我們看到的是,只要牢記這些原則,我們就可以通過在預定義視窗(通常為5個單詞)內將每個單詞與其相鄰單詞簡單地連接起來,從而在文本中構建圖形,
現在我們有了一個基于我們的知識連接起來的真實單詞物件的圖形,
最簡單/最復雜的單詞表示
我們仍然無法建立任何模型,因為單詞沒有以表格或向量表示,
如果我們需要將單詞轉換為數字,那么有一個簡單的解決方案,讓我們來看看字典,并為每個單詞指定其在字典中的位置,
例如,如果我有三個單詞:貓(cat),毛毛蟲(caterpillar),小貓(kitten),
我的向量表示法如下:cat—[1],caterpillar—[2],和kitten—[3],
不幸的是,這不起作用,通過這樣分配數字,我們隱式地引入了單詞之間的距離,貓和毛毛蟲之間的距離是1,貓和小貓之間的距離是2,這樣進行表示就等于,我們說貓比起小貓更像毛毛蟲,這與我們的知識是相互矛盾的,
另外一個解決方案也稱為獨熱編碼(one-hot encoding):
cat — [1,0,0]
caterpillar — [0,1,0]
kitten — [0,0,1]
該方法表示所有單詞都彼此正交,我們沒有單詞相似性的先入觀念,我們將依靠我們的知識圖譜(如上所述)和的單詞相似性原理來構建嵌入模型,
在現實世界中,字典的大小遠遠大于3,字典的維數可能是數萬到數百萬,這些向量不僅不能真正代表我們的相似性概念,而且它們的體積也很大,無法在實際中使用,
建立詞嵌入(word embeddings)
我們的知識圖譜為我們提供了非常多的邊,每條邊都可以解釋成輸入資料作為邊的起點,標簽為邊的終點,我們正在構建一個模型,該模型試圖使用被標簽包圍的單詞來預測單詞,通常以兩種方式完成,我們要么從某個單詞的所有鄰居來構造單詞向量,要么從某個單詞來構造其所有鄰居,
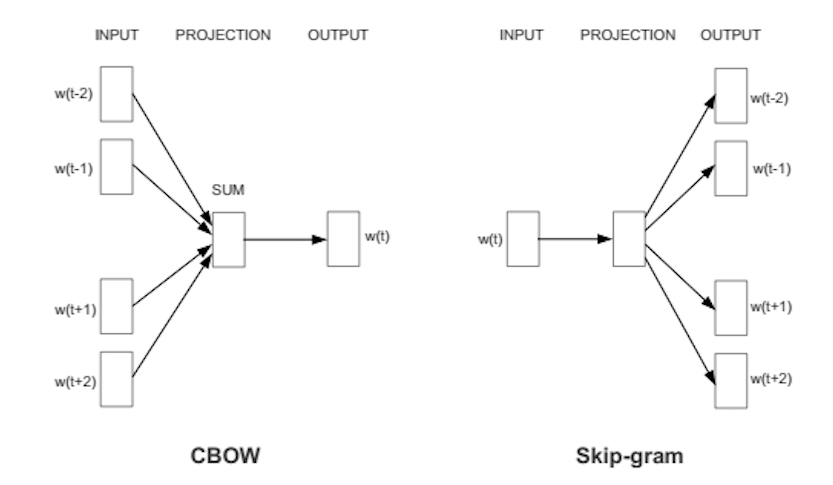 https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf
https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf
該模型的詳細資訊超出我要講的范圍,并且在許多其他文章中都有詳細描述,從根本上講,該團隊使用基本的編碼器/解碼器模型來學習從高維空間(數百萬個維)到有限維空間(通常為300個)到高維空間的投影,訓練的目的是在壓縮程序中保留盡可能多的資訊(用最小化交叉熵的方法),
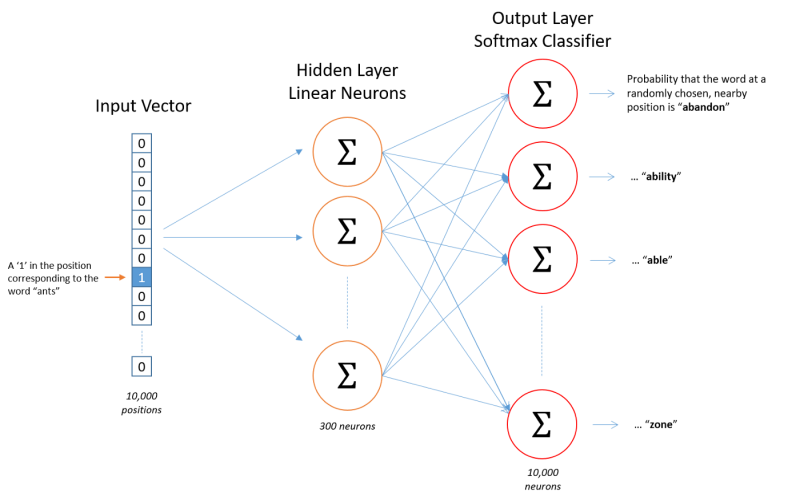
http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
把稀疏,正交,高維的資料空間投影到更密集的低維空間,這一概念是許多其他嵌入訓練模型的基礎,
該模型通常使用Google,Twitter或Wikipedia資料集等來進行訓練,我們消耗世界的知識,以此建立我們的單詞嵌入模型,
Word2Vec嵌入的屬性
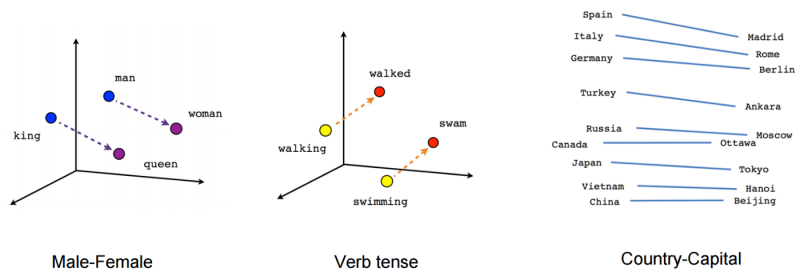
Word2Vec的重要屬性是保留單詞之間的關系和表示結構關系,
下圖顯示了國家與首都之間的聯系,
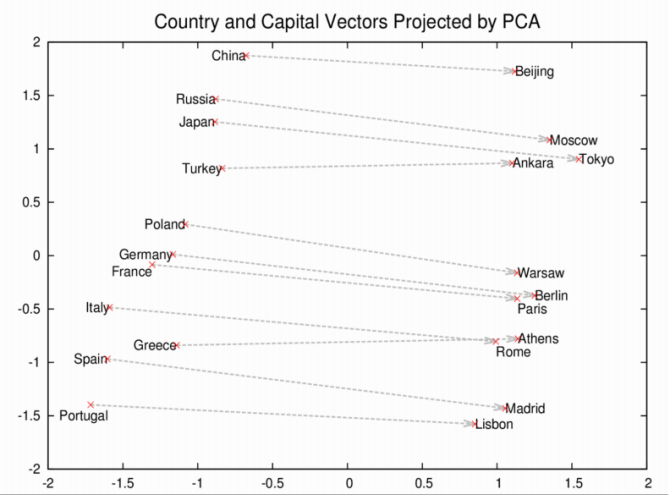 或其他不同的概念,
或其他不同的概念,
https://www.tensorflow.org/tutorials/representation/word2vec
本質上,它允許像這樣對單詞進行代數運算:
國王-男人+女人=女王,
使用單詞嵌入
單詞嵌入可以極大地改善諸如文本分類,命名物體識別,機器翻譯等等任務的執行效果,
更多資訊:http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
Node2Vec
Node2Vec(作者:A. Grover and J. Leskovec)是在Word2Vec思想的基礎上,對齊次加權圖進行分析,本文的思想是通過探索圖節點的周圍環境來刻畫圖節點的特征,我們對世界的理解是建立在兩個原則的基礎上的——同質和結構對等,
同質
相似的節點位于附近,
示例:
社交網路-我們與像我們這樣的人有更多的聯系
商業地點-金融公司、醫生辦公室或營銷公司似乎通常位于同一條街上
組織結構-同一團隊的人有相似的特征
結構對等
不同的社區共享相同的結構:
- 組織結構-雖然團隊之間可能存在弱連接,但團隊的結構(經理、高級成員、新成員、初級成員)在團隊之間重復,
https://arxiv.org/pdf/1607.00653.pdf
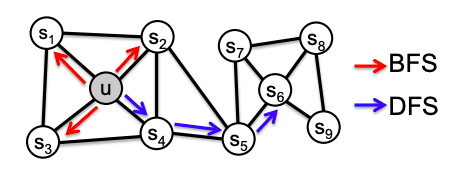
為了將這兩個原則結合到我們的嵌入中,Node2Vec的作者提出了一種結合廣度優先采樣和深度優先采樣的隨機游走方法來捕獲同質性和結構等價性,
如我們所見,節點(u)在組(s1、s2、s3、s4)中充當中心,這類似于s6是(s7、s5、s8、s9)的中心,我們通過BFS發現(s1,s2,s3,s4)社區,通過DFS發現(u)<->(s6)相似性,
我們通過探索每個節點的周圍環境來了解它們,這種探索將圖轉換為隨機游動產生的大量序列(句子),將BFS和DFS探索結合起來,BFS和DFS的混合由圖邊的權值和模型的超引數控制,
一旦我們有了完整的序列(句子),我們就可以像應用于文本一樣應用Word2Vec方法,它產生了基于我們定義的原則和從圖中獲得的知識的圖節點嵌入,
Node2Vec 性質
Node2Vec表示改進了節點的聚類和分類模型,嵌入中學習到的相似性將有助于欺詐檢測等任務,
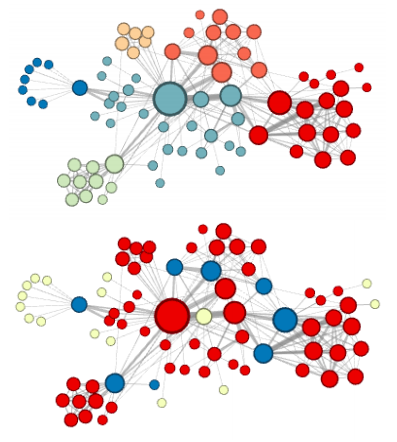
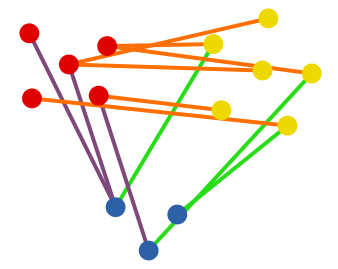
node2vec生成的Les Misérables共現網路的互補可視化,標簽顏色反映了同質(頂部)和結構等價性(底部),— https://arxiv.org/pdf/1607.00653.pdf
https://arxiv.org/pdf/1607.00653.pdf
Node2Vec在鏈路預測(link prediction)方面有顯著的改進,它能夠提高重建圖的能力,其中洗掉了一定比率的邊,本文將進一步討論鏈路預測評估程序,
知識圖譜
下面我們將討論PYTORCH-BIGGRAPH:一個大規模的圖嵌入系統論文(進一步命名為PBG)以及相關論文,
知識圖譜是一種特殊的圖形型別,它包含已知的物體和不同型別的邊,它代表結構知識,
在知識圖譜中,節點通過不同型別的關系連接起來,
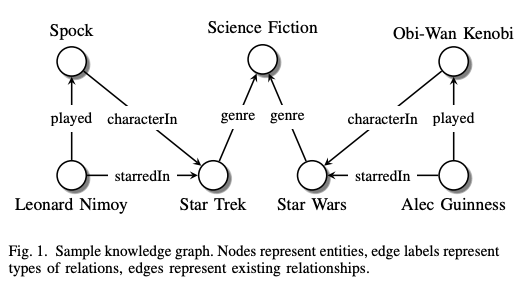
https://arxiv.org/pdf/1503.00759.pdf
訓練的目標是產生代表知識的嵌入,一旦我們有了節點的嵌入,就應該很容易通過特定型別的關系來確定相應的節點在我們的知識圖譜中是否是連接的(或應該連接的),
不同的模型提出了不同的比較嵌入的方法,最簡單的模型使用余弦或向量積距離來比較嵌入向量,比較復雜的模型在比較之前對向量的元素應用不同的加權方案,加權方案表示為矩陣,并且特定于關系型別,作為訓練的一部分,我們可以學習加權矩陣,
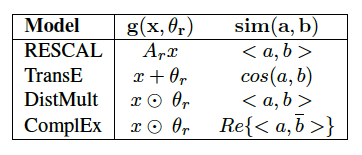
https://www.sysml.cc/doc/2019/71.pdf
我們需要找到一種方法來度量邊之間的相似性得分,并使用該得分來估計這些節點連接的可能性,
知識圖譜的表示
知識圖譜可以表示為鄰接張量,要建立它,我們需要一個平方矩陣來表示每種型別的關系,每個矩陣的列或行數與圖形中的節點數相同,通過這種型別的關系,如果這些節點中相互連接,則矩陣的值將是1,否則為0,很明顯,這個矩陣非常大,非常稀疏,
為了學習我們的嵌入,我們需要將每個節點轉換成固定大小的向量,讓我們討論“好”嵌入的性質,
好的嵌入以圖邊的形式表示我們的知識,位于“附近”的嵌入向量應該表示更有可能連接的節點,基于此觀察,我們將訓練我們的模型,使相鄰張量中標記為1的連接節點的相似度得分更高,相鄰張量中標記為0的連接節點的相似度得分更低,
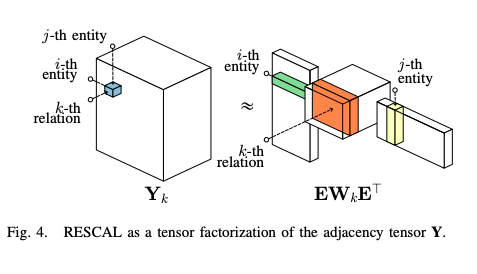 https://arxiv.org/pdf/1503.00759.pdf
https://arxiv.org/pdf/1503.00759.pdf
我們正在訓練我們的嵌入以最小的資訊損失從節點嵌入重建 知識圖譜的邊,
負采樣
我們的訓練方法有點問題,我們正在嘗試使用圖資料來區分1(節點已連接)和0(節點未連接),然而,我們實際擁有的唯一資料是連接在一起的節點,就像只看貓就學會了分辨貓和狗,
負采樣是一種通過使用非常簡單的觀測來擴展資料集并提供更好的訓練資料的技術,任何隨機選擇的節點,如果沒有作為我們的圖的一部分進行連接,將用標簽0表示一個樣本資料,出于訓練的目的,PBG提出讀取圖的每條邊,然后提出一個負樣本,其中一個節點被隨機選擇的節點替換,
對于每一條邊,我們可以指定一個正相似度得分和一個負相似度得分,基于節點嵌入和邊關系型別權重計算正相似度得分,用同樣的方法計算負相似度得分,但是邊的一個節點被損壞并被隨機節點替換,
排名損失函式,將在訓練期間進行優化,它的構造是為了在圖中所有節點和所有關系型別的正負相似度得分之間建立一個可配置的邊距(margin),排名損失是節點嵌入和特定關系權重的函式,通過尋找最小的排名損失進行學習,
訓練
現在我們有了訓練嵌入模型所需的一切:
資料-負邊和正邊
標簽-(1或0)
優化函式(可以是排名損失、更傳統的logistic回歸損失或在word2vec中使用的交叉熵softmax損失)
我們的引數是用于相似性評分函式的嵌入和權重矩陣,
現在是用微積分來尋找引數-嵌入的問題,優化我們的損失函式,
隨機梯度下降
隨機梯度下降的實質是逐步調整損失函式的引數,使損失函式逐漸減小,為此,我們以小批量方式讀取資料,使用每個批次計算對損失函式引數的更新,以將其最小化,
隨機梯度下降有多種方法,PBG論文利用隨機梯度下降的一種形式ADAGrad來尋找使損失函式最小化的引數,我強烈推薦這個博客來了解梯度下降的所有型別:http://ruder.io/optimization-gradient-descent/index.html#adagrad
tensorflow和Pythorch等軟體包為不同的型別提供了開箱即用的實作,
梯度下降的關鍵是模型引數的多次更新,直到損失函式最小化,在訓練結束時,我們期望能有嵌入和評分函式,以滿足我們整合知識的目標,
HogWild-分布式隨機梯度下降
隨機梯度下降的分布式是一個挑戰,如果我們同時通過調整引數來訓練以最小化損失函式,就需要某種鎖定機制,在傳統的多執行緒開發中,我們在更新程序中通過悲觀或樂觀鎖定來鎖定資料,鎖定會減慢進度,但會確保結果的正確性,
幸運的是, hogwild paper 證明了我們不需要鎖定機制,我們可以簡單地批量讀取資料,計算引數調整,并將這些資料保存在共享引數空間中,而不考慮其正確性,HogWild演算法正是這樣做的,訓練可以是分布式的,每個HogWild執行緒可以更新我們的引數,而不考慮其他執行緒,
我推薦這個博客來獲取更多關于HogWild的資訊: https://medium.com/@krishna_srd/parallel-machine-learning-with-hogwild-f945ad7e48a4
分布式訓練
當圖跨越數十億個節點和數萬億條邊時,很難在一臺機器的記憶體中擬合所有引數,如果我們在開始另一批之前等待每一批的結束來完成計算,也需要很多時間,我們的圖是如此之大,這將有利于能夠同時進行并行化的訓練和引數學習,這個問題是由Facebook團隊解決的,他們發布了PBG的論文,
節點按物體型別拆分,然后組織為磁區:
https://torchbiggraph.readthedocs.io/en/latest/data_model.html
 https://torchbiggraph.readthedocs.io/en/latest/data_model.html
https://torchbiggraph.readthedocs.io/en/latest/data_model.html
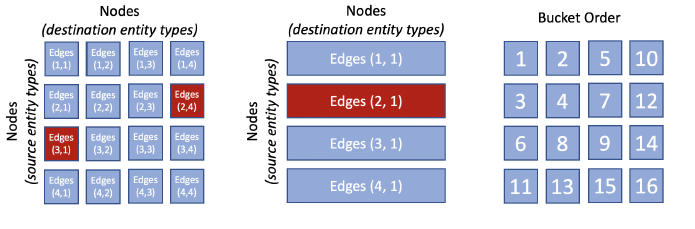
https://www.sysml.cc/doc/2019/71.pdf
節點被劃分為P個bucket,邊被劃分為PxP個bucket,不必對基數較小的物體型別進行磁區,
訓練與下列限制同時進行:
對于除第一個外的每個邊 bucket(p1;p2),在前一個迭代中訓練邊 bucket(p1;*)或(*;p2)是很重要的,
只要多個邊 buckets 在不相交的磁區集上操作,它們可以并行訓練,
https://www.sysml.cc/doc/2019/71.pdf
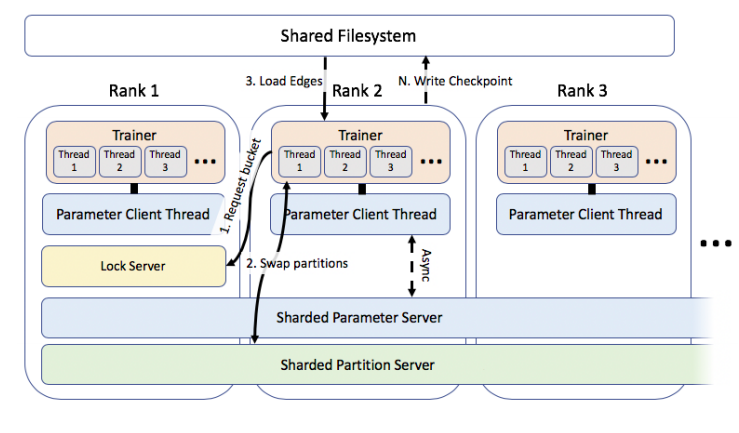
訓練在多臺機器上并行進行,并且每臺機器有多個執行緒,每個執行緒根據分配的bucket和批資料計算引數更新,鎖服務器根據建立的約束分發訓練 buckets,注意,鎖服務器只控制hogwild執行緒中批資料的分布,而不控制引數更新,
PBG嵌入特性
知識嵌入可以通過兩種方式使用:
- 鏈接預測,
? 鏈接預測有助于通過查找可能連接或即將連接的節點來填補我們知識中的空白,
? 示例:該圖表示客戶和客戶購買的產品,邊是采購訂單,嵌入可用于形成下一個購買建議,
- 學習節點的屬性
? 嵌入可以用作特征向量作為各種分類模型的輸入,所學的類可以填補我們對物件屬性的知識空白,
使用MRR/Hits10評估鏈路預測
這篇論文Learning Structured Embeddings of Knowledge Bases描述了這個程序,后來被用作衡量嵌入模型質量的方法,在包括Facebook PBG在內的許多其他論文上都有報道,
演算法獲取測驗邊的子集并執行以下操作:
通過將邊的開始或結束替換為負采樣邊來損壞邊,
在部分損壞的資料集上訓練模型
計算測驗資料集邊的聚合MRR和Hits10度量,
平均倒數排序(Mean reciprocal rank)
MRR或Mean reciprocal rank是衡量搜索質量的指標,我們選取一個未損壞的節點,以距離作為相似度得分來尋找“最近鄰”,我們根據相似度得分對最近的鄰居進行排序,并期望連接的節點出現在排序的頂部,MRR會在節點沒有傾斜到頂部的情況下降低精度得分,
另一種方法是Hits10,我們期望損壞的節點出現在前10個最近的鄰居中,
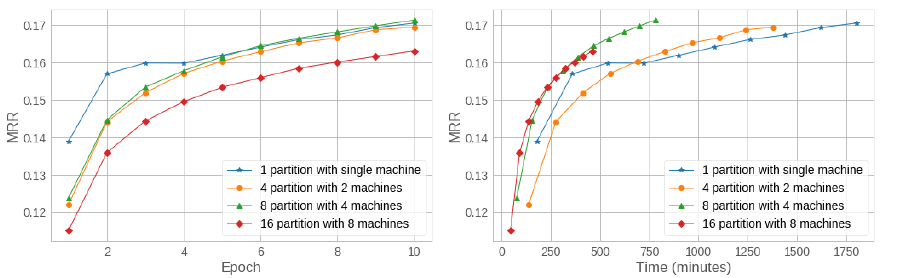
https://www.sysml.cc/doc/2019/71.pdf
PBG的研究表明,在許多資料集上,MRR指標隨著我們將資源分配到訓練中而逐漸增加,并行性不會影響排名質量,但可以節省大量時間,
可以通過簡單地探索和可視化圖來執行進一步的評估,
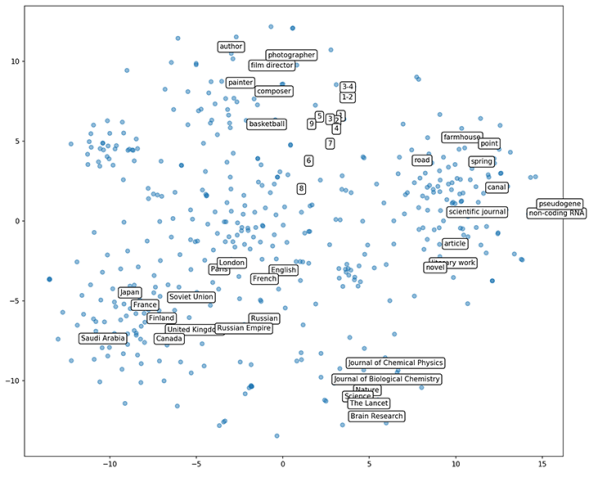
https://ai.facebook.com/blog/open-sourcing-pytorch-biggraph-for-faster-embeddings-of-extremely-large-graphs/
上面的影像是根據Freebase知識圖譜構建的嵌入的二維投影,如我們所見,相似的節點被組合在一起,即使在精心準備的二維投影圖上,國家、數字、科學期刊行業似乎也有集群,
知識圖譜模型的局限性
如上所述的知識圖譜表示的是我們知識的靜態快照,它并不能反映知識是如何建立起來的,在現實世界中,我們通過觀察時間模式來學習,雖然可以學習節點A和節點B之間的相似性,但就像3年前一樣,很難看到節點A和節點C之間的相似性,
例如,如果我們看一天森林,我們會看到兩棵大紅杉之間的相似性,然而,如果沒有對這片森林的長期觀察,很難理解哪棵小樹會長成一棵大紅杉樹,
理想情況下,我們需要探索在不同時間點構建的一系列知識圖譜,然后構建嵌入,這將包含代與代之間的相似性,
原文鏈接:https://towardsdatascience.com/extracting-knowledge-from-knowledge-graphs-e5521e4861a0
歡迎關注磐創AI博客站: http://panchuang.net/
sklearn機器學習中文官方檔案: http://sklearn123.com/
歡迎關注磐創博客資源匯總站: http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/5340.html
標籤:其他
上一篇:BERT生成文本摘要