本文首發于 微信公眾號:隱語的小劇場
一、“隱語”架構設計全貌
1.隱語框架設計思想
隱私計算是一個新興的跨學科領域,涉及密碼學、機器學習、資料庫、硬體等多個領域,根據過去幾年的實踐經驗,我們發現
- 隱私計算技術方向多樣,不同場景下有其各自更為合適的技術解決方案
- 隱私計算學習曲線很高,非隱私計算背景的用戶使用困難
- 隱私計算涉及領域眾多,需要領域專家共同協作
隱語的設計目標是使得資料科學家和機器學習開發者可以非常容易地使用隱私計算技術進行資料分析和機器學習建模,而無需了解底層技術細節,
為達到這個目標,隱語提供了一層設備抽象,將多方安全計算(MPC)、同態加密(HE)和可信執行環境(TEE)等隱私計算技術抽象為密文設備, 將單方計算抽象為明文設備,
基于這層抽象,資料分析和機器學習作業流可以表示為一張計算圖,其中節點表示某個設備上的計算,邊表示設備之間的資料流動,不同型別設備之間的資料流動會自動進行協議轉換,在這一點上,隱語借鑒了主流的深度學習框架,后者將神經網路表示為一張由設備上的算子和設備間的張量流動構成的計算圖, 隱語框架圍繞開放這一核心思想,提供了不同層次的設計抽象,希望為不同型別的開發者都提供良好的開發體驗,
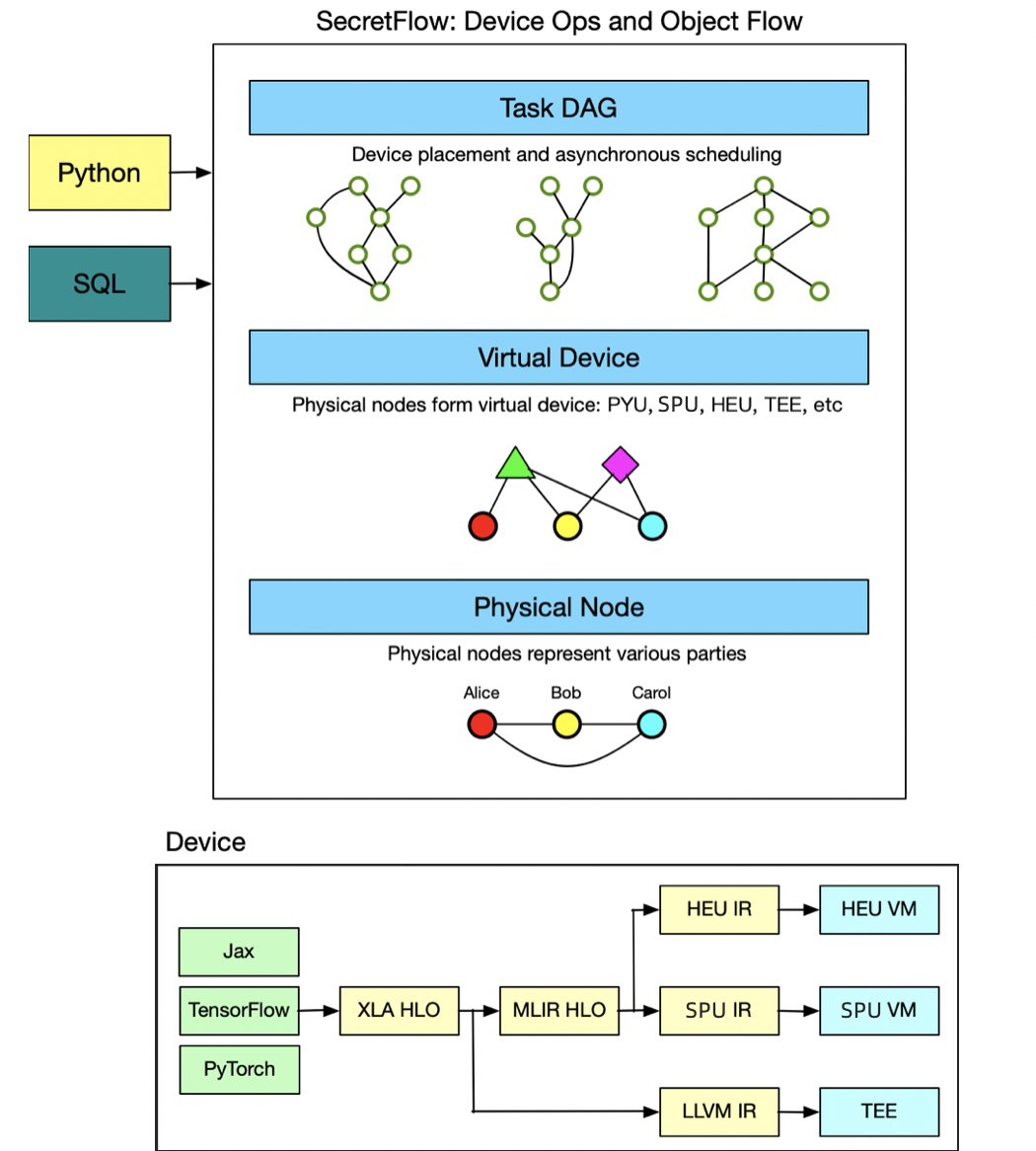
在設備層,隱語提供了良好的設備介面和協議介面,支持更多的設備和協議插拔式的接入,我們希望與密碼學、可信硬體、硬體加速等領域專家通力合作,不斷擴展密態計算的型別和功能,不斷提升協議的安全性和計算性能,
同時,隱語提供了良好的設備介面,第三方隱私計算協議可作為設備插拔式接入,在演算法層,為機器學習提供了靈活的編程介面,演算法開發者可以很容易定義自己的演算法,
2.架構分層總覽
隱語總體架構自底向上一共分為五層:
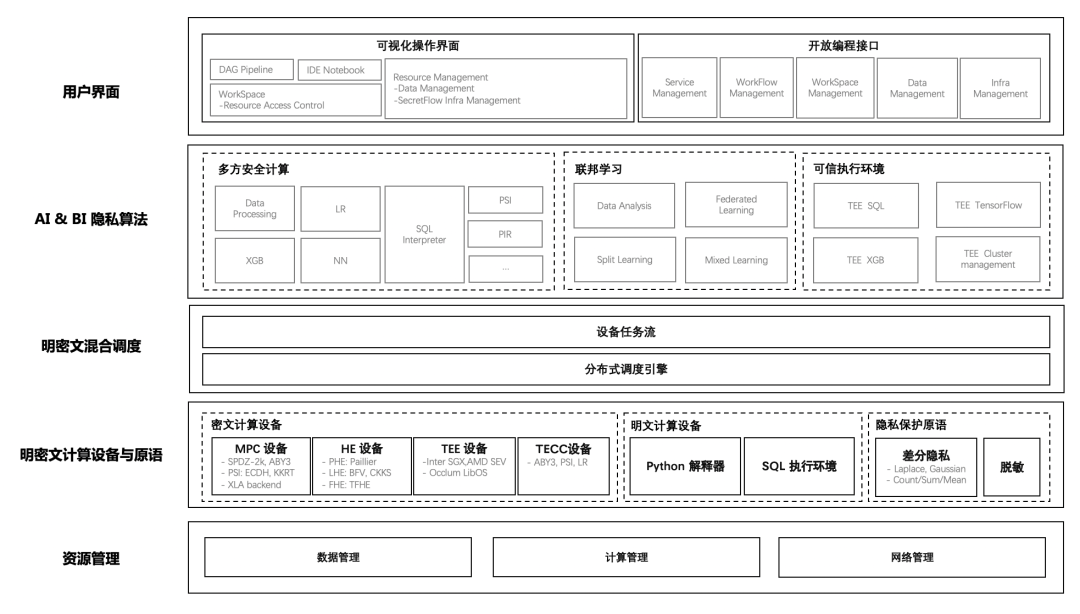
- 資源管理層:主要承擔了兩方面的職責,第一是面向業務交付團隊,可以屏蔽不同機構底層基礎設施的差異,降低業務交付團隊的部署運維成本,另一方面,通過對不同機構的資源進行集中式管理,構建出一個高效協作的資料協同網路,
- 明密文計算設備與原語層:提供了統一的可編程設備抽象,將多方安全計算(MPC)、同態加密(HE)、可信硬體(TEE)等隱私計算技術抽象為密態設備,將單方本地計算抽象為明文設備,同時,提供了一些不適合作為設備抽象的基礎演算法,如差分隱私(DP)、安全聚合(Secure Aggregation)等,
- 明密文混合調度層:提供了統一的設備調度抽象,將上層演算法描述為一張有向無環圖,其中節點表示某個設備上的計算,邊表示設備之間的資料流動,即邏輯計算圖,邏輯計算圖由分布式框架進一步拆分并調度至物理節點,
- AI & BI 隱私演算法層:這一層的目的是屏蔽掉隱私計算技術細節,但保留隱私計算的概念,其目的是降低隱私計算演算法的開發門檻,提升開發效率,有隱私計算演算法開發訴求的同學,可以根據自身場景和業務的特點,設計出一些特化的隱私計算演算法,來滿足自身業務和場景對安全性、計算性能和計算精度的平衡,在這一層上,隱語本身也會提供一些通用的演算法能力,比如MPC的LR/XGB/NN,聯邦學習演算法,SQL能力等,
- 用戶界面層:隱語的目標并不是做一個端到端的產品,而是為了讓不同的業務都能夠通過快速集成隱語而具備全面的隱私計算能力,因此我們會在最上層去提供一層比較薄的產品API,以及一些SDK,去降低業務方集成隱語的成本,
3.架構細節拆解
設備與原語層
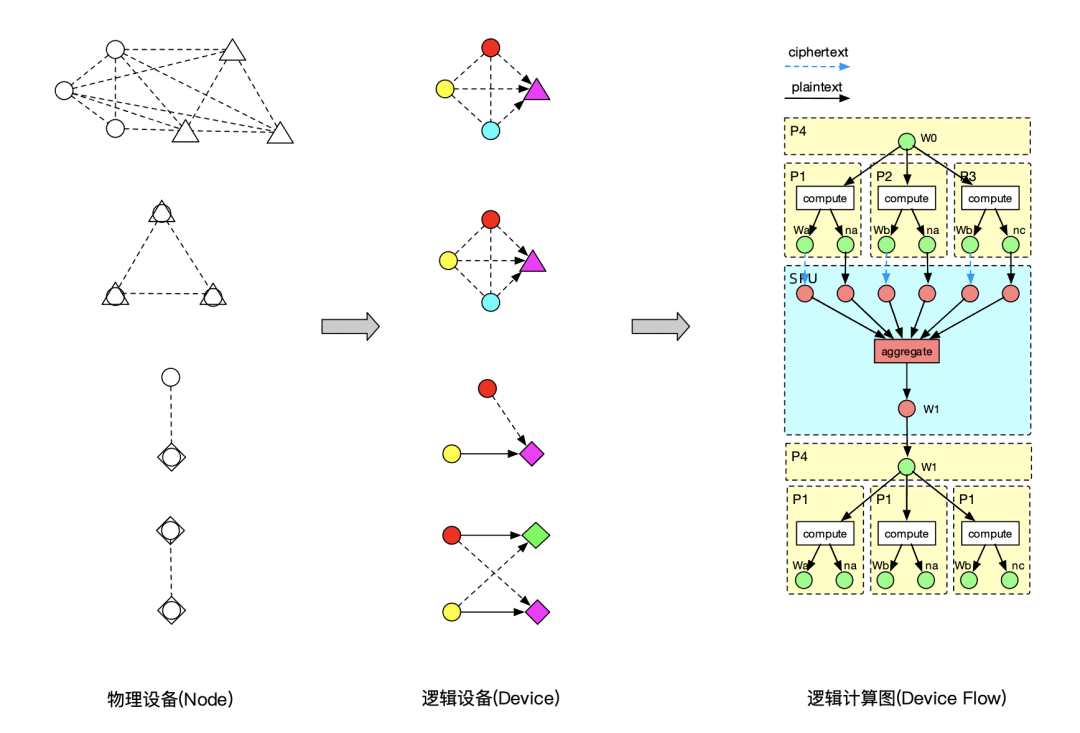
隱語的設備分為物理設備和邏輯設備,其中,物理設備是隱私計算各個參與方的物理機器,邏輯設備則由一個或多個物理設備構成,邏輯設備支持一組 特定的計算算子(Device Ops),有自己特定的資料表示(Device Object),邏輯設備分為明文和密文兩種型別,前者執行單方本地計算,后者執行多方參與的隱私計算,
邏輯設備的運行時負責記憶體管理、資料傳輸、算子調度等職責,運行在一個或多個物理設備上,邏輯設備和物理設備不是一對一的關系,一個物理設備可能同時屬于多個邏輯設備,在同一組物理設備上,可以根據不同的隱私協議和參與組合虛擬出不同的邏輯設備,
下表是隱語目前暫定支持的設備串列:
|
設備 |
型別 |
運行時 |
算子 |
協議 |
前端 |
狀態 |
|
PYU |
明文 |
Python Interpreter |
— |
— |
Python |
Release |
|
SPU |
密文 |
SPU VM |
PSI, XLA HLO |
SPDZ-2k, ABY3 |
JAX, TensorFlow, PyTorch |
Alpha |
|
HEU |
密文 |
HEU Runtime |
Add, XLA HLO |
Paillier, OU, TFHE |
Numpy, JAX |
Alpha |
|
TEE |
密文 |
TEE Runtime |
XLA HLO |
Intel SGX |
JAX, TensorFlow, PyTorch |
WIP |
可編程性
邏輯設備具備可編程性,即用戶可以在設備上自定義計算邏輯,每個設備對用戶提供了協議無關的編程介面,在一個設備上,用戶可以定義從簡單的矩陣運算, 到完整的深度模型訓練,當然,這一切取決于設備提供的計算能力,
對于明文設備PYU,它的前端為python,用戶可以通過@device將一段預定義python函式調度至其上執行,
對于密文設備SPU、HEU、TEE,它們的前端可以是任何支持XLA 的框架, 如JAX, TensorFlow,PyTorch等,同樣的,用戶也可以通過@device將基于這些前端自定義的函式調度至指定的設備執行,
1 import jax.numpy as jnp 2 3 dev = Device() # maybe PYU, SPU, HEU, TEE 4 5 @device(dev) 6 def selu(x, alpha=1.67, lmbda=1.05): 7 return lmbda * jnp.where(x > 0, x, alpha * jnp.exp(x) - alpha) 8 9 res = selu(x) # res is a DeviceObject
用戶自定義函式首先轉換成XLA HLO Computation,由XLA進行設備無關的代碼優化和分析,并發往后端設備,后端設備進一步執行代碼優化和分析,并生成最終 的可執行代碼,可執行代碼或由設備的虛擬機解釋執行(SPU, HEU),或由硬體直接執行(TEE),使用XLA HLO作為IR,使得我們可以復用XLA前端和設備無關 代碼優化,同時使得后端實作更加簡潔干凈,
對于密文設備(半同態)HEU,它僅支持一組有限的計算,因此提供了一組預定義算子如__add__, __mul__等,用戶不能通過@device進行自定義編程,
1 x, y = HEUObject(), PYUObject() 2 z = x + y # add 3 z = x * y # mul 4 z = x @ y # matmul協議轉換
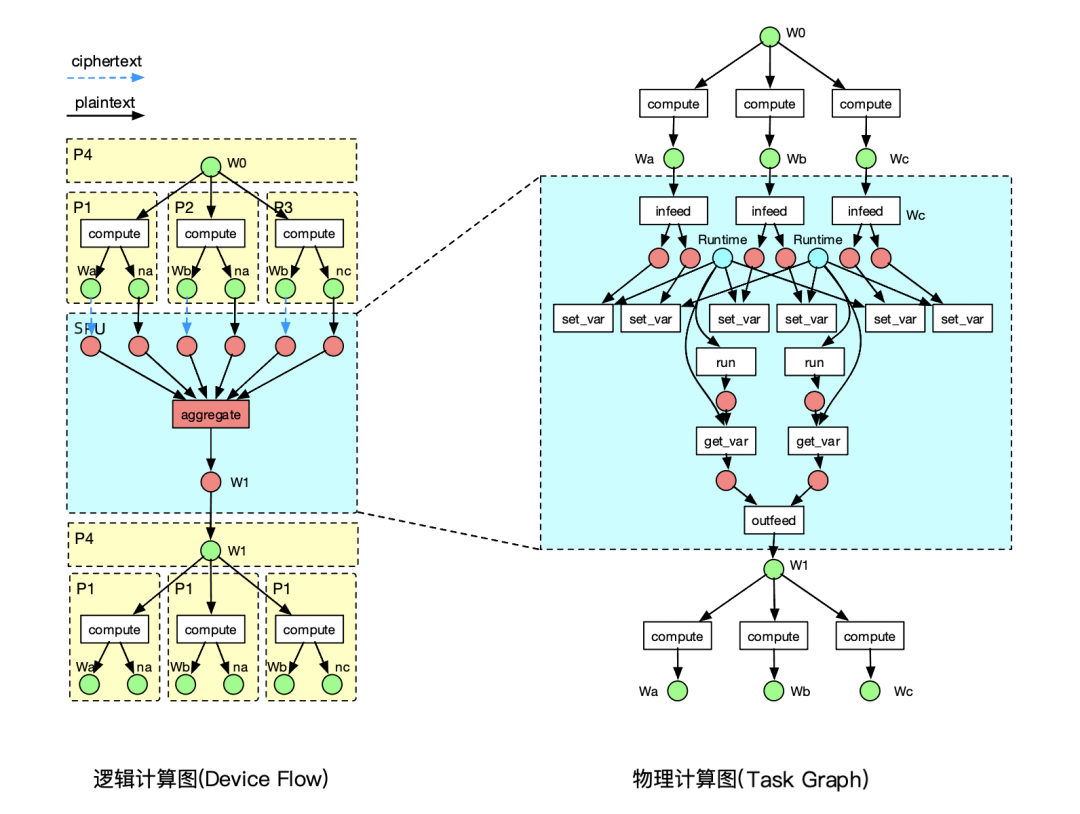
用戶在邏輯設備上進行編程,構建邏輯計算圖,其節點表示設備上的一段函式或算子,邊表示設備物件的流動,邏輯計算圖被設備進一步分割為子圖,兩個子圖間的 邊表示跨設備的物件流動,此時需要進行協議轉換,設備物件的DeviceObject.to介面用于轉換至目標設備物件,任何新增的設備都應該提供相應的轉換函式并 插入物件轉換表中,
下表是各個邏輯設備物件的轉換表:
| PYU | SPU | HEU | TEE | |
| PYU | share | encrypt | encrypt | |
| SPU | reconstruct | encrypt+add | reconstruct+encrypt | |
| HEU | decrypt | minus+decrypt | decrypt+encrypt | |
| TEE | decrypt | decrypt+share | decrypt+encrypt |
用戶基于設備構建了一張邏輯計算圖,那么我們如何執行這張計算圖?由于邏輯設備映射到一個或多個物理設備,因此我們需要將邏輯設備上的算子正確調度到其對應的物理設備,同時處理好這些物理設備間的資料傳輸關系,毫無疑問,我們需要一個分布式圖執行引擎來解決這些問題,
那么我們需要一個怎樣的分布式圖執行引擎?以下是隱語對它的要求
-
細粒度的異構計算:在一張邏輯計算圖中,具有不同粒度的計算任務,既有簡單的資料處理(秒級),也有復雜的多方訓練(幾個小時至幾十小時),同時,物理節點具有不同的硬體環境,CPU, GPU, TEE, FPGA等,
-
靈活的計算模型:在水平、垂直場景下,針對資料處理和模型訓練等不同作業流,支持多種并行模型,如資料并行、模型并行、混合并行,
-
動態執行:在聯邦學習場景下,不同機構的資料規模、帶寬延遲、機器性能可能有較大差異,這導致同步模式的效率受限于最慢的作業節點,因此,我們希望支持 異步訓練模式,這要求圖執行引擎具有動態執行能力,
隱語針對隱私計算場景,已經對框架進行了一些安全加固作業:通過身份認證、代碼預裝、代碼存證等手段對框架做了整體加固,未來,還將探索沙箱隔離、訪問控制、靜態圖等機制以進一步提升安全水位,在環境適配方面,為了適配跨機構網路通信的特點,推進了GCS gRPC通信、域名支持、弱網斷線處理等相關功能的開發,
AI & BI 隱私演算法這一層的目的是其目的是降低隱私計算演算法的開發門檻,提升開發效率,有隱私計算演算法開發訴求的同學,可以根據自身場景和業務的特點,設計出一些特化的隱私計算演算法,來滿足自身業務和場景對安全性、計算性能和計算精度的平衡,在這一層上,隱語本身也會提供一些通用的演算法能力,比如MPC的LR/XGB/NN,聯邦學習演算法,SQL能力等,
二、使用“隱語”框架構建隱私計算演算法
邏輯設備抽象為演算法開發者提供了極大的靈活性,他們可以像積木一樣自由組合這些設備,在設備上自定義計算,從而構建自己的隱私計算演算法,接下來,我們通過一個具體的演算法來展示隱語框架的通用編程能力,
聯邦學習演算法
聯邦機器學習又名聯邦學習,聯合學習,聯盟學習,是一種機器學習框架,能有效幫助多個機構在滿足用戶隱私保護、資料安全和政府法規的要求下,進行資料使用和機器學習建模,
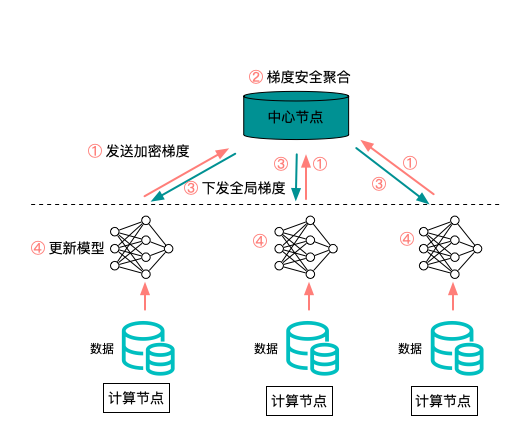
聯邦學習的演算法流程如上圖所示,大致分為以下四個步驟
- 機構節點在本地進行多輪訓練,得到模型引數
- 機構節點使用加密協議,將模型引數上傳至聚合節點
- 聚合節點使用加密協議,對模型引數進行聚合,得到全域模型
- 機構節點從聚合節點獲取最新的全域模型,進入下一輪訓練
節點本地訓練
機構節點運行在機構本地,隱語提供了一個邏輯設備PYU,執行本地的明文計算,下面的BaseTFModel定義了本地模型訓練邏輯,用戶可以選擇自己喜好的機器學習框架,如TensorFlow, PyTorch等,隱語提供了@proxy裝飾器,對一個普通的類進行了初始設定,以便后續在邏輯設備上對其實體化,@proxy(PYUObject)表明該類需要在PYU設備上實體化,
1 @proxy(PYUObject) 2 class BaseTFModel: 3 def train_step(self, weights, cur_steps, train_steps) -> Tuple[np.ndarray, int]: 4 self.model.set_weights(weights) 5 num_sample = 0 6 for _ in range(train_steps): 7 x, y = next(self.train_set) 8 num_sample += x.shape[0] 9 self.model.fit(x, y) 10 11 return self.model.get_weights(), num_sample
模型安全聚合
模型聚合對各個機構節點的模型引數進行加權平均,如下面_average所示,隱語邏輯設備的最大特點在于可編程性,用戶可以將一段函式調度到多種設備執行,以達到使用不同隱私計算技術的目的,目前,DeviceAggregator可以支持PYU明文聚合,也可以支持SPU MPC協議聚合,后續我們還將支持TEE, HEU等多種密文設備,
1 @dataclass 2 class DeviceAggregator(Aggregator): 3 device: Union[PYU, SPU] 4 5 def average(self, data: List[DeviceObject], axis=0, weights=None): 6 # 2. 機構節點使用加密協議,將模型引數上傳至聚合節點 7 data = https://www.cnblogs.com/secretflow/p/[d.to(self.device) for d in data] 8 if isinstance(weights, (list, tuple)): 9 weights = [w.to(self.device) if isinstance(w, DeviceObject) else w for w in weights] 10 11 def _average(data, axis, weights): 12 return [jnp.average(element, axis=axis, weights=weights) for element in zip(*data)] 13 14 # 3. 聚合節點使用加密協議,對模型引數進行聚合,得到全域模型 15 return self.device(_average, static_argnames='axis')(data, axis=axis, weights=weights)
訓練流程整合
有了節點本地訓練、模型安全聚合,我們就可以將其整合起來形成完整的訓練流程,首先,我們在每個PYU設備(代表機構節點)創建BaseTFModel實體,同時,初始化聚合器,可以是PYU, SPU, TEE, Secure Aggregation,然后,按照上述描述的聯邦學習演算法流程進行迭代訓練,
1 class FedTFModel: 2 def __init__(self, device_list: List[PYU] = [], model: Callable[[], tf.keras.Model] = None, aggregator=None): 3 # 在每個機構節點(PYU)創建一個BaseTFModel實體 4 self._workers = {device: BaseTFModel( 5 model, device=device) for device in device_list} 6 # 聚合器,可以是PYU, SPUPPU, TEE, Secure Aggregation 7 self._aggregator = aggregator 8 9 def fit(self, x: Union[HDataFrame, FedNdarray], y: Union[HDataFrame, FedNdarray], batch_size=32, epochs=1, verbose='auto', 10 callbacks=None, validation_data=https://www.cnblogs.com/secretflow/p/None, shuffle=True, 11 class_weight=None, sample_weight=None, validation_freq=1, aggregate_freq=1): 12 self.handle_data(train_x, train_y, batch_size=batch_size, 13 shuffle=shuffle, epochs=epochs) 14 15 # 初始化模型引數 16 current_weights = { 17 device: worker.get_weights() for device, worker in self._workers.items()} 18 19 for epoch in range(epochs): 20 for step in range(0, self.steps_per_epoch, aggregate_freq): 21 weights, sample_nums = [], [] 22 for device, worker in self._workers.items(): 23 # 1. 機構節點在本地進行多輪訓練,得到模型引數 24 weight, sample_num = worker.train_step(current_weights[device], epoch*self.steps_per_epoch+step, aggregate_freq) 25 weights.append(weight) 26 sample_nums.append(sample_num) 27 # 模型引數聚合,可以是:PYU, SPU, TEE, Secure Aggregation 28 current_weight = self._aggregator.average( 29 weights, weights=sample_nums) 30 # 4. 機構節點從聚合節點獲取最新的全域模型,進入下一輪訓練 31 current_weights = {device: current_weight.to(device) for device, worker in self._workers.items()}
更多演算法:
通過以上聯邦學習演算法的例子,我們展示了隱語作為隱私計算框架的可編程性、可擴展性,期待您基于隱語探索更多有趣的用法!更多詳情請參考我們的教程和實作,
https://secretflow.readthedocs.io/zh_CN/latest/
-
在SPU進行PSI對齊,邏輯回歸、神經網路訓練
-
使用SPU HEU的組合構建HESS-LR, HESS-XGB演算法
-
橫向聯邦學習,在PYU進行本地訓練,使用SPU、TEE、Secure Aggregation進行梯度、權重聚合
-
縱向拆分學習,將一個模型拆分至多個PYU,使用PYU聚合隱層,使用差分隱私保護前向隱層和反向梯度
隱語官網: https://www.secretflow.org.cn 隱語社區及代碼訪問: https://github.com/secretflow https://gitee.com/secretflow 關注我們:
 公眾號:隱語的小劇場
B站:隱語secretflow
郵箱:[email protected]
關注微信公眾號:隱語的小劇場
公眾號:隱語的小劇場
B站:隱語secretflow
郵箱:[email protected]
關注微信公眾號:隱語的小劇場
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/534145.html
標籤:其他
上一篇:get、post、狀態碼型別